




來自:http://pda.readthedocs.org/en/latest/chp4.html
NumPy 是 Numerical Python 的簡稱,是高性能計算和數據分析的基礎包。本書中幾乎所有高級工具都是建立在它的基礎之上,下面是它所能做的一些事情:
- ndarray,快速和節省空間的多維數組,提供數組化的算術運算和高級的 廣播 功能。
- 使用標準數學函數對整個數組的數據進行快速運算,而不需要編寫循環。
- 讀取/寫入磁盤上的陣列數據和操作存儲器映像文件的工具。
- 線性代數,隨機數生成,和傅里葉變換的能力。
- 集成C,C++,Fortran代碼的工具。
從生態系統的角度看,最後一點是最爲重要的。因爲NumPy 提供了易用的C API,它可以很容易的將數據傳遞到使用低級語言編寫的外部庫,也可以使外部庫返回NumPy數組數據到Python。 這一特性使得Python成爲包裝傳統的C/C++/Fortran代碼庫,並給它們一個動態的、易於使用的接口的首選語言。
雖然NumPy本身並沒有提供非常高級的數據分析功能,但是瞭解NumPy的數組和麪向數組的計算將會幫助你高效的使用類似於pandas這樣的工具。 如果你是Python新手,並且只希望使用pandas來處理你手邊的數據,隨時可以略過這一章。 更多的NumPy的特性例如廣播,請見 第12章 。
對於大多數的數據分析應用來說,我關注的主要功能是:
- 快速的矢量化數組操作:數據切割和清除,子集和過濾,轉化和任何其它類型的計算
- 通用的數組算法,例如:sorting,unique和set操作
- 有效的描述性統計和聚集/彙總數據
- 數據對齊、關係數據的合併操作、異構數據的拼接操作
- 使用數組表達式來表示條件邏輯,而不是用帶有 if-elif-else 分支的循環來表示
- 組間數據的操作(聚合,轉換,功能應用)。關於這一點詳見 第5章
雖然NumPy提供了這些操作的計算功能,但你或許希望使用pandas作爲大多數數據分析的基礎(特別是結構化或表格數據),因爲它提供了一個豐富的,高級的接口使得常見的數據任務非常簡潔和簡單。 pandas也提供了更多的一些特定領域的功能,如時間數組操作,這是NumPy所沒有的。
1.1. NumPy ndarray:多維數組對象
NumPy的一個關鍵特性是它的N維數組對象(ndarray),它在Python中是一個大型數據集的快速的,靈活的容器。 數組使你能夠在整個數據塊上進行數學運算,且與對應的純量元素間操作有相似的語法:
ndarray是一個同種類數據的多維容器,也就是說,它的所有元素都是同類型的。每一個數組都有一個 shape(表示它每一維大小的元組)和 dtype (一個描述數組數據類型的對象):
本章將介紹ndarray的基礎知識,並足以應對本書剩下的部分。 雖然對於許多的數據分析應用來說不必要對NumPy有深入的理解,但是精通面向數組編程和思想是成爲一名科學的Python大師的關鍵一步。
1.1.1. 創建ndarray
最簡單的創建數組的方式是使用 array 函數。它接受任何數組對象(包括其它數組),產生一個包含所傳遞的數據的新NumPy數組。例如,列表就是一個很好的用於轉換的候選:
嵌套序列,如等長列表的列表,將會轉化爲一個多維數組:
除非明確指定(在此以後會更多), np.array 試圖推斷一個好的數據類型給它所創建的數組。數據類型存儲在一個特定的 dtype 的對象中;例如,在上面的兩個例子中,我們有:
除 np.array 之外,還有許多函數來創建新的數組。例如, zeros 和 ones 使用給定的長度或形狀分別的創建0‘s 和 1‘s數組。 empty 會創建一個沒有使用特定值來初始化的數組。給這些方法傳遞一個元組作爲形狀來創建高維數組:
arange 是Python內建 range 函數的數組版本:
表格4-1 是一個用於構建數組的標準函數的清單。
| 函數 | 描述 |
|---|---|
| array | 轉換輸入數據(列表,數組或其它序列類型)到一個ndarray,可以推斷一個dtype或明確的設置一個dtype。默認拷貝輸入數據。 |
| asarray | 轉換輸入爲一個ndarray,當輸入已經是一個ndarray時就不拷貝。 |
| arange | 同內建的range函數,但不返回列表而是一個ndarray |
| ones, ones_like | 根據提供的shape和dtype產生一個全1的數組。ones_like使用另一歌數組爲入參,產生一個shape和dtype都相同的數組。 |
| zeros, zeros_like | 同ones和ones_like,但是生成全0的數組 |
| empty, enpty_like | 通過分配新內存來構造新的數組,但不同與ones 和 zeros,不初始任何值。 |
| eye, identity | 生成一個NxN的單位方陣(對角線上爲1,其它地方爲0) |
1.1.2. ndarray的數據類型
數據類型或dtype是一個特別的對象,保存了ndarray如何解釋一塊內存爲特定類型數據的信息:
Dtypes是使NumPy如此強大和靈活的一部分。在大多數情況下,它們直接映射到底層的機器表示,這是的很容易地讀取和寫入二進制流到磁盤上,也能鏈接低級語言,如C 或Fortran編寫的代碼。數值表示的dtypes以相同的方式命名:一個類型名,如 folt 或 int ,後面跟着一個表示數字有多少位的數字。一個標準的雙精度浮點值(它是Python的 float 對象的底層表示)佔據8字節或64位。因此,這一類型在NumPy中被認爲是float64 。見 表格4-2 是一個NumPy支持的全部數據類型的清單。
| 類型 | 類型碼 | 描述 |
|---|---|---|
| 類型 | 類型碼 | 描述 |
| int8, uint8 | i1, u1 | 有符號和無符號8位(1字節)整數類型 |
| int16, uint16 | i2, u2 | 有符號和無符號16位整數類型 |
| int32, uint32 | i4, u4 | 有符號和無符號32位整數類型 |
| int64, uint64 | i8, u8 | 有符號和無符號64位整數類型 |
| float16 | f2 | 半精度浮點類型 |
| float32 | f4 or f | 標準精度浮點。與C的 float 兼容 |
| float64, float128 | f8 or d | 標準雙精度浮點。與C的 double 和Python 的 folat 對象兼容 |
| float128 | f16 or g | 擴展精度浮點 |
| complex64, complex128, complex256 | c8, c16, c32 | 分別使用兩個32,64,128位浮點表示的複數 |
| bool | ? | 布爾值,存儲 True 和 False |
| object | O | Python對象類型 |
| string_ | S | 定長字符竄類型(每字符一字節)。例如,爲了生成長度爲10的字符竄,使用 ‘S10’ |
| unicode_ | f16 or g | 擴展精度浮點(字節書依賴平臺)。同 string_ 有相同的語義規範(例如:``U10`` ) |
你可以使用ndarray的 astype 方法顯示的把一個數組的dtype轉換或 投射 到另外的類型:
在這個例子中,整形被轉換到浮點型。如果把浮點數轉換到整形dtype,小數部分將會被截斷:
你可能有一個字符竄數組表示的數字,可以使用 astype 把它們轉換到數字的形式:
如果因爲某些原因(如一個字符竄不能轉換到 float64 )轉換失敗了,將會引起一個 TypeError 。正如你所看見的,我有一些懶,使用 float 而不是 np.float64 ;NumPy會足夠聰明的把Python的類型對應到等價的dtypes。
你也可以使用dtype的另一個屬性:
你也可以使用速記的類型碼字符竄來指定一個dtype:
1.1.3. 數組和純量間的操作
數組非常重要,因爲它們使你不使用循環就可以在數據上進行一系列操作。 這通常被叫做矢量化。相同大小的數組間的算術運算,其操作作用在對應的元素上:
純量的算術操作正如你期望的一樣,把操作值作用於每一個元素:
在不同大小的數組見的操作被叫做 broadcasting ,將在 第12章 詳細討論。深入的瞭解broadcasting在本書的多數地方是不必要的。
1.1.4. 基本的索引和切片
NumPy的索引是一個內容豐富的主題,因爲有許多方法可以使你在你的數據中選取一個子集或單個元素。一維的數組很簡單,表面上它們的行爲類似於Python的列表:
如你所見,當你給一個切片賦一純量值,如 arr[5:8] = 12 所示,該值被傳送(或 傳播 )到整個選擇區域。與列表的第一個重要的區別是數組的切片在原來的數組上(不生成新的數組)。這意味着數據不會被拷貝,且對切片的任何修改都會影響源數組:
如果你是使用NumPy的新手,這一點回事你感到驚訝,尤其當你使用過其它數組編程語言,它們非常熱衷於拷貝數據。請記住,NumPy是設計用來處理大數據的情況,你可以想象如果NumPy堅持使用拷貝數據將會出現的性能和內存問題。
對於高維數組,你會有更多選項。在兩維的數組,每一個索引的元素將不再是一個純量,而是一個一維數組:
因此,單個元素可以遞歸的訪問,但是這會做多一點的工作。不過,你可以使用一個逗號分隔的索引列表來選擇單個元素。因此,下面的操作是等價的:
見 NumPy數組的索引,是在二維數組上的索引圖例。

NumPy數組的索引
在多維數組中,如果你省略了後面的索引,返回的對象將會是一個較低維的ndarray,它包括較高維度的所有數據。因此,在 2*2*3 的數組 arr3d 中
arr3d[0] 是一個 2*3 的數組:
純量值和數組都可以給 arr3d[0] 賦值:
類似的, arr3d[1, 0] 給你那些索引以 (1, 0) 開始的值,形成了一個1維數組:
請注意,在所有的情況下,被選中的子節返回的數組總是數組視窗。
1.1.4.1. 帶切片的索引
如同一維對象,例如Python的列表,ndarrys可以使用熟悉的語法來切片:
較高維的對象給你更多的選擇,你可以切割一個或多個座標座標軸,並且可以混合整數。對上面的2維數組,arr2d ,對它的切片有些不同:
正如你所見,它沿着 0 座標座標軸(第一個座標座標軸)切片。因此,一個切片沿着一個座標座標軸向選擇一個範圍的元素。你可以傳遞多個切片,就像你傳遞多個索引一樣:
象這樣切片時,你得到的總是相同維數的數組視窗。通過混合整形索引和切片,你可以得到較低維的切片:
見 兩維數組切片 圖解。注意,一個單一的冒號意味着取整個座標/座標軸,因此,你可以只切割更高維的座標軸,做法如下:
當然,給一個切片表達式賦值會對整個選擇賦值:
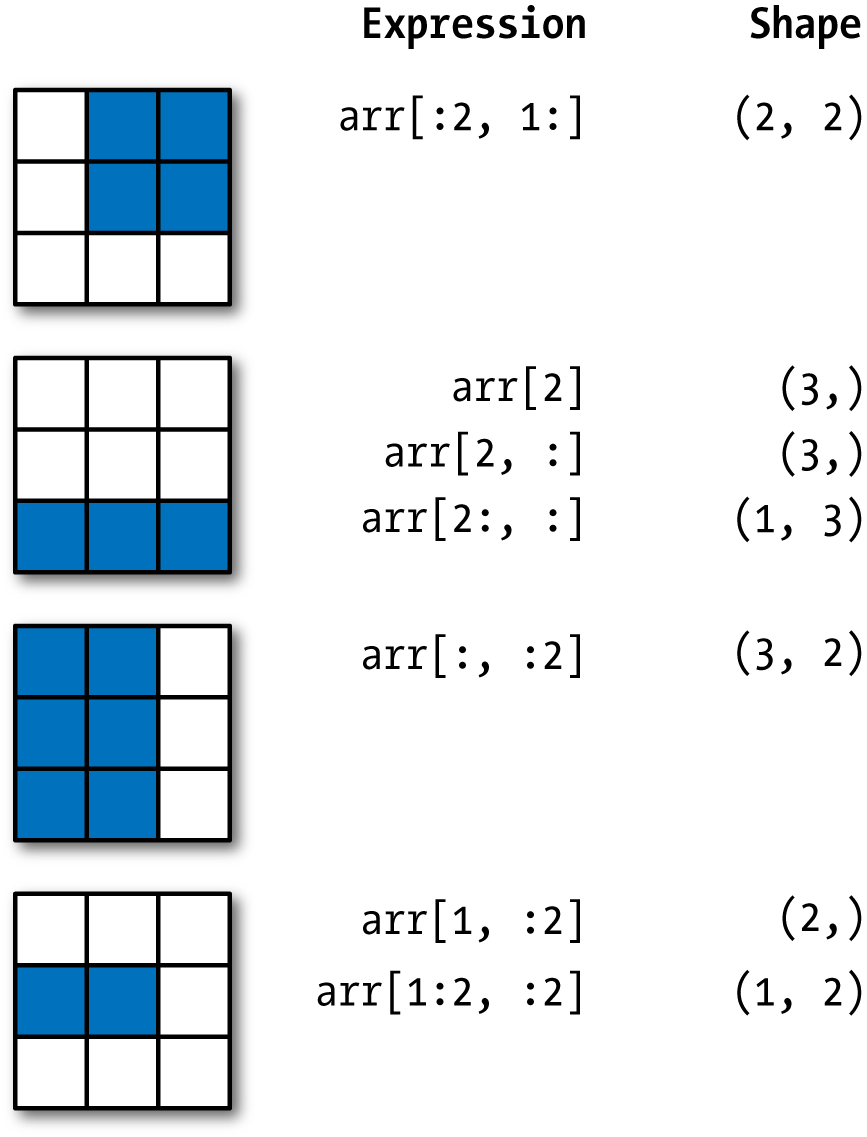
兩維數組切片
1.1.5. 布爾索引
讓我們來考慮一個例子,我們有一些數據在一個數組中和一個有重複名字的數組。我將會在這使用numpy.random 中的 randn 函數來產生一些隨機的正態分佈的數據:
假設每一個名字都和 data 數組中的一行對應。如果我們想要選擇與 ‘Bob’ 名字對應的所有行。象算術運算一樣,數組的比較操作(例如 == )也可以矢量化。因此, names 和 Bob 字符竄的比較會產生一個布爾數組:
當索引數組時可以傳遞這一布爾數組:
布爾數組必須和它索引的座標軸的長度相同。你甚至可以把布爾數組和切片或整數(或者整數序列,關於這一點後面會更多介紹)混合和匹配起來:
爲了選擇除了 ‘Bob’ 之外的所有東西,你可以使用 != 或用 - 對條件表達式取反:
使用布爾算術操作符如 & (and) 和 | (or)來結合多個布爾條件,下面是從三個名字中選取兩個的操作:
通過布爾索引從一個數組中選取數據 總是 會創建數據的一份拷貝,即使是返回的數組沒有改變。
通過布爾數組設置值工作於一種種常識性的方式。爲了設置 data 中所有的負值爲0,我們只需要:
使用一維布爾數組設置整行或列也非常簡單:
1.1.6. Fancy索引
Fancy 索引 是一個術語,被NumPy用來描述使用整形數組索引。假如我們有一個 8*4 的數組:
爲了選出一個有特定順序行的子集,你可以傳遞一個列表或整形ndarray來指定想要的順序:
很慶幸這個代碼做了你所期望的!使用負的索引從結尾選擇行:
傳遞多個索引數組有些微的不同;它選取一個一維數組,元素對應與索引的每一個元組:
花一點兒時間來看看剛剛發生了什麼:元素 (1, 0), (5, 3), (7, 1), 和(2, 2)被選擇了。 fancy索引的行爲與一些用戶(也包括我自己)可能期望的有所不同, 它因該是一個矩形區域,由選取的矩形的行和列組成。這裏有一個方法來得到它:
另一種方法是使用 np.ix_ 函數,將兩個以爲整形數組轉換爲位標,來選取一個正方形區域:
注意,fancy索引,不像切片,它總是拷貝數據到一個新的數組。
1.1.7. 轉置數組和交換座標軸
轉置是一種特殊形式的變形,類似的它會返回基礎數據的一個視窗,而不會拷貝任何東西。數組有transpose 方法和專門的 T 屬性:
當進行矩陣運算時,你常常會這樣做,像下面的例子一樣,使用 np.dot 計算內部矩陣來產生 XTX` :
對於更高維的數組, transpose 接受用於轉置的座標軸的號碼的一個元組(for extra mind bending):
使用 .T 的轉置,僅僅是交換座標軸的一個特殊的情況:
類似的 swapaxes 返回在數據上的一個視窗,而不進行拷貝。
1.2. 通用函數:快速的基於元素的數組函數
一個通用的函數,或者 ufunc ,是一個在ndarrays的數據上進行基於元素的操作的函數。你可以認爲它們是對簡單函數的一個快速矢量化封裝,它們接受一個或多個標量值併產生一個或多個標量值。
許多 ufuncs 都是基於元素的簡單變換,像 sqrt 或 exp :
這些歸諸於 unary ufuncs。其它的,例如 add 或 maximum ,接受兩個數組(因此,叫做 binary ufuncs)且返回一個數組:
雖然不常見,一個ufunc可以返回多個數組。 nodf 就是一個例子,它是Python內建 divmod 的矢量化的版本:它返回一個副點數數組的分數和整數部分:
見 表格4-3 和 表格4-4 是可用的ufuncs的清單。
| 函數 | 描述 |
|---|---|
| abs, fabs | 計算基於元素的整形,浮點或複數的絕對值。fabs對於沒有複數數據的快速版本 |
| sqrt | 計算每個元素的平方根。等價於 arr ** 0.5 |
| square | 計算每個元素的平方。等價於 arr ** 2 |
| exp | 計算每個元素的指數。 |
| log, log10, log2, log1p | 自然對數(基於e),基於10的對數,基於2的對數和 log(1 + x) |
| sign | 計算每個元素的符號:1(positive),0(zero), -1(negative) |
| ceil | 計算每個元素的天花板,即大於或等於每個元素的最小值 |
| floor | 計算每個元素的地板,即小於或等於每個元素的最大值 |
| rint | 圓整每個元素到最近的整數,保留dtype |
| modf | 分別返回分數和整數部分的數組 |
| isnan | 返回布爾數組標識哪些元素是 NaN (不是一個數) |
| isfinite, isinf | 分別返回布爾數組標識哪些元素是有限的(non-inf, non-NaN)或無限的 |
| cos, cosh, sin sinh, tan, tanh | regular 和 hyperbolic 三角函數 |
| arccos, arccosh, arcsin, arcsinh, arctan, arctanh | 反三角函數 |
| logical_not | 計算基於元素的非x的真值。等價於 -arr |
| 函數 | 描述 |
|---|---|
| add | 在數組中添加相應的元素 |
| substract | 在第一個數組中減去第二個數組 |
| multiply | 對數組元素相乘 |
| divide, floor_divide | 除和地板除(去掉餘數) |
| power | 使用第二個數組作爲指數提升第一個數組中的元素 |
| maximum, fmax | 基於元素的最大值。 fmax 忽略 NaN |
| minimum, fmin | 基於元素的最小值。 fmin 忽略 NaN |
| mod | 基於元素的模(取餘) |
| copysign | 拷貝第二個參數的符號到第一個參數 |
| greater, greater_equal, less, less_equal, not_equal | 基於元素的比較,產生布爾數組。等價於中綴操作符 >, >=, <, <=,==, != |
| logical_and, logical_or, logical_xor | 計算各個元素邏輯操作的真值。等價於中綴操作符 &, |, ^ |
1.3. 使用數組進行數據處理
使用NumPy可以是你能夠使用簡明的數組表達式而不是編寫循環表達許多種類的數據處理任務。這種使用數組表達式代替顯示循環通常被成爲“矢量化”。在一般情況下,矢量化數組操作比與之等價的純Python操作數度快一到兩(或更多)個等級,這對任何種類的數值計算有最大的影響。稍後,在chp12index中,我會講解broadcasting ,一個矢量化計算的強大方法。
作爲一個簡單示例,假如我們希望研究函數 sqrt(x\ :sup:`^`\ 2 + \ :sup:`^`\ 2) 穿過一個網格數據。np.meshgrid 函數接受兩個一維數組併產生兩個二維矩陣,其值對於兩個數組的所有 (x, y) 對:
現在,研究這個函數是一個簡單的事情,編寫與你可能寫過的相同的表達式:
見 繪製在網格上的函數,我使用 matplotlib 函數 imshow 創建一個了一個圖像,數據來源於上面的函數生成的二維數組。

繪製在網格上的函數
1.3.1. 用數組操作來表達條件邏輯
函數 numpy.where 是三元表達式 x if condition else y 的矢量化版本。假如我們有一個布爾數組和兩個值數組:
假如我們想要當對應的 cond 值爲 True 時,從 xarr 中獲取一個值,否則從 yarr 中獲取值。使用列表推到來做這件事,可能會像這樣:
這樣做會有許多問題。首先,對於大的數組,它不會很快(因爲所有的工作都是有純Python來做的)。其次,對於多維數組,它不能工作。使用 np.where 你可以像這樣非常簡潔的編寫:
np.where 的第一個和第二個參數不需要是數組;它們中的一個或兩個可以是純量。 在數據分析中 where的典型使用是生成一個新的數組,其值基於另一個數組。假如你有一個矩陣,其數據是隨機生成的,你想要把其中的正值替換爲2,負值替換爲-2,使用 np.where 非常容易:
傳遞到 where 的數組不僅僅只是大小相等的數組或純量。
使用一些小聰明,你可以使用 where 來表達更復雜的邏輯;考慮這個例子,我有兩個布爾數組, cond1 和cond2 ,並想根據4種布爾值來賦值:
也許可能不會很明顯,這個 for 循環可以轉換成一個嵌套的 where 表達式:
在這個特殊的例子中,我們還可以利用布爾表達式在計算中被當作0或1這一事實,因此可以使用算術運算來表達:
1.3.2. 數學和統計方法
一組數學函數,計算整個數組或一個軸向上數據的統計,和數組函數一樣是容易訪問的。聚合(通常被稱爲reductions ),如 sun , mean ,標準偏差 std 可以使用數組實例的方法,也可以使用頂層NumPy的函數:
像 mean 和 sun 函數可以有一個可選的 axis 參數,它對給定座標軸進行統計,結果數組將會減少一個維度:
像 cumsum 和 cumprod 這些函數並不聚集,而是產生一個 intermediate results 的數組:
表格4-5 是一個完整的清單。我們將在稍後的章節中看見關於這些函數的大量例子。
| 方法 | 描述 |
|---|---|
| sum | 對數組的所有或一個軸向上的元素求和。零長度的數組的和爲靈。 |
| mean | 算術平均值。靈長度的數組的均值爲NaN。 |
| std, var | 標準差和方差,有可選的調整自由度(默認值爲n)。 |
| min, max | 最大值和最小值 |
| argmin, argmax | 索引最小和最大元素。 |
| cumsum | 從0元素開始的累計和。 |
| cumprod | 從1元素開始的累計乘。 |
1.3.3. 布爾數組的方法
在上面的方法中布爾值被強制爲1( True )和0a( False )。因此, sum 經常被用來作爲對一個布爾數組中的True 計數的手段:
有兩個額外的方法, any 和 all ,對布爾數組尤其有用。 any 用來測試一個數組中是否有一個或更多的True ,而 all 用來測試所有的值是否爲 True :
這些方法這些方法也可以工作在非不而數組上,非零元素作爲 True 。
1.3.4. 排序
像Python的內建列表一樣,NumPy數組也可以使用 sort 方法就地排序:
多維數組可以通過傳遞一個座標軸數到 sort ,對一維截面上的數據進行就地排序:
頂層的 np.sort 函數返回一個經過排序後的數組拷貝,而不是就地修改。一個快速和骯髒的計算一個數組的位數是對它排序並選擇一個特定階層值:
關於使用NumPy的排序方法和更高級的技術,如間接排序,請見第12章。其它幾種有關排序的數據操作(例如,通過一列或多列對數據表排序)也會在 pandas 中找到。
1.3.5. Unique 和其它集合邏輯
Numpy有一些基本的針對一維ndarrays的集合操作。最常使用的一個可能是 np.unique ,它返回一個數組的經過排序的 unique 值:
np.unique 與純Python版本比較:
另一個函數 np.in1d ,測試一個數組的值和另一個的關係,返回一個布爾數組:
見 表格4-6 是關於集合函數的清單。
| unique(x) | 計算x單一的元素,並對結果排序 |
|---|---|
| intersect1d(x, y) | 計算x和y相同的元素,並對結果排序 |
| union1d | 結合x和y的元素,並對結果排序 |
| in1d(x, y) | 得到一個布爾數組指示x中的每個元素是否在y中 |
| setdiff1d(x, y) | 差集,在x中但不再y中的集合 |
| setxor1d(x, y) | 對稱差集,不同時在兩個數組中的元素 |
1.4. 關於數組的文件輸入和輸出
NumPy能夠保存數據到磁盤和從磁盤加載數據,不論數據是文本或二進制的。在後面的章節你可以學到使用pandas提供的工具來加載表格化的數據到內存。
1.4.1. 對磁盤上的二進制格式數組排序
np.save 和 np.load 是兩個主力功能,有效的保存和加載磁盤數據。數組默認保存爲未經過壓縮的原始二進制數據,文件擴展名爲 .npy :
如果文件路進並不是以 .npy 結尾,擴展名將會被自動加上。在磁盤上的數組可以使用 np.load 加載:
你可以使用 np.savez 並以關鍵字參數傳遞數組來保存多個數組到一個zip的歸檔文件中:
當你加載一個 .npz 文件時,會得到一個字典對象,它懶洋洋的加載單個數組:
1.4.2. 保存和加載文本文件
從文件加載文本是一個相當標準的任務。對一個新人來說,Python的文件加讀取和寫入函數的景象可能有一點兒混亂,因此我將主要集中在pandas的 read_csv 和 read_table 函數上。有時使用 np.loadtxt 或更專門的 np.genfromtxt 對於加載數據到 vanilla NumPy 數組是很有用的。
這些函數有許多選項,允許你指定不同的分割副,特定列的轉換函數,跳過某些行,和其它的事情。以這樣一個逗號分割文件(CSV)作爲一個簡單的例子:
它可以像這樣被加載到一個二維數組:
np.savatxt 執行相反的操作:寫入數組到一個界定文本文件中。 genfromtxt 與 loadtxt 相似,但是她是面向結構數組和缺失數據處理的;更多關於結構數組請見第12章 。
1.5. 線性代數
線性代數,如矩陣乘法,分解,行列式和其它的方陣數學,對任何一個數組庫來說都是重要的部分。不像一些語言,如 MATLAB ,使用 * 來乘兩個二維數組是基於元素的乘法,而不是矩陣點積。因此,有一個 dot 函數,是數組的一個方法和 numpy 命名空間中的一個函數,用來進行矩陣乘法運算:
在一個二維數組和合適大小的一維數組間的矩陣乘積的結果是一個一維數組:
numpy.linalg 有一個關於矩陣分解和像轉置和行列式等的一個標準集合。它們和其它語言(如: MATLAB和 R )一樣都是基於行業標準的 Fortran 庫,如 BLSA , LAPACK ,或可能的 Intel MKL (依賴於你的NumPy的編譯)實現的:
表格4-7 是一些常用的線性代數常用的函數清單。
科學Python社區希望有一天可以實現矩陣乘法的中綴操作符,提供一個語法上更好的使用 np.dot 的替代。但是現在只能這樣做。
| 函數 | 描述 |
|---|---|
| diag | 返回一個方陣的對角線(或非對角線)元素爲一個一維數組,或者轉換一個一維數組到一個方陣(非對角線元素爲零) |
| dot | 矩陣乘積 |
| trace | 計算對角線上元素的和 |
| det | 計算矩陣行列式 |
| eig | 計算方陣的特徵值和特徵向量 |
| inv | 計算方陣轉置 |
| pinv | 計算方陣 Moore-Penrose pseudo-inverse 的轉置 |
| qr | 計算 QR 分解 |
| svd | 計算奇異值分解(SVD) |
| solve | 求解線性系統方程 Ax = b 的x,其中A是一個方陣 |
| lstsq | 計算 y = Xb 的最小二乘解 |
1.6. 示例:隨機遊走
這是一個利用數組操作來模擬隨機遊走的示例程序。讓我們先來看一個簡單的隨機遊走的例子,從0開始,步長爲1和-1,且以相等的概率出現。一個純Python方式來實現一個單一的有1000步的隨機遊走的方式是使用內建的 random 模塊:
一個簡單的隨機遊走是使用這些隨機遊走的前100個值的例圖。

一個簡單的隨機遊走
你可能會發現 walk 簡單的把隨機步長累積起來並且可以可以使用一個數組表達式來計算。因此,我用np.random 模塊去1000次硬幣翻轉,設置它們爲1和-1,並計算累計和:
從這,我們可以開始沿着遊走軌跡來提取如最小或做大值的統計信息:
一個更復雜的統計數據是第一交叉時間,隨機遊走達到一個特定值的步值。這裏,我們可能想要知道過了多長時間的隨機遊走,從任一個方向到達距離原點0至少10步之遙。 ** np.ads(walk) >= 10 ** 會給我們一個布爾數組指示在哪兒遊走到達了或超過了10,但是我需要的是第一個10或-10的索引。可以使用 argmax 來計算,它返回布爾數組(最大值爲 True)中第一個最大值的索引:
注意在這使用 ragmax 並不是總是高效的,因爲它總是對數組做全掃描。在這一特殊情況下,一旦一個 True出現了,我們就知道它是一個最大值。
1.6.1. 一次模擬許多隨機遊走
如果你的目標是模擬許多隨機遊走,如5000個,你可以對上面的代碼稍作修改來生成所有的隨機遊動。numpy.random 函數,如果通過一個2元組,將產生一個二維數組繪製,我們可以跨越行一次計算5000個隨機遊動的累計和:
現在,我們可以獲得所有遊走的最大和最小值:
在這些遊走中,讓我們來計算到達30或-30的最短時間。這有一點兒狡猾,因爲不是所有的5000個遊走都能到達30。我們可以使用 any 方法來檢測:
我們可以使用這個布爾數組來選擇這些遊走中跨過絕對30的行,並調用 argmax 來取得座標軸1的交叉時間:
可以大膽的試驗其它的分佈的步長,而不是相等大小的硬幣翻轉。你只需要使用一個不同的隨機數生成函數,如 normal 來產生相同均值和標準偏差的正態分佈:

