




轉載來自:http://my.oschina.net/aaron74/blog/282304
我把我這些年在java學習中學到的東西,按照項目開發中可能遇見的場景,進行了一次梳理。
這個故事是我最後決定加上來的,我非常喜歡這個故事,軟件工程中有一個被戲稱爲Cargo Cult編程法的編程風格,而下面這個故事講述了此編程法的來源:
早在40年代,據說,美軍曾駐紮在一個偏遠的島嶼。島上的土著居民在此以前從未見過的現代文明,所以,他們對聯軍和他們帶來的東西非常驚奇。他們發現聯軍修建了機場跑道和控制塔,帶着耳機的士兵對天呼叫,然後滿載着大量貨物的大鐵鳥便從天而降。當鐵鳥降落後,貨物便分發給所有島上的人們,爲人們帶來繁榮。
終於,有一天,部隊離開了,大鐵鳥也不再回來了。爲了再次得到貨物,島上的土著居民用竹子建造了自己的跑道,控制塔,讓他們的頭領登上平臺,並讓他戴上用椰子做的耳機。但無論他們如何努力嘗試,大鐵鳥再也沒有回來。
幾十年後,研究人員發現了該島。島上的土著居民仍舊保留着這一宗教儀式。他們把島上居民的這一奇怪的宗教儀式命名爲“Cargo Cult”
@考慮這樣一個應用場景:我們的項目功能日漸強大,代碼卻日漸臃腫,我們如何將代碼變得有條理些?
無論我們是學習還是工作,我們的前輩總是會告訴我們,我們需要把java項目進行架構上的分層,界面層(UI) 業務邏輯層(BLL)
數據訪問層(DAL),就像Cargo Cult中的土著居民一樣,雖然我們並不知道爲什麼高手們要那樣做,但是我們相信這麼做可以讓程序工作起來,後面我會講到爲什麼會有所謂的經典的三層架構,現在我們已經做完的事是,按照三層架構將項目搭建並運行起來了!
我們一般會想到MVC,很多書上都有寫到,可惜很多時候我們理解的MVC是錯誤的。。。甚至我曾經天真的以爲,MVC正好對應着DAL,UI,BLL。。。實際上,這兩者並沒有顯式的關係,前者屬於設計模式,而後者屬於架構設計的範疇,如果一定要扯到一起的話,關係可能會是這樣的:
|
|
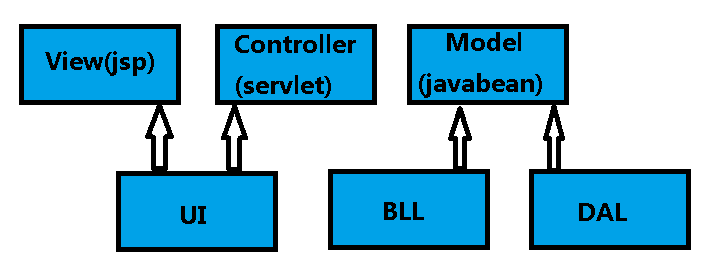 |
實際上,Controller是很薄的一層,它僅僅負責接收參數,封裝參數,調用不同的service。所以我們可以考慮先從它入手,簡化代碼。
我們現有的controller做法是,不同的業務調用不同的servlet,通過參數的不同,調用不同的方法,比如,有下面一個form
|
1
2
3
4
|
<form action=”UserServlet?command=login”> <input name=”name” /> <input name=”password” /> </form> |
如果我們在這個表單中輸入用戶名密碼,最終後臺會將這個請求提交到UserServlet中,然後根據command=login,調用UserServlet中的login方法。在login方法中,會有這樣的一段代碼:
|
1
2
3
4
5
6
7
8
|
String name = request.getAttribute(“name”); String password = request.getAttribute(“password”); Boolean result = userService.hasUser(name, password); if(result) { .... } else { .... } |
我們可以發現,基本上這個servlet中,所有的方法幾乎都有着從request中獲取參數的這麼一個過程,而且同一個servlet中,需要獲取的參數大部分都是重疊的(比如UserServlet中,幾乎所有的方法都需要獲取name和password的值,才能進行近一步操作),既然每一個方法都有這麼一個需求,爲什麼不考慮將這一過程抽象出來呢?
首先,我們可以設計一個叫AaronDispatcher的類,它負責截取了所有的對項目的訪問的http請求。
比如,我們上面的請求叫UserServlet?command=login,同時傳遞三個參數name和password(以及上面的command) 。AaronDispatcher巨牛叉,它直接把這個請求截取了,並進行分析,首先它的名字叫UserServlet,調用的方法叫login。爲了不引發歧義,我們更改前臺的請求地址,改爲發送到UserAction?command=login。
然後我們可以重新設計UserServlet,創建全新的UserAction。(現已加入豪華午餐)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
public UserAction { String name; String password; String newpassword; //updatePassword這個方法需要 String oldpassword; ...... //所有的UserAction從前端獲取的參數 public login() { ... } public logout() { ... } public updatePassword() { ... } ...... //所有UserAction需要提供的方法 } //UserAction結束 |
(眼疾手快的人也許可以注意到一點:這個類不再需要接受HttpServletRequest及HttpServletResponse作爲參數了)
每當我們有一個發送到UserAction的請求,AaronDispatcher就幫我們new一個新的UserAction實例,同時將請求中的參數賦給UserServlet中的屬性。具體的底層做法,類似於下面這樣:(實際上會複雜很多,不會直接new對象,而是使用反射來創建對象並賦值屬性)
|
1
2
3
4
5
6
|
UserAction userAction = new UserAction(); userAction.setName(request.getAttrbute(“name”)); userAction.setPassword(request.getAttrbute(“password”)); userAction.setNewpassword(request.getAttrbute(“newpassword”)); userAction.setOldpassword(request.getAttrbute(“oldpassword”)); ...... |
如果我們需要登陸功能,直接調用userAction.login()就可以了(至於name和password,直接可以在方法內部獲取當前對象屬性)。 所有的方法中,從request中獲取參數並進行封裝的這麼一個過程,全部都被巨牛叉的AaronDispatcher做了,是不是減少了很多重複的代碼量?!
可能會有疑慮,所有的請求,無論什麼方法,都進行一次屬性全賦值,如果前臺沒有傳入這個屬性,不就爲空了嘛?但是要知道,如果我們調用login這個功能,newpassword和oldpassword固然會因爲前臺沒有相應的屬性值傳入而設爲null,但是,但是,在login方法中,我們根本就不會用到這兩個參數啊!所以即使爲空也不會有錯的!
甚至我們可以做的再牛叉一點,AaronDispatcher會去讀取一段配置文件,配置文件中指定了什麼樣的請求調用什麼養的類以及相應的方法,這樣我們就可以徹底解耦最前方的Controller了!
但是AaronDispatcher是怎麼做到無論什麼類,當中有什麼屬性,我們都不需要事先知道,我們都可以接收前端參數,給他們的屬性賦值呢?(答案是通過反射)
現在,我們已經成功的重新發明輪子了!
因爲以上這個偉大的想法已經有被別人搶在前面實現了,就是著名的Struts2,毋庸置疑,Struts2的核心功能就是這麼簡單。
在Struts2中,每一個處理類被稱之爲Action,而Struts2也正是通過xml配置文件,實現了無需要修改代碼,通過修改配置文件,就可以修改Controller。
Struts2發展到今天已然是一個功能齊全的龐然大物了。
正如一開始所說,MVC框架只不過幫助我們封裝了請求參數,分發了請求而已。Controller是非常薄的一層,而我們的業務邏輯都是由BLL層提供的Service對象實現。
首先講述一下爲什麼會有所謂BLL(Business Logic Layer)和DAL(Dataaccess Layer)了。在一個項目中,無論是查詢用戶的用戶名,還是查詢庫存數量,這些數據終歸是要保存到數據庫的,而這些對數據庫的操作將會無比的頻繁,如果我們不將這些對數據庫表的操作獨立出來,如果在多個方法中存在着對一個用戶記錄的查詢,我們不得不把這段代碼copy、paste無數次,既然這樣,我們爲什麼不像上面那樣,將這種可能會多次遇到操作抽象出來呢?於是就有了所謂的DAL了,這樣,無論在什麼地方,需要用到數據庫查詢相關的工作的時候,僅僅需要這麼做:
|
1
2
|
User user = userDaoImp.getUserById(userId); ...... |
這麼做有一個好處:減少了因爲持久化方案的更換而導致的代碼修改帶來的工作。
持久化是一個非常高端大氣的專業術語,說的更專業一點,就是將內存中的數據保存到硬盤中。在我們的項目中,用戶進行了註冊,我們需要將用戶註冊的用戶名密碼保存起來,以便下次用戶登陸的時候我們能夠知道,這個用戶名的用戶是合法註冊過的。
通常持久化的方案就是將數據保存到數據庫中,但是我相信如果我不願意使用數據庫,而直接將用戶名密碼明文保存到文本文件中,也沒有人會從技術上反對吧(實際上這種事情在中國互聯網的發展歷史中還真發生過。。。),如果我真的選擇這麼做,我所需要做的工作就是僅僅修改DAL中的實現,將對數據庫的操作改爲對本地文件的操作,而無須修改調用持久化方法的方法。
業務層負責業務的處理(接收上層傳過來的信息進行處理),當處理完之後,將處理的結果利用DAL的對象進行“保存到硬盤”。而DAL具體是怎麼實現的,完全不會影響到已實現的業務。
很明顯的,爲了做到上面這一點,DAL中的方法要儘量的“單純”,不包含任何的業務上的邏輯,僅僅是將內存中的數據(一般就是某個對象)保存到硬盤的“實現”,以及從硬盤讀取的數據提取到內存的“實現”。
已經很明顯了,三層架構不是從來都有的,只不過是在無數次痛苦的經歷過後先烈們總結出來的一套證明可以在某一方面減少因變動而帶來的額外工作量。說它經典,也只不過是因爲它實現了展示、業務、持久化這三個必不可少卻又相對對立的需求的切割(不過確實有的項目中,展示不是必選的)。
所以基本上所有的複雜架構也只不過是在此基礎上的進一步分割,曾經做過一個巨複雜SaaS項目,爲了減少某些不定因素的變動而帶來的代碼上的改動,架構師將BLL分成了兩層,在原有的BLL之上又增加了一層core
business layer。這樣MVC框架只需要調用core business的業務而無須自己在重複組裝比較底層的業務邏輯了。
如果有更復雜些的項目的話,就需要通過分割子項目及更復雜的層級關係來解決了。
這個時候我們或許應該講述BLL了,不過在此之前,我們可以再多想一步,能不能修改DAL中的東西,讓我們使用起來更簡單?
一般來說,數據庫中的表對應着java中的類,表中的一行記錄對應着一個entity對象,表中的字段對應着對象中的屬性,我以前一直覺得很神奇,這就是傳說中的ORM。這當中還有很多更復雜的東西,比如多表級聯的結果映射爲對象,在這裏我們先忽略這些複雜的情況。
有了上面的知識,我們可以發現, 如果我們選擇關係型數據庫作爲持久化方案,我們的DAL其實也很“單純”,他們所做的也不過是將對象屬性通過sql存儲到數據庫、將通過sql獲取的數據封裝爲對象。
同樣的我們可以寫一個巨牛叉框架(好吧,這次不是寫一個巨牛叉的類了),它會自動根據我們entity的名字,去數據庫尋找相應的表,當我們調用insert,delete,update,select等方法的時候,它會自動幫助我們根據要求及參數拼接sql,然後去數據庫查詢/修改記錄,如果是查詢,則把查詢出來的記錄集封裝成對象,保存在list中。這樣,我們就可以在DAL中簡單的定義一些entity就可以了。
比如,我們這次在DAL中,僅僅只定義了一個類:
|
1
2
3
4
5
|
public User { long id; String name; String password; } |
|
1
2
3
|
//我們已經假設了框架巨牛叉,所有的DAL對象都是可以根據entity自動生成 AaronDao userDao = new AaronDao(User.class); List<User> list = userDao.list(......) //括號裏面是一些列條件,比如一些分頁條件啊,屬性限制啊之類的。 |
只可惜java中還真沒有這種框架。。。
實際上java的JDBC遠比想象中的複雜(主要是因爲作爲強異常處理的java語言,爲了完成一次對數據庫的操作,需要編寫的異常處理代碼實在太多了),還有事務的處理,數據庫連接的開啓和釋放(甚至連接池的配置),等等等等。。。如果使用Spring JDBC或者Hibernate ORM框架,可以幫助我們不需要花太多精力放在非核心的處理上,專注於數據的讀/寫。
即使這樣,需要寫的代碼還是太多了。因爲每一個entity我們都必須手動編寫相應的Dao類(注:操作entity的類),我又開始懷念那個巨牛叉的框架了。如果大家有興趣,倒是可以嘗試一下實現我上面所形容的據牛叉的DAL框架。
實際上,真的有人在Ruby中實現了類似於上述的數據庫操作框架,在Ruby On Rails中,我們僅僅只需要定義一些普通的entity,而剩下的操作都是ror自動生成,當年DHH(ror的作者)在網上發出15分鐘從零開始完成博客系統的視頻,整個Web世界都被驚歎到了。
在正式講到BLL之前,咱們先懷念一下最原始的servlet,是的,就是它剛剛出生的時候的事。
最早的時候,sun在提出servlet規範的時候,很多人是直接在servlet中完成接收參數,處理業務,從數據庫或者本地文件中讀取數據,最後打印出html返回。這個過程,大概會長成這個樣子:
|
1
2
3
|
response.getWriter().println(“<html>”); response.getWriter().println(“hello ” + user.name); response.getWriter().println(“</html>”); |
顯然的,後來對數據庫的操作被剝離出來作爲DAL了,那爲什麼還要剝離BLL呢?
如果我們不剝離service對象(BLL),如果我們需要增加用戶,我們需要在UserServlet中這樣寫:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
public void doPost(HttpServletRequest request, HttpServletResponse response){ Strring cmd = request.getAttribute(“command”); if (“addUser”.equals(request.getAttribute(cmd))) { String name = request.getAttribute(“name”); String password = request.getAttribute(“password”); User user = new User(name,password); if (userDaoImp.getUserByName(“name”) != null){ userDaoImp.addUser(user); ......//返回添加成功頁面 } else { ......//返回添加失敗頁面 } } else if (其他command) { ...... } } |
如果我們想測試我們所寫的代碼是否正確,會遇到一個前所未有的困難,需要模擬HttpServletRequest和HttpServletResponse對象以及一個UserServlet對象。我們很難脫離瀏覽器環境測試這個類。(實際上可以通過mock來模擬這個過程,這個後面會說到)
簡單的辦法就是寫好前端頁面,然後通過在頁面上去添加一個用戶,看看是不是真以上邏輯正確。
天吶。。。這纔是一個簡單的業務邏輯,我們就不得不等到有了前端頁面之後才能去測試它,如果我們的邏輯更復雜點,等到前端都做完了才能發現有後臺有bug,而且即使修改完了還需要回頭通過瀏覽器再測試一遍,如果是通過頁面不斷地手動輸入用戶信息這種,估計一天也就測試幾個case了。。。大部分時間都浪費在鍵盤上了。
要是能把測試的case記錄下來,下次由電腦自動的重新模擬這個過程該多好(正所謂重複勞動力全部交給電腦吧!),不過自動化測試在後面,我們先跳過這個瘋狂的想法。
還是修改源代碼吧。。。
|
1
2
3
4
5
6
7
8
9
|
public void doPost(HttpServletRequest request, HttpServletResponse response){ String cmd = request.getAttribute(“command”); if (“addUser”.equals(cmd)) { String name = request.getAttribute(“name”); String password = request.getAttribute(“password”); User user = new User(name,password); userService.addUSer(); } } //結束doPost |
比如我們可以簡單的這樣測試:
|
1
2
3
4
5
|
public static void main(String[] args) { UserService userService = new UserService(); User user = new User(name,password); System.out.println(userService.addUser(user)); } |
這樣保證了一種“契約”:servlet負責調用service並提供相應參數,根據service的返回結果,返回不同的UI展示。只要service沒有錯誤,servlet肯定能正確的執行MVC中對View的跳轉。
而對service中業務邏輯的測試,在前期就可以通過簡單的單元測試做完,保證最後提供出去的service都是正確的。相比較於將業務邏輯寫入servlet,等到後期通過頁面的操作才能發現bug,開發效率可以說是驟增。
實際情況當然會比我所說的例子複雜的多。。。
首先,現在很少有項目會直接採用servlet的形式來做,那樣子的話我們不得不在很多地方重新創造輪子(還記不記得我設計的很牛叉的AaronDispatcher。。。),一般會採用MVC框架來封裝servlet。
同時,我們會遇到很多很多諸如安全性,權限控制,異常處理等等之類的,需要解決的問題。(最後我們會發現,我們的業務邏輯的代碼量和這些非業務邏輯代碼量相比,要少的多的多)
對有些人來說,如果僅僅是爲了測試而多做一層service的確看起來沒有那個必要,三層架構不一定總是正確,有很多缺點,典型的貧血模型,不夠面向對象(關於這一點,網上的資料好多,可以嘗試一下);開發過程漫長;做出來的效果魚龍混雜;(同樣適用三層架構,大牛們和我設計出來的效果簡直就是美食和狗屎的區別)
現實生活中,沒有這麼複雜的php也活得好好的。
但是,但是,但是。。。如果我們只是想做一個網站,它只需要記錄我們的博客,展示我們曾經拍過的照片,提供一個供大家談談人生談談理想論壇,那麼我建議使用php,的確做網站最好的是php,用java純屬裝逼。java之所以是java(或者換句話,.net之所以是.net),他們與php的差別在於,他們有完整的命名空間機制(java中的package,C#中的namespace),完善的開發標準體系,成熟的第三方框架,語法簡單、規則性強。事實上,java/.net絕對不適合做快速成型的展示型網站。
吐槽結束,回到上面的問題,既然三層架構絕對不是權威,僅僅爲了測試還不值得我們抽象出一層BLL,那爲什麼我們要像Cargo Cult土著居民那樣,跟隨別人的腳步呢?
因爲我們還不夠強。。。
因爲我們還不夠強,不能想到更好的分層辦法,所以我們不得不沿用傳統的三層架構或者在此基礎上的多層架構,如果我們足夠強大,完全可以利用領域模型的思維來構建系統。
因爲我們不夠強大,很多功能我們需要利用BLL才能實現。
正如前面所說,java工程師的方向絕對不是做一個簡單的網站,如果項目領導突然有一天神經大條,說我們需要做一個iphone客戶端,因爲領導用的是iphone,如果我們沒有把BLL抽象出來,我們就不得不重新寫一個和web處理相同業務邏輯的層級,用來和iphone客戶端通信。如果業務複雜,天吶。。。
正是由於我們已經將不依賴於任何顯示邏輯的BLL抽象出來,我們才能淡然的添加一層薄薄的iphone客戶端通信層,當需要發生業務邏輯的時候,僅僅只需要調用BLL已實現的方法。
通常三層架構中的UI最終會返回html給瀏覽器解析,而iphone通信層一般會返回json數據給iphone客戶端解析。
好吧,的確不是所有領導都有iphone的,但是,即使我們確定我們僅僅需要支持的就是瀏覽器,很不幸,很多時候我們也需要利用BLL。
通常BLL中的每一個方法都是一個事務。事務是一個很複雜的東西,在分佈式系統中更是如此,但即使是一個簡單的項目,我們也不得不爲事務而傷神。
在我們的潛意識中,事務應該是數據庫訪問層做的事,但是很不幸,我們需要在業務邏輯處理中進行事務。
最爛大街的例子,BLL中有一個AccountServer類,提供一個transfer(Double money, Account from, Account to)方法。在這個方法中,首先會進行一次update(from),再進行一次update(to)的數據庫操作,但是如果update(from),匯款操作成功了,但是因爲某些未知原因,update(to),收款操作失敗了,估計所有人都接受不了這件事。
所以我們要保證transfer(Double money, Account from, Account to)作爲一個方法,要麼裏面的數據庫操作都成功,要麼都失敗。
抽象出業務邏輯層的好處在於我們可以以一種更好的顆粒度來做事務。
說點題外話。。。
不得不說,如果不利用Spring AOP來配置事務,純手工編寫的話,給BLL中的方法做事務,的確是一個很有技術含量的活。
這當中的確用到了很多設計模式的奇技淫巧、ThrealLocal等較爲高深的技術(好吧,的確在一年之前,我真的不知道ThreadLoacl是什麼。。。),因爲我們做事務的一個前提是,事務中所有的數據庫操作,使用的是同一個connection。
關於更具體的,如何簡化BLL中的事務配置,以及面向接口的編程習慣,spring的使用,將會留到下一個應用場景。
現在我們來做一次總結:
MVC之類的設計模式、三層架構的劃分,歸根結底的目的在於解耦,減少項目中牽一髮而動全身的現象,同時減少重複代碼的編寫,增加代碼的可讀性、複用性。
所謂框架,就是幫助我們減少重複的、不必要的、非業務核心的代碼的編寫的工具而已。(不然我們用它圖什麼呢?)
事實上,如果我們真的看完所謂23種設計模式,實際上只是在強調三個原則:封裝變化點、對接口進行編程、多使用組合而不是繼承。(這裏主要注意第一點)
好吧,進入下面的應用場景。
@考慮這樣一個應用場景:我們已經深刻的掌握了三層架構的要領(事實上並沒有。。。),並且使用了業內最牛叉的Aaron MVC框架來處理請求,一切都變得很美好。突然有一天,領導來了。。。
領導有一天突然發現,我們的UserService中的listUsers寫的不夠好,沒有另外一個小組編寫的UserService中實現的listUsers方法好,因爲另外一個小組在listUsers中加了一個小判斷,在列舉出來的用戶中,領導永遠排在第一個。
於是乎,領導二話不說,讓我們直接把Action中有引用到UserService的全部換成他們的UserService。
因爲我們的UserService是這樣子導入的:
|
1
|
import com.unis.team1.UserService; |
|
1
|
import com.unis.team2.UserService; |
如果很不湊巧,大家的命名方法不一樣,另外一個小組的名字叫做com.unis.team2.UserServ,我就不得不全文搜索將import com.unis.team1.UserService 改爲import com.unis.team2.UserServ , 同時,全文搜索將UserService改爲UserServ。
這一切的一切的罪惡的根源,源於如下的代碼:
|
1
2
3
4
5
|
import com.unis.team1.UserService; public UserAction{ UserService userService = new UserService(); ....... //參考struts2中需要的東西 } |
我們添加一個接口:
|
1
2
3
|
public interface IUSerService { List<User> listUsers(); } |
於是,導致罪惡的代碼被修改爲這樣:
|
1
2
3
4
5
|
import com.unis.service.UserService; public UserAction{ IUserService userService; ....... //參考struts2中需要的東西 } |
|
1
|
Animal cat = new Cat(); //Cat實現了Animal接口 |
回到剛纔的罪惡的代碼,我們在Action中定義了service的接口,可是那又怎麼樣呢?最終不還是需要new一個具體的實現嗎?如果我們new了UserService,後面需要替換的時候,還是需要換成new UserServ啊!
嗯,所以我們就要想辦法不需要自己在代碼中new!跟往常一樣,我們設計一個超級牛叉的Aaron Container框架,它能完美的和Aaron MVC結合。
我們定義瞭如上的UserAction,但是實際上我們真正使用的UserAction並不是我們自己new出來的,而是每次有一個請求到來的時候,由Aaron MVC創建的,創建的過程可以這麼去理解(實際上的情況要複雜的多,可以看出,Aaron MVC就是一個山寨版的struts2,action的創建遠遠比這個複雜!):
|
1
2
3
|
UserAction userAction = new UserAction(); IUserService userService = new UserService(); userAction.setUserService(userService); |
如果僅僅是爲了動態的替換實現類,就將所有本來一個類就能完成的事拆分成接口和實現類,好像也說不過去哦。。。不過,領導怎麼會這麼輕易地善罷甘休呢?
領導決定放大招了,他覺得既然我們現在已經分離出了BLL,那麼他希望BLL中的每一個方法執行前,都進行一次log記錄,記錄的格式大概如下:
“誰誰誰”於“什麼什麼時間”進行了“什麼什麼操作”
我可以罵人嗎?!在提幹的假設中,我們的項目已經做的很龐大了,也就是說,我們的BLL中有上百個類,上千個方法!也就是說,爲了領導的一句話,我們不得不Ctrl C V上千次,而且還有可能有遺漏。。。
是時候讓史上最牛叉的Aaron Container框架出場了!
上面已經說了,Aaron MVC會幫助我們自動生成Action,而當中如果有需要用的BLL中的接口,會被自動“注入”我們需要的實現類,我們修改一下這個過程:
|
1
2
3
|
UserAction userAction = new UserAction(); IUserService userService = AaronContainer.get(IUserService.class) userAction.setUserService(userService); |
先介紹一下可愛的代理模式吧。。。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
public interface Test { public void test(); } public AaronTest implements Test { public void test() { System.out.println(“hello world !”); } } public AaronTestProxy implements Test { public Test testImpl; public AaronTestProxy(Test test) { this.testImpl = test; } public void doBefore() { System.out.println(“do before !”); } public void doAfter() { System.out.println(“do after!”); } public void test() { this.doBefore(); this.testImpl.test(); this.doAfter(); } } |
|
1
2
|
Test test = new AaronTest(); test.test(); |
hello world !
但是如果我們使用代理類,我們可以這麼做:
|
1
2
|
Test test = new AaronTestProxy(new AaronTest()); test.test(); |
do before !
hello world !
do after !
相信聰明的孩子已經看出來了,通過代理類,我們可以在原本需要實現的方法實現之前/之後做點別的事。
而想要完成這一點,關鍵就在於——接口!
我們聲明需要的只是某一個接口,我們提供的是代理之後的實現。
我們將核心的邏輯放入接口實現類,而公共的非業務邏輯放入代理實現類,通過代理實現類包裝業務邏輯,我們就可以全心全意的將精力放入業務邏輯的實現,而將權限控制、日誌記錄、異常處理等功能,由代理類實現。(比如上面的doBefore方法,完全可以用來記錄日誌)
這也是設計模式第二個原則:面向接口編程。
現在假設我們的Aaron Container框架已經幫助我們代理了所有的service實現類(前提是,service都是接口!!!)於是乎,所有在需要service實現類的地方,我們都只是聲明一個接口,Aaron Container會自動將代理類注入進去!
而且,我們的Aaron Container框架已經聰敏的成精了,AaronContainer.get(IUserService.class)這個過程,返回的是包裝了我們所編寫的UserService的代理類,當我們執行當中的方法的時候,代理類首先先記錄一下日誌:
“誰誰誰”於“什麼什麼時間”調用了“什麼什麼方法”
然後再調用UserService中的我們所編寫的帶有業務邏輯的方法。
好了,現在我來總結一下這一套“複雜”的過程:
首先是我們將service分爲接口和實現。
然後在需要service方法的地方聲明瞭相應的接口。
OK,我們工作結束了。
然後,Aaron框架套件會幫助我們利用一些列高階的java技巧,完成剩下的工作。
將需要用到service的地方“注入”具體的“實現”,而這當中,所有的“具體實現”,不再是簡單的我們自己所編寫的service實現,而是經過包裝(也就是代理)後的代理實現類。
代理實現類很牛叉的幫助我們在運行具體業務邏輯方法之前/之後做點別的事,比如記錄一下日誌,檢測一下用戶權限是否匹配,事務的聲明什麼的。
理解上述的過程還是十分簡單的,不過我仍然要說一下,具有人工智能的Aaron框架套件仍處於開發中,所以我們還不能因爲我們的領導想添加日誌,框架就會幫助我們實現代理類的日誌記錄,所以我們需要自行編寫代理類的日誌記錄行爲(這當中的步驟遠比我形容的困難,我們甚至需要獲取到當前用戶的信息)。
現在我們來看一看Aaron Container到底做了些什麼吧:幫助我們生成某個接口實現類的代理類,在我們所有的編寫的需要這些實現類的地方,我們都不再需要人爲的“new”了,我們僅僅需要聲明我們需要這個接口,然後它會幫助我們將生成代理類“注入”到聲明瞭有接口的地方。因爲所有的代理類都是從Aaron Container“拿”出來的,所以運行的時候調用這些代理類的某個方法的時候,很容易就可以做到添加點別的功能,而無須修改我們自己編寫的那個實現類。
這就是所謂的依賴注入(或者高端大氣一點叫做控制反轉),我們無需自己new,僅僅只需要聲明,真正需要用到這個對象的時候會被“注入”進來。
好吧,這就是Spring的核心,一個大大的container,負責創建“實現了某個接口的業務邏輯對象”的代理對象(這麼說很狹隘,實際上要是願意,我們可以將大部分對象都交由Spring管理)。
Spring幫助我們管理需要被管理的對象的生命週期,簡單來說,就是我們可以通過配置文件,控制這些需要被管理的對象什麼時候生成,生成的時候加點什麼操作,什麼時候銷燬,銷燬的時候加點什麼操作(比如在銷燬的時候記錄一下日誌“我死了。。。”)什麼的,一切都變得可控了。
而且我們可以隨時替換具體的實現類,因爲我們在源代碼中並沒有硬編碼聲明我們需要new“哪一個”具體實現類!!
是的,這就是Spring的核心,聽起來好簡單,沒什麼大不了,但是的確就是這樣。
而Spring AOP(這個會在很多地方看到的專業術語),也只不過是因爲Spring幫助我們通過代理類管理了類的生成和注入從而纔有的“附加功能”。AOP的含義簡單來說,就像上面我們需要在每一個BLL中方法被調用時記錄一下日誌那樣,因爲所有的BLL中的具體實現類對象都由Spring來管理,當我們需要“橫切”,對所有對象統一的加一個“調用方法時記錄這個操作”這個操作時,只需要在一個地方聲明一下我們需要在方法調用之前進行日誌操作,就可以完成對所有BLL中的方法添加記錄日誌這個功能,這就是AOP。
再次記住這句話,依賴於接口,而不是依賴於具體的某一個類(通俗一點的說就是不要在代碼裏面直接new某個實現類對象),可以幫助我們減少很多代碼量,同時提高項目的擴展性,擴展性在於,我們不需要修改已有代碼(重中之重!!!),就可以替換行爲,而在java中,如果不面向接口編程,這是無論如何都做不到的。
再次給我摯愛的Ruby做一次廣告,爲什麼Ruby的開發速度比java快?爲什麼Ruby/Python不需要接口?
腳本語言在運行的時候可以動態的修改類裏面的行爲,而java需要先編譯,一旦編譯好的類,我們就無法再次去修改他們了,所以腳本語言不需要像java那樣,事先定義好很多接口才能玩轉設計模式(所以很多設計模式對於腳本語言來說,都是天生自然而然就能做到的,而不是很難的“編程技巧”)。
從這個角度來說,java/C#是擁有很強“契約精神”的語言,這種“限制”保證了我們可以在代碼量成幾何式增長之後仍舊能夠保持良好的結構,而且即使是新手,只要按照相應的“契約”,就能夠完成上面所交代的任務而不會影響別人的代碼。某種意義上來說,java項目更注重“架構”的設計,而Ruby項目更注重個人的編程能力。
正如黑格爾所說,太陽下面沒有新事物,隨着我們的項目從無到有,從小到大,代碼量成幾何式增長,於是我們爲了減少重複代碼量,將項目中可變的部分抽象出來。爲了減少因爲代碼改動而帶來的額外工作量,我們總結了一套設計模式。爲了用更少的代碼實現總結出來的設計模式,我們將當中公共的部分作爲模板(也就是框架),需要用到的時候直接利用這套模板就可以幫助我們專注於業務邏輯的實現而不是其他的條條框框。
嗯,讀到這裏的時候,我們已經可以人模人樣的做一些項目了,甚至在這個過程中,查看了一些主流框架的使用方法並且用上了他們,我們簡直就可以宣稱我們是一個合格的軟件工程師了!
其實。。。我們纔剛上路。
進入下面一個應用場景吧!
@考慮這樣一個應用場景:我們已經利用SSH(是的,就是那個很流行的Spring,Struts2,Hbiernate),人模人樣的將項目重新搭建起來了,代碼的結構瞬間變得無比清晰(雖然我相信百分之八十以上的人並不是真正理解SSH),這個時候,項目變得越來越龐大。。。
SSH在華人社區流行已久(主要是大陸和臺灣地區),其實我個人並不喜歡這三個框架的組合。在歐美地區,只有Spring是依然流行的。(實際上Spring的地位也在遭受很多輕量級IOC框架的挑戰)
在這次的應用場景中,我準備一次性講述多一點的東西,所以這次的假設會糟糕一點。
因爲開發人員衆多,經常會發生每個人的開發環境不一致,比如明明我們用的是Spring 3.0的jar包,卻偏偏有人用的是Spring 2.5的jar包。而且項目越做越大,我們不得已分成了幾個子項目,交由不同的團隊去做,可是經常發生其他團隊已經完成了bug fix並打出新包了,我們仍然在沿用以前的有bug的舊包!
以前寫過一篇關於Maven的簡單介紹,這次就直接copy過來了。
關於構建的概念:
很久很久之前,在我剛剛學習Java的時候,那個時候還是非常的菜的,有一次學習struts,需要做一個項目,當時的流程是這樣的(我相信很多人都時曾相識?):
1、熟練地打開eclipse,新建dynamic web項目
2、從struts官網下載最新的jar包(好多好多個jar文件啊)
3、不管三七二十一,刷的一下,把所有jar包放到WEB-INF/lib
4、開始寫代碼
5、右擊項目,導出war包,拷貝到tomcat的webapp下
這個過程看似沒有問題,直到後來實習的時候被項目經理狠批。這個過程中我根本就不知道我所需要的什麼jar包,不管有用的沒用的,全部放到lib下。這種做法不但會導致lib臃腫難以維護,而且根本無法保證所有開發人員的第三方依賴包版本一致。最關鍵的是,因爲每一次的打包動作,都需要開發人員從eclipse中右擊導出war包。想象一種情況:我們的項目中有一個依賴的jar包是另外一個開發小組所寫,如果我們需要進行最新的項目測試,我們首先得先讓另外一個開發小組將他們最新的代碼導出爲jar包,
然後將他們最新的jar包導 入我們項目的classpath(這個過程,是不是離開了eclipse大家就不會了?),然後繼續,右擊導出war包。如果我們依賴的多個jar包都是我們不同的團隊所寫,這個過程所耗費的時間將成集幾何的增長。
題外話:eclipse導出war包的原理:
我們每次通過eclipse創建dynamic web項目的時候, eclipse會自動幫我們創建一個src文件夾,WebContent文件夾,.project配置文件(其實根據插件的選用,隱藏配置文件會有很多個)。同時引入了一些列classpath:src、 WebContent/WEB-INF/lib、jvm核心依賴包、tomcat中的一些servlet依賴包、其他。。。當我們導出war包的時候,eclipse
首先根據.project中的配置,導入classpath中的依賴包(這也是爲什麼我們在初學階段,總是將需要用到的這些jar包放到WebContent/WEB-INF/lib中去),將src下的所有.java文件編譯(這也是爲什麼我們的源代碼總是要寫在src下才能被編譯),將生成的.class文件拷貝到 WebContent/WEB-INF/classes中。最後將WebContent打成war包輸出(war包的名字爲:項目名.war)。
回來繼續:
因爲這個過程絕對不可能由人來做(耗費時間太長而且沒有意義),於是後來我們就開始學習Ant來進行剛纔的操作。Ant的原理就是:指定好我們需要編譯的源代碼路徑(不管一個公司有多少項目,這些項目最新的源代碼路徑總是有的)、依賴的jar包位置(Ant會幫我們把這些依賴包引入到classpath中)、打包的方式(jar還是war等等之類)、以及打包的順序(就像最開始所說的那樣,可能某一個模塊的編譯需要依賴另外一個模塊,被依賴的源代碼會首先被編譯)。然後Ant就會幫我們編譯這些源代碼了,那些被依賴的jar會首先被編譯打包(會根據依賴樹進行打包順序),然後放到某個文件夾下,然後這些被依賴的jar包會被引入classpath,然後繼續編譯,最後,所有的源代碼編譯結束,將依賴的jar包們拷貝到WEB-INF/lib中,web層的.class們拷貝到WEB-INF/classes中。
刪除被打出來放到臨時目錄 的jar包們。將最後的war包拷貝到指定目錄,整個過程就結束了。
需要說明一下的是:平時我們在eclipse中,eclipse已經幫我們指定了servlet容器位置,所以我們不覺得有什麼不對勁,但是一旦自己手動打包的時候,我們必須手動指定servlet相關jar包的路徑並引入到classpath中!
在剛剛的過程中,我們發現,我們可以做到只需要一個命令:Ant自動幫我們根據順序依次打包最新的代碼,然後將最新的代碼進行打包,並且可以將生成的war包拷貝到指定目錄下,於是我們可以引入一些系統腳本,測試只需要執行一下某個腳本文件,就可以自動的將新鮮出爐的war包放入tomcat/jboss/jetty中,並啓動容器。之後什麼都不需要做,直接打開瀏覽器就可以測試啦!
這個過程之中的問題:
如果你寫過Ant的build.xml,也就是Ant的配置文件,你一定會發現這是一個痛苦的過程。首先,我們得指定第三方依賴包的路徑,雖然這樣能保證所有人引用第三方依賴包的版本一致,但是如果依賴包過多的話,需要編寫老長的一段說明。其次,我們需要指定項目源代碼的路徑,這樣是很長的一段說明(同一個項目不一定在同一個地方啊。。。像我之前所說的那樣,可能我們項目中的某個模塊,是由另一個團隊在別的路徑下編寫,最後我們只是引用他們所生成的jar包而已)。最後,也是最坑爹的事情,我們必須手動指定打包順序:如果a模塊依賴b模塊和c模塊(這三個模塊都是我們自己開發),b模塊依賴c模塊,我們必須先打包c模塊,然後再打包b模塊(同時引用c模塊打好的包),最後打包a模塊(同時引用b模塊和c模塊打好的包)。這纔是最簡單的一種情況呀,隨着項目的模塊化,這種關係可能會變得更加複雜,打包順序也需要考慮好一會,即使我們很聰明,這種樹形順序難不倒我們,編寫xml也是一個很煩人的任務啊。
Maven的出現:
我們可以簡單的認爲,Maven也是爲了完成上面的任務所誕生的,但是相比較於Ant,我們所需要編寫的xml將會驟減不少。而且,在大多數的時候,打包順序這種費腦經的事,Maven可以依據依賴關係自動幫我們完成。
同時,Maven不但可以完成了上述Ant所寫的所有功能,還有額外的一些功能,幫助我們縮短開發時間:
我們不必再自己去各個第三方依賴包官網手動下載依賴包了,只要申明瞭我需要某個jar包的某個版本,Maven會自動幫我們下載下來並在編譯、打包的時候引用。
Maven貫穿項目整個生命週期,從早期的依賴包下載到後期的打包部署,在編譯過程中,找到測試代碼,運行jUnit等工具進行測試並生成測試報告。
Maven比Ant更進一步,更像一個部署工具,依靠插件,可以在運行Maven命令之後,甚至連數據庫初始化這個工作都可以幫我們做了,在編譯之後,將項目拷貝至容器並啓動容器,真正做到“開箱即測”。
Maven的使用:
自行百度吧。。。
Maven的出現實際上是爲了適應我們項目越來越複雜,開發人員越來越多,依賴包越來越龐大,同時拆分爲更多子項目,打包過程繁瑣,自動化測試程度越來越高的發展需要。
我原本覺得下一章應該進入自動化測試的介紹了,但自動化測試絕對是一個無窮無盡的深坑。。。所以我就簡單描述一下,在自動化測試中,所有的操作必須由代碼來模擬,測試過程中不會有人的干預,所有用例均由代碼控制。作爲開發人員,我們提供出去的每一個方法都有相應的測試用例,最終會在編譯過程中自動由Maven進行測試並生成報告。
進入最後一個應用場景
@考慮這樣一個應用場景:有一天我們領導發現,單頁面應用變得火爆起來,於是讓我們將項目轉爲單頁面應用
首先還是得解釋一下什麼是單頁面應用。
傳統的網站在頁面上會有各種的超鏈接以及表單按鈕,通過點擊這些超鏈接或者表單按鈕,我們會訪問不同的網站,如果我們有當當購書的經驗,就會知道,當我們點擊了購買按鈕時,我們會跳轉到支付頁面,當完成支付時,我們會跳轉到購買成功的頁面,我們不斷地在跳轉,也沒有覺得有什麼不對。
的確,事實上這沒有什麼不對。
還記得google maps嗎?那個超炫的頁面,我們在頁面上滾動鼠標中論,就可以實現地圖的放大和縮小,我們不斷地像後臺發送請求,後臺也一直在反饋,可是至始至終,我們都沒有進行過頁面的跳轉。
這就是ajax,它負責將用戶的請求發送到服務端,然後將接收到的返回數據渲染到當前html中。在這過程中,一直都是在早已渲染好了的html中進行操作。
很自然而然的,因爲沒有頁面的全局刷新,我們就像在操縱本地軟件那樣操作進行操作,正如single app一詞,它就像一個app而不是一個網站。
在具體介紹之前,我們先老生常談一個問題,如何實現MVC?
我去,這個問題在第一個場景中不就已經講過了嗎。
正如下面所見:
|
|
 |
由Controller接收請求,將數據封裝爲 Model 的形式,並將其傳入 View 中,毫無難度。
好吧,不是我侮辱大家智商,只是,很多事情並不是我們想當然的那樣,正所謂,世事無絕對嘛。
我們來看這張圖:
|
|
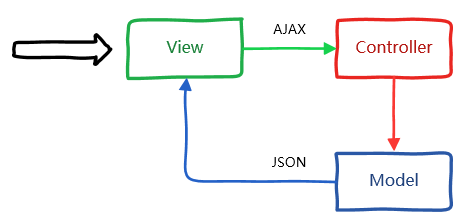 |
在上圖的MVC模式中,我們直接在 HTML(也就是 View)中發送 AJAX 請求,該請求由 Action(也就是 Controller)接收,隨後將數據模型轉爲 JSON 格式返回到 HTML 中。
早期前端都是比較簡單,基本以頁面爲工作單元,內容以瀏覽型爲主,也偶爾有簡單的表單操作,這個時期每個界面上只有很少的JavaScript邏輯。
隨着AJAX的出現,Web2.0的興起,人們可以在頁面上可以做比較複雜的事情了,js針對DOM的操作越來越頻繁,於是出現了以簡化DOM操作、屏蔽瀏覽器差異的js庫jQuery。(jQuery僅僅是js庫,不是框架。。。)
伴隨着一些Web產品逐漸往應用方向發展,遇到了在C/S領域相同的問題:由於前端功能的增強、代碼的膨脹,js代碼變得越來越混亂。
於是我們想起了曾經在後臺使用過的方法,各種基於MVC變種模式的前端框架應運而生。