




博文大綱:
一、Kafka概述
1)消息隊列
2)爲什麼要使用消息隊列?
3)什麼是Kafka?
4)Kafka的特性
5)Kafka架構
6)Topic和Partition的區別
7)kafka流程圖
8)Kafka的文件存儲機制
9)數據的可靠性和持久性保證
10)leader選舉
二、部署單機Kafka
1)部署Kafka
2)測試Kafka
三、部署Kafka羣集
1)環境準備
2)部署zookeeper羣集
3)部署Kafka羣集
一、Kafka概述
1)消息隊列
1)點對點模式(一對一,消費者主動拉取數據,消息收到後消息清除)
點對點模型通常是一個基於拉取或者輪詢的消息傳送模型,這種模型從隊列中請求信息,而不是將消息推送到客戶端。這個模型的特點是發送到隊列的消息被一個且只有一個接收者接收處理,即使有多個消息監聽者也是如此;
2)發佈/訂閱模式(一對多,數據生產後,推送給所有訂閱者)
發佈訂閱模型則是一個基於推送的消息傳送模型。發佈訂閱模型可以有多種不同的訂閱者,臨時訂閱者只在主動監聽主題時才接收消息,而持久訂閱者則監聽主題的所有消息,即使當前訂閱者不可用,處於離線狀態。
2)爲什麼要使用消息隊列?
1)解耦
允許你獨立的擴展或修改兩邊的處理過程,只要確保它們遵守同樣的接口約束。
2)冗餘
消息隊列把數據進行持久化直到它們已經被完全處理,通過這一方式規避了數據丟失風險。許多消息隊列所採用的"插入-獲取-刪除"範式中,在把一個消息從隊列中刪除之前,需要你的處理系統明確的指出該消息已經被處理完畢,從而確保你的數據被安全的保存直到你使用完畢。
3)擴展性
因爲消息隊列解耦了你的處理過程,所以增大消息入隊和處理的頻率是很容易的,只要另外增加處理過程即可。
4)靈活性&&削峯填谷
在訪問量劇增的情況下,應用仍然需要繼續發揮作用,但是這樣的突發流量並不常見。如果爲以能處理這類峯值訪問爲標準來投入資源隨時待命無疑是巨大的浪費。使用消息隊列能夠使關鍵組件頂住突發的訪問壓力,而不會因爲突發的超負荷的請求而完全崩潰。
5)可恢復性
系統的一部分組件失效時,不會影響到整個系統。消息隊列降低了進程間的耦合度,所以即使一個處理消息的進程掛掉,加入隊列中的消息仍然可以在系統恢復後被處理。
6)順序保證
在大多使用場景下,數據處理的順序都很重要。大部分消息隊列本來就是排序的,並且能保證數據會按照特定的順序來處理。(Kafka 保證一個 Partition 內的消息的有序性)
7)緩衝
有助於控制和優化數據流經過系統的速度,解決生產消息和消費消息的處理速度不一致的情況。
8)異步通信
很多時候,用戶不想也不需要立即處理消息。消息隊列提供了異步處理機制,允許用戶把一個消息放入隊列,但並不立即處理它。想向隊列中放入多少消息就放多少,然後在需要的時候再去處理它們。
3)什麼是Kafka?
kafka是由Apache軟件基金會發布的一個開源流處理平臺,由Scala和Java編寫。它是一種高吞吐量的分佈式發佈的訂閱消息系統,它可以處理消費者規模的網站中的所有動作流數據。這種動作(網頁瀏覽,搜索和其他用戶的行動)是在現代網絡上的許多社會功能的一個關鍵因素。 這些數據通常是由於吞吐量的要求而通過處理日誌和日誌聚合來解決。 對於像Hadoop一樣的日誌數據和離線分析系統,但又要求實時處理的限制,這是一個可行的解決方案。Kafka的目的是通過Hadoop的並行加載機制來統一線上和離線的消息處理,也是爲了通過集羣來提供實時的消息。
4)Kafka的特性
kafka是一種高吞吐量的分佈式發佈訂閱消息系統,具有以下特性:
1)通過磁盤數據結構提供消息的持久化,這種結構對於即使數以TB的消息存儲也能夠保持長時間的穩定性能;
2)持久性:使用文件性存儲,日誌文件存儲消息,需要寫入硬盤,採用達到一定閾值才寫入硬盤,從而減少磁盤I/O,如果kafka突然宕機,數據會丟失一部分;
3)高吞吐量:即使是非常普通的硬件kafka也可以支持每秒數百萬的消息;
4)支持通過kafka服務器和消費機集羣來分區消息;
5)支持Hadoop並行數據加載;
5)Kafka架構
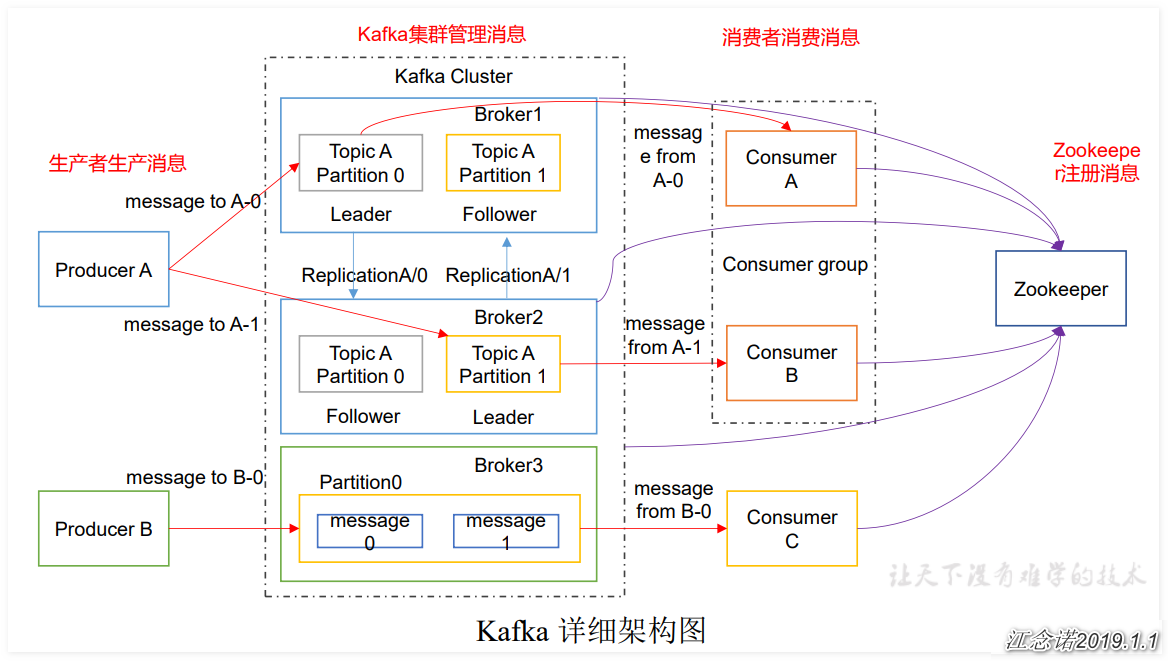
架構圖中的各個組件作用:
1)Producer :消息生產者,就是向 kafka broker 發消息的客戶端;
2)Broker :一臺 kafka 服務器就是一個 broker。一個集羣由多個broker 組成。一個 broker可以容納多個 topic;
3)Consumer :消息消費者,向 kafka broker 取消息的客戶端;
4)Partition:爲了實現擴展性,一個非常大的 topic 可以分佈到多個 broker(即服務器)上,一個 topic 可以分爲多個 partition,每個 partition 是一個有序的隊列。partition 中的每條消息都會被分配一個有序的 id(offset)。kafka 只保證按一個 partition 中的順序將消息發給consumer,不保證一個 topic 的整體(多個 partition 間)的順序;
5)Topic :Kafka根據topic對消息進行歸類,發佈到Kafka集羣的每條消息都需要指定一個topic;
6)ConsumerGroup:每個Consumer屬於一個特定的Consumer Group,一條消息可以發送到多個不同的Consumer Group,但是一個Consumer Group中只能有一個Consumer能夠消費該消息;
6)Topic和Partition的區別
一個topic可以認爲一個一類消息,每個topic將被分成多個partition,每個partition在存儲層面是append log文件。任何發佈到此partition的消息都會被追加到log文件的尾部,每條消息在文件中的位置稱爲offset(偏移量),offset爲long型的數字,它唯一標記一條消息。每條消息都被append到partition中,是順序寫磁盤,因此效率非常高(順序寫磁盤比隨機寫內存的速度還要高,這是kafka高吞吐率的一個很重要的保證)。
每一條消息被髮送到broker中,會根據partition規則選擇被存儲到哪一個partition(默認採用輪詢的方式進行寫入數據)。如果partition規則設置合理,所有消息可以均勻分佈到不同的partition裏,這樣就實現了水平擴展。(如果一個topic對應一個文件,那這個文件所在的機器I/O將會成爲這個topic的性能瓶頸,而partition解決了這個問題),如果消息被消費則保留append.log兩天。
7)kafka流程圖
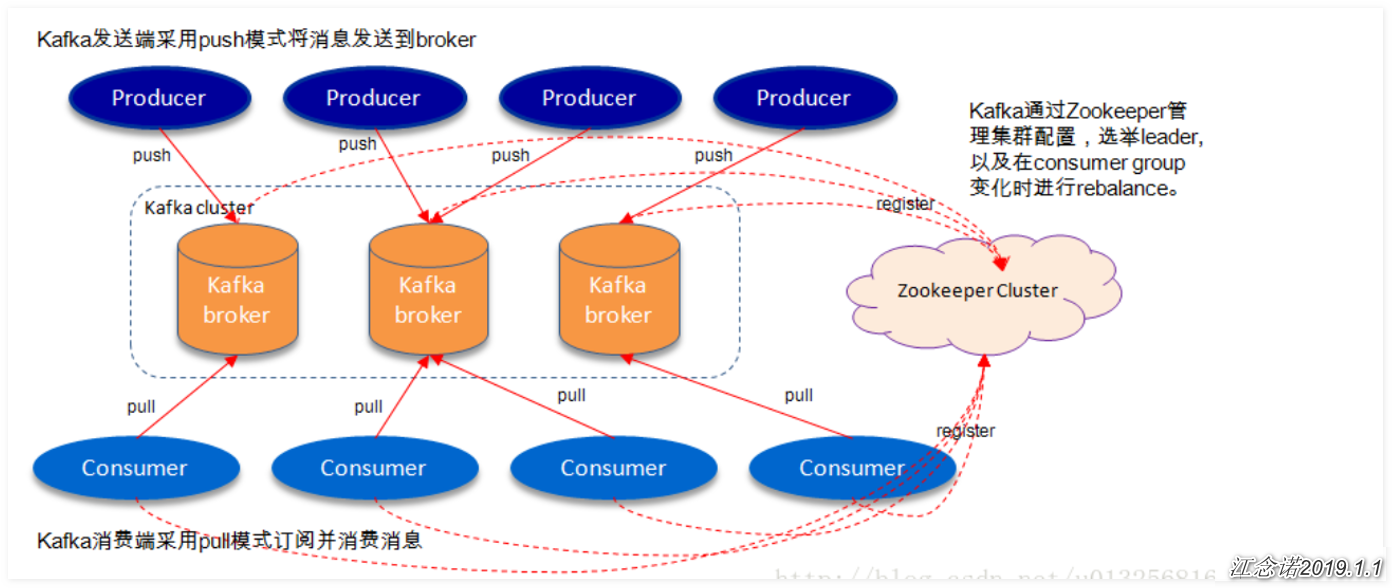
如上圖所示,一個典型的kafka體系架構包括若干Producer(可以是服務器日誌,業務數據,頁面前端產生的page view等),若干個broker(kafka支持水平擴展,一般broker數量越多,集羣吞吐率越高),若干Consumer(Group),以及一個Zookeeper集羣。kafka通過Zookeeper管理集羣配置,選舉出leader,以及在consumer group發生變化時進行重新調整。Producer使用push(推)模式將消息發佈到broker,consumer使用pull(拉)模式從broker訂閱並消費消息。
zookeeper羣集中有兩個角色:leader和follower,leader對外提供服務,follower負責leader裏面所產生內容同步消息寫入生成時產生replicas(副本);
kafka的高可靠性的保證來源於其健壯的副本(replicas)策略。通過調節其副本相關參數,可以使得kafka在性能和可靠性之間運轉之間的遊刃有餘。kafka從0.8.x版本開始提供partition級別的複製的。
8)Kafka的文件存儲機制
kafka中消息是以topic進行分類的,生產者通過topic向kafka broker發送消息,消費者通過topic讀取數據。然而topic在物理層面又能以partition爲分組,一個topic可以分爲若干個partition,partition還可以細分爲segment,一個partition物理上由多個segment組成。
爲了便於說明問題,假設這裏只有一個kafka集羣,且這個集羣只有一個kafka broker,也就是隻有一臺物理機。在這個kafka broker的server.properties配置文件中定義kafka的日誌文件存放路徑以此來設置kafka消息文件存儲目錄,與此同時創建一個topic:test,partition的數量爲4,啓動kafka就可以在日誌存放路徑中看到生成4個目錄,在kafka文件存儲中,同一個topic下有多個不同的partition,每個partition爲一個目錄,partition的名稱規則爲:topic名稱+有序序號,第一個序號從0開始。
segment是什麼?
如果就以partition爲最小存儲單位,我們可以想象當Kafka producer不斷髮送消息,必然會引起partition文件的無限擴張,這樣對於消息文件的維護以及已經被消費的消息的清理帶來嚴重的影響,所以這裏以segment爲單位又將partition細分。每個partition(目錄)相當於一個巨型文件被平均分配到多個大小相等的segment(段)數據文件中(每個segment 文件中消息數量不一定相等)這種特性也方便old segment的刪除,即方便已被消費的消息的清理,提高磁盤的利用率。每個partition只需要支持順序讀寫就行。
segment文件由兩部分組成,分別爲“.index”文件和“.log”文件,分別表示爲segment索引文件和數據文件。這兩個文件的命令規則爲:partition全局的第一個segment從0開始,後續每個segment文件名爲上一個segment文件最後一條消息的offset值(偏移量),數值大小爲64位,20位數字字符長度,沒有數字用0填充。
9)數據的可靠性和持久性保證
當producer向leader發送數據時,可以通request.required.acks參數來設置數據可靠性的級別:
- 1(默認):producer的leader已成功收到數據並得到確認。如果leader宕機了,則會丟失數據;
- 0 :producer無需等待來自broker的確認而繼續發送下一批消息。這種情況下數據傳輸效率最高,但是數據可靠性確是最低的;
- -1:producer需要等待所有follower都確認接收到數據後纔算一次發送完成,可靠性最高;
10)leader選舉
一條消息只有被所有follower都從leader複製過去纔會被認爲已提交。這樣就避免了部分數據被寫進了leader,還沒來得及被任何follower複製就宕機了,而造成數據丟失。而對於producer而言,它可以選擇是否等待消息commit。
一種非常常用的選舉leader的方式是“少數服從多數”,在進行數據的複製過程中,存在多個follower,並且每個follower的數據速度都不相同,當leader宕機後,當前的follower上誰的數據最多誰就是leader。
二、部署單機Kafka
1)部署Kafka
Kafka服務默認需要依賴Java環境,本次使用Centos 7系統,默認已經具備Java的環境。
Kafka羣集所需軟件下載鏈接:https://pan.baidu.com/s/1VHUH-WsptDB2wOugxvfKVg
提取碼:47x7
[root@kafka ~]# tar zxf kafka_2.11-2.2.1.tgz
[root@kafka ~]# mv kafka_2.11-2.2.1 /usr/local/kafka
[root@kafka ~]# cd /usr/local/kafka/bin/
[root@kafka bin]# ./zookeeper-server-start.sh ../config/zookeeper.properties &
#啓動zookeeper,啓動時需指定zookeeper的配置文件
#需添加“&”符號,表示後臺運行,否則會佔用前臺的終端
[root@kafka bin]# ./kafka-server-start.sh ../config/server.properties &
#啓動kafka,啓動方式與啓動zookeeper一樣
[root@kafka bin]# netstat -anpt | grep 9092
#kafka的監聽端口爲9092,確認端口在監聽的狀態由於kafka是通過zookeeper來調度的,所以,即使是單機kafka也需要啓動zookeeper服務,kafka的安裝目錄下是默認集成了zookeeper的,直接啓動即可。
2)測試Kafka
[root@kafka bin]# ./kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic test
#在本機創建一個topic,名稱爲test,副本數量爲1,分區數量爲1
[root@kafka bin]# ./kafka-topics.sh --list --bootstrap-server localhost:9092
#查看本機的topic
[root@kafka bin]# ./kafka-console-producer.sh --broker-list localhost:9092 --topic test
#向創建的topic中添加消息,消息內容自定義
>aaaa
>bbbb
>cccc
[root@kafka bin]# ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
aaaa
bbbb
cccc
#開啓新的終端,進行讀取消息測試,“--from-beginning”表示從開頭讀取測試成功!
三、部署Kafka羣集
1)環境準備
| 系統版本 | 主機名 | IP地址 | 運行的服務 |
|---|---|---|---|
| Centos 7 | kafka01 | 192.168.1.6 | Kafka+zookeeper |
| Centos 7 | kafka02 | 192.168.1.7 | Kafka+zookeeper |
| Centos 7 | kafka03 | 192.168.1.8 | Kafka+zookeeper |
2)部署zookeeper羣集
1)主機kafka01配置
[root@kafka01 ~]# tar zxf zookeeper-3.4.9.tar.gz
[root@kafka01 ~]# mv zookeeper-3.4.9 /usr/local/zookeeper
#安裝zookeeper
[root@kafka01 ~]# cd /usr/local/zookeeper/conf
[root@kafka01 conf]# cp -p zoo_sample.cfg zoo.cfg
[root@kafka01 conf]# sed -i 's/dataDir=\/tmp\/zookeeper/dataDir=\/usr\/local\/zookeeper\/data/g' zoo.cfg
[root@kafka01 conf]# echo "server.1 192.168.1.6:2888:3888" >> zoo.cfg
[root@kafka01 conf]# echo "server.2 192.168.1.7:2888:3888" >> zoo.cfg
[root@kafka01 conf]# echo "server.3 192.168.1.8:2888:3888" >> zoo.cfg
[root@kafka01 conf]# egrep -v '^$|^#' zoo.cfg #更改後的配置文件
tickTime=2000 #節點之間的心跳檢測時間單位爲毫秒
initLimit=10 #節點之間檢查失敗次數超過後斷開相應的節點
syncLimit=5 #達到5個訪問進行同步數據
dataDir=/usr/local/zookeeper/data #日誌文件存放路徑
clientPort=2181 #監聽端口
server.1 192.168.1.6:2888:3888
server.2 192.168.1.7:2888:3888
server.3 192.168.1.8:2888:3888
#聲明參與集羣的主機,2888和3888端口用於羣集內部通信
[root@kafka01 conf]# mkdir /usr/local/zookeeper/data
[root@kafka01 conf]# echo 1 > /usr/local/zookeeper/data/myid
#創建所需目錄及設置節點的ID號
[root@kafka01 conf]# scp -r /usr/local/zookeeper/ [email protected]:/usr/local/
[root@kafka01 conf]# scp -r /usr/local/zookeeper/ [email protected]:/usr/local/
#將配置好的zookeeper目錄複製到羣集內的其他節點
[root@kafka01 conf]# /usr/local/zookeeper/bin/zkServer.sh start
[root@kafka01 conf]# netstat -anpt | grep 2181
#確認zookeeper服務端口正在監聽2)主機kafka02配置
[root@kafka02 ~]# echo 2 > /usr/local/zookeeper/data/myid
#修改ID號爲2
[root@kafka02 ~]# /usr/local/zookeeper/bin/zkServer.sh start
#啓動zookeeper3)主機kafka03配置
[root@kafka03 ~]# echo 3 > /usr/local/zookeeper/data/myid
#修改ID號爲3
[root@kafka03 ~]# /usr/local/zookeeper/bin/zkServer.sh start
#啓動zookeeper4)查看zookeeper羣集內節點的角色
[root@kafka01 conf]# /usr/local/zookeeper/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Mode: follower #角色爲follower
[root@kafka02 ~]# /usr/local/zookeeper/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Mode: follower #角色爲follower
[root@kafka03 ~]# /usr/local/zookeeper/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Mode: leader #角色爲leader3)部署Kafka羣集
1)主機kafka01配置
[root@kafka01 ~]# tar zxf kafka_2.11-2.2.1.tgz
[root@kafka01 ~]# mv kafka_2.11-2.2.1 /usr/local/kafka
#安裝kafka
[root@kafka01 ~]# cd /usr/local/kafka/config/
[root@kafka01 config]# sed -i 's/broker.id=0/broker.id=1/g' server.properties
[root@kafka01 config]# sed -i 's/#listeners=PLAINTEXT:\/\/:9092/listeners=PLAINTEXT:\/\/192.168.1.6:9092/g' server.properties
[root@kafka01 config]# sed -i 's/#advertised.listeners=PLAINTEXT:\/\/your.host.name:9092/advertised.listeners=PLAINTEXT:\/\/192.168.1.6:9092/g' server.properties
[root@kafka01 config]# sed -i 's/log.dirs=\/tmp\/kafka-logs/log.dirs=\/usr\/local\/zookeeper\/data/g' server.properties
[root@kafka01 config]# sed -i 's/zookeeper.connect=localhost:2181/zookeeper.connect=192.168.1.6:2181,192.168.1.7:2181,192.168.1.8:2181/g' server.properties
[root@kafka01 config]# sed -i 's/zookeeper.connection.timeout.ms=6000/zookeeper.connection.timeout.ms=600000/g' server.properties
#修改kafka的配置文件
[root@kafka01 config]# egrep -v '^$|^#' server.properties
#修改後的配置文件
broker.id=1 #kafka的ID號,這裏爲1,其他節點依次是2、3
listeners=PLAINTEXT://192.168.1.6:9092 #節點監聽地址,填寫每個節點自己的IP地址
advertised.listeners=PLAINTEXT://192.168.1.6:9092 #集羣中節點內部交流使用的端口,填寫每個節點自己的IP地址
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/usr/local/zookeeper/data
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=192.168.1.62:2181,192.168.1.7:2181,192.168.1.8:2181
#聲明鏈接zookeeper節點的地址
zookeeper.connection.timeout.ms=600000
#修改這的時間,單位是毫秒,爲了防止連接zookeeper超時
group.initial.rebalance.delay.ms=0
[root@kafka01 config]# scp -r /usr/local/kafka/ [email protected]:/usr/local/
[root@kafka01 config]# scp -r /usr/local/kafka/ [email protected]:/usr/local/
#將修改後的kafka目錄發送至其他節點
[root@kafka01 bin]# ./kafka-server-start.sh ../config/server.properties &
#啓動kafka
[root@kafka01 bin]# netstat -anpt | grep 9092
確認端口在監聽2)主機kafka02配置
[root@kafka02 ~]# cd /usr/local/kafka/
[root@kafka02 kafka]# sed -i 's/broker.id=1/broker.id=2/g' config/server.properties
[root@kafka02 kafka]# sed -i 's/192.168.1.6:9092/192.168.1.7:9092/g' config/server.properties
#修改與kafka01衝突之處
[root@kafka02 kafka]# cd bin/
[root@kafka02 bin]# ./kafka-server-start.sh ../config/server.properties &
#啓動kafka
[root@kafka02 bin]# netstat -anpt | grep 9092
#確認端口在監聽3)主機kafka03配置
[root@kafka03 ~]# cd /usr/local/kafka/
[root@kafka03 kafka]# sed -i 's/broker.id=1/broker.id=3/g' config/server.properties
[root@kafka03 kafka]# sed -i 's/192.168.1.6:9092/192.168.1.8:9092/g' config/server.properties
#修改與kafka01衝突之處
[root@kafka03 kafka]# cd bin/
[root@kafka03 bin]# ./kafka-server-start.sh ../config/server.properties &
#啓動kafka
[root@kafka03 bin]# netstat -anpt | grep 9092
#確認端口在監聽4)發佈和訂閱消息測試
[root@kafka01 bin]# ./kafka-topics.sh --create --bootstrap-server 192.168.1.6:9092 --replication-factor 3 --partitions 1 --topic my-replicated-topic
#創建名爲my-replicated-topic的topic
[root@kafka01 bin]# ./kafka-topics.sh --describe --bootstrap-server 192.168.1.6:9092 --topic my-replicated-topic
#查看topic的狀態和leader
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:segment.bytes=1073741824
#返回的信息表示partition數量爲1,副本數量爲3,segment字節數爲1073741824
Topic: my-replicated-topic Partition: 0 Leader: 1 Replicas: 1,3,Isr: 1,3,2
#名稱爲“my-replicated-topic”,ID爲1的節點爲leader
[root@kafka01 bin]# ./kafka-console-producer.sh --broker-list 192.168.1.6:9092 --topic my-replicated-topic
#向名爲my-replicated-topic的topic 中插入數據進行測試
>aaaaaaaa
>bbbbbbbbbbbbbbb
>ccccccccccccccccccccccc
[root@kafka02 bin]# ./kafka-console-consumer.sh --bootstrap-server 192.168.1.7:9092 --from-beginning --topic my-replicated-topic
#在其他節點上查看插入的數據
aaaaaaaa
bbbbbbbbbbbbbbb
ccccccccccccccccccccccc5)模擬leader宕機,查看topic的狀態及新的leader
[root@kafka01 bin]# ./kafka-topics.sh --describe --bootstrap-server 192.168.1.6:9092 --topic my-replicated-topic
#查看名爲my-replicated-topic的topic狀態
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:segment.bytes=1073741824
Topic: my-replicated-topic Partition: 0 Leader: 1 Replicas: 1,3,Isr: 1,3,2
#可以看出ID號爲1的節點是leader
[root@kafka01 bin]# ./kafka-server-stop.sh
#ID號爲1的節點停止kafka服務
[root@kafka02 bin]# ./kafka-topics.sh --describe --bootstrap-server 192.168.1.7:9092 --topic my-replicated-topic
#在第二個節點上查看topic狀態
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:segment.bytes=1073741824
Topic: my-replicated-topic Partition: 0 Leader: 3 Replicas: 1,3,Isr: 3,2
#可以看出leader換成了ID爲3的節點———————— 本文至此結束,感謝閱讀 ————————