




這裏介紹的SimHash算法很好的解決了VSM方法的缺陷,該方法最初由Google提出,用於網頁去重。
在介紹SimHash前,先大概說下傳統的Hash算法。我們知道,衡量一個Hash算法好壞的一個指標是隨機性。也被稱作簡單一致散列假設:每個關鍵字都等可能地散列到m個槽位中的任何一箇中去,並與其他的關鍵字已被散列到哪一個槽位中無關。說白了,就是讓散列的分佈儘量均勻,哪怕內容發生很小的變化,hash值也會發生很大的變化。因此,根據傳統的hash值無法得知被散列內容的相似程度。
下面正式談談SimHash算法。它的神奇之處就在 於它的簽名值除了提供原始內容是否相等的信息外,還能額外提供不相等的原始內容的差異程度的信息。SimHash的思想非常簡單,如圖所示:

算法描述如下:
輸入爲一個N維向量V,比如文本的特徵向量,每個特徵具有一定權重。輸出是一個C位的二進制簽名S。
1)初始化一個C維向量Q爲0,C位的二進制簽名S爲0。
2)對向量V中的每一個特徵,使用傳統的Hash算法計算出一個C位的散列值H。對1<=i<=C,
如果H的第i位爲1,則Q的第i個元素加上該特徵的權重;
否則,Q的第i個元素減去該特徵的權重。
3)如果Q的第i個元素大於0,則S的第i位爲1;否則爲0;
4)返回簽名S。
對每篇文檔根據SimHash算出簽名後,再計算兩個簽名的海明距離(兩個二進制異或後1的個數)即可。根據經驗值,對64位的SimHash,海明距離在3以內的可以認爲相似度比較高。
讀到這裏,你也許有一個疑惑:SimHash到底是怎樣解決VSM需要兩兩比較的缺陷呢?請繼續往下看。
假設對64位的SimHash,我們要找海明距離在3以內的所有簽名。我們可以把64位的二進制簽名均分成4塊,每塊16位。根據鴿巢原理(也成抽屜原理,見組合數學),如果兩個簽名的海明距離在3以內,它們必有一塊完全相同。你也許很興奮,說的這些你都懂。但是請不要忘了,我們事先是不知道具體是哪一塊完全相同,因此我們需要窮舉,對,你沒看錯,是窮舉。但是這裏的窮舉也就是4次而已。我們把上面分成的4塊中的每一個塊分別作爲前16位來進行查找。什麼意思呢?請看圖:
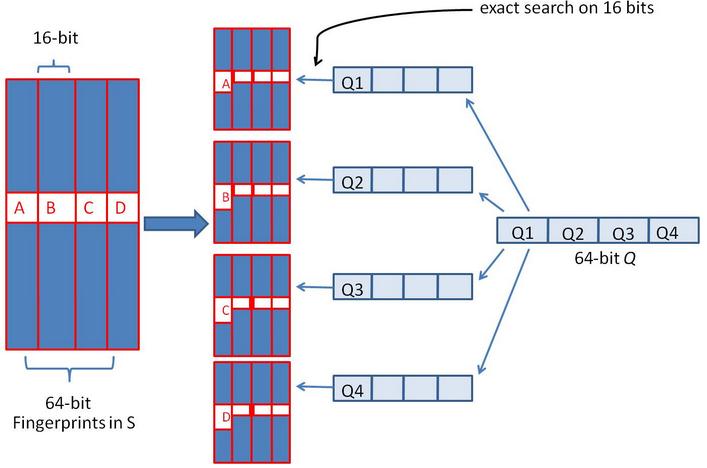
通過這幅圖,不知道你看明白沒有,反正我還沒有明白。下面讓咱們一起進一步探索。
舉個簡單的例子,對於8位的二進制簽名 01 10 00 11,咱們分別把每一塊拿出來,在所有的8位二進制簽名中查找前兩位分別是01,10,00,11的簽名。也許你要說,那不同樣需要兩兩比較嗎?對,常規意義下卻是如此。但是咱們可以做索引啊!按照前兩位進行索引,比如00111111和00101010放在一個簇中,10111111和10101010放在一個簇中。這下應該明白了吧。
如果庫中有2^34個(大概10億)簽名,那麼匹配上每個塊的結果最多有2^(34-16)=262144個候選結果,四個塊返回的總結果數爲4* 262144(大概100萬)。原本需要比較10億次,經過索引,大概就只需要處理100萬次了。由此可見,確實大大減少了計算量。
參考文獻:
1.《 Similarity Estimation Techniques From Rounding Algorithms》