




【1、HashMap的工作原理?】
答:
A、HashMap基於Hashing原理,通過put()和get()方法存儲與獲取對象。
B、我們將值傳遞給put()方法,它調用鍵對象的hashCode()方法來計算hashcode,然後找到bucket位置來存儲對象。
C、獲取對象時,通過鍵對象的equals()方法找到正確的鍵值對,然後返回值對象。
D、HashMap使用鏈表來解決碰撞問題,當發生碰撞了,對象將會儲存存在鏈表的下一個節點。
E、HashMap在每個鏈表節點中存儲鍵值對對象。
【2、什麼是Hashing原理?】
散列法(Hashing)是一種將字符組成的字符換轉換爲固定長度的數值或索引的方法,稱爲散列法,也叫哈希法。
由於通過更短的哈希值比用原來的值進行數據庫搜索更快,這種方法一般用在數據庫中建立索引進行搜索,同時還用在各種解密算法中。
【3、HashMap中的bucket位置是什麼?】
答:HashMap及其子類,採用Hash算法來決定集合中元素的存儲位置。當系統開始初始化HashMap時,系統會創建一個長度爲capacity的Entry數組。
這個數組裏可以存儲元素的位置被稱爲bucket(桶)。每個bucket都有指定索引,系統可以根據其索引快速訪問該bucket裏存儲的元素。
HashMap的每個bucket(桶)只存儲一個元素Entry,由於Entry對象可以包含一個引用變量,也就是Entry指向另一個Entry依次類推,就形成了一個鏈。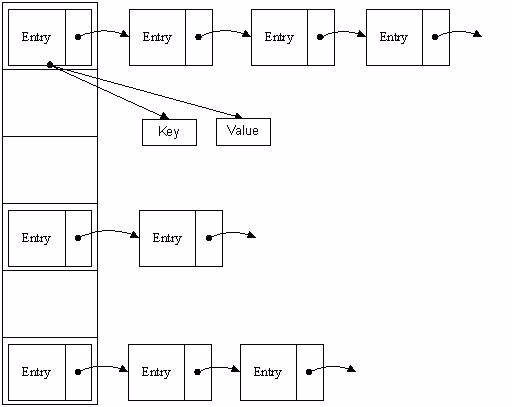
【4、HashMap的讀取實現?】
答:當HashMap的每個bucket裏面只存儲一個Entry,也就是沒有通過指針產生Entry鏈時,此時HashMap具有最好的性能。
當程序取出對應的value時,系統只要先計算出key的hashcode返回值,根據hashode返回值找到該key在table數組中的索引,然後取出索引處的Entry,返回給可以對應的value即可。
public V get(Object key) {
// 如果 key 是 null,調用 getForNullKey 取出對應的 value
if (key == null)
return getForNullKey();
// 根據該 key 的 hashCode 值計算它的 hash 碼
int hash = hash(key.hashCode());
// 直接取出 table 數組中指定索引處的值,
for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next){
Object k;
// 如果該 Entry 的 key 與被搜索 key 相同
if (e.hash == hash && ((k = e.key) == key
|| key.equals(k)))
return e.value;
}
return null;
} 如果HashMap的每個桶裏只有一個Entry時,HashMap可以根據索引快速的取出桶裏的Entry。
在碰撞問題下,單個桶裏存儲的不是一個Entry,而是一個Entry鏈,系統只有按順序遍歷每個Entry,知道找到目標Entry爲止。
HashMap在底層將key-value作爲一個整體,進行處理。這個整體就是Entry對象。HashMap底層採用一個Entry[]數組來保存所有的key-value。
當需要存儲一個Entry對象時,會根據Hash算法來決定其存儲位置;
先判斷該位置上有沒有Entry,沒有的話就創建一個Entry對象,再在這個位置上插入;
如果有Entry的話,通過鏈表的遍歷方式去逐個遍歷,通過Equals方法將key和已有的key進行比較,看看有沒有已經存在的key,有的話用新的value替換之前的value;如果沒有則在table[i]插入該Entry,把原來的table[i]位置上的Entry賦值給新的Entry的next。所以新的Entry插入的位置永遠是鏈表的最前面。
當需要取出一個Entry對象時,會根據Hash算法找到其存儲位置,直接取出Entry。
【5、當兩個不同的鍵對象的hashcode相同會怎樣?】
答:會儲存在同一個bucket位置的鏈表中。鍵對象的equals()方法用來找到鍵值對。
【6、什麼是HashTable?】
答:哈希表(HashTable)又叫做散列表,是根據關鍵碼值(即鍵值對)而直接訪問的數據結構。也就是說,它通過把關鍵碼映射到表中一個位置來訪問記錄,以加快查找速度
【7、HashMap和Hashtable的區別?】
答:1、繼承的父類不同
Hashtable繼承自Dictionary類,而HashMap繼承自AbstractMap類。但二者都實現了Map接口。
2、線程安全性不同
hashmap:此實現不是同步的。如果多個線程同時訪問一個哈希映射,而其中至少一個線程從結構上修改了該映射,則它必須保持外部同步。
HashMap和Hashtable都實現了Map接口,但決定用哪一個之前先要弄清楚它們之間的分別。主要的區別有:線程安全性,同步(synchronization),以及速度。
HashMap幾乎可以等價於Hashtable,除了HashMap是非synchronized的,並可以接受null(HashMap可以接受爲null的鍵值(key)和值(value),而Hashtable則不行)。
HashMap是非synchronized,而Hashtable是synchronized,這意味着Hashtable是線程安全的,多個線程可以共享一個Hashtable;而如果沒有正確的同步的話,多個線程是不能共享HashMap的。
HashMap不能保證隨着時間的推移Map中的元素次序是不變的。
3、key和value是否允許null值
Hashtable中,key和value都不允許出現null值。
但是如果在Hashtable中有類似put(null,null)的操作,編譯同樣可以通過,因爲key和value都是Object類型,但運行時會拋出NullPointerException異常,這是JDK的規範規定的。
HashMap中,null可以作爲鍵,這樣的鍵只有一個;可以有一個或多個鍵所對應的值爲null。
當get()方法返回null值時,可能是 HashMap中沒有該鍵,也可能使該鍵所對應的值爲null。因此,在HashMap中不能由get()方法來判斷HashMap中是否存在某個鍵, 而應該用containsKey()方法來判斷。
【8、什麼是HashSet?】
HashSet實現了Set接口,它不允許集合中有重複的值,當我們提到HashSet時,第一件事情就是在將對象存儲在HashSet之前,要先確保對象重寫equals()和hashCode()方法,這樣才能比較對象的值是否相等,以確保set中沒有儲存相等的對象。如果我們沒有重寫這兩個方法,將會使用這個方法的默認實現。public boolean add(Object o)方法用來在Set中添加元素,當元素值重複時則會立即返回false,如果成功添加的話會返回true。
【9、HashMap與HashSet的區別?】
答:
【10、HashMap中的負載因子0.75是啥意思?】
答:HashMap中默認的容量是16,負載因子爲0.75。由於集合在使用的過程中,不斷的存放數據,當存放的數量達到了16*0.75 = 12的時候就需要把當前的16容量進行擴容。擴容涉及到rehash,複製數據等操作,很消耗性能的。
【11、ConcurrentHashMap】
答:ConcurrentHashMap是Java中的一個線程安全且高效的HashMap實現。平時涉及高併發如果要用map結構,那第一時間想到的就是它。
1、ConcurrentHashMap在JDK8裏結構:
它的優點:結合了HashMap和HashTable。
它的兩個靜態內部類:HsahEntry和segment
它含有16個segment: ConcurrentHashMap將hash表分爲16個桶(默認值),諸如get,put,remove等常用操作只鎖當前需要用到的桶。
它的get方法:count>0,hash找到HashEntry,hash相等並且key相同,若取value爲null,加鎖重新獲取。
它的remove方法:加鎖,每刪除一個元素就將那之前的元素克隆一邊。因爲設置爲第一次next之後不能再改變。
它的size()方法:2次不鎖住segment方式統計各個segment的大小,若count發生變化,採用加鎖方式統計。modCount變量,在put,remove和clean方法裏操作元素,modcount加1.
【12、什麼是紅黑樹算法?】
答: 紅黑樹又稱紅-黑二叉樹,它首先是一顆二叉樹,它具體二叉樹所有的特性。同時紅黑樹更是一顆自平衡的排序二叉樹。
基本的二叉樹都需要滿足一個基本性質,樹中的任何節點的值大於它的左側子節點,且小於右側子節點,這樣使得樹的檢索效率大大提高。
但是二叉樹非常容易失衡(一邊倒),這樣會導致檢索效率大大降低。因此出現了一系列的算法,像:AVL、SBT、伸展樹、TREAP、紅黑樹等。
這樣二叉樹就平衡了,它的左右兩個子樹的高度差絕對值不超過1,左右都是一顆平衡二叉樹。【後續跟進此類型的算法...】
【13、什麼是TreeMap?】
答:TreeMap繼承AbstractMap,實現NavigableMap、Cloneable、Serializable三個接口。其中AbstractMap表明TreeMap爲一個Map即支持key-value的集合, NavigableMap(更多)則意味着它支持一系列的導航方法,具備針對給定搜索目標返回最接近匹配項的導航方法 。
【1】TreeMap中的元素默認按照keys的自然排序排列。(對Integer來說,其自然排序就是數字的升序;對String來說,其自然排序就是按照字母表排序)
//創建一個空集合,按照自然順序排列
TreeMap<Integer, String> treeMap = new TreeMap<>();
//創建一個空TreeMap,按照指定的comparator排序
TreeMap<Integer, String> map = new TreeMap<>(Comparator.reverseOrder());
map.put(3, "val");
map.put(2, "val");
map.put(1, "val");
map.put(5, "val");
map.put(4, "val");
System.out.println(map); // {5=val, 4=val, 3=val, 2=val, 1=val}
//map創建一個TreeMap,keys按照自然排序
Map<Integer, String> map = new HashMap<>();
map.put(1, "val");
map.put(1, "val");
map.put(5, "val");
map.put(4, "val");
TreeMap<Integer, String> treeMap = new TreeMap<>(map);