




如果你覺得我寫的不錯, 或者想和我多交流, 就關注本人公衆號: stormling
1. redis介紹
1.1 什麼是redis
Redis是用C語言開發的一個開源的高性能 ( key-value ) ,它是一種NOSQL的數據庫。
redis是單進程單線程的內存數據庫, 所以說不存在線程安全問題
redis課支持10wQPS, 可以說性能非常優秀. 之所以單進程單線程性能還那麼好, 是因爲底層採用了[IO多路複用(NIO思想)]
1.2 redis數據類型
redis提供了五種數據類型:
string(字符串)
list(鏈表)
set(集合)
zset(有序集合)
hash(哈希類型)
記得有一次面試, 面試官特意問了zset數據類型的用法, 平時開發中很少用到zset數據類型, 但是zset經典的應用就是排序, 後面會介紹到.
1.3 redis和memcached的對比
- 持久化:
- redis可以用來做緩存, 也可以做存儲, 致辭aof和rdb兩種持久化方式
- memecached只能做緩存, 沒法持久化數據
- 數據結構:
- redis有豐富的數據類型: 五種常用的數據結構
- memcached一般就是字符串和對象
1.4 redis官網
- 官網地址: http://redis.io
- 中文官網地址: http://www.redis.cn
- 下載地址: http://download.redis.io/releases/
1.5 redis應用場景
- 內存數據庫(登陸信息, 購物車信息, 用戶瀏覽器記錄)
- 緩存服務器(商品數據, 廣告數據等等)(使用的最多)
- session共享
- 任務隊列(秒殺, 搶購, 12306等)
- 分佈式鎖的實現
- 支持發佈訂閱的消息模式
- 應用排行榜(有序集合)
- 網站訪問統計
- 數據過期處理
2. redis的多種模式
2.1 redis單機版
- 執行如下命令:
#第一步 安裝C語言環境
yum install -y gcc-c++
yum install -y wget
# 第二步 下載源碼包
wget http://download.redis.io/releases/redis-5.0.6.tar.gz
tar xzvf redis-5.0.6.tar.gz
# 第三步 編譯
cd redis-5.0.6
make
# 第四步 安裝
make install prefix=/usr/local/redis-5.0.6
- 啓動redis
cd redis-5.0.6
./redis-server如果出現如下的界面, 說明啓動成功了:
- 守護進程啓動
redis-5.0.6下面有一個配置文件redis.conf, 修改如下:
vim redis.conf
# 將`daemonize`由`no`改爲`yes`
daemonize yes
# 默認綁定的是迴環地址,默認不能被其他機器訪問
# bind 127.0.0.1
# 是否開啓保護模式,由yes該爲no
protected-mode no啓動
./redis-server redis.conf- 後端啓動關閉方式
./redis-cli shutdown- redis的其他主要命令
- redis-benchmark: 性能測試工具
- redis-check-aof: 檢查 AOF 日誌
- redis-check-dump: 檢查 RDB 日誌
- redis-cli: 啓動命令行客戶端
- redis-sentinel: redis的哨兵服務, 在redis2.8+以後加入的
- Redis-server: 啓動Redis服務
在redis的解壓目錄中, 有一個redis的配置文件
2.2 主從模式
1. 主從複製的作用
- 主從備份 防止主機宕機
- 讀寫分離,分擔 master 的任務
- 任務分離,如從服分別分擔備份工作與計算工作
2. redis主從複製的兩種方式

- redis主從服務通信的原理
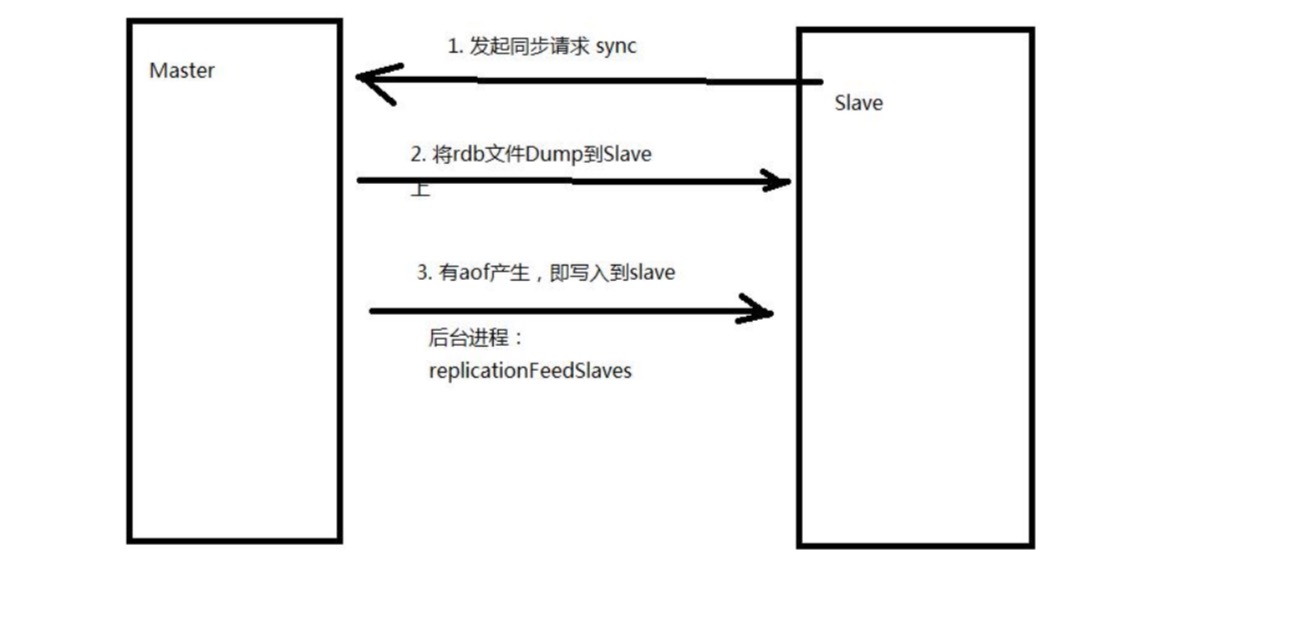
4. 配置redis主從模式
如果主服務器上需要增加redis的密碼, 增加如下配置:
requirepass xxxxxxredis的主, 從的安裝方式, 步驟都一樣, 從的配置文件從主拷貝過來, 然後在從節點的配置文佳中加上如下配置:
slaveof localhost 6379
#如果主上有密碼, 則從服務器上的配置文件需要增加以下配置:
masterauth xxxxxx2.3 哨兵模式
redis的哨兵模式是建立在主從模式上的, 因爲主從模式如果主發生故障, 我們的從並無法直接提升出來主共我們使用, 所以有了哨兵模式, 簡單的說, 哨兵模式就是增加的投票機制, 增加幾臺服務器作爲哨兵節點, 即監控節點, 如果超過半數的哨兵即: 2 / n + 1的個數認爲主掛了, 就會自動提升從服務器爲主服務器, 並且, 哨兵是可以實時改動redis主從的配置文件的.而自己的配置文件是實時發生變化.
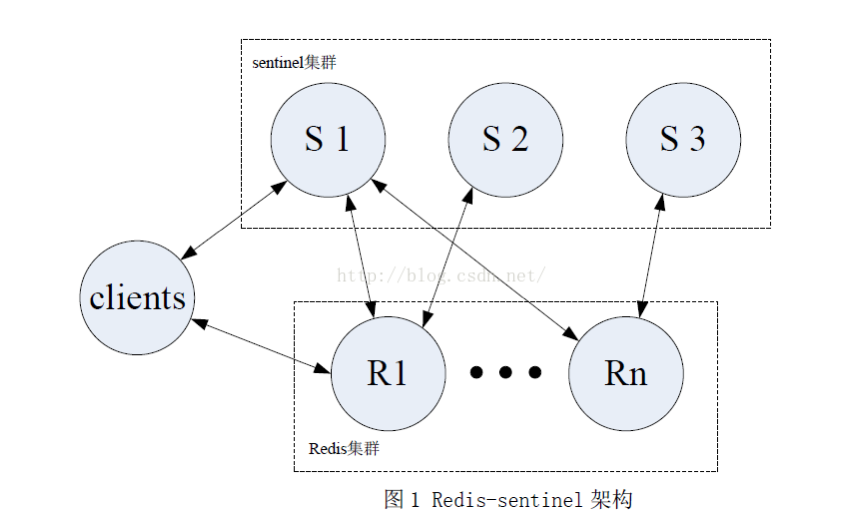
2.3.1 sentinel結構
2.3.2 sentinel功能
Sentinel實現如下功能:
(1)monitoring——redis實例是否正常運行。
(2)notification——通知application錯誤信息。
(3)failover——某個master死掉,選擇一個slave升級爲master,修改其他slave的slaveof關係,更新client連接。
(4)configurationprovider——client通過sentinel獲取redis地址,並在failover時更新地址。
Redis 2.8及以上版本可用。
2.3.3 sentinel集羣
很顯然,只使用單個sentinel進程來監控redis集羣是不可靠的,當sentinel進程宕掉後(sentinel本身也有單點問題,single-point-of-failure)整個集羣系統將無法按照預期的方式運行。所以有必要將sentinel集羣,這樣有幾個好處:
即使有一些sentinel進程宕掉了,依然可以進行redis集羣的主備切換;
如果只有一個sentinel進程,如果這個進程運行出錯,或者是網絡堵塞,那麼將無法實現redis集羣的主備切換(單點問題);
如果有多個sentinel,redis的客戶端可以隨意地連接任意一個sentinel來獲得關於redis集羣中的信息。
最少建立3個sentinel節點(sentinel-26380.conf、sentinel-26381.conf、sentinel-26382.conf)的部署方法完全是一致的(端口不同).
2.3.4 配置sentinel
根據官網給出的配置文件如下:
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 60000
sentinel failover-timeout mymaster 180000
sentinel parallel-syncs mymaster 1
# 監控其他集羣
sentinel monitor resque 192.168.1.3 6380 4
sentinel down-after-milliseconds resque 10000
sentinel failover-timeout resque 180000
sentinel parallel-syncs resque 5-
第一行配置指示 Sentinel 去監視一個名爲 mymaster 的主服務器, 這個主服務器的 IP 地址爲 127.0.0.1 , 端口號爲 6379 , 而將這個主服務器判斷爲失效至少需要 2 個 Sentinel 同意 (只要同意 Sentinel 的數量不達標,自動故障遷移就不會執行)。
不過要注意, 無論你設置要多少個 Sentinel 同意才能判斷一個服務器失效, 一個 Sentinel 都需要獲得系統中多數(majority) Sentinel 的支持, 才能發起一次自動故障遷移, 並預留一個給定的配置紀元 (configuration Epoch ,一個配置紀元就是一個新主服務器配置的版本號)。
換句話說, 在只有少數(minority) Sentinel 進程正常運作的情況下, Sentinel 是不能執行自動故障遷移的。
- down-after-milliseconds 選項指定了 Sentinel 認爲服務器已經斷線所需的毫秒數。
如果服務器在給定的毫秒數之內, 沒有返回 Sentinel 發送的 PING 命令的回覆, 或者返回一個錯誤, 那麼 Sentinel 將這個服務器標記爲主觀下線(subjectively down,簡稱 SDOWN )。
不過只有一個 Sentinel 將服務器標記爲主觀下線並不一定會引起服務器的自動故障遷移: 只有在足夠數量的 Sentinel 都將一個服務器標記爲主觀下線之後, 服務器纔會被標記爲客觀下線(objectively down, 簡稱 ODOWN ), 這時自動故障遷移纔會執行。
將服務器標記爲客觀下線所需的 Sentinel 數量由對主服務器的配置決定。
- parallel-syncs 選項指定了在執行故障轉移時, 最多可以有多少個從服務器同時對新的主服務器進行同步, 這個數字越小, 完成故障轉移所需的時間就越長。
如果從服務器被設置爲允許使用過期數據集(參見對 redis.conf 文件中對 slave-serve-stale-data 選項的說明), 那麼你可能不希望所有從服務器都在同一時間向新的主服務器發送同步請求, 因爲儘管複製過程的絕大部分步驟都不會阻塞從服務器, 但從服務器在載入主服務器發來的 RDB 文件時, 仍然會造成從服務器在一段時間內不能處理命令請求: 如果全部從服務器一起對新的主服務器進行同步, 那麼就可能會造成所有從服務器在短時間內全部不可用的情況出現。
你可以通過將這個值設爲 1 來保證每次只有一個從服務器處於不能處理命令請求的狀態。
2.3.5 啓動sentinel
線上一般是不同的機器, 我們這裏使用的是一個機器的不同端口
./redis-sentinel sentinel-26380.conf &
./redis-sentinel sentinel-26381.conf &
./redis-sentinel sentinel-26382.conf &2.3.6 sentinel的工作原理
- 每個Sentinel以每秒鐘一次的頻率向它所知的Master,Slave以及其他 Sentinel 實例發送一個 PING 命令
- 如果一個實例(instance)距離最後一次有效回覆 PING 命令的時間超過 down-after-milliseconds 選項所指定的值, 則這個實例會被 Sentinel 標記爲主觀下線。
- 如果一個Master被標記爲主觀下線,則正在監視這個Master的所有 Sentinel 要以每秒一次的頻率確認Master的確進入了主觀下線狀態。
- 當有足夠數量的 Sentinel(大於等於配置文件指定的值)在指定的時間範圍內確認Master的確進入了主觀下線狀態, 則Master會被標記爲客觀下線
- 在一般情況下, 每個 Sentinel 會以每 10 秒一次的頻率向它已知的所有Master,Slave發送 INFO 命令
- 當Master被 Sentinel 標記爲客觀下線時,Sentinel 向下線的 Master 的所有 Slave 發送 INFO 命令的頻率會從 10 秒一次改爲每秒一次
- 若沒有足夠數量的 Sentinel 同意 Master 已經下線, Master 的客觀下線狀態就會被移除。
若 Master 重新向 Sentinel 的 PING 命令返回有效回覆, Master 的主觀下線狀態就會被移除。2.4 redis cluster
2.4.1 什麼是redis cluster
Redis Cluster 是 Redis 的分佈式解決方案,在 Redis 3.0 版本正式推出 的,有效解決了 Redis 分佈式方面的需求。當遇到單機內存、併發、流 量等瓶頸時,可以採用 Cluster 架構達到負載均衡的目的。
redis-cluster的優勢:
-
官方推薦,毋庸置疑。
-
去中心化,集羣最大可增加1000個節點,性能隨節點增加而線
性擴展。
-
管理方便,後續可自行增加或摘除節點,移動分槽等等。
- 簡單,易上手。
2.4.2數據分佈理論與redis的數據分區
分佈式數據庫首要解決把整個數據集按照分區規則映射到多個節點 的問題,即把數據集劃分到多個節點上,每個節點負責整個數據的一個 子集。常見的分區規則有哈希分區和順序分區。Redis Cluster 採用哈希 分區規則。
虛擬槽分區巧妙地使用了哈希空間,使用分散度良好的哈希函數把 所有的數據映射到一個固定範圍內的整數集合,整數定義爲槽(slot)。比如 Redis Cluster 槽的範圍是 0 ~ 16383。槽是集羣內數據管理和遷移 的基本單位。
Redis Cluster 採用虛擬槽分區,所有的鍵根據哈希函數映射到 0 ~16383,計算公式:slot = CRC16(key)&16383。每一個節點負責維護一部 分槽以及槽所映射的鍵值數據。
redis-cluster把所有的物理節點映射到[0-16383] 上,cluster 負責維護node <->slot <-> value
2.4.3 redis cluster的體系架構
我們以 6 個節點爲例,來介紹 Redis Cluster 的體系架構。其中:三個爲
master 節點,另外三個爲 slave 節點。
2.4.4 redis cluster一致性保證(官網)
Redis 並不能保證數據的強一致性. 這意味這在實際中集羣在特定的條件下可能會丟失寫操作.
第一個原因是因爲集羣是用了異步複製. 寫操作過程:
- 客戶端向主節點B寫入一條命令.
- 主節點B向客戶端回覆命令狀態.
- 主節點將寫操作複製給他得從節點 B1, B2 和 B3.
主節點對命令的複製工作發生在返回命令回覆之後, 因爲如果每次處理命令請求都需要等待複製操作完成的話, 那麼主節點處理命令請求的速度將極大地降低 —— 我們必須在性能和一致性之間做出權衡。 注意:Redis 集羣可能會在將來提供同步寫的方法。 Redis 集羣另外一種可能會丟失命令的情況是集羣出現了網絡分區, 並且一個客戶端與至少包括一個主節點在內的少數實例被孤立。
舉個例子 假設集羣包含 A 、 B 、 C 、 A1 、 B1 、 C1 六個節點, 其中 A 、B 、C 爲主節點, A1 、B1 、C1 爲A,B,C的從節點, 還有一個客戶端 Z1 假設集羣中發生網絡分區,那麼集羣可能會分爲兩方,大部分的一方包含節點 A 、C 、A1 、B1 和 C1 ,小部分的一方則包含節點 B 和客戶端 Z1 .
Z1仍然能夠向主節點B中寫入, 如果網絡分區發生時間較短,那麼集羣將會繼續正常運作,如果分區的時間足夠讓大部分的一方將B1選舉爲新的master,那麼Z1寫入B中得數據便丟失了.
注意, 在網絡分裂出現期間, 客戶端 Z1 可以向主節點 B 發送寫命令的最大時間是有限制的, 這一時間限制稱爲節點超時時間(node timeout), 是 Redis 集羣的一個重要的配置選項:
2.4.5 安裝redis cluster
Redis cluster最少需要三臺主服務器, 三臺從服務器(自己做實驗的話, 可以使用一臺服務器, 不同的端口)
- 安裝Ruby環境和Ruby Redis接口
由於創建和管理需要使用到 redis-trib 工具,該工具位於 Redis 源碼的 src 文 件夾中,它是一個 Ruby 程序,這個程序通過向實例發送特殊命令來完成創建新 集羣,檢查集羣,或者對集羣進行重新分片(reshared)等工作,所以需要安裝 Ruby環境和相應的 Redis 接口
下面是可以使用 yum 來安裝 Ruby, 添加yum源, 然後yum安裝
[media]
name=Red Hat Enterprise Linux 7.4 baseurl=file:///cdroom
enabled=1
gpgcheck=1
gpgkey=file:///cdroom/RPM-GPG-KEY-redhat-release
yum -y install ruby ruby-devel rubygems rpm-build
gem install redis如果在安裝過程中出現ERROR: Error installing redis redis requires Ruby version >= 2.2.2.
請參考《 ruby 中國官網 》的安裝方法
- 以6個節點爲例, 安裝和部署redis cluster
- 主節點: 6379, 6380, 6381
- 從節點: 6382, 6383, 6384
- 每個配置文件的地方都需要修改, 修改成端口所對應的
daemonize yes
#各個節點的端口不同
port 6379
#開啓集羣服務
cluster-enabled yes
#節點的配置文件名字, 需要更改成不同的端口
cluster-config-file nodes/nodes-6379.conf cluster-node-timeout 15000
# rdb 文件名字改成不同的端口
dbfilename dump6379.rdb
appendonly yes
#aof 文件名字改成不同的端口
appendfilename "appendonly6379.aof"- 配置文件一共有6個
- redis6379.conf
- redis6380.conf
- redis6381.conf
- redis6382.conf
- redis6383.conf
- redis6384.conf
- 啓動redis實例
bin/redis-server conf/redis6379.conf
bin/redis-server conf/redis6380.conf
bin/redis-server conf/redis6381.conf
bin/redis-server conf/redis6382.conf
bin/redis-server conf/redis6383.conf
bin/redis-server conf/redis6384.conf查看redis的進程
- 使用 redis-trib.rb 自動部署方式
bin/redis-trib.rb create --replicas 1 192.168.56.72:6379 192.168.56.72:6380
192.168.56.72:6381 192.168.56.72:6382 192.168.56.72:6383 192.168.56.72:6384注意: –replicas 1 表示我們希望爲集羣中的每個主節點創建一個從節點。
開始配置集羣
- 測試redis cluster
- 使用客戶端登陸:
bin/redis-cli -c -p 6379-c: 表示登陸集羣
可以使用cluster nodes 命令查看集羣中的節點
2.4.6 維護節點
- 添加主節點
- 在終端打開一個新的標籤頁.
- 進入cluster-test 目錄.
- 創建並進入 7006文件夾.
- 和其他節點一樣,創建redis.conf文件,需要將端口號改成7006.
- 最後啓動節點 ../redis-server ./redis.conf
- 如果正常的話,節點會正確的啓動.
bin/redis-trib.rb add-node 127.0.0.1:7006 127.0.0.1:6379redis 127.0.0.1:7006> cluster nodes
3e3a6cb0d9a9a87168e266b0a0b24026c0aae3f0 127.0.0.1:6380 master - 0 1385543178575 0 connected 5960-10921
3fc783611028b1707fd65345e763befb36454d73 127.0.0.1:6383 slave 3e3a6cb0d9a9a87168e266b0a0b24026c0aae3f0 0 1385543179583 0 connected
f093c80dde814da99c5cf72a7dd01590792b783b :0 myself,master - 0 0 0 connected
2938205e12de373867bf38f1ca29d31d0ddb3e46 127.0.0.1:6381 slave 3c3a0c74aae0b56170ccb03a76b60cfe7dc1912e 0 1385543178072 3 connected
a211e242fc6b22a9427fed61285e85892fa04e08 127.0.0.1:6382 slave 97a3a64667477371c4479320d683e4c8db5858b1 0 1385543178575 0 connected
97a3a64667477371c4479320d683e4c8db5858b1 127.0.0.1:6379 master - 0 1385543179080 0 connected 0-5959 10922-11422
3c3a0c74aae0b56170ccb03a76b60cfe7dc1912e 127.0.0.1:6384 master - 0 1385543177568 3 connected 11423-16383新節點現在已經連接上了集羣, 成爲集羣的一份子, 並且可以對客戶端的命令請求進行轉向了, 但是和其他主節點相比, 新節點還有兩點區別:
a. 新節點沒有包含任何數據, 因爲它沒有包含任何哈希槽.
b. 儘管新節點沒有包含任何哈希槽, 但它仍然是一個主節點, 所以在集羣需要將某個從節點升級爲新的主節點時, 這個新節點不會被選中。
-
has槽重新分配(數據遷移)
a. 先連接集羣上任意一個節點
bin/redis-cli --cluster reshard 127.0.0.1:6379 b. 輸入要分配的槽數量
bin/redis-trib.rb reshard 127.0.0.1:6379
#有個提示輸入1-16384, 屬於多少, 代表分配多少個槽 c. 輸入要接收槽的節點id
通過cluster nodes 查看7006的節點id爲: 3e3a6cb0d9a9a87168e266b0a0b24026c0aae3f0
輸入到提示信息中 d. 輸入源節點id
輸入源節點id, 槽將從源節點中拿, 分配後的槽在源及誒單中就不存在了, 輸入all, 就是把所有源節點中獲取槽, 輸入done取消分配
- 添加從節點
./redis-trib.rb add-node --slave 127.0.0.1:7006 127.0.0.1:6379- 刪除節點
bin/redis-trib del-node 127.0.0.1:6379 `<node-id>`
#可以通過cluster nodes 查看node-id
cluster nodes3. redis的數據類型
3.1 string類型
3.1.1 賦值
語法:
# 一次設置一個key
set key value
# 一次設置多個key
mset key1 value1 key2 value2示例:
127.0.0.1:6379> set test 123
OK3.1.2 取值
語法:
#獲取一個key的值
get key
# 獲取多個key的值
mget key1 key2示例:
127.0.0.1:6379> get test
"123“3.1.3 數值遞增
語法:
# key 增加1
incr key
# key 增加n
incrby key n示例:
# 增加1
127.0.0.1:6379> incr num
(integer) 1
127.0.0.1:6379> incr num
(integer) 2
127.0.0.1:6379> incr num
(integer) 3
# 增加 n
127.0.0.1:6379> incrby num 2
(integer) 5
127.0.0.1:6379> incrby num 2
(integer) 7
127.0.0.1:6379> incrby num 2
(integer) 9
應用場景: 商品編號, 編號, 採用incr命令生成自增主鍵
3.1.4 數值遞減
語法:
# 遞減1
decr key
# 遞減n
decrby key n示例:
127.0.0.1:6379> decr num
(integer) 6
127.0.0.1:6379> decr num
(integer) 5
127.0.0.1:6379> decrby num 3
(integer) 2
127.0.0.1:6379> decrby num 3
(integer) -13.1.5 僅當不存在賦值
該命令可以實現分佈式鎖的功能, 後面會講解
語法:
setnx key value示例:
(integer) 0
redis> SETNX job "programmer"
(integer) 1
redis> SETNX job "code-farmer"
(integer) 0
redis> GET job
"programmer"3.1.5 向尾部追加值
語法:
append key value示例:
127.0.0.1:6379> set str hello
OK
127.0.0.1:6379> append str " world!"
(integer) 12
127.0.0.1:6379> get str
"hello world!"3.1.6 獲取字符串長度
語法:
strlen key示例:
127.0.0.1:6379> strlen str
(integer) 0
127.0.0.1:6379> set str hello
OK
127.0.0.1:6379> strlen str
(integer) 5
3.2 list類型
redis的列表類型可以存儲一個有序的字符串列表, 常用的操作是向列表兩端添加元素, 或者獲得列表的某一個片段.
列表類型內部是使用雙向鏈表(double linked list)實現的, 所以向列表兩端添加元素的時間複雜度爲o(1), 獲取越接近兩端的元素速度越快.
3.2.1 插入元素
語法:
# 左邊插入元素
lpush key [value1, value2, value3]
# 右邊插入元素
rpush key [value1, value2, value3]示例:
127.0.0.1:6379> lpush list:1 1 2 3
(integer) 3
127.0.0.1:6379> rpush list:1 4 5 6
(integer) 33.2.2 列表切片
語法:
# 查看從start到stop之間的所有元素, 包含兩端的元素, 索引從`0`開始。索引可以 是負數,如:“`-1`”代表最後邊的一個元素。
lrange key start stop示例:
注意: lpush是按照元素的先後順序, 從左往右, rpush是按照元素的先後順序, 從右往左
127.0.0.1:6379> lpush list1 1 2 3
(integer) 3
127.0.0.1:6379> lrange list1 0 -1
1) "3"
2) "2"
3) "1"
127.0.0.1:6379> rpush list1 4 5 6
(integer) 6
127.0.0.1:6379> lrange list1 0 -1
1) "3"
2) "2"
3) "1"
4) "4"
5) "5"
6) "6"3.2.3 list兩端彈出元素
語法:
# 左彈出元素
lpop key
# 右彈出元素
rpop key示例:
127.0.0.1:6379>lpop list:1
"3“
127.0.0.1:6379>rpop list:1
"6“3.2.4 獲取列表長度
語法:
# 獲取列表中元素的個數
llen key示例:
127.0.0.1:6379> llen list:1
(integer) 23.2.5 刪除元素
語法:
# 刪除列表中指定個數的值
lrem key count value
# 當count > 0 時, 從表頭開始向表尾搜索,移除與 VALUE 相等的元素,數量爲 COUNT
# 當count < 0 時, 從表尾開始向表頭搜索,移除與 VALUE 相等的元素,數量爲 COUNT 的絕對值。
# 當count = 0 時, 移除表中所有與 VALUE 相等的值。示例:
redis> RPUSH mylist "hello"
(integer) 1
redis> RPUSH mylist "hello"
(integer) 2
redis> RPUSH mylist "foo"
(integer) 3
redis> RPUSH mylist "hello"
(integer) 4
redis> LREM mylist -2 "hello"
(integer) 2
redis> LRANGE mylist 0 -1
1) "hello"
2) "foo"3.2.6 獲取指定索引的元素值
語法:
lindex key index示例:
127.0.0.1:6379>lindex l:list 2
"1"3.2.7 列表中插入元素
語法:
# 向列表中插入元素, 該命令首先會在列表從左到右查找值爲target的元素, 然後根據第二個參數before或者after來決定value插入到該元素的前面還是後面
linsert key before|after target value示例:
127.0.0.1:6379> lrange list 0 -1
1) "3"
2) "2"
3) "1"
127.0.0.1:6379> linsert list after 3 4
(integer) 4
127.0.0.1:6379> lrange list 0 -1
1) "3"
2) "4"
3) "2"
4) "1"
3.3 set類型
set類型即集合類型, 其中的數據是不重複且沒有順序的.
3.3.1 添加元素
語法:
sadd key member示例:
127.0.0.1:6379> sadd set a b c
(integer) 3
127.0.0.1:6379> sadd set a
(integer) 03.3.2 刪除元素
語法:
srem key member示例:
127.0.0.1:6379> srem set c d
(integer) 13.3.3 獲取集合所有元素
語法:
sembers key示例:
127.0.0.1:6379> smembers set
1) "b"
2) "a”3.3.4 判斷元素是否在集合中
語法:
sismember key member示例:
127.0.0.1:6379>sismember set a
(integer) 1
127.0.0.1:6379>sismember set h
(integer) 03.3.5 兩個集合差集
語法:
# 結合key - key1 - key2 ....
sdiff key [key1, key2 ...]示例:
127.0.0.1:6379> sadd setA 1 2 3
(integer) 3
127.0.0.1:6379> sadd setB 2 3 4
(integer) 3
127.0.0.1:6379> sdiff setA setB
1) "1"
127.0.0.1:633.3.6 並集
語法:
# 集合的交集運算 A ∩ B:屬於A且屬於B的元素構成的集合。
sinter key [key1, key2, ...]示例:
127.0.0.1:6379> sinter setA setB
1) "2"
2) "3"3.3.7 合集
語法:
# 集合的並集運算 A ∪ B:屬於A或者屬於B的元素構成的集合
sunion key [key1, key2, ...]示例:
127.0.0.1:6379> sunion setA setB
1) "1"
2) "2"
3) "3"
4) "4"3.3.8 獲取集合元素個數
語法:
SCARD key示例:
127.0.0.1:6379> smembers setA
1) "1"
2) "2"
3) "3"
127.0.0.1:6379> scard setA
(integer) 33.3.9 彈出隨機一個元素
注意: 因爲集合是無序的, 所有spop會隨機從集合中彈出一個元素
語法:
spop key示例:
127.0.0.1:6379> spop setA
"1“3.4 hash類型
3.4.1 賦值
語法:
# 設置一個字段值
hset key field value
# 設置多個字段值
hmset key field1 value1 field2 value2 [...]示例:
127.0.0.1:6379> hset user username zhangsan
(integer) 1
127.0.0.1:6379> hmset user age 20 username lisi
OK3.4.2 當字段不存在時賦值
語法:
# 如果字段存在, 不進行任何操作, 沒有進行設置
hsetnx key field value語法:
# 如果user中沒有age字段則設置age值爲30,否則不做任何操作
127.0.0.1:6379> hsetnx user age 30
(integer) 03.4.3 取值
語法:
# 獲取單個字段
hget key field
# 獲取多個字段
hget key field [field1, field2...]示例:
127.0.0.1:6379> hget user username
"zhangsan“
127.0.0.1:6379> hget user username
"zhangsan“3.4.4 獲取所有字段
語法:
hgetall key示例:
127.0.0.1:6379> hgetall user
1) "age"
2) "20"
3) "username"
4) "lisi"3.4.5 刪除字段
語法:
hdel key field [field ...]示例:
127.0.0.1:6379> hdel user age
(integer) 1
127.0.0.1:6379> hdel user age name
(integer) 0
127.0.0.1:6379> hdel user age username
(integer) 13.4.6 增加數字
語法:
hincrby key field increment示例:
127.0.0.1:6379> hincrby user age 2 # 將用戶的年齡加2
(integer) 22
127.0.0.1:6379> hget user age # 獲取用戶的年齡
"22“3.4.5 判斷字段是否存在
語法:
hexists key field示例:
# 查看user中是否有age字段
127.0.0.1:6379> hexists user age
(integer) 1
# 查看user中是否有name字段
127.0.0.1:6379> hexists user name
(integer) 03.4.6 獲取所有的field和value
語法:
# 獲取所有的field
hkeys key
# 獲取所有的value
hvalues key示例:
127.0.0.1:6379> hmset user age 20 name lisi
OK
127.0.0.1:6379> hkeys user
1) "age"
2) "name"
127.0.0.1:6379> hvals user
1) "20"
2) "lisi"3.4.7 獲取所有字段
語法:
hgetall key示例:
127.0.0.1:6379> hset hh a 1 b 2
(integer) 2
127.0.0.1:6379> hgetall hh
1) "a"
2) "1"
3) "b"
4) "2"3.5 zset類型
在 set 集合類型的基礎上,有序集合類型爲集合中的每個元素都 關聯一個分數 ,這使得我們不僅可以完成插入、刪除 和判斷元素是否存在在集合中,還能夠獲得分數最高或最低的前N個元素、獲取指定分數範圍內的元素等與分數有關 的操作
3.5.1 增加元素
語法:
zadd key score member [score member ...]示例:
127.0.0.1:6379> zadd top10 10 zhangsan 20 lisi
(integer) 2
127.0.0.1:6379> zadd top10 15 ling
(integer) 1
127.0.0.1:6379> 3.5.2 獲取元素範圍
語法:
# 分數從大到小
zrange key start stop [WITHSCORES]
# 分數從小到大
zrevrange key start stop [WITHSCORES]示例:
127.0.0.1:6379> zrange top10 0 10
1) "zhangsan"
2) "ling"
3) "lisi"
127.0.0.1:6379> zrevrange top10 0 10
1) "lisi"
2) "ling"
3) "zhangsan"
127.0.0.1:6379>如果需要獲取元素的分數, 可以在命令尾部加上WITHSCORES參數
127.0.0.1:6379> zrevrange top10 0 10 WITHSCORES
1) "lisi"
2) "20"
3) "ling"
4) "15"
5) "zhangsan"
6) "10"
3.5.3 獲取元素分數
語法:
zscore key member示例:
127.0.0.1:6379> zscore top10 ling
"15"3.5.4 刪除元素
語法:
zrem key member [memeber ...]示例:
127.0.0.1:6379> zrem top10 ling
(integer) 1
127.0.0.1:6379> zrevrange top10 0 10
1) "lisi"
2) "zhangsan"3.5.5 獲取指定分數範圍的元素
語法:
zrangebyscore key min max [WITHSCORES]示例:
127.0.0.1:6379> zadd top10 15 ling
(integer) 1
127.0.0.1:6379> zadd top10 99 zhangsan
(integer) 0
127.0.0.1:6379> zrevrange top10 0 10 WITHSCORES
1) "zhangsan"
2) "99"
3) "lisi"
4) "20"
5) "ling"
6) "15"
127.0.0.1:6379> zrangebyscore top10 19 100 WITHSCORES
1) "lisi"
2) "20"
3) "zhangsan"
4) "99"3.5.6 增加某個元素的分數
語法:
zincrby key increment member 示例:
127.0.0.1:6379> zincrby top10 100 zhangsan
"199"
127.0.0.1:6379> zincrby top10 -10 zhangsan
"189"
127.0.0.1:6379> zrange top10 0 10 WITHSCORES
1) "ling"
2) "15"
3) "lisi"
4) "20"
5) "zhangsan"
6) "189"
127.0.0.1:6379> 3.5.7 獲取集合中元素的個數
語法:
zcard key示例:
127.0.0.1:6379> zcard top10
(integer) 33.5.8 獲取指定分數範圍內的元素個數
語法:
zcount key min max示例:
127.0.0.1:6379> zrange top10 0 10 WITHSCORES
1) "ling"
2) "15"
3) "lisi"
4) "20"
5) "zhangsan"
6) "189"
127.0.0.1:6379> zcount top10 19 30
(integer) 13.5.9 按照排名範圍刪除元素
語法:
zremrangebyrank key start stop示例:
127.0.0.1:6379> zcount top10 19 30
(integer) 1
127.0.0.1:6379> zrange top10 0 -1 WITHSCORES
1) "zhangsan"
2) "189"3.5.10 按照分數範圍刪除元素
語法:
zremrangebyscore key min max示例:
127.0.0.1:6379> zadd top10 85 ajing 72 shang 53 kong
(integer) 3
127.0.0.1:6379> zrange top10 0 -1 WITHSCORES
1) "kong"
2) "53"
3) "shang"
4) "72"
5) "ajing"
6) "85"
127.0.0.1:6379> zremrangebyscore top10 60 100
(integer) 2
127.0.0.1:6379> zrange top10 0 -1 WITHSCORES
1) "kong"
2) "53"
3) "zhangsan"
4) "189"3.5.11 獲取元素的排名
語法:
# 從小的到大
zrank key member
# 從大到小
zrevrank key member示例:
# 從小到大排名第二
127.0.0.1:6379> zrank top10 zhangsan
(integer) 1
# 從大到小排名第一
127.0.0.1:6379> zrevrank top10 zhangsan
(integer) 0- zset很多用在銷售排名, 打賞排名等.但是zset要比list更消耗系統性能
3.6 其他常用命令
3.6.1 查看key(支持正則)
語法:
keys pattern示例:
127.0.0.1:6379> keys *
1) "top10"
2) "a"
3) "list1"
4) "list"
5) "hh"3.6.2 刪除key
語法:
del key示例:
127.0.0.1:6379> del a
(integer) 13.6.3 判斷key是否存在
語法:
exists key示例:
127.0.0.1:6379> exists a
(integer) 0
127.0.0.1:6379> exists hh
(integer) 13.6.4 設置過期時間(重要)
語法:
# 設置key的生存時間
exire key seconds
# 查看key的生存時間
ttl key
# 清除生存時間
persist key
# 生存時間設置單位爲毫秒
pexpire key milliseconds示例:
# 設置test的值爲1
192.168.101.3:7002> set test 1
OK
# 獲取test的值
192.168.101.3:7002> get test
"1"
# 設置test的生存時間爲5秒
192.168.101.3:7002> EXPIRE test 5
(integer) 1
# 查看test的剩餘生成時間還有1s刪除
192.168.101.3:7002> TTL test
(integer) 1
192.168.101.3:7002> TTL test
(integer) -2
# 獲取test的值, 已經刪除了
192.168.101.3:7002> get test
(nil)3.6.5 改名字
語法:
rename oldkey newkey3.6.6 查看key類型
語法:
type key3.6.7 清空數據
語法:
flushdb3.6.8 查看redis信息詳情
語法:
info4. redis的消息模式
4.1 隊列模式
使用redis的list數據類型lpush和rpop實現消息隊列

注意事項:
消息接收方如果不知道隊列中是否有消息,會一直髮送rpop命令,如果這樣的話,會每一次都建立一次連接, 這樣顯然不好。可以使用brpop命令,它如果從隊列中取不出來數據,會一直阻塞,在一定範圍內沒有取出則返回null
4.2 發佈訂閱模式
4.2.1 訂閱模式
訂閱例子示意圖:下圖展示了頻道 channel1 , 以及訂閱這個頻道的三個客戶端 —— client2 、 client5 和 client1 之間的關係.
4.2.2 發佈模式
發佈例子示意圖:當有新消息通過 PUBLISH 命令發送給頻道 channel1 時, 這個消息就會被髮送給訂閱它的三個客戶端:
4.3.3 其它相關命令
# 訂閱一個或多個符合給定模式的頻道。
PSUBSCRIBE pattern [pattern ...]
# 查看訂閱與發佈系統狀態。
PUBSUB subcommand [argument [argument ...]]
# 退訂所有給定模式的頻道。
PUNSUBSCRIBE [pattern [pattern ...]]
# 指退訂給定的頻道。
UNSUBSCRIBE [channel [channel ...]]
5. redis持久化
Redis 提供了多種不同級別的持久化方式:
-
RDB 持久化可以在指定的時間間隔內生成數據集的時間點快照(point-in-time snapshot)。
-
AOF (Append-only file)持久化記錄服務器執行的所有寫操作命令,並在服務器啓動時,通過重新執行這些命令來還原數據集。 AOF 文 件中的命令全部以 Redis 協議的格式來保存,新命令會被追加到文 件的末尾。 Redis 還可以在後臺對 AOF 文件進行重寫(rewrite), 使得 AOF 文件的體積不會超出保存數據集狀態所需的實際大小。
- Redis 還可以同時使用 AOF 持久化和 RDB 持久化。 在這種情況下, 當 Redis 重啓時, 它會優先使用 AOF 文件來還原數據集, 因爲AOF 文件保存的數據集通常比 RDB 文件所保存的數據集更完整。
- 你甚至可以關閉持久化功能,讓數據只在服務器運行時存在。
5.1 rdb
5.1.1 save策略
SNAPSHOTTING的持久化方式有多種save策略可供選擇,而且支持混用,例如:
save 900 1
save 300 100
save 60 10000上述配置的效果是:snapshotting會在3個條件中的任何一個滿足時被觸發:
a. 900s內至少1個key有變化;
b. 300s內至少100個key有變化;
c. 60s內至少有10000個key有變化
- 主動備份數據
redis 127.0.0.1:6379> SAVE
OK
# 在後臺執行備份
127.0.0.1:6379> BGSAVE
Background saving started5.1.2 優缺點
RDB 的優點:
- RDB是一種表示某個即時點的Redis數據的緊湊文件。RDB文件適合用於備份。例如,你可能想要每小時歸檔最近24小時的RDB文件,每天保存近30天的RDB快照。這允許你很容易的恢復不同版本的數據集以容災。
- RDB非常適合於災難恢復,作爲一個緊湊的單一文件,可以被傳輸到遠程的數據中心,或者是Amazon S3(可能得加密)。
- RDB最大化了Redis的性能,因爲Redis父進程持久化時唯一需要做的是啓動(fork)一個子進程,由子進程完成所有剩餘工作。父進程實例不需要執行像磁盤IO這樣的操作。
- RDB在重啓保存了大數據集的實例時比AOF要快。
RDB 的缺點
- 當你需要在Redis停止工作(例如停電)時最小化數據丟失,RDB可能不太好。你可以配置不同的保存點(save point)來保存RDB文件(例如,至少5分鐘和對數據集100次寫之後,但是你可以有多個保存點)。然而,你通常每隔5分鐘或更久創建一個RDB快照,所以一旦Redis因爲任何原因沒有正確關閉而停止工作,你就得做好最近幾分鐘數據丟失的準備了。
- RDB需要經常調用fork()子進程來持久化到磁盤。如果數據集很大的話,fork()比較耗時,結果就是,當數據集非常大並且CPU性能不夠強大的話,Redis會停止服務客戶端幾毫秒甚至一秒。AOF也需要fork(),但是你可以調整多久頻率重寫日誌而不會有損(trade-off)持久性(durability)。
5.2 aof
5.2.1 配置aof
appendonly yes
appendfilename "6379.aof"
appendfsync everysec配置說明:
no:redis不主動調用fsync,何時刷盤由os來調度
always:redis針對每個寫入命令俊輝主動調用fsync刷磁盤
eversec:每秒調用一次fsync刷盤
5.2.2 優缺點
AOF 的優點:
- 使用AOF Redis會更具有可持久性(durable):你可以有很多不同的fsync策略:沒有fsync,每秒fsync,每次請求時fsync。使用默認的每秒fsync策略,寫性能也仍然很不錯(fsync是由後臺線程完成的,主線程繼續努力地執行寫請求),即便你也就僅僅只損失一秒鐘的寫數據。
- AOF日誌是一個追加文件,所以不需要定位,在斷電時也沒有損壞問題。即使由於某種原因文件末尾是一個寫到一半的命令(磁盤滿或者其他原因),redis-check-aof工具也可以很輕易的修復。
- 當AOF文件變得很大時,Redis會自動在後臺進行重寫。重寫是絕對安全的,因爲Redis繼續往舊的文件中追加,使用創建當前數據集所需的最小操作集合來創建一個全新的文件,一旦第二個文件創建完畢,Redis就會切換這兩個文件,並開始往新文件追加。
- AOF文件裏面包含一個接一個的操作,以易於理解和解析的格式存儲。你也可以輕易的導出一個AOF文件。例如,即使你不小心錯誤地使用FLUSHALL命令清空一切,如果此時並沒有執行重寫,你仍然可以保存你的數據集,你只要停止服務器,刪除最後一條命令,然後重啓Redis就可以。
AOF 的缺點:
- 對同樣的數據集,AOF文件通常要大於等價的RDB文件。
- AOF可能比RDB慢,這取決於準確的fsync策略。通常fsync設置爲每秒一次的話性能仍然很高,如果關閉fsync,即使在很高的負載下也和RDB一樣的快。不過,即使在很大的寫負載情況下,RDB還是能提供能好的最大延遲保證。
- 在過去,我們經歷了一些針對特殊命令(例如,像BRPOPLPUSH這樣的阻塞命令)的罕見bug,導致在數據加載時無法恢復到保存時的樣子。這些bug很罕見,我們也在測試套件中進行了測試,自動隨機創造複雜的數據集,然後加載它們以檢查一切是否正常,但是,這類bug幾乎不可能出現在RDB持久化中。爲了說得更清楚一點:Redis AOF是通過遞增地更新一個已經存在的狀態,像MySQL或者MongoDB一樣,而RDB快照是一次又一次地從頭開始創造一切,概念上更健壯。但是,1)要注意Redis每次重寫AOF時都是以當前數據集中的真實數據從頭開始,相對於一直追加的AOF文件(或者一次重寫讀取老的AOF文件而不是讀內存中的數據)對bug的免疫力更強。2)我們還沒有收到一份用戶在真實世界中檢測到崩潰的報告。
5.2.3 AOF持久性如何?
你可以配置 Redis 多久纔將數據 fsync 到磁盤一次。有三個選項:
- 每次有新命令追加到 AOF 文件時就執行一次 fsync :非常慢,也非常安全。
- 每秒 fsync 一次:足夠快(和使用 RDB 持久化差不多),並且在故障時只會丟失 1 秒鐘的數據。
- 從不 fsync :將數據交給操作系統來處理。更快,也更不安全的選擇。
推薦(並且也是默認)的措施爲每秒 fsync 一次, 這種 fsync 策略可以兼顧速度和安全性。 總是 fsync 的策略在實際使用中非常慢, 即使在 Redis 2.0 對相關的程序進行了改進之後仍是如此 —— 頻繁調用 fsync 註定了這種策略不可能快得起來。
6. redis事務
Redis 對事務的支持目前還比較簡單。redis 只能保證一個 client 發起 的事務中的命令可以連續的執行,而中間不會插入其他 client 的命令。由 於 redis 是單線程來處理所有 client 的請求的所以做到這點是很容易的。 一般情況下 redis 在接受到一個 client 發來的命令後會立即處理並 返回 處理結果,但是當一個 client 在一個連接中發出 multi 命令有,這個連接 會進入一個事務上下文,該連接後續的命令並不是立即執行,而是先放 到一個隊列中。當從此連接受到 exec 命令後,redis 會順序的執行隊列中 的所有命令。並將所有命令的運行結果打包到一起返回給 client.然後此 連接就 結束事務上下文。
6.1事務命令
#用於標記事物的開始
multi
# 在一個事務中執行所有先前放入隊列的命令, 然後恢復正常的連接狀態
exec
# 清楚所有先前在一個事物中放入隊列的命令, 然後恢復到正常的連接狀態
discard
# 當某個事物需要按條件執行時, 就要使用這個命令給設定的鍵爲受監控狀態
watch key [key ...]
# 清除所有先前爲一個事物監控的鍵
unwatch6.2 事務示例: 銀行轉賬
127.0.0.1:6379> set tom 1000
OK
127.0.0.1:6379> set mike 1000
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> decrby tom 100
QUEUED
127.0.0.1:6379> incrby mike 100
QUEUED
127.0.0.1:6379> exec
1) (integer) 900
2) (integer) 1100
127.0.0.1:6379> mget tom mike
1) "900"
2) "1100"6.4 watch
如果在事務執行之前這個(或這些) key 被其他命令所改動,那麼事務將被打斷。
示例: 買票
客戶端一:
127.0.0.1:6379> set ticket 1
OK
127.0.0.1:6379> set ling 1000
OK
127.0.0.1:6379> watch ticket
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> decr ticket
QUEUED
127.0.0.1:6379> decrby tom 100
QUEUED
客戶端二:
127.0.0.1:6379> get ticket
"1"
127.0.0.1:6379> decr ticket
(integer) 0客戶端一: 事務被打斷
127.0.0.1:6379> exec
(nil)
6.5 redis爲什麼不支持回滾
在瞭解事務的回滾的時候, 我們先要跳出事務的原子性來看待, redis爲了性能的關係, 並不是支持事務的回滾.
我們知道事務的原子性, 就是事務裏面如果全部成功, 要麼全部執行失敗.其實我們這裏要說的, 就是在執行exec的時候, 如果在執行過程中有語法報錯的, 或者中間有失敗的, 那執行過的, 就執行過了, 並不進行回滾操作.
但是discard命令還是可以清楚到以前的所有命令的
7. redis的分佈式鎖
7.1 鎖的處理:
- 單應用中使用鎖: (單進程多線程)
synchronize, ReentrantLock- 分佈式應用中使用鎖: (多進程多線程)
分佈式鎖是控制分佈式系統之間同步訪問共享資源的一種方式
7.2 分佈式鎖的實現方式
- 基於數據庫的樂觀鎖實現分佈式鎖
- 基於zookeeper的臨時節點實現分佈式鎖
- 基於redis的分佈式鎖
7.3 實現分佈式鎖
- 獲取鎖:
在set命令中, 有很多選項可以用來修改命令的行爲, 以下是set命令可用選項的基本語法
redis 127.0.0.1:6379>SET KEY VALUE [EX seconds] [PX milliseconds] [NX|XX]
- EX seconds 設置指定的到期時間(單位爲秒)
- PX milliseconds 設置指定的到期時間(單位毫秒)
- NX: 僅在鍵不存在時設置鍵
- XX: 只有在鍵已存在時設置方式1: 推介
private static final String LOCK_SUCCESS = "OK";
private static final String SET_IF_NOT_EXIST = "NX";
private static final String SET_WITH_EXPIRE_TIME = "PX";
public static boolean getLock(JedisCluster jedisCluster, String lockKey, String requestId, int expireTime) {
// NX: 保證互斥性
String result = jedisCluster.set(lockKey, requestId, SET_IF_NOT_EXIST, SET_WITH_EXPIRE_TIME, expireTime);
if (LOCK_SUCCESS.equals(result)) {
return true;
}
return false;
}方式2:
public static boolean getLock(String lockKey,String requestId,int expireTime) {
Long result = jedis.setnx(lockKey, requestId);
if(result == 1) {
jedis.expire(lockKey, expireTime);
return true;
}
return false;
}注意: 推介方式1, 因爲方式2中setnx和expire是兩個操作, 並不是一個原子操作, 如果setnx出現問題, 就是出現死鎖的情況, 所以推薦方式1
- 釋放鎖:
del命令實現
public static void releaseLock(String lockKey,String requestId) {
if (requestId.equals(jedis.get(lockKey))) {
jedis.del(lockKey);
}
}
8. redis的故障診斷與優化
8.1 常見緩存問題
8.1.1 緩存穿透
- 什麼叫緩存穿透?
一般的緩存系統,都是按照key去緩存查詢,如果不存在對應的value,就應該去後端系統查找(比如DB)。如果key對應的value是一定不存在的,並且對該key併發請求量很大,就會對後端系統造成很大的壓力。
也就是說,對不存在的key進行高併發訪問,導致數據庫壓力瞬間增大,這就叫做【緩存穿透】。
- 如何解決?
1:對查詢結果爲空的情況也進行緩存,緩存時間設置短一點,或者該key對應的數據insert了之後清理緩存。
2:對一定不存在的key進行過濾。可以把所有的可能存在的key放到一個大的Bitmap中,查詢時通過該bitmap過 濾。(布隆表達式)
8.1.2 緩存雪崩
- 什麼叫緩存雪崩
當緩存服務器重啓或者大量緩存集中在某一個時間段失效,這樣在失效的時候,也會給後端系統(比如DB)帶來很大壓 力。
- 如何解決
1:在緩存失效後,通過加鎖或者隊列來控制讀數據庫寫緩存的線程數量。比如對某個key只允許一個線程查詢數據和 寫緩存,其他線程等待。
2:不同的key,設置不同的過期時間,讓緩存失效的時間點儘量均勻。
3:做二級緩存,A1爲原始緩存,A2爲拷貝緩存,A1失效時,可以訪問A2,A1緩存失效時間設置爲短期,A2設置爲長 期(此點爲補充)
8.1.3 緩存擊穿
- 什麼叫做緩存擊穿
對於一些設置了過期時間的key,如果這些key可能會在某些時間點被超高併發地訪問,是一種非常“熱點”的數據。這 個時候,需要考慮一個問題:緩存被“擊穿”的問題,這個和緩存雪崩的區別在於這裏針對某一key緩存,前者則是很多key。
緩存在某個時間點過期的時候,恰好在這個時間點對這個Key有大量的併發請求過來,這些請求發現緩存過期一般都會 從後端DB加載數據並回設到緩存,這個時候大併發的請求可能會瞬間把後端DB壓垮。
- 如何解決
使用redis的setnx互斥鎖先進行判斷,這樣其他線程就處於等待狀態,保證不會有大併發操作去操作數據庫。
if(redis.sexnx()==1){
//先查詢緩存
//查詢數據庫
//加入緩存
}
8.2 啓動redis日誌功能
redis默認不記錄log文件, 需要在redis.conf文件修改logfile參數.如下:
- 日誌級別 loglevel notic
- 日誌路勁 logfile "/usr/local/redis/log/redis.log"
8.3 redis的監控狀態
8.3.1 RDB狀態監控
bin/redis-cli info |grep rdb_- rdb_changes_since_last_save表明上次RDB保存以後改變的key次數
- rdb_bgsave_in_progress 表示當前是否在進行 bgsave 操作,1 表示正在進行;0 表示沒有進行
- rdb_last_save_time 上次保存 RDB 文件的時間戳
- rdb_last_bgsave_time_sec 上次保存的耗時
- rdb_last_bgsave_status 上次保存的狀態
- rdb_current_bgsave_time_sec 目前保存 RDB 文件已花費的時間
8.3.2 aof的監控狀態
bin/redis-cli info |grep aof_- aof_enabledAOF文件是否啓用
- aof_rewrite_in_progress 表示當前是否在進行 AOF 日誌的重寫
- aof_rewrite_scheduled
- aof_last_rewrite_time_sec 上次寫入的時間戳
- aof_current_rewrite_time_sec:-1
- aof_last_bgrewrite_status:ok 上次寫入狀態
- aof_last_write_status:ok 上次寫入狀態
8.3.3 內存監控
bin/redis-cli info |grep mem- used_memory:13490096 //數據佔用了多少內存(字節)
- used_memory_human:12.87M //數據佔用了多少內存(帶單位的,可讀性好)
- used_memory_rss:13490096 //redis 佔用了多少內存
- used_memory_peak:15301192 //佔用內存的峯值(字節)
- used_memory_peak_human:14.59M //佔用內存的峯值(帶單位的,可讀性好)
- used_memory_lua:31744 //lua 引擎所佔用的內存大小(字節)
- mem_fragmentation_ratio:1.00 //內存碎片率
- mem_allocator:libc //redis 內存分配器版本,在編譯時指定的。有 libc、jemalloc、tcmalloc 這 3 種
8.4 redis慢查詢
8.4.1 慢查詢日誌
慢查詢日誌幫助開發和運維人員定位系統存在的慢操作。慢查詢日誌就是系統
在命令執行前後計算每條命令的執行時間,當超過預設閥值,就將這條命令的相關 信息(慢查詢 ID,發生時間戳,耗時,命令的詳細信息)記錄下來。
Redis 客戶端一條命令分爲如下四部分執行: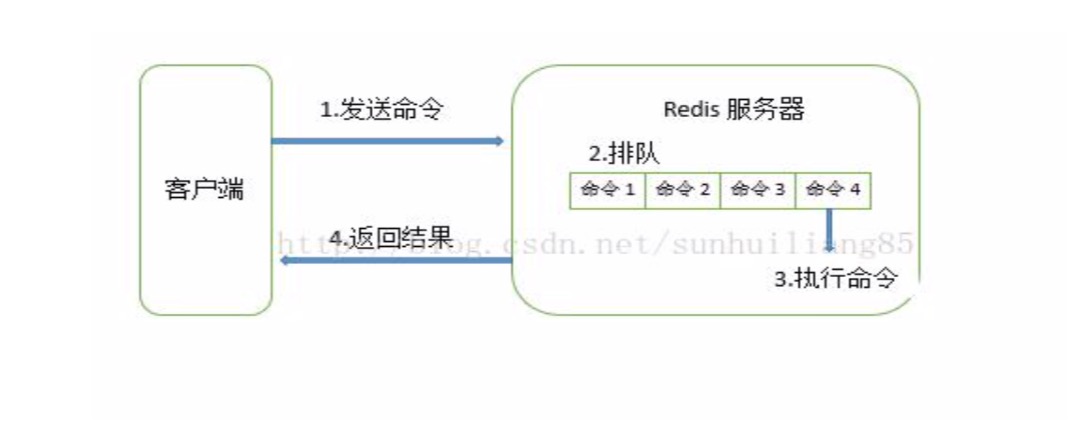
需要注意的是,慢查詢日誌只是統計步驟 3)執行命令的時間,所以慢查詢並不代 表客戶端沒有超時問題。需要注意的是,慢查詢日誌只是統計步驟 3)執行命令的時間, 所以慢查詢並不代表客戶端沒有超時問題。
8.4.2 慢查詢參數
-
慢查詢的預設閥值 slowlog-log-slower-than
- slowlog-log-slower-than參數就是預設閥值,1000,如果一條命令的執行時間超過 10000 微妙,那麼它將被記錄 在慢查詢日誌中。
- 如果slowlog-log-slower-than的值是0,則會記錄所有命令。
- 如果slowlog-log-slower-than的值小於0,則任何命令都不會記錄日誌
- 對於高流量的場景,如果執行命令的時間在 1 毫秒以上,那 麼 redis 最多可支撐 OPS(每秒操作次數)不到 1000,因此高 OPS 場景的 REDIS 建議設置爲 1 毫秒.
-
慢查詢日誌的長度slowlog-max-len
- slowlog-max-len只是說明了慢查詢日誌最多存儲多少條。Redis使用
一個列表來存儲慢查詢日誌,showlog-max-len 就是列表的最大長度。 當慢查詢日誌已經到達列表的最大長度時,又有慢查詢日誌要進入列 表,則最早插入列表的日誌將會被移出列表,新日誌被插入列表的末 尾。
- slowlog-max-len的設置建議, 線上環境建議調大慢查詢日誌的列表,記錄慢查詢日誌時 Redis 會對長命令做截斷操作,並不會佔用大量內存。增大慢查詢列表可 以減緩慢查詢被剔除出列表的可能性。例如線上可以設置爲 1000 以 上
8.4.3 慢查詢日誌的組成
慢查詢日誌由以下四個屬性組成:
標識 ID,發生時間戳,命令耗時,執行命令和參數
8.5 redis的pipeline(管道)
簡單來說,PipeLine(管道)就是“批處理”操作。 由於網絡開銷延遲,就算 redis server 端有很強的處理能力,也會由於收到的client 消息少,而造成吞吐量小。當 client 使用 pipelining 發送命令時,redis server 必須將部分請求放到隊列中(使用內存),執行完畢後一次性發送結果;如果發送 的命令很多的話,建議對返回的結果加標籤,當然這也會增加使用的內存。
Pipeline 在某些場景下非常有用,比如有多個 command 需要被“及時的”提 交,而且他們對相應結果沒有互相依賴,對結果響應也無需立即獲得,那麼 pipeline 就可以充當這種“批處理”的工具;而且在一定程度上,可以較大的提升性能,性 能提升的原因主要是 TCP 連接中減少了“交互往返”的時間。
應用場景: 特別是有for循環取值時, 建議使用pipeline
代碼示例:
# 自定義一個自己需要的類
List<Response<String>> resAll = new ArrayList();
// 獲取一個管道對象
Pipeline pipeline = jedisUtil.getReis().pipelined();
List<String> ids = new ArrayList();
ids.add("str1");
ids.add("str2");
ids.add("str3");
ids.forEach(id->{
Response<String> res = pipeline.get(id);
// 管道的對象結果都存在resAll中
resAll.add(res);
});
//pipeline.sync(); close內部有sync()方法調用
pipeline.close();
resAll.forEach(item -> {
System.out.println(Integer.valueof(res) + 100);
});8.6 redis的噩耗: 阻塞
8.6.1 耗時長命令造成阻塞
- keys, sort等命令
當redis的數據量達到一定級別後(比如20G),阻塞操作對性能的影響尤爲嚴重;keys命令用於查找所有符合給定模式 pattern 的 key,時間複雜度爲O(N), N 爲數據庫中 key 的數量。當數據庫中的個數達到千萬時,這個命令會造成讀寫線程阻塞數秒;
類似的命令有sunion sort等操作;
如果業務需求中一定要使用keys、sort等操作怎麼辦?
解決方案
在架構設計中,有“分流”一招,說的是將處理快的請求和處理慢的請求分離開來,否則,慢的影響到了快的,讓快的也快不起來;這在redis的設計中體現的非常明顯,redis的純內存操作,epoll非阻塞IO事件處理,這些快的放在一個線程中搞定,而持久化,AOF重寫、Master-slave同步數據這些耗時的操作就單開一個進程來處理,不要慢的影響到快的;同樣,既然需要使用keys這些耗時的操作,那麼我們就將它們剝離出去,比如單開一個redis slave結點,專門用於keys、sort等耗時的操作,這些查詢一般不會是線上的實時業務,查詢慢點就慢點,主要是能完成任務,而對於線上的耗時快的任務沒有影響
- smembers命令
smembers命令用於獲取集合全集,時間複雜度爲O(N),N爲集合中的數量;
如果一個集合中保存了千萬量級的數據,一次取回也會造成事件處理線程的長時間阻塞;
解決方案
和sort,keys等命令不一樣,smembers可能是線上實時應用場景中使用頻率非常高的一個命令,這裏分流一招並不適合,我們更多的需要從設計層面來考慮;
在設計時,我們可以控制集合的數量,將集合數一般保持在500個以內;
比如原來使用一個鍵來存儲一年的記錄,數據量大,我們可以使用12個鍵來分別保存12個月的記錄,或者365個鍵來保存每一天的記錄,將集合的規模控制在可接受的範圍;
如果不容易將集合劃分爲多個子集合,而堅持用一個大集合來存儲,那麼在取集合的時候可以考慮使用SRANDMEMBER key [count];隨機返回集合中的指定數量,當然,如果要遍歷集合中的所有元素,這個命令就不適合了;
- save命令
save命令使用事件處理線程進行數據的持久化;當數據量大的時候,會造成線程長時間阻塞(我們的生產上,reids內存中1個G保存需要12s左右),整個redis被block;
save阻塞了事件處理的線程,我們甚至無法使用redis-cli查看當前的系統狀態,造成“何時保存結束,目前保存了多少”這樣的信息都無從得知;
解決方案
推薦使用bgsave命令
8.7 redis持久化故障診斷
- 使用 Java 客戶端,循環插入 20 個 200M 大小的數據,程序如下:
- 檢查 RDB 的狀態信息
bin/redis-cli info |grep rdb_- 檢查日誌文件: redis.log

-
解決問題:
修改 vm.overcommit_memory 參數。關於 vm.overcommit_memory 不同的值說明:- 0 表示檢查是否有足夠的內存可用,如果是,允許分配;如果內存不夠,拒絕該請求,並返回一個錯誤給應用程序。
- 1 允許分配超出物理內存加上交換內存的請求
- 2 內核總是返回 true
由於 RDB 文件寫的時候 fork 一個子進程。相當於複製了一個內存鏡像。 當時系統的內存是 4G,而 redis 佔用了近 3G 的內存,因此肯定會報內存無法 分配。如果 「vm.overcommit_memory」設置爲 0,在可用內存不足的情況下, 就無法分配新的內存。如果 「vm.overcommit_memory」設置爲 1。 那麼 redis將使用交換內存。
- 方法一: 修改內核參數 vi /etc/sysctl。設置 vm.overcommit_memory = 1 然後執行 sysctl -p
- 方法二: 使用交換內存並不是一個完美的方案。最好的辦法是擴大物 理內存。
8.8 redis內存淘汰策略
8.8.1 最大緩存
在 redis 中,允許用戶設置最大使用內存大小maxmemory,默認爲0,沒有指定最大緩存,如果有新的數據添 加,超過最大內存,則會使redis崩潰,所以一定要設置.
redis 內存數據集大小上升到一定大小的時候,就會實行數據淘汰策略
8.8.2 淘汰策略
redis淘汰策略配置: maxmemory-policy voltile-lru,支持熱配置
Redis提供6種數據淘汰策略:
- voltile-lru:從已設置過期時間的數據集(server.db[i].expires)中挑選最近最少使用的數據淘汰
- volatile-ttl:從已設置過期時間的數據集(server.db[i].expires)中挑選將要過期的數據淘汰
- volatile-random:從已設置過期時間的數據集(server.db[i].expires)中任意選擇數據淘汰
- allkeys-lru:從數據集(server.db[i].dict)中挑選最近最少使用的數據淘汰
- allkeys-random:從數據集(server.db[i].dict)中任意選擇數據淘汰
- no-enviction(驅逐):禁止驅逐數據
8.8.3 LRU原理
LRU( ,最近最少使用)算法根據數據的歷史訪問記錄來進行淘汰數據,其核心思想是“如 果數據最近被訪問過,那麼將來被訪問的機率也更高”。
9. redis的java客戶端
9.1 Jedis
9.1.1 maven配置
使用jedis需要引入jedis的jar包,下面提供了maven依賴
jedis.jar是封裝的包,commons-pool2.jar是管理連接的包
<!-- https://mvnrepository.com/artifact/redis.clients/jedis 客戶端-->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.commons/commons-pool2 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.5.0</version>
</dependency>9.1.2 配置文件
abc.data.redis.connection.appRedis1.database = 0
abc.data.redis.connection.appRedis1.timeout = 20000
# master的ip地址
abc.data.redis.connection.appRedis1.host = 1.1.1.1
abc.data.redis.connection.appRedis1.port = 6410
abc.data.redis.connection.appRedis1.password = 8bH4Ft82P2JjwFiV
# 哨兵地址
abc.data.redis.connection.appRedis1.nodes = 1.1.1.1,1.1.1.2,1.1.1.3
abc.data.redis.connection.appRedis1.master = sentinel-1.1.1.1-6410
abc.data.redis.connection.appRedis1.minIdle = 10
abc.data.redis.connection.appRedis1.maxActive = 500
abc.data.redis.connection.appRedis1.maxWait = 20000
abc.data.redis.connection.appRedis1.maxIdle = 2009.1.3 建立配置文件對應的類
@Component
@ConfigurationProperties(prefix = "abc.data.redis.connection.appRedis1")
@Data
public class RedisConfig {
/** 節點名稱 */
private String nodes;
/** master名稱 */
private String master;
/** 密碼 */
private String password;
/** 超時時長 */
private Integer timeout;
/** 最小空閒數量 */
private Integer minIdle;
/** 連接池的最大數據庫連接數 */
private Integer maxActive;
/** 最大建立連接等待時間 */
private Integer maxWait;
/** 最大空閒數量 */
private Integer maxIdle;
}9.1.4 編寫連接池工具類
package com.test.jedis;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
public class JedisUtils {
@Resource
private RedisConfig redisConfig;
private JedisSentinelPool jedisSentinelPool;
// 1、定義一個連接池對象
private final static JedisPool POOL;
static {
try{
// 初始化
// 1、設置連接池的配置對象
JedisPoolConfig config = new JedisPoolConfig();
JedisPoolConfig config = new JedisPoolConfig();
//設置最大空閒數量
config.setMaxIdle(redisConfig.getMaxIdle());
//設置最小空閒數量
config.setMinIdle(redisConfig.getMinIdle());
//設置最長等待時間
config.setMaxWaitMillis(redisConfig.getMaxWait());
//設置連接池的最大數據庫連接數
config.setMaxTotal(redisConfig.getMaxActive());
//是否在從池中取出連接前進行檢驗,如果檢驗失敗,則從池中去除連接並嘗試取出另一個
config.setTestOnBorrow(true);
//是否進行有效性檢查
config.setTestOnReturn(true);
//在空閒時檢查有效性, 默認false
config.setTestWhileIdle(true);
// 2、設置連接池對象(連接的是哨兵redis)
String[] split = redisConfig.getNodes().split(",");
Set<String> nodeSet = Sets.newHashSet(split);
jedisSentinelPool = new JedisSentinelPool(redisConfig.getMaster(), nodeSet, jedisPoolConfig, redisConfig.getTimeout(), redisConfig.getPassword());
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 從連接池中獲取連接
*/
public synchronized static Jedis getJedis() {
try {
if (jedisSentinelPool != null) return jedisSentinelPool.getResource();
} catch (Exception e) {
e.printStackTrace();
}
return null;
return POOL.getResource();
}
}9.1.4 在開發過程中遇到的坑
java.net.SocketException: Broken pipe
原因: 在開發過程中, 混用了pipeline和jedis,
即在上面的pipeline的使用過程中, 還沒有全部取完pipeline的數據, 在其中就使用了jedis, 推介在架構設計上分開使用.
9.2 redisTemplate
9.2.1 maven 配置
<!-- springboot整合redis -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency> 9.2.2 application.properties配置Redis
spring.redis.host=127.0.0.1
spring.redis.port=6379
spring.redis.password=1239.2.3 使用示例
public class StudentServiceImpl implements StudentService {
@Autowired
private RedisTemplate<String,Object> redisTemplate;
public List<Student> getAllStudent() {
//查詢緩存
List<Student> studentList= (List<Student>)redisTemplate.opsForValue().get("allStudents");
if(null == studentList) {
//緩存爲空,查詢一遍數據庫
studentList = studentMapper.selectAllStudent();
//把數據庫查詢出來數據,放入Redis中
redisTemplate.opsForValue().set("allStudents",studentList);
}
return studentList;
}
}9.2.4 redisTemplate方法
其實如果經常寫程序, 簡單看一下方法名字, 大概就知道做什麼的啦!
如果大家想學習這方面的內容, 後期我會整理在自己的公衆號上, 發佈出來,請大家多多關注.
如果你覺得我寫的不錯, 或者想和我多交流, 就掃一掃關注我吧, 本人公衆號stormling