




Kafka 是一個分佈式流式處理平臺。這到底是什麼意思呢?
流平臺具有三個關鍵功能:
- 消息隊列:發佈和訂閱消息流,這個功能類似於消息隊列,這也是 Kafka 也被歸類爲消息隊列的原因。
- 容錯的持久方式存儲記錄消息流:Kafka 會把消息持久化到磁盤,有效避免了消息丟失的風險·。
- 流式處理平臺:在消息發佈的時候進行處理,Kafka 提供了一個完整的流式處理類庫。
Kafka 主要有兩大應用場景:
-
消息隊列 :建立實時流數據管道,以可靠地在系統或應用程序之間獲取數據。
- 數據處理:構建實時的流數據處理程序來轉換或處理數據流。
![關於kafka的認知]()
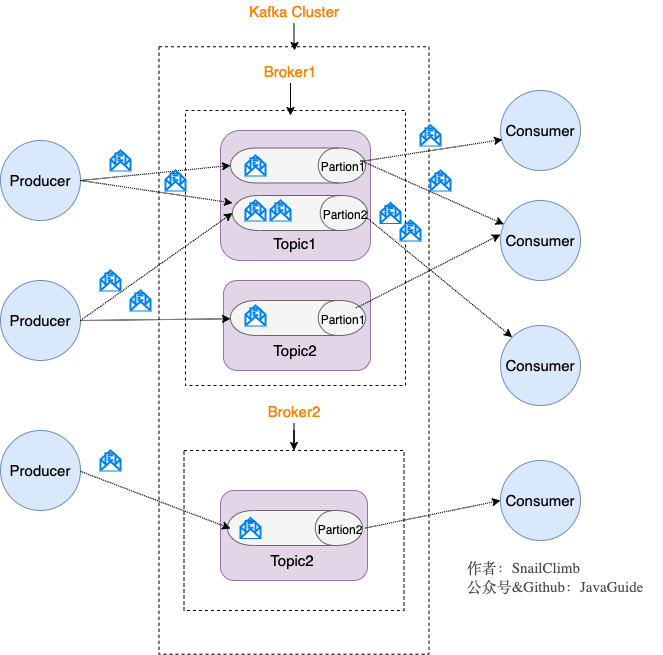
關於 Kafka 幾個非常重要的概念:
Kafka 將記錄流(流數據)存儲在 topic 中。
每個記錄由一個鍵、一個值、一個時間戳組成。
你一定也注意到每個 Broker 中又包含了 Topic 以及 Partition 這兩個重要的概念:
Topic(主題):Producer 將消息發送到特定的主題,Consumer 通過訂閱特定的 Topic(主題) 來消費消息。
Partition(分區):Partition 屬於 Topic 的一部分。一個 Topic 可以有多個 Partition,並且同一 Topic 下的 Partition 可以分佈在不同的 Broker 上,這也就表明一個 Topic 可以橫跨多個 Broker。
劃重點:Kafka 中的 Partition(分區) 實際上可以對應成爲消息隊列中的隊列。
另外,還有一點我覺得比較重要的是 Kafka 爲分區(Partition)引入了多副本(Replica)機制。分區(Partition)中的多個副本之間會有一個叫做 leader 的傢伙,其他副本稱爲 follower。我們發送的消息會被髮送到 leader 副本,然後 follower 副本才能從 leader 副本中拉取消息進行同步。
生產者和消費者只與 leader 副本交互。你可以理解爲其他副本只是 leader 副本的拷貝,它們的存在只是爲了保證消息存儲的安全性。當 leader 副本發生故障時會從 follower 中選舉出一個 leader,但是 follower 中如果有和 leader 同步程度達不到要求的參加不了 leader 的競選。
Kafka 的多分區(Partition)以及多副本(Replica)機制有什麼好處呢?
-
Kafka 通過給特定 Topic 指定多個 Partition,而各個 Partition 可以分佈在不同的 Broker 上, 這樣便能提供比較好的併發能力(負載均衡)。
- Partition 可以指定對應的 Replica 數, 這也極大地提高了消息存儲的安全性, 提高了容災能力,不過也相應的增加了所需要的存儲空間。
ZooKeeper 在 Kafka 中的作用
要想搞懂 ZooKeeper 在 Kafka 中的作用 一定要自己搭建一個 Kafka 環境然後自己進 ZooKeeper 去看一下有哪些文件夾和 Kafka 有關,每個節點又保存了什麼信息。一定不要光看不實踐,這樣學來的也終會忘記!
下圖就是我的本地 ZooKeeper ,它成功和我本地的 Kafka 關聯上(以下文件夾結構藉助 idea 插件 ZooKeeper tool 實現)。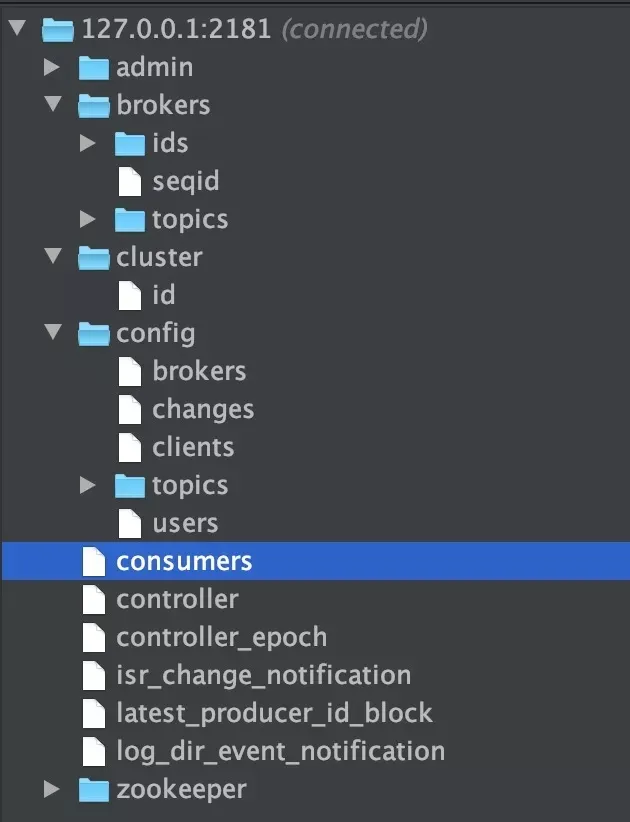
ZooKeeper 主要爲 Kafka 提供元數據的管理的功能。
從圖中我們可以看出,Zookeeper 主要爲 Kafka 做了下面這些事情:
Broker 註冊 :在 Zookeeper 上會有一個專門用來進行 Broker 服務器列表記錄的節點。每個 Broker 在啓動時,都會到 Zookeeper 上進行註冊,即到/brokers/ids 下創建屬於自己的節點。每個 Broker 就會將自己的 IP 地址和端口等信息記錄到該節點中去。
Topic 註冊 :在 Kafka 中,同一個Topic 的消息會被分成多個分區並將其分佈在多個 Broker 上,這些分區信息及與 Broker 的對應關係也都是由 Zookeeper 在維護。比如我創建了一個名字爲 my-topic 的主題並且它有兩個分區,對應到 zookeeper 中會創建這些文件夾:/brokers/topics/my-topic/partitions/0、/brokers/topics/my-topic/partions/1。
負載均衡 :上面也說過了 Kafka 通過給特定 Topic 指定多個 Partition, 而各個 Partition 可以分佈在不同的 Broker 上, 這樣便能提供比較好的併發能力。對於同一個 Topic 的不同 Partition,Kafka 會盡力將這些 Partition 分佈到不同的 Broker 服務器上。當生產者產生消息後也會盡量投遞到不同 Broker 的 Partition 裏面。當 Consumer 消費的時候,Zookeeper 可以根據當前的 Partition 數量以及 Consumer 數量來實現動態負載均衡。
Kafka 如何保證消息的消費順序?
我們在使用消息隊列的過程中經常有業務場景需要嚴格保證消息的消費順序,比如我們同時發了 2 個消息,這 2 個消息對應的操作分別對應的數據庫操作是:更改用戶會員等級、根據會員等級計算訂單價格。假如這兩條消息的消費順序不一樣造成的最終結果就會截然不同。
我們知道 Kafka 中 Partition(分區)是真正保存消息的地方,我們發送的消息都被放在了這裏。而我們的 Partition(分區)又存在於 Topic(主題)這個概念中,並且我們可以給特定 Topic 指定多個 Partition。
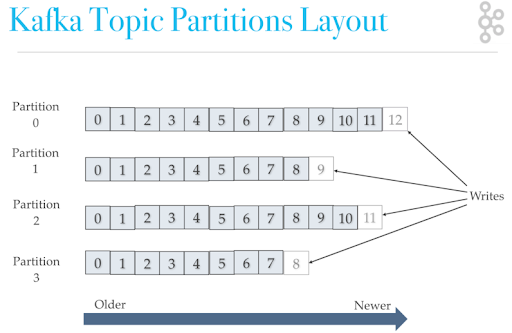
每次添加消息到 Partition(分區)的時候都會採用尾加法,如上圖所示。Kafka 只能爲我們保證 Partition(分區)中的消息有序,而不能保證 Topic(主題)中的 Partition(分區)的有序。
消息在被追加到 Partition(分區)的時候都會分配一個特定的偏移量(offset)。Kafka 通過偏移量(offset)來保證消息在分區內的順序性。
所以,我們就有一種很簡單的保證消息消費順序的方法:1 個 Topic 只對應一個 Partion。這樣當然可以解決問題,但是破壞了 Kafka 的設計初衷。
Kafka 中發送 1 條消息的時候,可以指定 Topic,Partition,Key,Data(數據) 4 個參數。如果你發送消息的時候指定了 partion 的話,所有消息都會被髮送到指定的 partion。並且,同一個 key 的消息可以保證只發送到同一個 partition,這個我們可以採用表/對象的 id 來作爲 key。
總結一下,對於如何保證 Kafka 中消息消費的順序,有了下面兩種方法:
1個 Topic 只對應一個 Partion。
(推薦)發送消息的時候指定 Key/Partion。
轉載鏈接:大白話帶你認識 Kafka