




原文:6 Rules of Thumb for MongoDB Schema Design: Part 2
By William Zola, Lead Technical Support Engineer at MongoDB
在上一篇文章中我介紹了三種基本的設計方案:內嵌,子引用,父引用,同時說明了在選擇方案時需要考慮的兩個關鍵因素。
一對多中的多是否需要一個單獨的實體。
這個關係中集合的規模是一對很少,很多,還是非常多。
在掌握了以上基礎技術後,我將會介紹更爲高級的主題:雙向關聯和反範式化。
雙向關聯
如果你想讓你的設計更酷,你可以讓引用的“one”端和“many”端同時保存對方的引用。
以上一篇文章討論過的任務跟蹤系統爲例。有person和task兩個集合,one-to-n的關係是從person端到task端。在需要獲取person所有的task這個場景下需要在person這個對象中保存有task的id數組,如下面代碼所示。

在某些場景中這個應用需要顯示任務的列表(例如顯示一個多人協作項目中所有的任務),爲了能夠快速的獲取某個用戶負責的項目可以在task對象中嵌入附加的person引用關係。

這個方案具有所有的一對多方案的優缺點,但是通過添加附加的引用關係。在task文檔對象中添加額外的“owner”引用可以很快的找到某個task的所有者,但是如果想將一個task分配給其他person就需要更新引用中的person和task這兩個對象(熟悉關係數據庫的童鞋會發現這樣就沒法保證操作的原子性。當然,這對任務跟蹤系統來說並沒有什麼問題,但是你必須考慮你的用例是否能夠容忍)
在一對多關係中應用反範式
在你的設計中加入反範式,可以使你避免應用層級別的join讀取,當然,代價是這也會讓你在更新是需要操作更多數據。下面我會舉個例子來進行說明
反範式Many -< One
以產品和零件爲例,你可以在parts數組中冗餘存儲零件的名字。以下是沒有加入反範式設計的結構。

反範式化意味着你不需要執行一個應用層級別的join去顯示一個產品所有的零件名字,當然如果你同時還需要其他零件信息那這個應用層的join是避免不了的。

在使得獲取零件名字簡單的同時,執行一個應用層級別的join會和之前的代碼有些區別,具體如下:

反範式化在節省你讀的代價的同時會帶來更新的代價:如果你將零件的名字冗餘到產品的文檔對象中,那麼你想更改某個零件的名字你就必須同時更新所有包含這個零件的產品對象。
在一個讀比寫頻率高的多的系統裏,反範式是有使用的意義的。如果你很經常的需要高效的讀取冗餘的數據,但是幾乎不去變更他d話,那麼付出更新上的代價還是值得的。更新的頻率越高,這種設計方案的帶來的好處越少。
例如:假設零件的名字變化的頻率很低,但是零件的庫存變化很頻繁,那麼你可以冗餘零件的名字到產品對象中,但是別冗餘零件的庫存。
需要注意的是,一旦你冗餘了一個字段,那麼對於這個字段的更新將不在是原子的。和上面雙向引用的例子一樣,如果你在零件對象中更新了零件的名字,那麼更新產品對象中保存的名字字段前將會存在短時間的不一致。
反範式One -< Many
你也可以冗餘one端的數據到many端:

如果你冗餘產品的名字到零件表中,那麼一旦更新產品的名字就必須更新所有和這個產品有關的零件,這比起只更新一個產品對象來說代價明顯更大。這種情況下,更應該慎重的考慮讀寫頻率。
在一對很多的關係中應用反範式
在日誌系統這個一對許多的例子中也可以應用反範式化的技術。你可以將one端(主機對象)冗餘到日誌對象中,或者反之。
下面的例子將主機中的IP地址冗餘到日誌對象中。
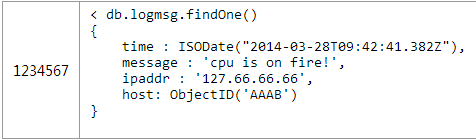
如果想獲取最近某個ip地址的日誌信息就變的很簡單,只需要一條語句而不是之前的兩條就能完成。

事實上,如果one端只有少量的信息存儲,你甚至可以全部冗餘存儲到多端上,合併兩個對象。
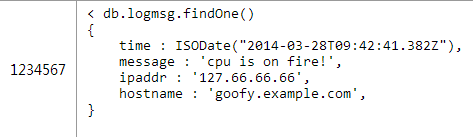
另一方面,也可以冗餘數據到one端。比如說你想在主機文檔中保存最近的1000條日誌,可以使用mongodb 2.4中新加入的$eache/$slice功能來保證list有序而且只保存1000條。
日誌對象保存在logmsg集合中,同時冗餘到hosts對象中。這樣即使hosts對象中超過1000條的數據也不會導致日誌對象丟失。
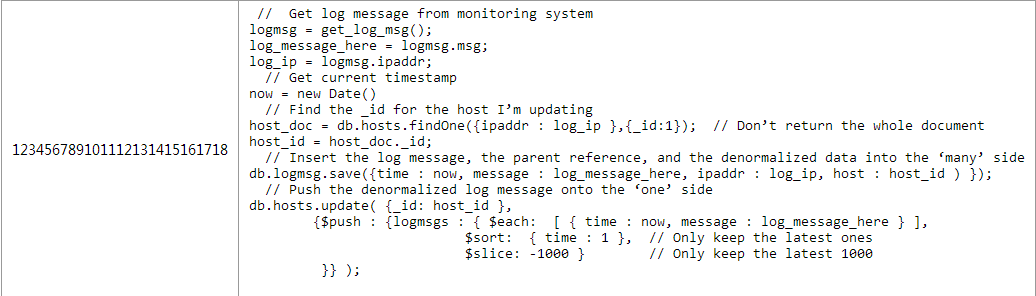
通過在查詢中使用投影參數 (類似{_id:1})的方式在不需要使用logmsgs數組的情況下避免獲取整個mongodb對象,1000個日誌信息帶來的網絡開銷是很大的。
在一對多的情況下,需要慎重的考慮讀和更新的頻率。冗餘日誌信息到主機文檔對象中只有在日誌對象幾乎不會發生更新的情況下才是個好的決定。
總結
在這篇文章裏,我介紹了對三種基礎方案:內嵌文檔,子引用,父引用的補充選擇。
使用雙向引用來優化你的數據庫架構,前提是你能接受無法原子更新的代價。
可以在引用關係中冗餘數據到one端或者N端。
在決定是否採用反範式化時需要考慮下面的因素:
你將無法對冗餘的數據進行原子更新。
只有讀寫比較高的情況下才應該採取反範式化的設計。
下次,我將會告訴你在面對這些方案時該如何抉擇。