




awk 其實是一門編程語言,它,支持條件判斷、數組、循環等功能,我們可以把它理解成一個腳本語言解釋器
它與grep、sed被linux稱爲"三劍客"
每個都有它的特長
grep 更適合單純的去查找或者匹配文本
sed 更適合編輯匹配到的文本
awk 更適合格式化文本,對文本進行較複雜格式處理
一、AWK基礎
awk的基本用法
格式
awk 動作 文件名/文件名/awk/動作
如果不指定任何參數直接使用awk
格式是這樣的
awk '{print}' 文件
直接回輸出整個文件,相當於shell中的cat命令
示例
[root@zhaocheng ~]# awk '{print}' echo.sh
#!/bin/bash
echo "shucai"\b"niunai"取free -m文件的第3列,這樣取的話,我們可以直接去使用free -m 先讓它輸出,然後通過管道再去取它的第三列,像取第三列的話,其實中間還是有分隔符的,也就是空格,不指定分隔符,默認將空格作爲分隔符了
[root@zhaocheng ~]# free -m |awk '{print $3}'
free
115
0也可以去取多個列,以,分開,比如還是取free -m,取它的第2,3,4列
[root@zhaocheng ~]# free -m |awk '{print $2,$3,$4}'
used free shared
1838 116 339
0 0 0另外awk還支持對文本的處理,添加字符串,像這個/etc/passwd文件中就是看起來是有列的,但是awk默認不加-F是先按空格去提取的,而這個沒有所以添加了一個":"當作文本的分隔符
格式
'{print $1,"hello"}'
'{print $1,$2,"hello"}'
'{print $1,"net",$2,"hello"}'
[root@zhaocheng ~]# awk -F ":" '{print $1,$2,"hello"}' test
root x hello
bin x hello
daemon x hello
adm x hello
lp x hello
sync x hello
shutdown x hello
halt x hello
[root@zhaocheng ~]# awk -F ":" '{print $1,"net",$2,"hello"}' test
root net x hello
bin net x hello
daemon net x hello
adm net x hello
lp net x hello
sync net x hello
shutdown net x hello
halt net x hello而它的格式也是'{print $1}'中間不能加引號,不然會當成普通字符給輸出
[root@zhaocheng ~]# awk -F ":" '{print "$1"}' test
$1
$1
$1
$1
$1
$1
$1
$1
[root@zhaocheng ~]# awk -F ":" '{print '$1'}' test
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt比如打印文件,也就是相當於cat命令一樣去用了,這裏awk給出兩個用法,第一個就是可以使用awk '{print $0}'或者可以使用awk '{print}',這兩種都可以打印出來
[root@zhaocheng ~]# echo "Learn awk to improve your Linux skills" |awk '{print}'
Learn awk to improve your Linux skills
[root@zhaocheng ~]# echo "Learn awk to improve your Linux skills" |awk '{print $0}'
Learn awk to improve your Linux skills而$0表示顯示整行,$NF表示當前行分隔後的最後一列($0和$NF均爲內置變量)
每行的倒數第二列都可以寫成$(NF-1)
[root@zhaocheng ~]# awk -F: '{print $(NF-1)}' test
/root
/bin
/sbin
/var/adm
/var/spool/lpd
/sbin
/sbin
/sbin
[root@zhaocheng ~]# awk -F: '{print $NF}' test
/bin/bash
/sbin/nologin
/sbin/nologin
/sbin/nologin
/sbin/nologin
/bin/sync
/sbin/shutdown
/sbin/haltawk包含了兩種特殊的模式:BEGIN和END
BEGIN模式是指定了處理文本之前需要執行的操作
END模式指定了處理完所有行之後所需要執行的操作
這個BEGIN可以看到,即使我們後面指定了輸出源,但是它還是隻打印了前面的字符,這也就是BEGIN的模式
[root@zhaocheng ~]# awk 'BEGIN{print "one","two"}'
one
[root@zhaocheng ~]# cat filetest
root:$1$dDTFylQ3$.vTZKpm7mrra9WMsxvBfW.:18241:0:99999:7
bin:*:17834:0:99999:7:dad
lp:*:17834:0:99999:7ada
sync:*:17834:0:99999:7:::gg
shutdown:*:17834:0:99999:7::da
halt:*:17834:0:99999:7::fsda
nginx:!!:18289::::::daaf
rabbitmq:!!:18297:::::dada二、AWK的分隔符
awk的分隔符的使用,這裏可以使用多種方法
-F 以什麼爲分隔符,來取第二列和第三列,-F:,-F"",-F''三種辦法都可以使用去取這個值
[root@zhaocheng ~]# awk -F: '{print $2,$3}' test
x 0
x 1
x 2
x 3
x 4
x 5
x 6
x 7
[root@zhaocheng ~]# awk -F ":" '{print $2,$3}' test
x 0
x 1
x 2
x 3
x 4
x 5
x 6
x 7
[root@zhaocheng ~]# awk -F ':' '{print $2,$3}' test
x 0
x 1
x 2
x 3
x 4
x 5
x 6
x 7除了-F選項,還能通過設置內部變量的方式,指定awk的輸入分隔符,awk內置變量FS可以用於指定輸入分隔符,但在使用變量時,需要使用-v選項,這裏使用"",''都可以
[root@zhaocheng ~]# awk -v FS=':' '{print $2,$3}' test
x 0
x 1
x 2
x 3
x 4
x 5
x 6
x 7
[root@zhaocheng ~]# awk -v FS=":" '{print $2,$3}' test
x 0
x 1
x 2
x 3
x 4
x 5
x 6
x 7awk的語法如下
**awk [選項] '模式{動作}' file
而-F 就是選項的一種,一般用於指定分隔符 -v也是選項的一種,用於設置變量的值
而AWK的分隔符又分爲輸入分隔符和輸出分隔符
輸入分隔符:也就是在輸入命令的時候以:,#爲分隔符的時候這就是我們輸入的分隔符
輸出分隔符:也就是當我們以#爲分隔符的時候,輸出的結果會有空格隔開,這就是我們的輸出分隔符,實際上沒有輸出出來
當然我們也可以將我們的輸出分隔符以awk的內置變量OFS進行輸出出來顯示,使用變量的時候需要加-v選項,OFS相當於以空格爲分隔符了**
[root@zhaocheng ~]# cat test1
aaa bbb ooo
cccc dddd eeee
fffff ggggg hhhhh
kkkkk pppppp ssssss
[root@zhaocheng ~]# awk -v OFS="********" '{print $2,$3}' test1
bbb********ooo
dddd********eeee
ggggg********hhhhh
pppppp********ssssss如果想以中間的符號爲分隔符可以以FS=":"當分隔符來,同時指定輸入分隔符和輸出分隔符
[root@zhaocheng ~]# cat test
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
[root@zhaocheng ~]# awk -v FS=":" -v OFS="********" '{print $2,$3}' test
x********0
x********1
x********2
x********3
x********4
x********5
x********6
x********7剛纔使用的是輸出分隔符想讓中間的空格用指定輸出隔開,如果不使用中間的符號進行隔開,直接進行合併的話,只需要將$1 $2分開,不加,號,一個是連接一起顯示,一個是以分隔符進行顯示
[root@zhaocheng ~]# awk '{print $1 $2}' test1
aaabbb
ccccdddd
fffffggggg
kkkkkpppppp
[root@zhaocheng ~]# awk '{print $1,$2}' test1
aaa bbb
cccc dddd
fffff ggggg
kkkkk pppppp三、AWK的變量
對於awk來說“變量”又分爲‘內置變量和’自定義變量“ ,”輸入分隔符FS,和輸出分隔符“OFS都屬於內置變量
awk的常用內置變量以及作用
FS:輸入字段分隔符,默認爲空白字符
OFS:輸出字段分隔符,默認爲空白字符
RS:輸入記錄分隔(輸入換行符)指定輸入時的換行符
ORS:輸入記錄分隔符(輸出換行符),輸出時用指定符號代替換行符
NF:當前行的字段的個數(即當前行被分隔成了幾列),字段數量
NR:行號,當前處理的文本行的行號
FNR:各文件分別計數的行號
FILENAME:當前文件名
ARGC:命令行的參數的個數
ARGV: 數組,保存的是命令行所給定的各參數
剛纔的FS和OFS都用過了,FS是輸入分隔符,OFS是輸出分隔符,默認都是空白字符,比如FS以什麼爲分隔符-v FS=":"以:爲分隔符,輸出的時候一般不加後門的OFS顯示以空格分隔,如果在輸出格式添加,需要指定-v OFS=""將空格替換成來展示
內置變量NR、NF
剛纔說到NR,其實就是當前文本的行號,一共幾行
NF就是一行中有幾列,一般以空格爲分隔符
這裏一共4列,使用NR直接顯示了行號
[root@zhaocheng ~]# cat test1
aaa bbb ooo
cccc dddd eeee
fffff ggggg hhhhh
kkkkk pppppp ssssss
[root@zhaocheng ~]# awk '{print NR}' test1
1
2
3
4這裏每行中有3列,所以使用NF就能統計出有多少列
[root@zhaocheng ~]# awk '{print NR,NF}' test1
1 3
2 3
3 3
4 3統計test文件有多少行,使用行號進行排序
可以使用awk的{print $0 NR}'
[root@zhaocheng ~]# awk '{print NR,$0 }' test
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8 halt:x:7:0:halt:/sbin:/sbin/halt或者使用cat -n 也是統計行號的
[root@zhaocheng ~]# awk '{print}' test |cat -n
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8 halt:x:7:0:halt:/sbin:/sbin/halt在bash語法中一般使用變量比如打印第一行需要$1,第二行$2,那麼在awk中,不管使用內置變量還是自定義變量都不需要加$
內置變量FNR
這個一般是處理多個文件的同時來記錄行號的內置變量,如果匹配多個文件的話,使用NR來記錄行號只會按順序直接排列,使用FNR會分開排列
[root@zhaocheng ~]# awk '{print NR,$0}' test test1
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8 halt:x:7:0:halt:/sbin:/sbin/halt
9 aaa bbb ooo
10 cccc dddd eeee
11 fffff ggggg hhhhh
12 kkkkk pppppp ssssss
[root@zhaocheng ~]# awk '{print FNR,$0}' test test1
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8 halt:x:7:0:halt:/sbin:/sbin/halt
1 aaa bbb ooo
2 cccc dddd eeee
3 fffff ggggg hhhhh
4 kkkkk pppppp ssssss內置變量RS
RS是輸入行分隔符,如果不指定,默認的行分隔符就是我們理解的回車換行
[root@zhaocheng ~]# awk -v RS=" " '{print NR,$0}' test1
1 aaa
2 bbb
3 ooo
cccc
4 dddd
5 eeee
fffff
6 ggggg
7 hhhhh
kkkkk
8 pppppp
9 ssssss內置變量ORS
這個和ORS的換行符差不多,只不過在指定輸出行分隔符+++的時候另換一行
[root@zhaocheng ~]# awk -v ORS="++++" '{print NR,$0}' test1
1 aaa bbb ooo++++2 cccc dddd eeee++++3 fffff ggggg hhhhh++++4 kkkkk pppppp ssssss++++[root@zhaocheng ~]# 內置變量FILENAME
FILENAME這個內置變量從字面上,可以看出是什麼意思,就是顯示文件名,使用指定多文件的FNR,統計行號,在前面並打印出這個文件的名稱
[root@zhaocheng ~]# awk '{print FILENAME,FNR,$0}' test1 test
test1 1 aaa bbb ooo
test1 2 cccc dddd eeee
test1 3 fffff ggggg hhhhh
test1 4 kkkkk pppppp ssssss
test 1 root:x:0:0:root:/root:/bin/bash
test 2 bin:x:1:1:bin:/bin:/sbin/nologin
test 3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
test 4 adm:x:3:4:adm:/var/adm:/sbin/nologin
test 5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
test 6 sync:x:5:0:sync:/sbin:/bin/sync
test 7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
test 8 halt:x:7:0:halt:/sbin:/sbin/halt內置變量ARGV與ARGC
ARGV內置變量表示的是一個數組,這個數組中保存的是命令行所給定的參數
[root@zhaocheng ~]# awk 'BEGIN{print "aaa"}' test test1
aaa
[root@zhaocheng ~]# awk 'BEGIN{print "aaa",ARGV[1]}' test test1
aaa test
[root@zhaocheng ~]# awk 'BEGIN{print "aaa",ARGV[2]}' test test1
aaa test1
[root@zhaocheng ~]# awk 'BEGIN{print "aaa",ARGV[1],ARGV[2]}' test test1
aaa test test1從上面看出ARGV內置變量表示的是一個數組,第一個數組就是test,第二個就是test1這個文件,而ARGV[0]這個就是我們本身的內置變量awk
[root@zhaocheng ~]# awk 'BEGIN{print "aaa",ARGV[0],ARGV[1],ARGV[2]}' test test1
aaa awk test test1而這個ARGC就是統計整個變量的數量
[root@zhaocheng ~]# awk 'BEGIN{print "aaa",ARGV[0],ARGV[1],ARGV[2],ARGC}' test test1
aaa awk test test1 3自定義變量
自定義變量就是給用戶定義變量
[root@zhaocheng ~]# awk -v www="1234" 'BEGIN{print www}'
1234
[root@zhaocheng ~]# awk 'BEGIN{www="1234" ; print www}'
1234
一次性定義多個變量
[root@zhaocheng ~]# awk 'BEGIN{www="1234"; baidu="4567" ; print www , baidu}'
1234 4567四、AWK格式化
對比print 和printf的區別,可以看出print 可以取$1的內容,而printf不會輸出換行符,默認會將文本輸出在一行裏面
[root@zhaocheng ~]# awk '{print $1}' test1
aaa
cccc
fffff
kkkkk
[root@zhaocheng ~]# awk '{printf $1}' test1
aaaccccfffffkkkkk[root@zhaocheng ~]# 如果使用printf的格式替換符的話也可以將printf的格式打印出來
[root@zhaocheng ~]# awk '{printf "%s\n" ,$1}' test1
aaa
cccc
fffff
kkkkk使用printf用法的是時候需要格式與列需要用逗號隔開,另外就是打印字符串的時候,可以通過\n,或者%s\n來替換
[root@zhaocheng ~]# printf "helloya\n"
helloya
[root@zhaocheng ~]# printf "%s\n" helloya
helloya在使用awk中的printf動作的時候需要注意點
1)使用printf動作輸出的文本不會換行,如果需要換行,可以在對應的格式替換符後加入\n進行轉義
2)使用printf動作時,指定的格式與被格式化的文本之間,需要用逗號隔開
3)使用printf動作時,格式中的格式替換符必須與被格式化的文本 一一對應
可以利用格式替換符對文本中的每一列進行格式化
針對空格進行使用awk與printf打印格式化,默認不使用輸入分隔符就是空格
[root@zhaocheng ~]# cat test1
aaa bbb ooo
cccc dddd eeee
fffff ggggg hhhhh
kkkkk pppppp ssssss[root@zhaocheng ~]# awk '{printf "%s\n",$1}' test1
aaa
cccc
fffff
kkkkk
[root@zhaocheng ~]# awk '{printf "第一列 %s\n",$1}' test1
第一列 aaa
第一列 cccc
第一列 fffff
第一列 kkkkk
[root@zhaocheng ~]# awk '{printf " 第一列 %s 第二列 %s\n" ,$1,$2}' test1
第一列 aaa 第二列 bbb
第一列 cccc 第二列 dddd
第一列 fffff 第二列 ggggg
第一列 kkkkk 第二列 pppppp
[root@zhaocheng ~]# awk '{printf " 第二列 %s\n",$2}' test1
第二列 bbb
第二列 dddd
第二列 ggggg
第二列 pppppp
[root@zhaocheng ~]# awk '{printf " 第三列 %s\n",$3}' test1
第三列 ooo
第三列 eeee
第三列 hhhhh
第三列 ssssss
[root@zhaocheng ~]# awk '{printf "第一列 %s 第三列 %s\n",$1,$3}' test1
第一列 aaa 第三列 ooo
第一列 cccc 第三列 eeee
第一列 fffff 第三列 hhhhh
第一列 kkkkk 第三列 ssssss
[root@zhaocheng ~]# awk '{printf "第一列 %s 第二列 %s 第三列 %s\n",$1,$2,$3}' test1
第一列 aaa 第二列 bbb 第三列 ooo
第一列 cccc 第二列 dddd 第三列 eeee
第一列 fffff 第二列 ggggg 第三列 hhhhh
第一列 kkkkk 第二列 pppppp 第三列 ssssss對於有分隔符的#來實現格式化
[root@zhaocheng ~]# cat test2
aaa#bbb#ooo
cccc#dddd#eeee
fffff#ggggg#hhhhh
kkkkk#pppppp#ssssss普通使用 -v FS輸入分隔符,以#分隔
[root@zhaocheng ~]# awk -v FS="#" '{print $1,$2}' test2
aaa bbb
cccc dddd
fffff ggggg
kkkkk pppppp
普通使用-v OFS 輸出分隔符
[root@zhaocheng ~]# awk -v FS="#" -v OFS="####" '{print $1,$2}' test2
aaa####bbb
cccc####dddd
fffff####ggggg
kkkkk####pppppp使用printf格式化輸出
[root@zhaocheng ~]# awk -v FS="#" '{printf "第一列 %s\n" ,$1}' test2
第一列 aaa
第一列 cccc
第一列 fffff
第一列 kkkkk
[root@zhaocheng ~]# awk -v FS="#" '{printf "第一列 %s 第二列 %s \n" ,$1,$2}' test2
第一列 aaa 第二列 bbb
第一列 cccc 第二列 dddd
第一列 fffff 第二列 ggggg
第一列 kkkkk 第二列 pppppp結合BEGIN處理文本之前需要執行的操作,與printf結合使用
[root@zhaocheng ~]# awk 'BEGIN{printf "%1s\t %s\n" ,"用戶名稱","用戶ID"}' test1
用戶名稱 用戶ID
[root@zhaocheng ~]# awk 'BEGIN{printf "%1s\t %s\n" ,"用戶名稱","用戶ID"} {printf "%1s\t %10s\n" , $1,$2}' test1
用戶名稱 用戶ID
aaa bbb
cccc dddd
fffff ggggg
kkkkk pppppp以#爲分隔符進行格式化文本
[root@zhaocheng ~]# awk -v FS="#" 'BEGIN{printf "%1s\t %s\n" ,"用戶名稱","用戶ID"} {printf "%1s\t %10s\n" , $1,$2}' test2
用戶名稱 用戶ID
aaa bbb
cccc dddd
fffff ggggg
kkkkk pppppp五、AWK模式(pattern)
對於awk使用語法
awk [options] 'Pattern {Action}' file1 file2 ...
awk -v FS=":" 'BEGIN{print/printf %1s\t %s\n","x x x", "xxxx"} {xxx}' file
對於options(選項),使用過 -F選項,也使用過 -v選項
對於Acation(動作),使用過print與printf
對於Pattern(模式),使用過BEGIN模式與END模式
下面熟悉一個awk的條件,也就是awk會先處理完當前行,在處理下一行,如果我們不指定任何“條件”,awk會一行一行的處理文本中的每一行,如果我們指定來條件,只有滿足條件的的行纔會被處理,不滿足條件的行就不會被處理,這就是awk中的模式其實在當awk進行逐行處理的時候,會把pattern(模式)作爲條件,判斷將要被處理的行是否滿足條件,是否能跟模式想匹配,如果匹配就處理,如果不匹配,則不進行處理
NF==4之前我們使用NF的時候是統計有多少列每行,NF==4也就是有4列的行,然後打印出來
[root@zhaocheng ~]# awk 'NF==4 {print}' test1
fffff ggggg hhhhh bbbbb
[root@zhaocheng ~]# awk 'NF==5 {print}' test1
kkkkk pppppp ssssss xxxxxx mmmmmmmm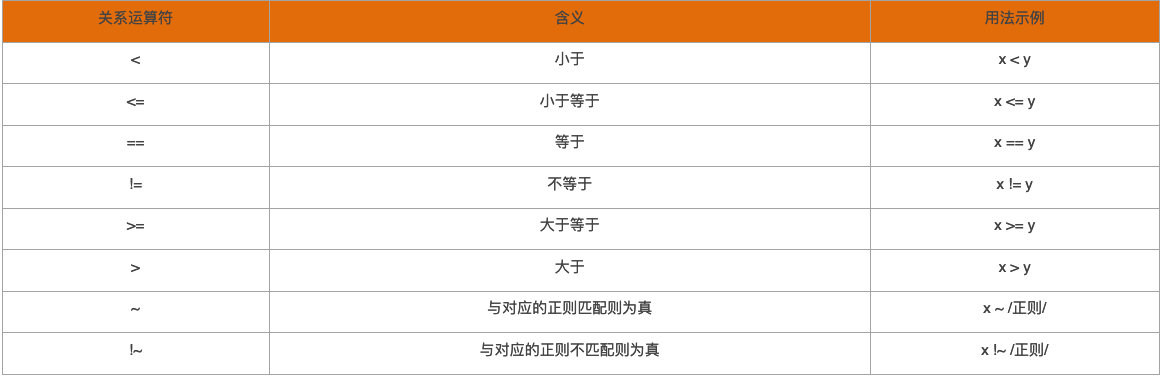
這就是awk使用到的關係表達式,比如==,<,>,<=,>=,也就是得到的結果爲真時,則滿足條件,與指定模式想匹配,滿足時就會執行相應的動作。
示例
[root@zhaocheng ~]# cat test1
aaa bbb ooo
cccc dddd eeee
fffff ggggg hhhhh bbbbb
kkkkk pppppp ssssss xxxxxx mmmmmmmm
大於4列的行
[root@zhaocheng ~]# awk 'NF>4 {print $0}' test1
kkkkk pppppp ssssss xxxxxx mmmmmmmm
大於等於4列的行
[root@zhaocheng ~]# awk 'NF>=4 {print $0}' test1
fffff ggggg hhhhh bbbbb
kkkkk pppppp ssssss xxxxxx mmmmmmmm
小於等於4列的行
[root@zhaocheng ~]# awk 'NF<=4 {print $0}' test1
aaa bbb ooo
cccc dddd eeee
fffff ggggg hhhhh bbbbb實際上awk有四種pattern模式
第一種就是BEGIN,表示在開始處理文本之前,需要執行的操作
第二種時END模式,表示將所有行都處理完畢後,需要執行的操作
第三種就是關係運算模式,剛纔我們用到的NF==xx
第四種就是空模式,就是相當於awk '{print $0}' file,空模式會匹配文本中每一行,所以每一行都滿足條件,每一行都會執行動作
熟悉一下END模式,ENGIN就是開始先處理什麼,END就是最後處理什麼
示例
[root@zhaocheng ~]# awk 'BEGIN{print "開始","開始"} {print $1,$2} END{print "結束","結束"}' test1
開始 開始
aaa bbb
cccc dddd
fffff ggggg
kkkkk pppppp
結束 結束