




官方文檔位置:https://www.elastic.co/guide/en/elasticsearch/reference/7.5/analysis.html
分詞
分詞是指將文本轉化成一系列的單詞(term or token)的過程,也可以叫文本分析
es裏稱之爲Analysis
分詞器
分詞器是es中專門處理分詞的組件,英文爲Analyzer ,它的組成如下:
Character Filters
- 針對原始文本進行處理,比如去除html特殊標記符
Tokenizer - 將原始文本按照一定規則切分爲單詞
Token Filters - 針對 tokenizer處理的單詞就行再加工,比如轉小寫、刪除或新增等處理
分詞器-調用順序
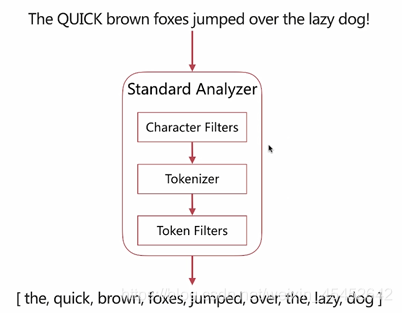
Analyze API
es提供了一個測試分詞的api接口,方便驗證分詞效果, endpoint是_ analyze
- 可以直接指定analyzer進行測試
- 可以直接指定索弓|中的字段進行測試
- 可以自定義分詞器進行測試
直接指定Analyzer進行測試,接口如下:
POST _analyze
{
"analyzer":"standard", //分詞器,standard是es默認分詞器,如果字段裏沒有指定分詞器,會默認使用standard
"text":"hello world!" //測試文本
}輸出:
{
"tokens": [
{
"token": "hello", //分詞結果
"start_offset": 0, //起始偏移
"end_offset": 5, //結束偏移
"type": "<ALPHANUM>",
"position": 0 //分詞位置
},
{
"token": "world",
"start_offset": 6,
"end_offset": 11,
"type": "<ALPHANUM>",
"position": 1
}
]
}直接指定索引中的字段進行測試,接口如下:
POST test_index/_analyze //測試的索引
{
"field":"username", //測試字段
"text":"hello world" //測試文本
}輸出:
{
"tokens": [
{
"token": "hello",
"start_offset": 0,
"end_offset": 5,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "world",
"start_offset": 6,
"end_offset": 11,
"type": "<ALPHANUM>",
"position": 1
}
]
}自定義分詞器測試,接口如下:
POST _analyze
{
"tokenizer":"standard", //指明分詞器
"filter":["lowercase"], //過濾成小寫
"text":"Hello World!"
}輸出:
{
"tokens": [
{
"token": "hello",
"start_offset": 0,
"end_offset": 5,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "world",
"start_offset": 6,
"end_offset": 11,
"type": "<ALPHANUM>",
"position": 1
}
]
}預定義分詞器
es自帶如下分詞器:
Standard
Simple
Whitespace
Stop
Keyword
Pattern
Language
Standard Analyzer
- 默認分詞器
- 按詞切分,支持多語言
- 小寫處理
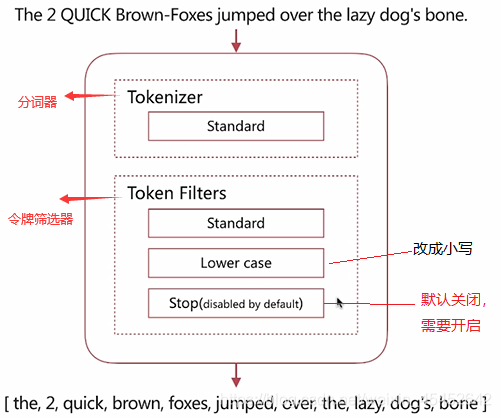
演示:
POST _analyze
{
"analyzer": "standard",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}輸出:(可以看到,所以大寫字母已經改成小寫)
{
"tokens": [
{
"token": "the",
"start_offset": 0,
"end_offset": 3,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "2",
"start_offset": 4,
"end_offset": 5,
"type": "<NUM>",
"position": 1
},
{
"token": "quick",
"start_offset": 6,
"end_offset": 11,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "brown",
"start_offset": 12,
"end_offset": 17,
"type": "<ALPHANUM>",
"position": 3
},
{
"token": "foxes",
"start_offset": 18,
"end_offset": 23,
"type": "<ALPHANUM>",
"position": 4
},
{
"token": "jumped",
"start_offset": 24,
"end_offset": 30,
"type": "<ALPHANUM>",
"position": 5
},
{
"token": "over",
"start_offset": 31,
"end_offset": 35,
"type": "<ALPHANUM>",
"position": 6
},
{
"token": "the",
"start_offset": 36,
"end_offset": 39,
"type": "<ALPHANUM>",
"position": 7
},
{
"token": "lazy",
"start_offset": 40,
"end_offset": 44,
"type": "<ALPHANUM>",
"position": 8
},
{
"token": "dog's",
"start_offset": 45,
"end_offset": 50,
"type": "<ALPHANUM>",
"position": 9
},
{
"token": "bone",
"start_offset": 51,
"end_offset": 55,
"type": "<ALPHANUM>",
"position": 10
}
]
}預定義分詞器:
Simple Analyzer
- 按照非字母切分
- 小寫處理
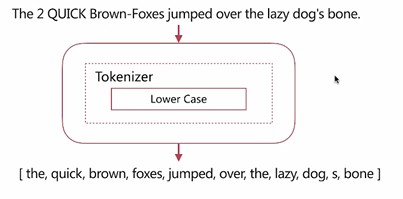
演示:
POST _analyze
{
"analyzer": "simple",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}輸出:注(因爲simple按照非字母切分,所以文中不是字母的已經全部切掉)
{
"tokens": [
{
"token": "the",
"start_offset": 0,
"end_offset": 3,
"type": "word",
"position": 0
},
{
"token": "quick",
"start_offset": 6,
"end_offset": 11,
"type": "word",
"position": 1
},
{
"token": "brown",
"start_offset": 12,
"end_offset": 17,
"type": "word",
"position": 2
},
{
"token": "foxes",
"start_offset": 18,
"end_offset": 23,
"type": "word",
"position": 3
},
{
"token": "jumped",
"start_offset": 24,
"end_offset": 30,
"type": "word",
"position": 4
},
{
"token": "over",
"start_offset": 31,
"end_offset": 35,
"type": "word",
"position": 5
},
{
"token": "the",
"start_offset": 36,
"end_offset": 39,
"type": "word",
"position": 6
},
{
"token": "lazy",
"start_offset": 40,
"end_offset": 44,
"type": "word",
"position": 7
},
{
"token": "dog",
"start_offset": 45,
"end_offset": 48,
"type": "word",
"position": 8
},
{
"token": "s",
"start_offset": 49,
"end_offset": 50,
"type": "word",
"position": 9
},
{
"token": "bone",
"start_offset": 51,
"end_offset": 55,
"type": "word",
"position": 10
}
]
}Whitespace Analyzer
- 按照空格切分
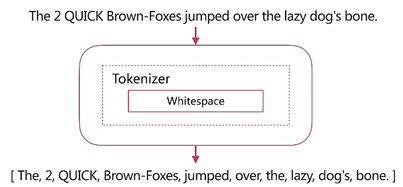
演示:
POST _analyze
{
"analyzer": "whitespace",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}輸出:(注:按空格切分,保持大小寫)
{
"tokens": [
{
"token": "The",
"start_offset": 0,
"end_offset": 3,
"type": "word",
"position": 0
},
{
"token": "2",
"start_offset": 4,
"end_offset": 5,
"type": "word",
"position": 1
},
{
"token": "QUICK",
"start_offset": 6,
"end_offset": 11,
"type": "word",
"position": 2
},
{
"token": "Brown-Foxes",
"start_offset": 12,
"end_offset": 23,
"type": "word",
"position": 3
},
{
"token": "jumped",
"start_offset": 24,
"end_offset": 30,
"type": "word",
"position": 4
},
{
"token": "over",
"start_offset": 31,
"end_offset": 35,
"type": "word",
"position": 5
},
{
"token": "the",
"start_offset": 36,
"end_offset": 39,
"type": "word",
"position": 6
},
{
"token": "lazy",
"start_offset": 40,
"end_offset": 44,
"type": "word",
"position": 7
},
{
"token": "dog's",
"start_offset": 45,
"end_offset": 50,
"type": "word",
"position": 8
},
{
"token": "bone.",
"start_offset": 51,
"end_offset": 56,
"type": "word",
"position": 9
}
]
}Stop Analyzer
- Stop Word指語氣助詞等修飾性的詞語,比如the、an、 的、這等等。
![ELK學習筆記-ES-分詞]()
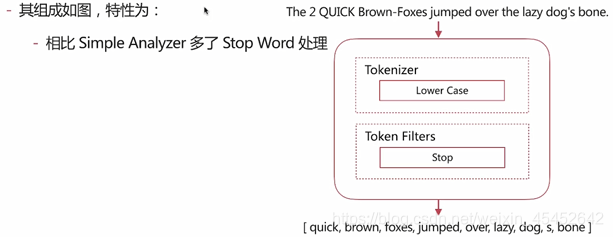
keyword Analyzer
- 不分詞,直接將輸入作爲一個單詞輸出
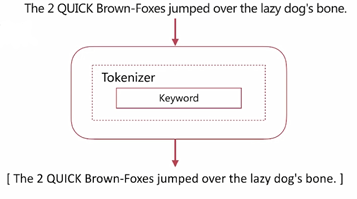
演示:
POST _analyze
{
"analyzer": "keyword",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}輸出:(注:不切分,所以直接輸出一整行)
{
"tokens": [
{
"token": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone.",
"start_offset": 0,
"end_offset": 56,
"type": "word",
"position": 0
}
]
}Pattern Analyzer
- 通過正則表達式自定義分隔符
- 默認\w+,非字詞的符號作爲分隔符
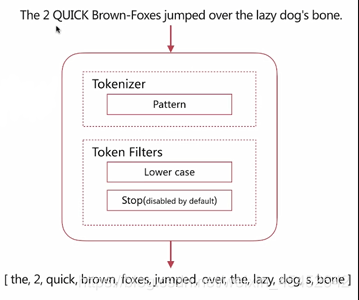
演示:
POST _analyze
{
"analyzer": "pattern",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}輸出:
{
"tokens": [
{
"token": "the",
"start_offset": 0,
"end_offset": 3,
"type": "word",
"position": 0
},
{
"token": "2",
"start_offset": 4,
"end_offset": 5,
"type": "word",
"position": 1
},
{
"token": "quick",
"start_offset": 6,
"end_offset": 11,
"type": "word",
"position": 2
},
{
"token": "brown",
"start_offset": 12,
"end_offset": 17,
"type": "word",
"position": 3
},
{
"token": "foxes",
"start_offset": 18,
"end_offset": 23,
"type": "word",
"position": 4
},
{
"token": "jumped",
"start_offset": 24,
"end_offset": 30,
"type": "word",
"position": 5
},
{
"token": "over",
"start_offset": 31,
"end_offset": 35,
"type": "word",
"position": 6
},
{
"token": "the",
"start_offset": 36,
"end_offset": 39,
"type": "word",
"position": 7
},
{
"token": "lazy",
"start_offset": 40,
"end_offset": 44,
"type": "word",
"position": 8
},
{
"token": "dog",
"start_offset": 45,
"end_offset": 48,
"type": "word",
"position": 9
},
{
"token": "s",
"start_offset": 49,
"end_offset": 50,
"type": "word",
"position": 10
},
{
"token": "bone",
"start_offset": 51,
"end_offset": 55,
"type": "word",
"position": 11
}
]
}Language Analyzer
- 提供了30+常見語言的分詞器(arabic, armenian, basque, bengali, brazilian, bulgarian,catalan, cjk, czech, danish,, dutch, english...)
注:如果工作中需要多語言分詞,可以用Language
中文分詞
難點:
- 中文分詞指的是將一 個漢字序列切分成- 個一個單獨的詞。在英文中,單詞之間是
以空格作爲自然分界符,漢語中詞沒有一個形式 上的分界符。 - 上下文不同,分詞結果迥異,比如交叉歧義問題,比如下面兩種分詞都合理
- 乒乓球拍/賣/完了
- 乒乓球/拍賣/完了
常見分詞系統
IK
- 實現中英文單詞的切分,支持ik smart. ik maxword等模式
- 可自定義詞庫,支持熱更新分詞詞典
jieba
- python中最流行的分詞系統,支持分詞和詞性標註
- 支持繁體分詞、自定義詞典、並行分詞等
基於自然語言處理的分詞系統:
Hanlp
- 由一系列模型與算法組成的Java工具包,目標是普及自然語言處理在生產環境中的應用
THULAC
- THU Lexical Analyzer for Chinese ,由清華大學自然語言處理與社會人文計算實驗室研製推出的一套中文詞法分析工具包,具有中文分詞和詞性標註功能
自定義分詞:
Tokenizer
- 將原始文本按照一定規則切分爲單詞(term or token)
- 自帶功能如下:
Path Hierarchy按照文件路徑進行切割
UAX URL Email按照standard分割,但不會分割郵箱和url
standard按照單詞進行分割
letter按照非字符類進行分割
NGram和Edge NGram連詞分割
whitespace按照空格進行分割
演示:Path Hierarchy (按文件路徑切割)
POST _analyze
{
"tokenizer": "path_hierarchy",
"text": "/var/log/xxx.log"
}
輸出:
{
"tokens": [
{
"token": "/var",
"start_offset": 0,
"end_offset": 4,
"type": "word",
"position": 0
},
{
"token": "/var/log",
"start_offset": 0,
"end_offset": 8,
"type": "word",
"position": 0
},
{
"token": "/var/log/xxx.log",
"start_offset": 0,
"end_offset": 16,
"type": "word",
"position": 0
}
]
}Token Filters
對於tokenizer輸出的單詞( term)進行增加、刪除、修改等操作
自帶如下功能:
- lowercase 將所有term轉爲小寫
- stop 刪除 stop words
- NGram和Edge NGram 連詞分割
- Synonym 添加近義詞的 term
演示:
POST _analyze
{
"text": "a Hello,world!", //需要切分的語句
"tokenizer": "standard",
"filter": [ //定義要測試的切分
"stop",
"lowercase",
{
"type": "ngram",
"min_gram":2, //最小2個
"max_gram":4 //最大4個
}
]
}自定義分詞需要在索引配置中設定。
創建分詞器:
PUT test_index_1
{
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer":{
"type": "custom",
"tokenizer": "standard",
"char_filter":[
"html_strip"
],
"filter":[
"lowercase",
"asciifolding"
]
}
}
}
}
}
}輸出:
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "test_index_1"
}分詞:
POST test_index_1/_analyze
{
"analyzer": "my_custom_analyzer", //引用剛纔定義的分詞器
"text": "this is a<b> box/b" //需要分詞語句
}輸出:
{
"tokens": [
{
"token": "this",
"start_offset": 0,
"end_offset": 4,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "is",
"start_offset": 5,
"end_offset": 7,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "a",
"start_offset": 8,
"end_offset": 12,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "box",
"start_offset": 13,
"end_offset": 16,
"type": "<ALPHANUM>",
"position": 3
},
{
"token": "b",
"start_offset": 17,
"end_offset": 18,
"type": "<ALPHANUM>",
"position": 4
}
]
}創建分詞器,並且設置條件切分:
PUT test_index2
{
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer":{ //定義分詞器名字
"type":"custom",
"char_filter":[ //設置字符過濾
"emoticons" //表情過濾
],
"tokenizer":"punctuation", //按照標點符號
"filter":[ //設置詞語更改操作
"lowercase", //小寫
"english_stop" //按英語格式,切分停止詞
]
}
},
"tokenizer": {
"punctuation":{
"type":"pattern",
"pattern":"[.,!?]" //添加標點符號
}
},
"char_filter": {
"emoticons":{
"type":"mapping",
"mappings":[
":) => _happy_", //添加表情
":( => _sad_"
]
}
},
"filter": {
"english_stop":{
"type":"stop",
"stopwords":"_english_" //按照英文格式分詞
}
}
}
}
}分詞:
POST test_index10/_analyze
{
"analyzer": "my_custom_analyzer",
"text": "I'm a :) , person and you?"
}輸出:像a,and,這樣的修飾詞已經被幹掉了
{
"tokens": [
{
"token": "i'm ",
"start_offset": 0,
"end_offset": 4,
"type": "word",
"position": 0
},
{
"token": " happy ",
"start_offset": 5,
"end_offset": 9,
"type": "word",
"position": 1
},
{
"token": " person",
"start_offset": 10,
"end_offset": 17,
"type": "word",
"position": 2
},
{
"token": " you",
"start_offset": 18,
"end_offset": 23,
"type": "word",
"position": 3
}
]
}分詞使用說明
- 創建或更新文檔時,會對相應的文檔進行分詞處理
- 查詢時,會對查詢語句進行分詞
創建索引時分詞:
- 索引時分詞是通過配置Index Mapping中每個字段的analyzer屬性實現的,如下:
- 不指定分詞時,使用默認standard
-
![ELK學習筆記-ES-分詞]()
查詢時分詞: - 查詢時通過analyzer指定分詞器
- 通過index mapping 設置 search_analyzer實現
注: 一般不需要特別指定查詢時分詞器,直接使用索引時分詞器即可,否則會出現無法匹配的情況(查詢和索引時使用同一個分詞器,這樣才能使用同一個分詞規則來進行語句分詞)![ELK學習筆記-ES-分詞]()
分詞的使用建議:
●明確字段是否需要分詞,不需要分詞的字段就將type設置爲keyword ,可以節省空間和提高寫性能
●善用_analyze API,查看文檔的具體分詞結果(可以查看你的分詞語句是如何被分詞的,再改正)選擇一個適合公司業務的分詞器,需要多次進行修改和測試



歡迎加入