




原文鏈接:
http://www.199it.com/archives/455137.html
本講座選自清華語音語言實驗室副主任王東於2016年1月19日在RONGv2.0系列——”語言語音語義與大數據技術”專場上所做的題爲《語音識別中的大數據與小數據學習》的演講。


謝謝大家。剛纔劉老師已經把很多的東西說得很清楚了,我覺得我已經可以走了J。但是既然來了,還是應該給大家說一說。劉老師在一個比較宏觀的場景下給大家介紹了整體的技術發展現狀,我稍微聚焦在一個特別小的地方,給大家一個參考。
我今天給大家報告的題目是語音識別中的大數據與小數據的學習。什麼意思呢?我們都需要大數據,今天的會也是個大數據的會。問題是很多時候我沒有那麼多大數據,怎麼辦?我們希望有一種辦法,在沒有很多的數據的時候,用小數據實現大數據的能力。

語音識別大家都知道很火爆,很多商業公司推出了語音識別服務。總體說來,語音識別其實是人工智能的一個分支,我們希望跟機器交互的時候能夠實現比較自然的交流,而不是通過文本打字,這在未來是一個必不可少的智能交互手段。
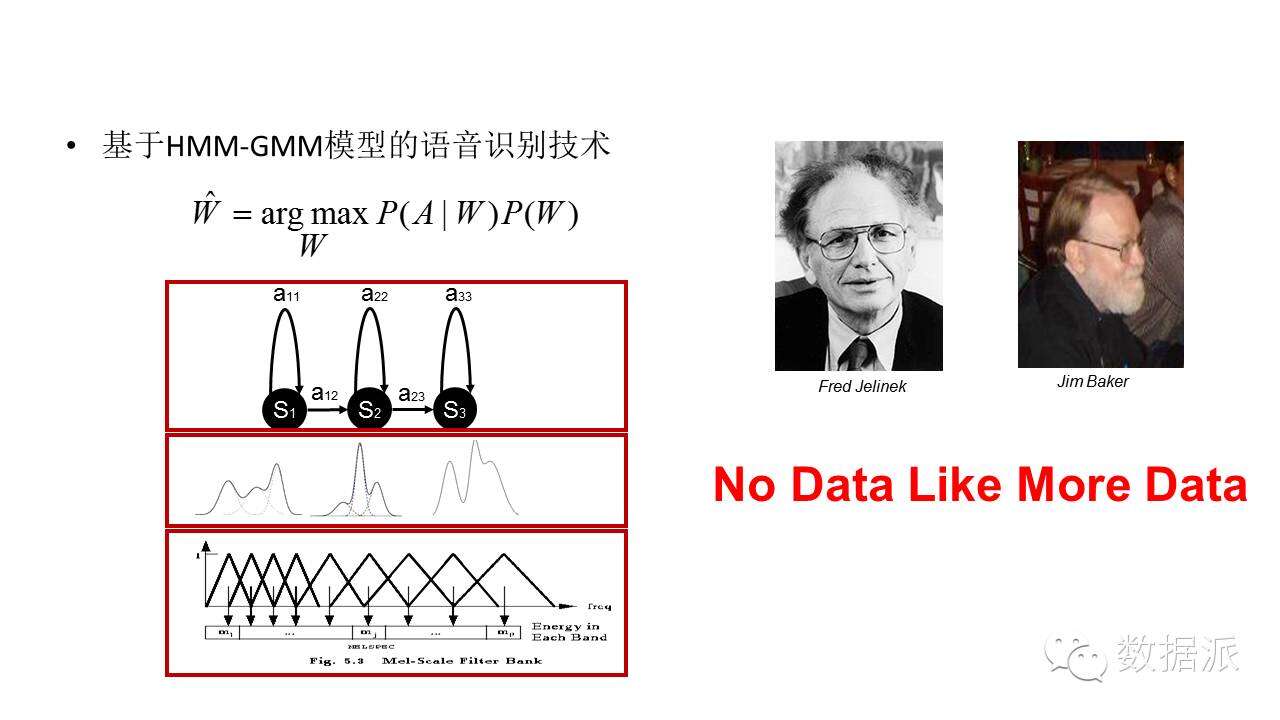
這是大約直到5年前還統治世界的這麼一個語音識別技術框架,叫HMM-GMM模型。最早是由IBM的Fred Jelinek和CMU的Jim Baker 這兩位提出來的。在這之前,語音識別一直是拿兩段聲音互相匹配,即動態時間彎折,DTW。但這種模板匹配方法很難處理語音中的不確定性問題,所以人們開始思考用統計模型對語音建模。你不是有很多不確定性嗎?那我們就用統計方法來描述這種不確定性,把不確定性放在模型裏面。這即HMM-GMM方法,從80年代一直到2010年左右的語音識別系統框架。該框架主要分三個組成部分。最底層是特徵提取。我想去識別你的語音,首先我得把最顯著的特徵提取出來,一般用的特徵叫MFCC的特徵。第二個部分是描述發音不確定性的靜態概率模型,即GMM模型。第三個部分是描述發音時序特性的動態概率模型,即HMM模型。這三個部分組成HMM-GMM系統框架,在很多領域都可應用,特別是對語音識別尤其有效,因爲語音信號具有很強的動態性,適合用該模型描述。
有了這個框架之後,Fred和Jim兩位先驅就提出這麼一個到現在還在用的公式,即後驗概率最大化識別準則。從80年代起直到大約在5年前,我們一直都是這麼做語音識別的。一個重要的問題是,有了統計模型還不夠,需要用數據來對模型進行訓練,或者說,使模型能適應某一任務的數據。當時就提出這麼一個說法,叫“No data like more data”,意思是說只有有了Data這個模型纔有意義,Data越多越大,模型效果越好。
2010年的時候世界發生了很大的變化。第一件事情特徵提取過程的簡化。傳統的特徵提取方法,如MFCC,要用很多步驟來提取出特徵。現在我不需要你人爲地設計出這麼多複雜的步驟,我直接給你一個語音信號的原始信號,或者簡單的原始譜,你把語音特徵提取過程用深度神經網絡學習出來。這意味着人們不再需要去費勁設計各種特徵提取方法和步驟,人的壓力就減輕了,而且因爲學習得到的特徵提取方法和任務目標更匹配。另一件事情是傳統GMM模型被深度神經網絡模型取代。傳統GMM模型通過混合若干簡單高斯模型來生成較複雜的概率分佈模型,可以描述語音信號的靜態分佈特性,但對不同發音的區分性不夠。用深度神經網絡取代GMM,可以直接描述後驗概率,增加發音區分性。第三件事情是傳統的HMM模型被遞歸神經網絡取代。RNN模型是比HMM更強的描述動態特性的工具,將HMM中的離散狀態描述變成連續狀態描述。所以,基本上深度學習是把原來的模型和方法全部推翻了,用神經模型代替了概率圖模型,將原來人工方式做的事情變成了一種學習的方式。這是一種非常翻天覆地的變化。
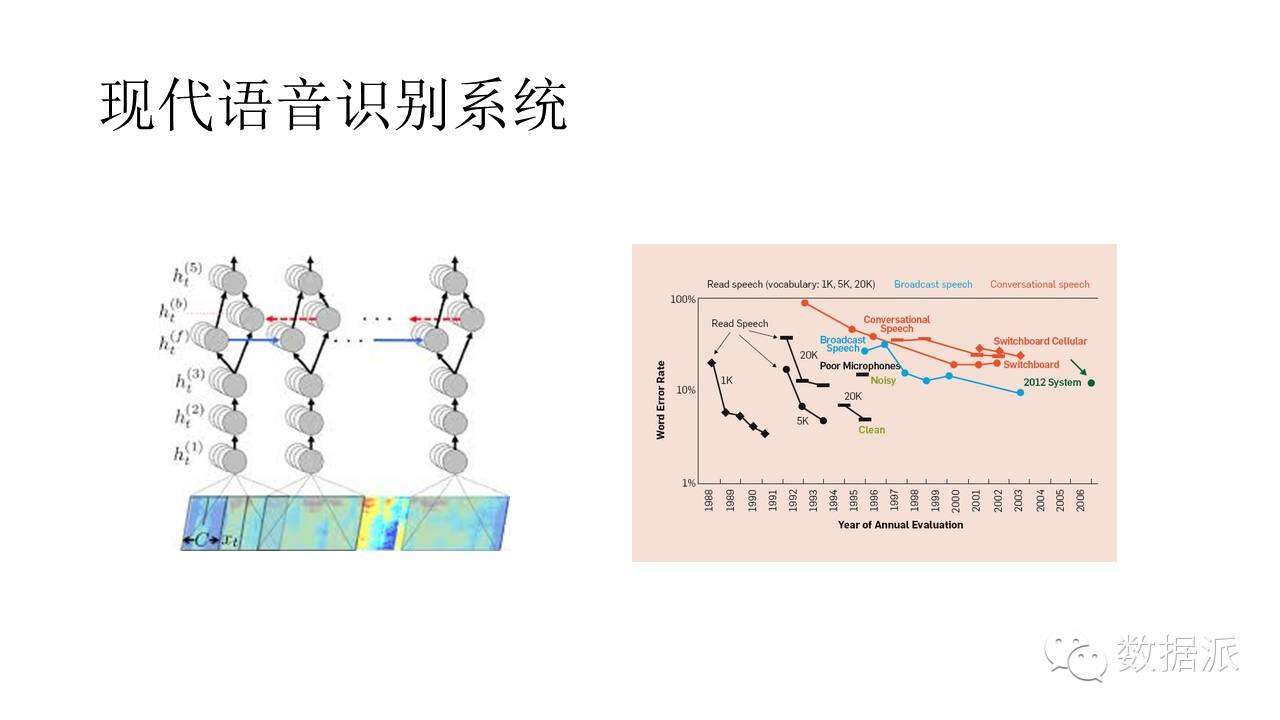
現在的語音識別基本是這個樣子的,整個一套系統不再有那麼多複雜的模塊,基本是由神經網絡將從語音信號到說話內容端到端的學習出來。這幅畫劉老師也提到過,由於深度學習的引入,語音識別系統的性能大幅提高。

今天是大數據的講堂,我們看語音識別和數據有什麼關係呢?在我看來,從我學習語音識別開始,我們就知道data是非常重要的東西,基本上做語音識別一大部分工作是在做data。這幅圖告訴我們什麼事呢?告訴我們兩件事,首先數據很重要,數據越多,性能越好。還有一個事,基於DNN的系統在數據增大時的效果提升更明顯。這意味數據重要,模型更加重要,只有數據和模型匹配的時候才能學到更多的東西,只有這兩個加在一起的時候才能實現“大數據”。感覺現在似乎是說我們還需要data,但並不像以前那麼迫切。因爲神經網絡的靈活性,數據少我們可以幹小事,數據大我們可以幹大事,而不是像以前一樣必須有大量數據,小數據我們一樣會幹的不錯。換句話說,是我們現在對data的依賴有所下降,我們還是很希望數據,但並不飢渴。We are datahungry,but not starving。

事實上作爲語音研究者,在大數據火爆之前我們一直不覺得自己是做大數據的,即使現在我們也不覺得自己是做大數據的。爲什麼呢,因爲我們覺得手頭的數據並沒有那麼大。
具體來說,(1)原始數據很大,標準數據很少;(2)低質量的數據很大,可用的數據其實並不多;(3)中英文數據很大,很多主流語言有很多數據可以得到,但是一些少數民族語言、小語種很難得到數據;(3)收費數據很大,免費數據很少,很多數據是有,都在公司裏,都要你錢的,其實沒有多少數據供研究者免費使用;(4)信息含量很大,可用信息很少。我現在說話,大家能聽到我的聲音,其中包括各種信息,包括說的什麼話、什麼口音、什麼性別等。這裏邊信息量很大,但是我們能用的東西確實非常非常少;(5)積累速度很快,一天積累無數的數據,但是能處理的很少,計算機的計算量是有限的。剛纔劉老師說的四個V(Volume、Velocity、Variety、Value),似乎好像看起來對語音數據來說,Volume是適合的,其他幾個都不是特別好。這意味着其實我們只是看着像大數據,其實並非如此。另一方面,因爲語音信號裏邊確實有很多信息,所以我們來認爲我們潛力很大,我們的數據裏面可以挖到很多東西,但是到當前能夠利用的,或者已經利用的東西還是非常非常少。一方面我們的技術可能沒達到那種程度,第二說明我們還有潛力,未來我們可能真的可以稱爲大數據研究。

我們希望幹什麼事呢?比如現在如果數據量很大,好幾十臺、上百臺CPU同時訓練,那當然是最好的。但這畢竟並不容易,除了Google、百度有那種能力之外,我們大多數研究機構還是沒有這種能力。退而求其次,我們希望用小數據做大數據的事情。我們數據有限,但是我們還是希望能夠得到一些大數據能得到的好處。
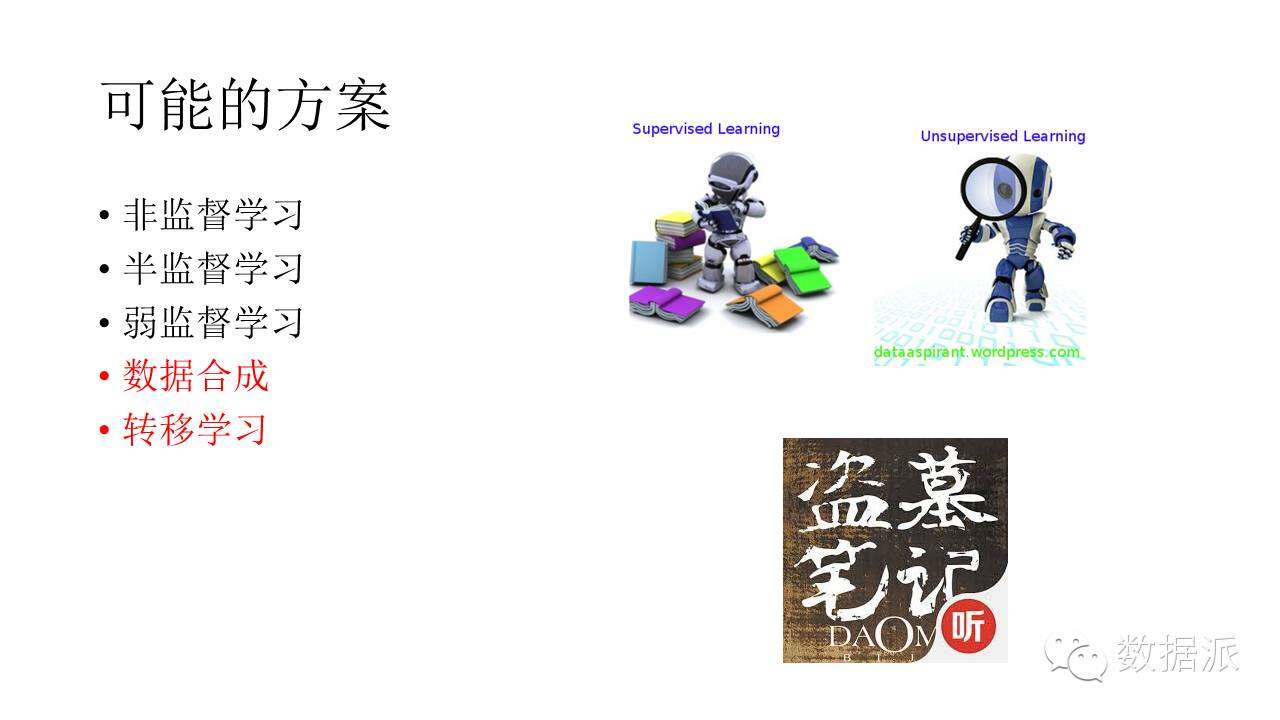
可能的方案有哪些呢?比較著名的可能是非監督學習。比如圖上這個機器人看了很多書,這是監督學習;但是有的時候沒有這些書,它就滿世界轉悠,看到一些東西記下來,用這些來豐富自己的知識,這是非監督學習。半監督學習的意思是,可能我學了一點東西,但是沒有太多的東西可學,因此可以利用學到的一點知識,爲其它沒有標註的數據進行標註,以擴大學習樣本。弱監督學習,比如說沒有那麼多標好的語音,但是網上有很多有聲小說,如《盜墓筆記》等,這些小說有人幫你讀出來了,因此可以利用裏邊的數據進行弱監督學習。另外一些方法包括數據合成和轉移學習,這是我想給大家分享的重點。
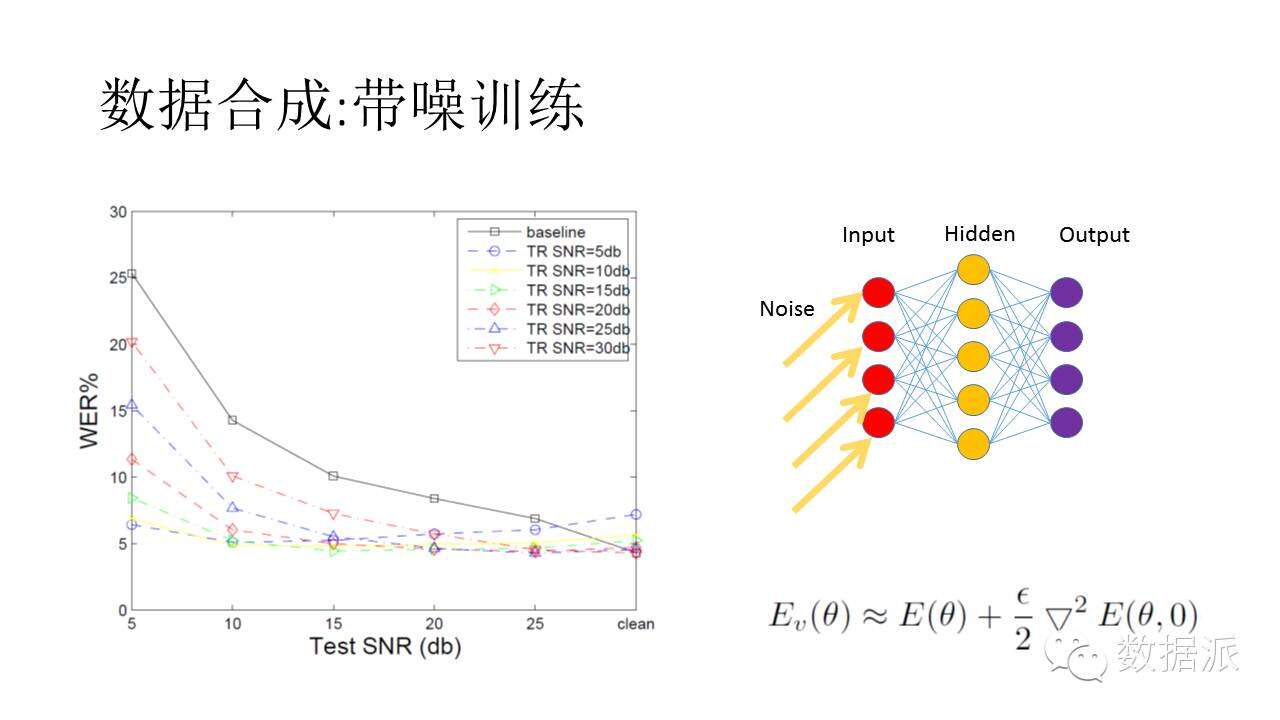
首先是數據合成。我們有一些數據,但數據總量有限。我可以用這些種子數據造出一些數據來。比如我現在需要噪聲數據,把種子數據里加一些噪音,這些噪音可以是各種各樣的,可以是機場的噪音,也可以是白噪聲,也可以是咖啡館的聲音。雖然我們沒有這些噪音爲背景的語音,但是通過人工加入這些噪音,在訓練的時候這些噪音信息還是加進去了。通過訓練,那些不容易被噪音破壞掉的語音成分被突出出來,增強識別效果。左邊這幅圖是加噪訓練的一個例子。我們往原始的DNN模型的輸入端加入噪音,通過學習,可以看到在噪聲環境下的識別性能顯著提高,對純淨語音性能幾乎沒有影響。
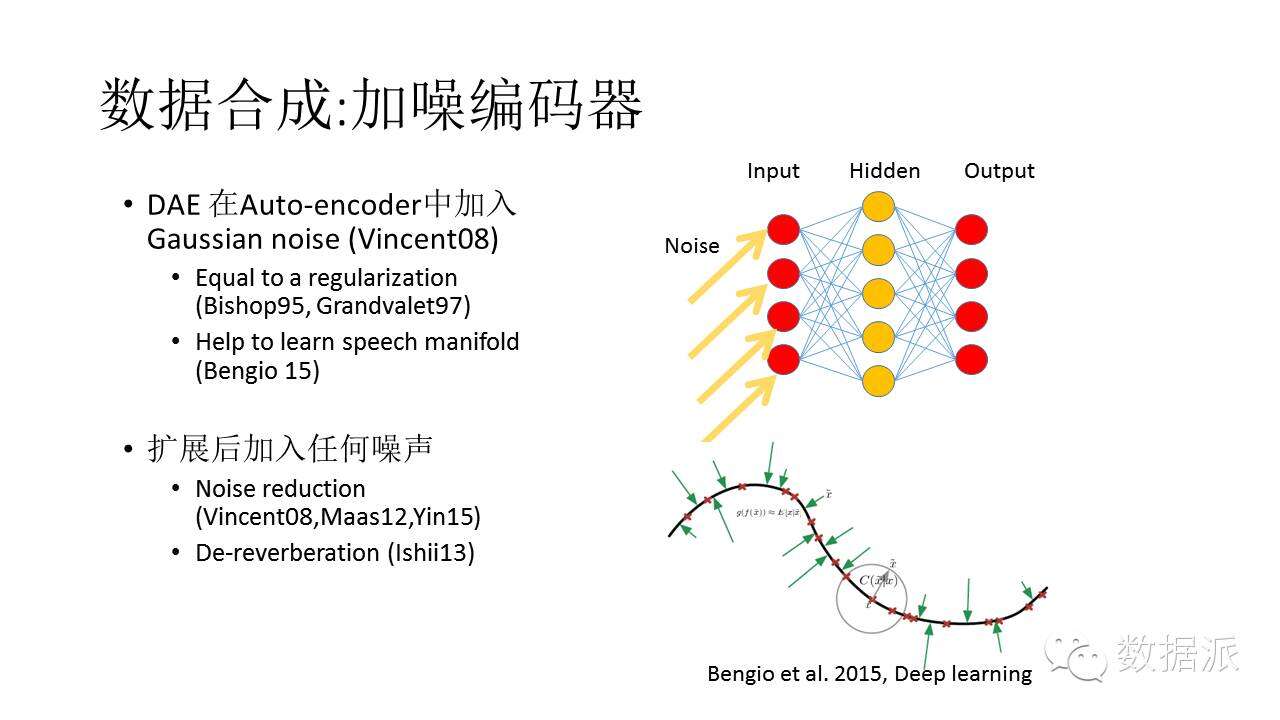
加噪編碼器,或者DAE。這一模型在很90年代就提出來。現在研究者傾向認爲,通過噪音訓練的編碼器等價於學習一個低維的子空間,這些低維子空間對噪音不敏感。這一理論最初是基於白噪聲,後來大家又做了擴展,加入其他噪音發現結果也不錯。比如說可以加一些敲門聲,DAE就可以把敲門聲濾掉,把跟敲門聲無關的信息學出來。同樣的方法還可以學習和濾除迴音。
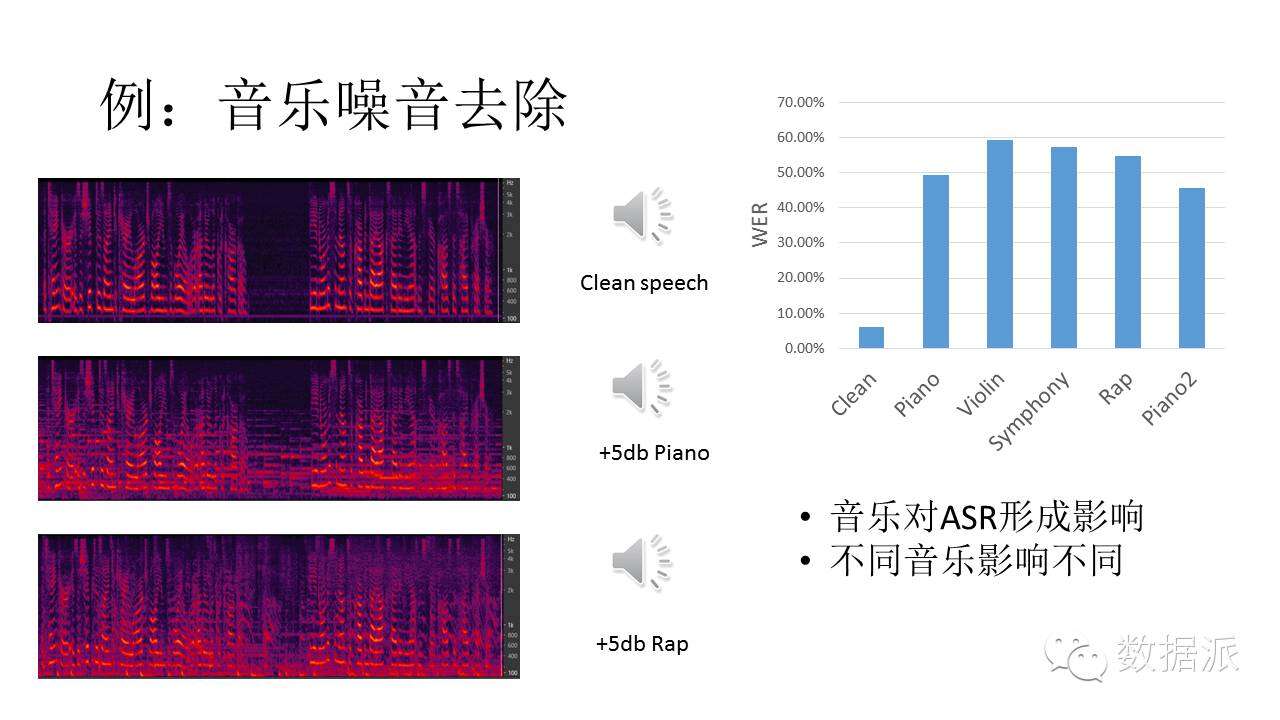
我們用這一方法可以去掉聲音中的音樂。音樂很規則,很有規律性,利用這點,我們可以用DAE學習音樂的特性。這是原始的語音,加入一些Piano,或加入Rap音樂。我們可以看到,加上這些噪音以後識別效果就變得非常差。這說明音樂對語音識別影響很大,越是跟人聲越近的音樂影響越大。
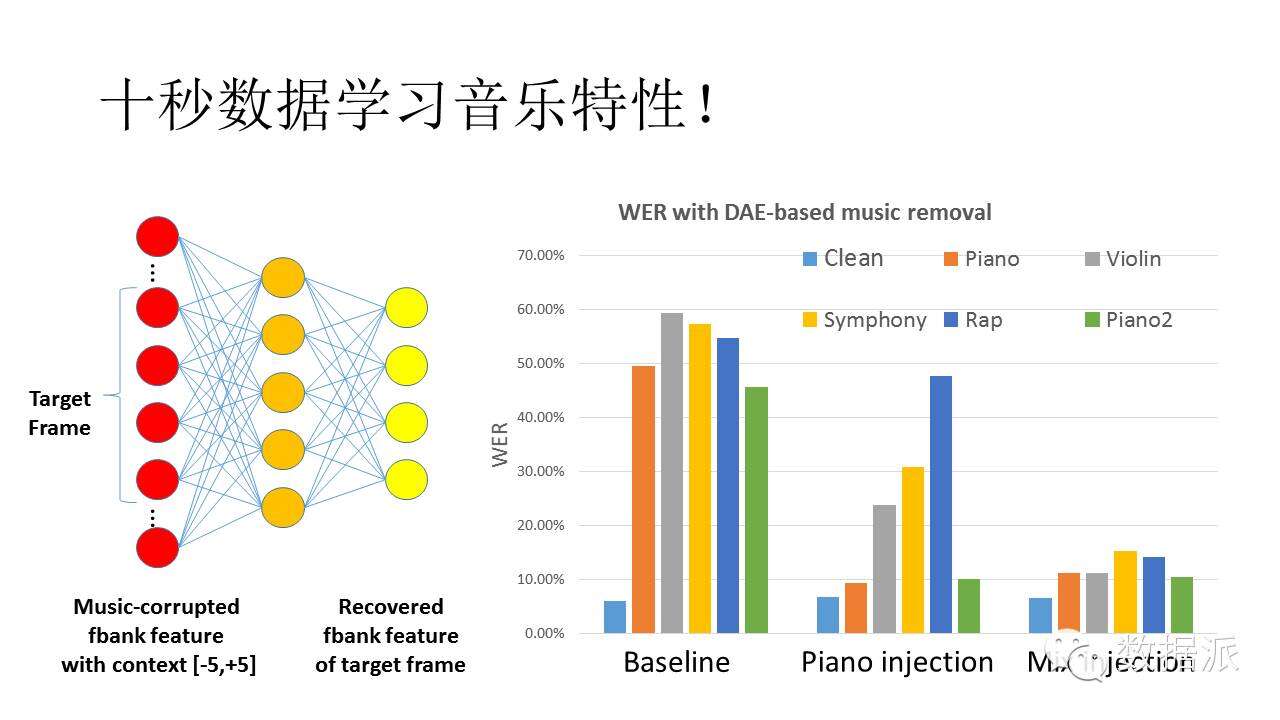
我們試圖用DAE學習音樂特性。左圖爲一個DAE,輸入的語音信號裏面加入一些音樂噪音後生成的Fbank特徵。輸出是原始純淨聲音的Fbank。通過學習,可以有效濾除這些加入的音樂。特別有意思的是,這裏面加入Piano進行訓練後,得到的模型對其它音樂學習也有好處。這證明音樂是具有共性的,學習一種音樂對其它音樂噪音也是有好處的。

另一種方法是轉移學習。這裏有兩個機器人,這個機器人先知先覺,學了很多東西,這個機器人將這個知識傳到了另外一個機器人那裏,第二個機器人在沒有數據的條件下也學得了很多知識,這一方法叫做轉移學習。
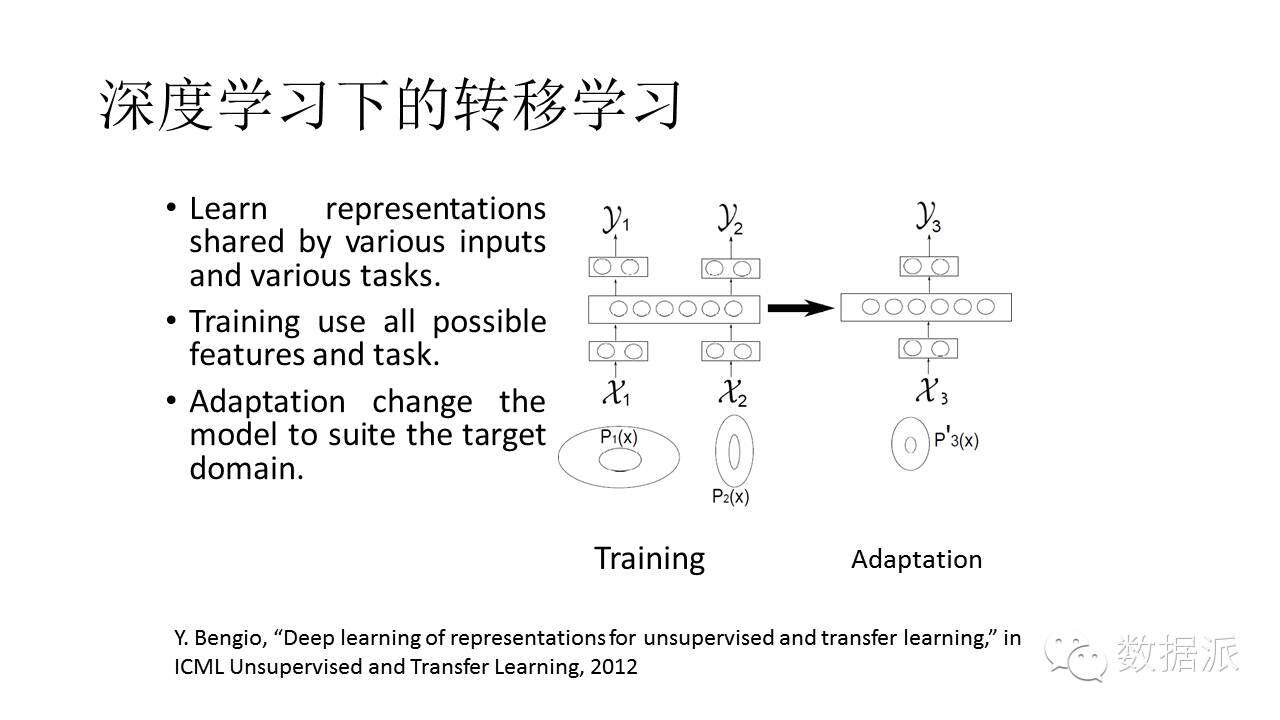
基於深度學習的轉移學習方法早在2009年就已經提出來,近年來得到廣泛應用。如圖所示,我把各種各樣可能的數據或特徵都給它扔進神經網絡,網絡的中間層用來表徵由各種不同的知識得到的共享的、共用的特徵。例如,輸入既可以是中文,也可以是英文,可以是機場環境,也可以是辦公室環境,但是不管什麼輸入,都共享中間層,這樣各種數據資源之間可以共享信息。用了這樣一個共享信息的網絡,網絡基本架構已經成型,實際應用的時候只要一些簡單的數據進行自適應就可以得到很好的結果。

具體到語音識別裏面,我們做了哪些事呢?有很多很多種方法,我們覺得有些比較有價值的可能是,第一個是跨語言轉移學習,第二個是跨模型的轉移學習,

爲什麼要考慮跨語言呢?因爲不同語言的數據分佈是非常不均勻的,某些語言數據量非常大,某些語言數據很小。人類語言總共有五千多種,其中389種語言覆蓋了94%的人羣,剩下的那麼多的語言其實很少有人說。所以從這個角度來說,其實絕大部分的語言都是閒置的,和大數據不沾邊。同時,語言現象是隨時變化的,今天說一件事,明天可能說另一件事,差別很大,所以要想一個模型一勞永逸很難。
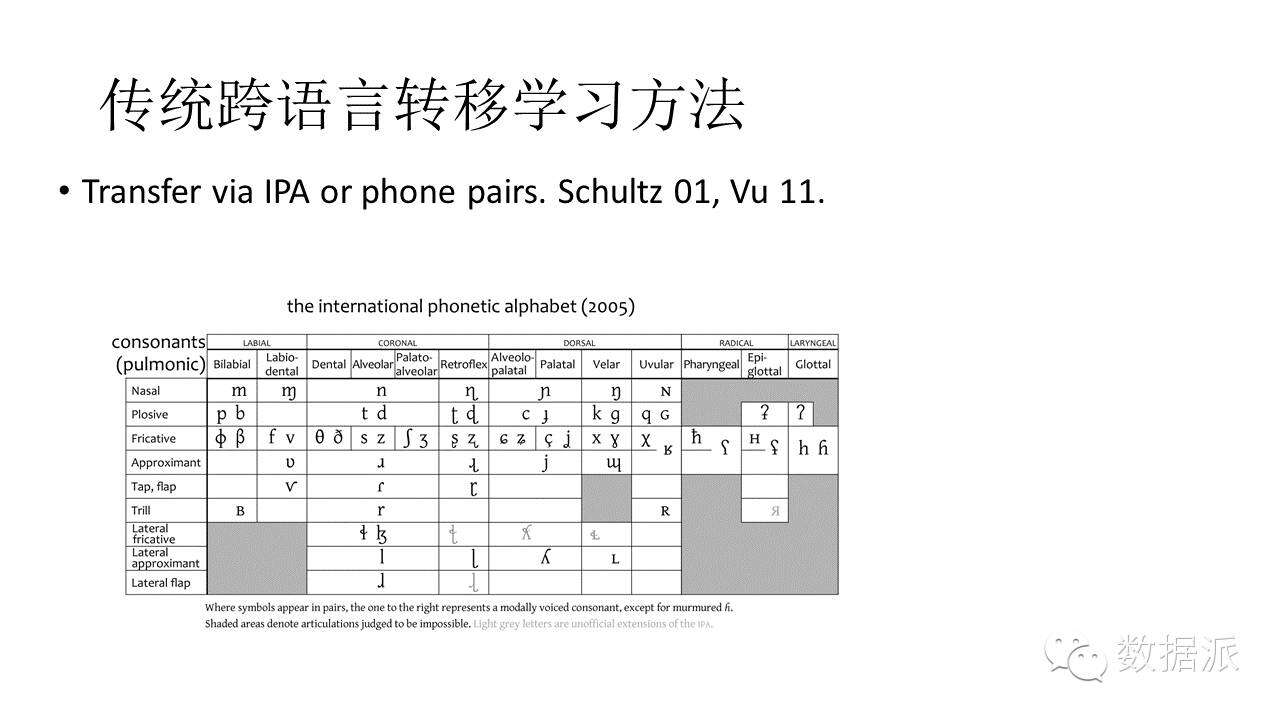
轉移學習是解決上述問題的有效方法,基本思路是利用語言之間的相似性。我們想利用語言之間的相似性來共享資源。原始的共享方法是用一套通用的發音系統來標註各種語言發音,這樣不同語言的相似發音就得到了共享。
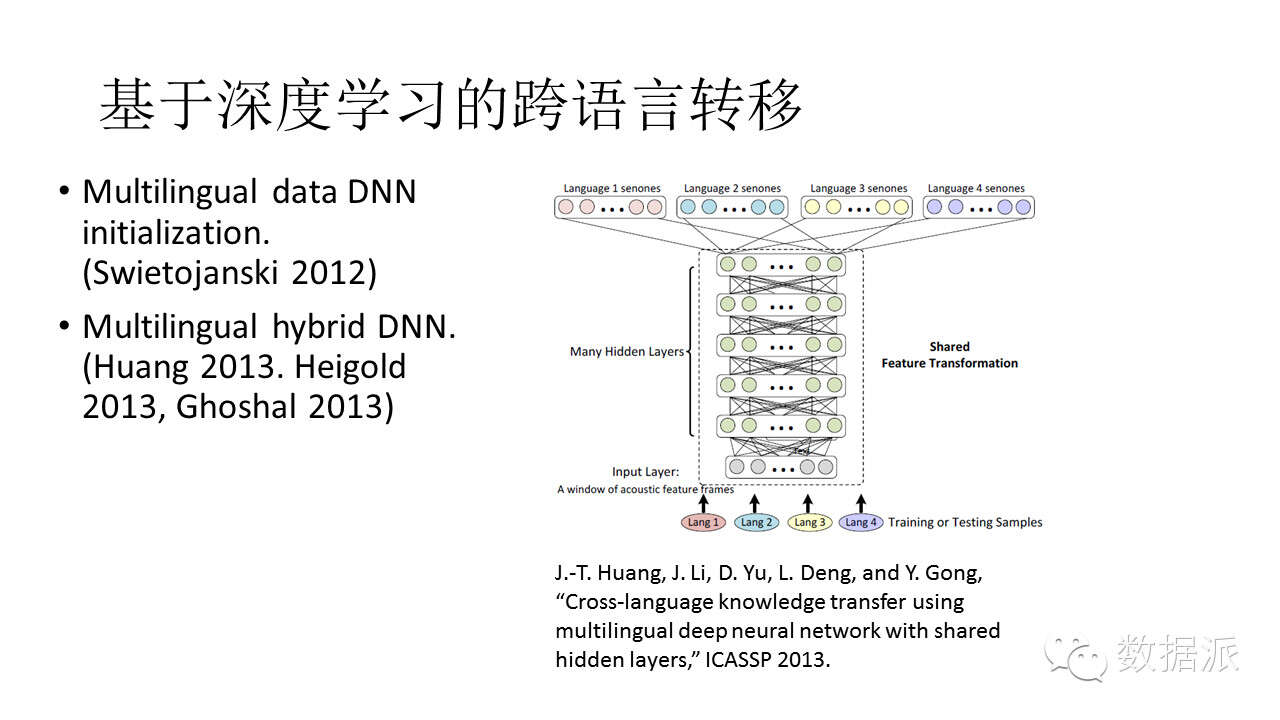
基於深度學習的語言共享是當前比較有效的方法。如圖所示,輸入層可以輸入各種語言,這些語言共享DNN的中間層,分類層用來在不同語言內部不同發音間進行區分。這是在2012年、2013年做的事情,現在基本上已經成爲一個標準框架。
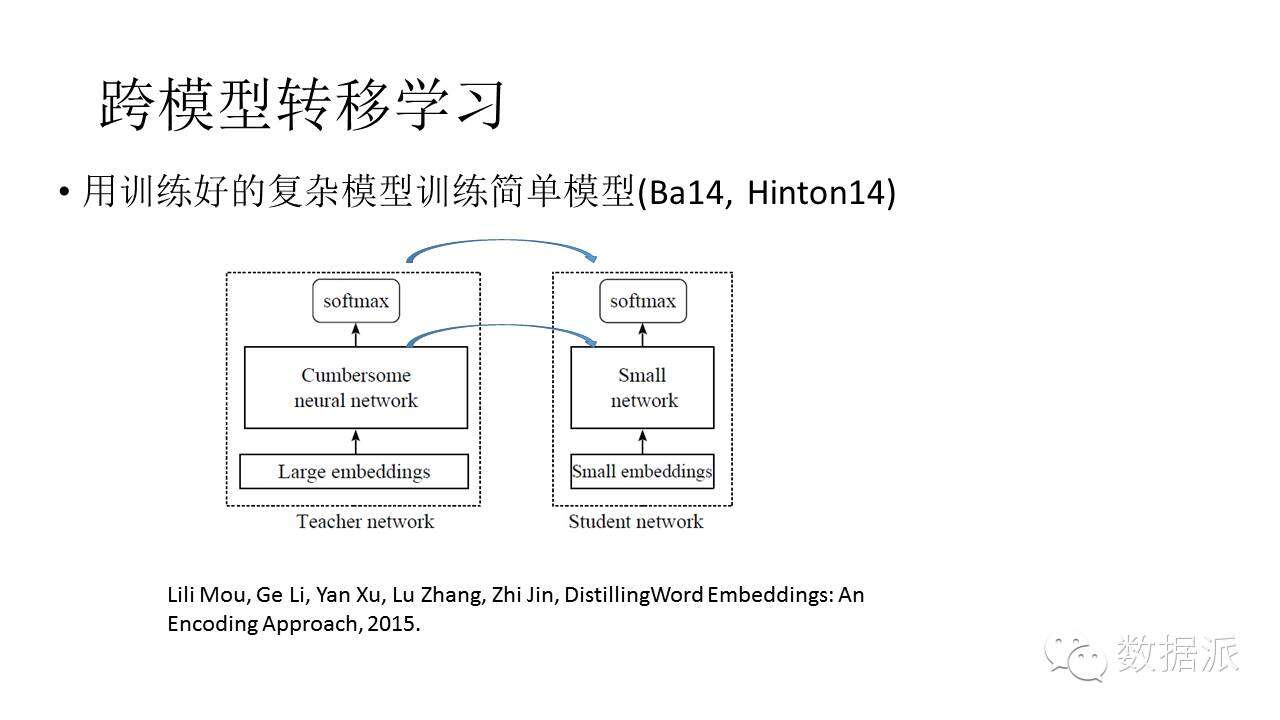
還有一種方法是跨模型轉移學習,什麼意思呢?現在學了一個模型,這個模型可以作爲一個知識源,或者是作爲一個老師,這個老師想辦法去教一個學生,把知識傳遞給學生。有很多種方法實現這種轉移學習。一種方法是相當於老師教學生一樣,我告訴你這個題的答案是什麼,然後你照着我的答案去寫過程。還有可能是從中間層給出指導,還沒出答案,我只告訴你中間的解題過程,你把解題過程告訴這個學生,這個學生也可以學到知識。
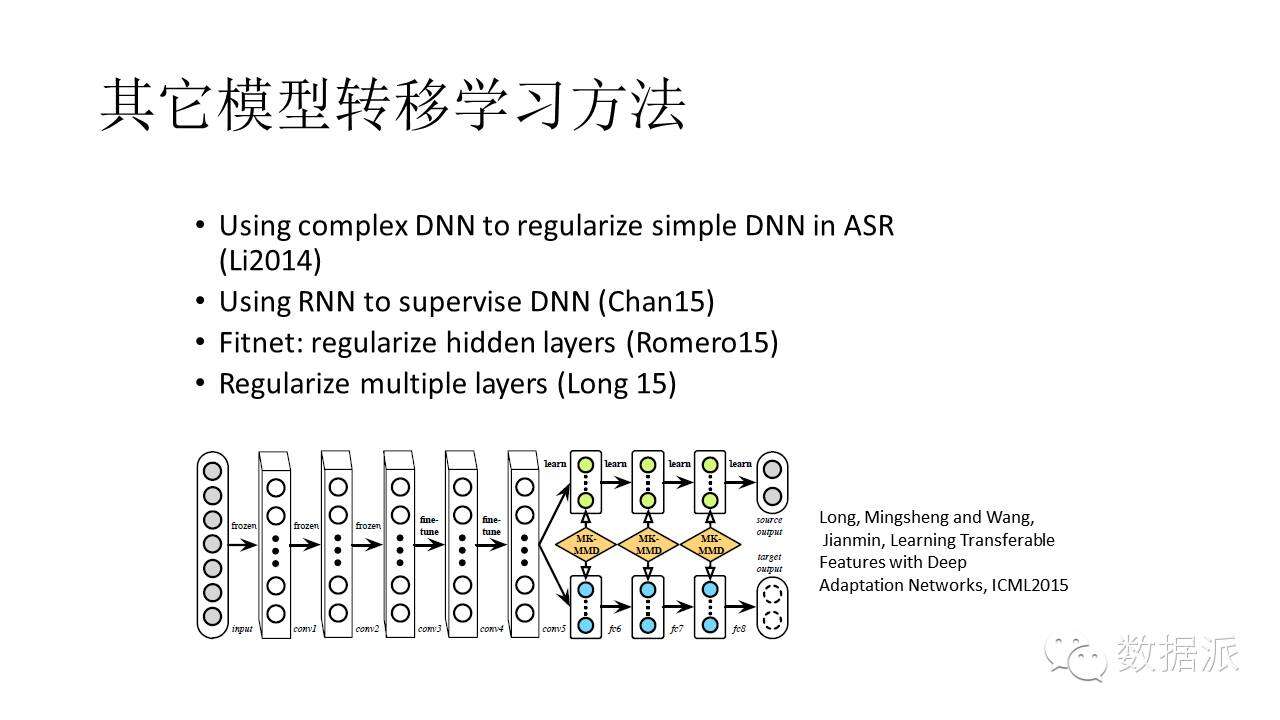
2014年、2015年發生很多事情,比如說2014年的時候可以用比較複雜的DNN來學習比較簡單的DNN。後來可以用比較複雜的RNN來指導一個比較簡單的DNN,這樣使得NDD達到近似於RNN的效果。這時的研究思路是儘量保證老師把知識儘可能教給學生。
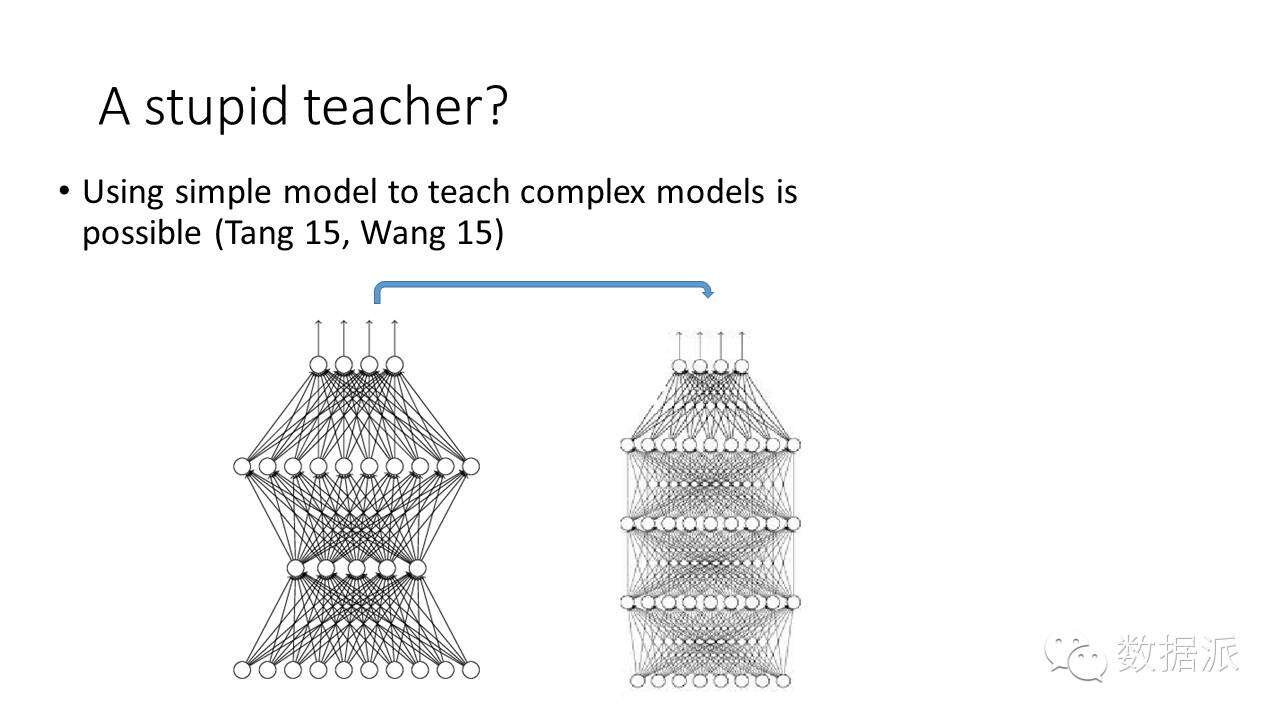
現在有一個問題,當前的方法都是用強的老師來教一個弱的學生。問題是,如果這個老師很笨怎麼辦?大家當老師都有這個經驗,很多時候老師不如學生,有的學生比老師還聰明,那老師還能教得了嗎?比如這幅圖裏,左邊有一個比較淺的網絡,右邊有比較深的網絡,我可以用淺的網絡來指導深的網絡學習嗎?
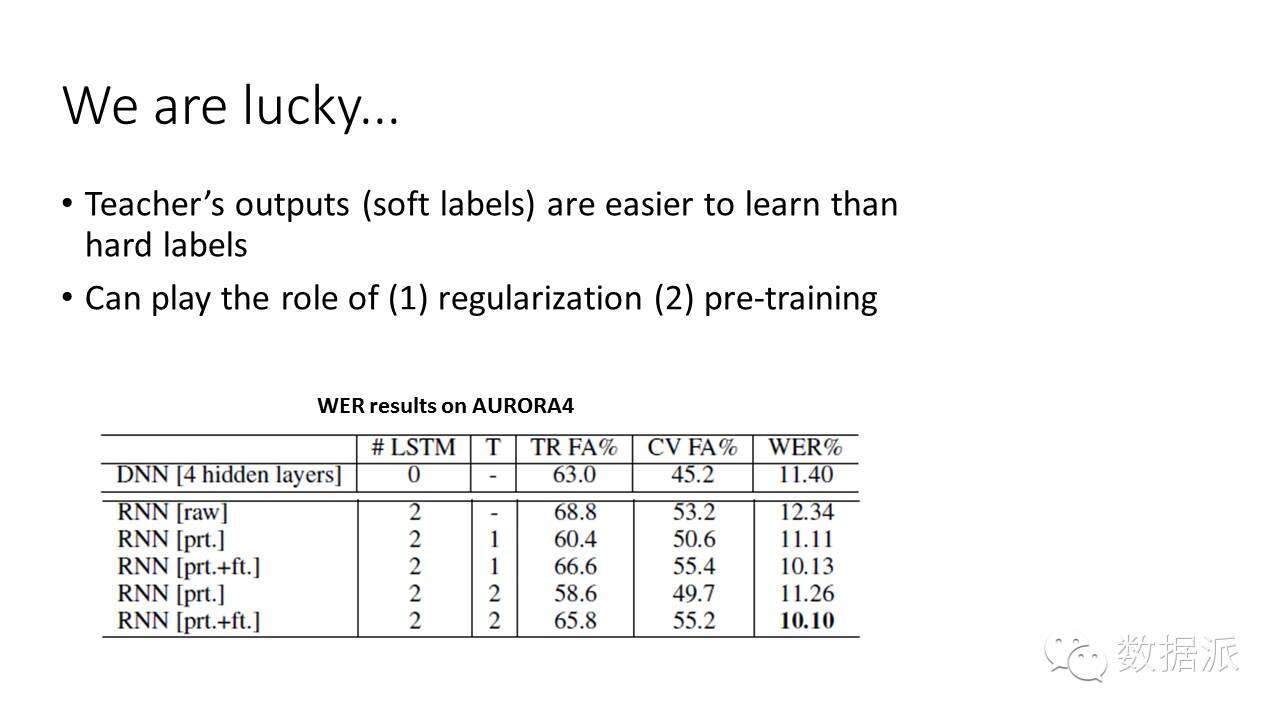
非常幸運的是,我們的實驗發現,即使比較笨的老師還是可以教出比較聰明的學生。通過什麼方式呢?一種方式就是我可以告訴這個學生,雖然我知道得不是很清楚,但是最開始我肯定比你知道得多,你也許後來可以發展得很好,但是開始至少你還是比我差一點點,所以我就把那一點點東西傳給你,將來怎麼發展,師傅領進門,修行在個人。雖然我的這個知識不是特別好,但是我可以讓你先有一個鍛鍊,鍛鍊的方式可以教給你,然後你自己去學。事實證明,這種方法確實有好處。比如說我們用一個比較弱的DNN,即是比較糟糕的老師去教一個比較強的學生,一個RNN模型。最初的時候,這個DNN老師的錯誤率是11.40。如果聰明的學生從開始自學,相當於把一個特別好的學生扔到一堆書裏,自己去看,結果是12.34,這個結果不如一個弱的老師。當這個DNN老師把這個知識傳給學生,聰明的學生拿到老師的知識以後,自己發揮、昇華,最後就超過老師了,錯誤率下降到10.10%。這意味着什麼呢?意味着老師弱的時候也無所謂,可以教比較聰明的學生。

總結。我們覺得語言和語音的問題很大程度上是一種大數據背景下的小數據問題,因爲我沒那麼多數據,所以我們不得不用有限的數據做更多的事情。基本的思路就是共享。共享在語音識別裏面有很長的歷史了,比如基於決策樹的上下文相關建模。未來我們可能需要將語音的、文本的各種信息集成在一起進行更有效的共享學習。另一方面,非監督學習有可能是間接利用語音大數據的有效工具。特別有意思的是深度學習使得小數據到大數據的學習成爲可能,沒有這個工具其實我們很難用小數據做什麼事。