




HTTP基礎知識歸納(1)
每日寄語:等風來不如追風去
此文章側重點是將零碎的知識點進行歸納總結;文章大致講以下知識點:
- HTTP的一次請求過程所經過的流程
- URL、URI、URN的概念及區別
- 字符亂碼的本質
- DNS的域名解析過程
- 請求報文和響應報文的結構:頭、首部字段、主體
- 常見的狀態碼及首部字段
1、HTTP一次請求流程

如上圖可知:HTTP的一次請求過程大致經過以下步驟:
- 1、域名解析:當用戶在瀏覽器上輸入網址按上回車鍵後會進行域名解析來獲得所需的服務器的IP地址;
- 2、TCP三次握手建立TCP連接:瀏覽器會根據IP地址和端口號向目標服務器發起TCP連接;
- 3、連接建立發送請求:連接建立起來後瀏覽器向服務器發送請求;
- 4、服務器接收請求並處理:(這裏的處理邏輯有可能是應用服務器在處理,應用服務器接收請求並處理的過程省略)
- 5、服務器向客戶端發送響應請求
- 6、瀏覽器接收響應報文並根據要求進行渲染頁面。
- 7、TCP四次揮手關閉連接。
有兩點問題需要我們着重關注(面試會問的哦):DNS解析的過程以及TCP的三次握手和四次揮手;如果想深入瞭解可以參考網上的技術博客。
2、DNS的域名解析過程
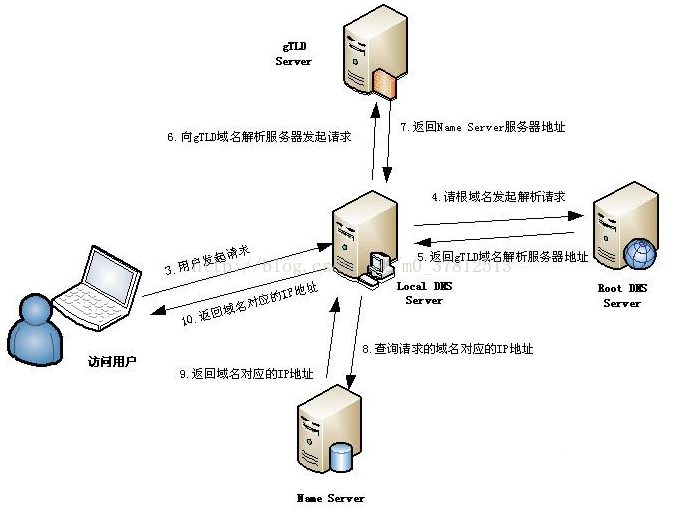
DNS域名解析大致經過的過程如下:
- 1、域名解析首先會在自己本機下的host文件下找
- 2、如果沒有找到會到本地域名解析服務器(Local DNS Server)下找,找到就返回
- 3、如果在Local DNS Server下沒有找到,會跳到根域名服務器解析請求, 根域名服務器返回給LDNS一個所查詢域的主域名服務器(gTLD Server,國際頂尖域名服務器,如.com .cn .org等)地址
- 4、LDNS會向gTLD域名服務器發起請求
- 5、接受請求的gTLD查找並返回這個域名對應的Name Server的地址,這個Name Server就是網站註冊的域名服務器
- 6、Name Server根據映射關係表找到目標ip,返回給LDNS
- 7、LDNS緩存這個域名和對應的ip
-
8、LDNS把解析的結果返回給用戶,用戶根據TTL值緩存到本地系統緩存中,域名解析過程至此結束
3、URL、URI、URN的概念及區別
| 名 稱 | 描 述 |
|---|---|
| URI | (Uniform Resource Identifier,URI) 統一資源標誌符;唯一標誌並定位信息資源。 |
| URL | (Uniform Resource Location,URL)統一資源定位符;明確說明如何從一個精準、固定的位置獲取資源。下面會詳細介紹URL的標準格式。 |
| URN | (Uniform Resource Name,URN) 統一資源名;URN是作爲特定內容的唯一名稱使用的,與目前的資源所在定無關。 |
URL的標準格式
| URL的通用格式 |
|---|
| <scheme>://<user>:<password>@<host>:<port>/<path>;<params>?<query>#<frag> |
其中URL最重要的3個部分是方案<scheme>、主機<host>、路徑<path>
其中我們應注意帶有片段的URL的請求:比如:http://www.joes-hardware.com/tools.html#drills; 在這個例子中,片段drills引用了Joe的五金商店的web服務器上頁面/tools.html中的一個部分,這個部分的名字叫做dirlls。那這個請求是如何進行的呢?由於HTTP服務器通常只處理整個對象,而不是對象的片段,所以瀏覽器向服務器發送請求的時會剔除片段向瀏覽器請求整個資源,瀏覽器接受資源後會根據片段展示所應該展示的內容。
4、字符亂碼的本質
首先,我們的明白什麼是字符集以及一個字符集來說要正確編碼轉碼一個字符需要三個關鍵元素
字符集:字符集就規定了某個文字對應的二進制數字存放方式(編碼)和某串二進制數值代表了哪個文字(解碼)的轉換關係。
一個字符集來說要正確編碼轉碼一個字符需要三個關鍵元素:
- 字符庫:是一個相當於所有可讀或者可顯示字符的數據庫,字庫表決定了整個字符集能夠展現表示的所有字符的範圍;
- 編碼字符集:即用一個編碼值code point來表示一個字符在字庫中的位置;
- 字符編碼:將編碼字符集和實際存儲數值之間的轉換關係。
三者之間的關係如下圖:
舉例:
假如採用ASCII字符集,字符A在字符表中位置爲65,65經規則轉化爲1000001(1000001就存儲在編碼字符集中),而65和1000001的對應關係就存在了字符編碼中,而字符亂碼是因爲採用不同的編碼其映射關係不同解析的數據也就不同了。
問題擴展 (摘錄)
看到這裏,可能很多讀者都會有和我當初一樣的疑問:字庫表和編碼字符集看來是必不可少的,那既然字庫表中的每一個字符都有一個自己的序號,直接把序號作爲存儲內容就好了。爲什麼還要多此一舉通過字符編碼把序號轉換成另外一種存儲格式呢?
其實原因也比較容易理解:統一字庫表的目的是爲了能夠涵蓋世界上所有的字符,但實際使用過程中會發現真正用的上的字符相對整個字庫表來說比例非常低。例如中文地區的程序幾乎不會需要日語字符,而一些英語國家甚至簡單的ASCII字庫表就能滿足基本需求。而如果把每個字符都用字庫表中的序號來存儲的話,每個字符就需要3個字節(這裏以Unicode字庫爲例),這樣對於原本用僅佔一個字符的ASCII編碼的英語地區國家顯然是一個額外成本(存儲體積是原來的三倍)。算的直接一些,同樣一塊硬盤,用ASCII可以存1500篇文章,而用3字節Unicode序號存儲只能存500篇。於是就出現了UTF-8這樣的變長編碼。在UTF-8編碼中原本只需要一個字節的ASCII字符,仍然只佔一個字節。而像中文及日語這樣的複雜字符就需要2個到3個字節來存儲。
5、參考文獻
- 《HTTP權威指南》
- 《圖解HTTP》
- 史上最通俗,徹底搞懂字符亂碼問題的本質
未完待續。。。。;如果閱讀過程中發現文中的知識點有錯誤的話,可以反饋給我,我們共同來完善。