




Python語言有一種獨特的推導式語法,有點像語法糖,可以幫你在某些場合寫出比較精簡酷炫的代碼,同時,它的性能可能會比我們寫循環要好。它主要用於初始化一個列表,也可以用於初始化集合和字典。
1. 推導式分類與用法
1.1 列表推導
列表推導式是一種快速生成列表的方式。它一般用“[]"括起來,例如
>>> [i for i in range(10)]
[0,1, 2, 3, 4, 5, 6, 7, 8, 9]這是一種最基本的用法,列表推導式先執行for循環,再把遍歷的元素(或者對元素的一些計算表達式)作爲列表的元素返回一個列表。
>>> [i*i for i in range(10)]
[0,1, 4, 9, 16, 25, 36, 49, 64, 81]它就相當於
>>> l = []
>>> for i in range(10):
... l.append(i*i)
...
>>> 我們可以用列表推導快速初始化一個二維數組
m = [[0,0,0],
[0,0,0],
[0,0,0]
]
n = []
for row in range(3):
r = []
for col in range(3):
r.append(0)
n.append(r)
print(n)用下面的式子就可以得到這個二維數組
>>> [[0]*3 for i in range(3)]
[[0, 0, 0], [0, 0, 0], [0, 0, 0]]列表推導式有很多種形式
for循環前面加if...else...
這種生成的元素個數不會少,只是根據for循環的結果使用不同的表達式
# 如果i是5的倍數,結果是i,否則就是0
>>> [i if i % 5 == 0 else 0 for i in range(20)]
[0, 0, 0, 0, 0, 5, 0, 0, 0, 0, 10, 0, 0, 0, 0, 15, 0, 0, 0, 0]
# 如果是偶數就加100,奇數就減100
>>> [i+100 if i % 2 == 0 else i-100 for i in range(10)]
[100, -99, 102, -97, 104, -95, 106, -93, 108, -91]for循環後面加if...
這種會只取符合條件的元素,所以元素個數跟條件相關
# for循環的結果只選擇是偶數的
>>> [i for i in range(10) if i % 2 == 0]
[0, 2, 4, 6, 8]
# for循環的結果只選擇是2和3的倍數的
>>> [i for i in range(10) if i % 2 == 0 and i % 3 == 0]
[0, 6]
# for循環的結果只選擇偶數,並且應用str函數
>>> [str(i) for i in range(10) if i % 2 == 0]
['0', '2', '4', '6', '8']嵌套循環
假如我們展開一個二維矩陣,如下面的m,我們可以用嵌套循環實現。
m = [[1,2,3],
[4,5,6],
[7,8,9]
]
n = []
for row in m:
for col in row:
n.append(col)
print(n)用列表推導,最外層的for循環得到的row,可以在內層中使用
m = [[1,2,3],
[4,5,6],
[7,8,9]
]
n = [col for row in m for col in row]
print(n)再比如下面這個例子
>>> [a + b for a in '123' for b in 'abc']
['1a', '1b', '1c', '2a', '2b', '2c', '3a', '3b', '3c']更多用法
列表推導的用法比較靈活,我們不一定要把所有的都掌握,但是要能看懂。
>>> dic = {"k1":"v1","k2":"v2"}
>>> a = [k+":"+v for k,v in dic.items()]
>>> a
['k1:v1', 'k2:v2']1.2 集合推導
集合推導的語法與列表推導一樣,只是它是用”{}“,而且,集合會自動去重
>>> { i for i in range(10)}
{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
>>> { 0 if i % 2 == 0 else 1 for i in range(10)}
{0, 1}1.3 字典推導
字典推導的語法也與其他的類似,只不過在最前面的格式是key:value,而且也是會去重
>>> { i : i.upper() for i in 'hello world'}
{'h': 'H', 'e': 'E', 'l': 'L', 'o': 'O', ' ': ' ', 'w': 'W', 'r': 'R', 'd': 'D'}
>>> { str(i) : i*i for i in range(10)}
{'0': 0, '1': 1, '2': 4, '3': 9, '4': 16, '5': 25, '6': 36, '7': 49, '8': 64, '9': 81}1.4 元組推導?不存在的
既然用[]就能做列表推導,那用()是不是就能做元組推導了?不是的,因爲()被用在了一種特殊的對象上:生成器(generator)。
>>> a = (i for i in range(10))
>>> print(a)
<generator object <genexpr> at 0x000001A6100869C8>
>>> type(a)
<class 'generator'>生成器是一個順序產生元素的對象,只能順序訪問,只能前進,而且只能遍歷一次。
可以使用next()函數取下一個元素,取不到就會報StopIteration異常,也可以使用for循環遍歷。
生成式沒法用下標訪問,用next訪問直到報異常
>>> a = (i for i in range(0,2))
>>> a[0]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'generator' object is not subscriptable
>>> next(a)
0
>>> next(a)
1
>>> next(a)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration用for循環遍歷
>>> a = (i for i in range(0,2))
>>> for i in a:
... print(i)
...
0
1先用next訪問,再用for循環
>>> a = (i for i in range(0,3))
>>> next(a)
0
>>> for i in a:
... print(i)
...
1
2我們可以加上list,tuple,set等做強轉,但是list和set就沒必要了,如果想初始化成tuple,就用tuple做強轉。強轉的時候不需要再加多餘的括號。
>>> a = tuple(i for i in range(0,3))
>>> a
(0, 1, 2)
>>> a = tuple( (i for i in range(0,3)) )
>>> a
(0, 1, 2)生成式是惰式計算的,就是你確實用到這個元素了,它纔去計算,好處就是節省了內存,但是壞處是不能隨機訪問。
2. 推導式的性能
2.1 列表推導式與循環的性能
我們用timeit模塊去比較一下性能。
import timeit
def getlist1():
l = []
for i in range(10000):
l.append(i)
return l
def getlist2():
return [i for i in range(10000)]
# 各執行10000次
t1 = timeit.timeit('getlist1()',"from __main__ import getlist1", number=10000)
t2 = timeit.timeit('getlist2()',"from __main__ import getlist2", number=10000)
print('循環方式:',t1)
print('推導式方式:',t2)執行結果如下:
循環方式: 5.343517699991935
推導式方式: 2.6003115000057733可見循環的方式比推導式慢了一倍,爲什麼會有這個問題呢?我們直接反編譯看這兩個的區別,用dis模塊可以反編譯Python代碼,產生字節碼。
源代碼及行數如下

getlist1的反編譯如下,左邊紅色對應源代碼的行數,藍色圈內就是第6行代碼對應的字節碼,我們可以看到,它有一個傳參並且調用方法append的過程,調用函數的代價是比較大的。
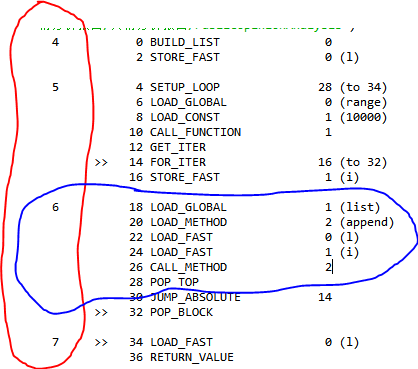
再來看一下列表推斷的反編譯結果

首先從字節碼數量上來比列表推斷就比用循環調append要少的多,而且列表推斷沒有使用方法調用,直接用了這個指令LIST_APPEND,在Python官網上的解釋是這樣的。

實際上這個解釋是有誤導性,字節碼中使用LIST_APPEND和在Python代碼中調用append是完全不一樣的,只不過這種底層的東西沒有很多人關心,它們的功能是一樣的。在2008年的時候就有人給Python代碼提patch,希望能自動將list.append()進行優化,直接優化成LIST_APPEND而不是通過函數調用,但是目前還沒被採納。

提出者希望能在編譯的時候加一些選項,比如像gcc可以使用-O1,-O2等進行不同級別的優化,但是目前CPython是沒有這些選項的,因爲大多數的Python開發者並不關心性能。
如果我們把上面的列表換成集合或者字典,差別會更大,所以能用推導式的地方儘量用推導式,可以提高性能。
2.2 列表推導式與生成器推導式的性能
其實這兩個並不具備可比性,因爲生成的結果並不是一個東西。我們可以很容易的預測,產生生成器的推導式性能要好於列表推導式,但是用的時候生成器就不如列表了。
import timeit
def getlist1():
return [i for i in range(10000)]
def getlist2():
return (i for i in range(10000))
# 各執行10000次
t1 = timeit.timeit('getlist1()',"from __main__ import getlist1", number=10000)
t2 = timeit.timeit('getlist2()',"from __main__ import getlist2", number=10000)
print('列表:',t1)
print('生成器:',t2)
def getlist11():
a = [i for i in range(10000)]
sum = 0
for i in a:
sum += i
def getlist22():
a = (i for i in range(10000))
sum = 0
for i in a:
sum += i
# 各執行10000次
t1 = timeit.timeit('getlist11()',"from __main__ import getlist11", number=10000)
t2 = timeit.timeit('getlist22()',"from __main__ import getlist22", number=10000)
print('列表:',t1)
print('生成器:',t2)執行結果:
列表: 2.5977418000111356
生成器: 0.006076899997424334
列表: 6.336311199993361
生成器: 9.181903699995019生成器產生的性能遠大於列表,但是遍歷的時候不如列表,但是總體上看好像生成器好。不過不要忘了,生成器不能隨機訪問,而且只能用一次。所以這兩種對象,就是在合適的地方用合適的類型,不一定哪一種比哪一種更好。