




驅逐管理是kubelet自我保護的一種機制,當資源缺乏的時候,通過閾值和策略主動驅逐部分的Pod從而保持系統的資源水位在一個合理的範圍內,本身的策略官方文檔上已經寫的很詳細,今天只是看下其在代碼上的一些設計
1. 設計臆測
1.1 驅逐總體流程
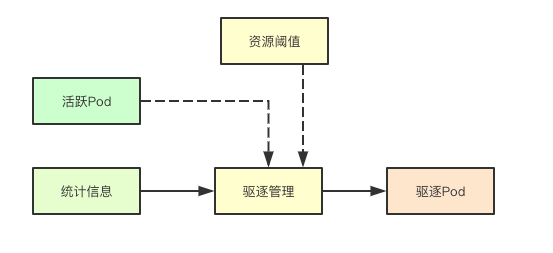
驅逐總體流程主要是通過獲取當前使用資源的統計信息和當前活躍的Pod容器列表,然後結合資源閾值來決策是否需要進行Pod的驅逐
1.2 基於觀察者模式的觀測
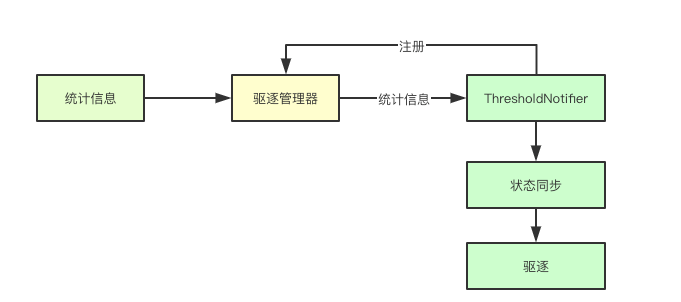
在驅逐管理器中基於觀察者模式實現對特殊資源驅逐管理的支持,比如內存資源,在某些情況下即時當前的資源水位沒有達到閾值,也可能會觸發oom killer這個時候,對應的ThresholdNotifier也會嘗試進行狀態同步,從而確定是否要主動的驅逐一些節點, 目前這個特性應該還沒開, 同理如果這個資源有專屬的閾值監測,則在後續驅逐Pod的時候,如果是由該資源觸發的驅逐,則優先級會被降低
2. 核心數據結構
驅逐管理器內部有很多的數據結構,這裏我們只關注其整體實現的關鍵數據結構
2.1 閾值與信號
2.1.1 Signal
kubelet主要是根據當前系統中的資源來進行驅逐決策的,而信號就表示某種具體可以觸發驅逐的資源,比如可用內存,在驅逐決策的時候,會根據統計信息來進行對應資源的計算
type Signal string
const (
// 省略其他資源
SignalMemoryAvailable Signal = "memory.available"
SignalNodeFsAvailable Signal = "nodefs.available"
)2.1.2 Threshold
信號表示某種資源,而Threshold則表示某類資源的閾值
type Threshold struct {
Signal Signal
Operator ThresholdOperator
Value ThresholdValue
GracePeriod time.Duration
MinReclaim *ThresholdValue
}
3. 驅逐核心流程

3.1 資源準備階段
資源準備階段,主要是爲後面的決策做準備,首先要獲取當前所有活躍的pod信息(後面從中挑選可以驅逐的Pod), 然後還要獲取當前的統計信息、閾值
thresholds := m.config.Thresholds
// 獲取Pod活躍信息
activePods := podFunc()
updateStats := true
// 獲取統計信息
summary, err := m.summaryProvider.Get(updateStats)3.2 週期性閾值監測
針對之前註冊的專有資源的閾值則會嘗試通知進行檢測,
if m.clock.Since(m.thresholdsLastUpdated) > notifierRefreshInterval {
m.thresholdsLastUpdated = m.clock.Now()
for _, notifier := range m.thresholdNotifiers {
// 更新summary通知
if err := notifier.UpdateThreshold(summary); err != nil {
klog.Warningf("eviction manager: failed to update %s: %v", notifier.Description(), err)
}
}
}3.3 獲取觀測狀態
首先第一步會通過統計信息來獲取當前已經觀測的信號的真實使用資源
observations, statsFunc := makeSignalObservations(summary)
func makeSignalObservations(summary *statsapi.Summary) (signalObservations, statsFunc) {
statsFunc := cachedStatsFunc(summary.Pods)
result := signalObservations{}
if memory := summary.Node.Memory; memory != nil && memory.AvailableBytes != nil && memory.WorkingSetBytes != nil {
result[evictionapi.SignalMemoryAvailable] = signalObservation{
available: resource.NewQuantity(int64(*memory.AvailableBytes), resource.BinarySI),
capacity: resource.NewQuantity(int64(*memory.AvailableBytes+*memory.WorkingSetBytes), resource.BinarySI),
time: memory.Time,
}
}
// 省略大部分信息
return result, statsFunc
}3.4 獲取被處罰的閾值
通過當前的觀測狀態和之前的所有配置的閾值配置,來進行獲取那些被處罰的閾值, 這裏最後一個false表示當前這是第一次檢測,先不要使用強制最小回收
thresholds = thresholdsMet(thresholds, observations, false)3.5 閾值檢測實現
閾值檢測主要是通過觀測的狀態裏面對應資源的容量和閾值,確定對應的容量信息,然後與實際的資源統計信息進行對比,如果超過則表明當前閾值達到,其中enforceMinReclaim則是否強制最小回收,只需要在實際容量裏面加上強制最小回收那部分資源,就實現了
func thresholdsMet(thresholds []evictionapi.Threshold, observations signalObservations, enforceMinReclaim bool) []evictionapi.Threshold {
results := []evictionapi.Threshold{}
for i := range thresholds {
threshold := thresholds[i]
// 獲取當前閾值信號的觀測狀態
observed, found := observations[threshold.Signal]
if !found {
klog.Warningf("eviction manager: no observation found for eviction signal %v", threshold.Signal)
continue
}
// 確定是否達到閾值
thresholdMet := false
// 計算
quantity := evictionapi.GetThresholdQuantity(threshold.Value, observed.capacity)
// 如果指定了enforceMinReclaim,則比較相對於值-minreclaim
if enforceMinReclaim && threshold.MinReclaim != nil {
// 強制最小回收,其實就是在之前閾值的基礎上,在加上最小回收的資源
quantity.Add(*evictionapi.GetThresholdQuantity(*threshold.MinReclaim, observed.capacity))
}
thresholdResult := quantity.Cmp(*observed.available)
switch threshold.Operator {
case evictionapi.OpLessThan:
thresholdMet = thresholdResult > 0
}
if thresholdMet {
results = append(results, threshold)
}
}
return results
}3.6 前後閾值合併
每次檢測完畢後,evictionManager都會講本輪所有觸發的閾值保存在自身的thresholdsMet字段中,在下一輪會檢測該資源是否得到滿足,即通過之前的閾值和當前的觀測狀態來進行對比,從而發現那些依舊未被滿足的閾值,合併到本輪的閾值中
if len(m.thresholdsMet) > 0 {
// 沒有被解決的thresholdMet, 進行合併
thresholdsNotYetResolved := thresholdsMet(m.thresholdsMet, observations, true)
thresholds = mergeThresholds(thresholds, thresholdsNotYetResolved)
}3.7 NodeConditions
在檢測到有閾值被觸發的時候,會根據閾值的信號類型來進行篩選,如果是對應的資源的類型有壓力,則會在kubelet的准入控制在pod創建的時候,可能會不允許Pod的創建
nodeConditions := nodeConditions(thresholds)
if len(nodeConditions) > 0 {
klog.V(3).Infof("eviction manager: node conditions - observed: %v", nodeConditions)
}
nodeConditionsLastObservedAt := nodeConditionsLastObservedAt(nodeConditions, m.nodeConditionsLastObservedAt, now)
nodeConditions = nodeConditionsObservedSince(nodeConditionsLastObservedAt, m.config.PressureTransitionPeriod, now)
if len(nodeConditions) > 0 {
klog.V(3).Infof("eviction manager: node conditions - transition period not met: %v", nodeConditions)
}
3.8 保存內部狀態
// update internal state
m.Lock()
m.nodeConditions = nodeConditions
m.thresholdsFirstObservedAt = thresholdsFirstObservedAt
m.nodeConditionsLastObservedAt = nodeConditionsLastObservedAt
m.thresholdsMet = thresholds
// determine the set of thresholds whose stats have been updated since the last sync
thresholds = thresholdsUpdatedStats(thresholds, observations, m.lastObservations)
debugLogThresholdsWithObservation("thresholds - updated stats", thresholds, observations)
m.lastObservations = observations
m.Unlock()3.9 本地臨時存儲驅逐策略
針對本地臨時存儲資源的計算,主要是計算emptyDIr、臨時Pod存儲、容器日誌幾個本地臨時存儲資源的統計,進行pod的驅逐
if utilfeature.DefaultFeatureGate.Enabled(features.LocalStorageCapacityIsolation) {
if evictedPods := m.localStorageEviction(summary, activePods); len(evictedPods) > 0 {
return evictedPods
}
}3.10 最小化驅逐閾值驅逐策略
首先會嘗試找到那些配置了最小化資源的進行搶佔
thresholdToReclaim, resourceToReclaim, foundAny := getReclaimableThreshold(thresholds)
if !foundAny {
return nil
}3.11 優先級排序
根據對應的資源類型和當前的活躍的pod來進行優先級的排序
// rank the thresholds by eviction priority
sort.Sort(byEvictionPriority(thresholds))
rank, ok := m.signalToRankFunc[thresholdToReclaim.Signal]
if !ok {
klog.Errorf("eviction manager: no ranking function for signal %s", thresholdToReclaim.Signal)
return nil
}
// the only candidates viable for eviction are those pods that had anything running.
if len(activePods) == 0 {
klog.Errorf("eviction manager: eviction thresholds have been met, but no pods are active to evict")
return nil
}
// 對指定資源的要逐出的正在運行的pod進行排序
rank(activePods, statsFunc)3.12 嘗試驅逐Pod
每次至少會嘗試驅逐一個Pod節點
for i := range activePods {
pod := activePods[i]
gracePeriodOverride := int64(0)
if !isHardEvictionThreshold(thresholdToReclaim) {
gracePeriodOverride = m.config.MaxPodGracePeriodSeconds
}
message, annotations := evictionMessage(resourceToReclaim, pod, statsFunc)
// 驅逐pod
if m.evictPod(pod, gracePeriodOverride, message, annotations) {
metrics.Evictions.WithLabelValues(string(thresholdToReclaim.Signal)).Inc()
return []*v1.Pod{pod}
}
}3.13 內存資源優先級排序算法
優先級排序主要從三個方面進行排序:是否超量、Pod優先級、超出容量的大小
3.13.1 內存超量對比
根據容器的時機使用量和對應Resource裏面Request請求的資源,來對返回true或,
func exceedMemoryRequests(stats statsFunc) cmpFunc {
return func(p1, p2 *v1.Pod) int {
p1Stats, p1Found := stats(p1)
p2Stats, p2Found := stats(p2)
if !p1Found || !p2Found {
return cmpBool(!p1Found, !p2Found)
}
p1Memory := memoryUsage(p1Stats.Memory)
p2Memory := memoryUsage(p2Stats.Memory)
p1ExceedsRequests := p1Memory.Cmp(v1resource.GetResourceRequestQuantity(p1, v1.ResourceMemory)) == 1
p2ExceedsRequests := p2Memory.Cmp(v1resource.GetResourceRequestQuantity(p2, v1.ResourceMemory)) == 1
// prioritize evicting the pod which exceeds its requests
return cmpBool(p1ExceedsRequests, p2ExceedsRequests)
}
}3.13.2 資源時機超量計算
計算時機使用內存使用超量對比
func memory(stats statsFunc) cmpFunc {
return func(p1, p2 *v1.Pod) int {
p1Stats, p1Found := stats(p1)
p2Stats, p2Found := stats(p2)
if !p1Found || !p2Found {
// prioritize evicting the pod for which no stats were found
return cmpBool(!p1Found, !p2Found)
}
// adjust p1, p2 usage relative to the request (if any)
p1Memory := memoryUsage(p1Stats.Memory)
p1Request := v1resource.GetResourceRequestQuantity(p1, v1.ResourceMemory)
p1Memory.Sub(p1Request)
p2Memory := memoryUsage(p2Stats.Memory)
p2Request := v1resource.GetResourceRequestQuantity(p2, v1.ResourceMemory)
p2Memory.Sub(p2Request)
// prioritize evicting the pod which has the larger consumption of memory
return p2Memory.Cmp(*p1Memory)
}
}3.13.3 優先級策略對比
func priority(p1, p2 *v1.Pod) int {
priority1 := pod.GetPodPriority(p1)
priority2 := pod.GetPodPriority(p2)
if priority1 == priority2 {
return 0
}
if priority1 > priority2 {
return 1
}
return -1
}沒有寫內存的memoryThresholdNotifier的實現,留着下篇,裏面會有一些unix本地通訊的實現,感覺還蠻好玩的,下篇再見
k8s源碼閱讀電子書地址: https://www.yuque.com/baxiaoshi/tyado3