




Kafka快速入門(五)——Kafka管理
一、Kafka工具腳本簡介
1、Kafka工具腳本簡介
Kafka默認提供了很多個命令行腳本,用於實現各種各樣的功能和運維管理。默認情況下,不加任何參數或攜帶--help運行Kafka shell腳本根據,會得到腳本的使用方法說明。
connect-standalone.sh用於啓動單節點的Standalone模式的Kafka Connect組件。
connect-distributed.sh用於啓動多節點的Distributed模式的Kafka Connect組件。
kafka-acls.sh腳本用於設置Kafka權限,比如設置哪些用戶可以訪問Kafka的哪些TOPIC的權限。
kafka-delegation-tokens.sh用於管理Delegation Token。基於Delegation Token的認證是一種輕量級的認證機制,是對SASL認證機制的補充。
kafka-topics.sh用於管理所有TOPIC。
kafka-console-producer.sh用於生產消息。
kafka-console-consumer.sh用於消費消息。
kafka-producer-perf-test.sh用於生產者性能測試。
kafka-consumer-perf-test.sh用於消費者性能測試。
kafka-delete-records.sh用於刪除Kafka的分區消息,由於Kafka有自己的自動消息刪除策略,使用率不高。
kafka-dump-log.sh用於查看Kafka消息文件的內容,包括消息的各種元數據信息、消息體數據。
kafka-log-dirs.sh用於查詢各個Broker上的各個日誌路徑的磁盤佔用情況。
kafka-mirror-maker.sh用於在Kafka集羣間實現數據鏡像。
kafka-preferred-replica-election.sh用於執行Preferred Leader選舉,可以爲指定的主題執行更換Leader的操作。
kafka-reassign-partitions.sh用於執行分區副本遷移以及副本文件路徑遷移。
kafka-run-class.sh用於執行任何帶main方法的Kafka類。
kafka-server-start.sh用於啓動Broker進程。
kafka-server-stop.sh用於停止Broker進程。
kafka-streams-application-reset.sh用於給Kafka Streams應用程序重設位移,以便重新消費數據。
kafka-verifiable-producer.sh用於測試驗證生產者的功能。
kafka-verifiable-consumer.sh用於測試驗證消費者功能。
trogdor.sh是Kafka的測試框架,用於執行各種基準測試和負載測試。
kafka-broker-api-versions.sh腳本主要用於驗證不同Kafka版本之間服務器和客戶端的適配性。
2、Kafka API兼容性測試
本文使用Kafka 2.4版本,kafka-broker-api-versions.sh需要指定Kafka Broker,測試相應版本的API兼容性。kafka-broker-api-versions.sh --bootstrap-server kafka-test:9092
Produce表示Produce請求,Produce請求是Kafka所有請求類型中的第一號請求,序號是0。0 to 8表示Produce請求在Kafka 2.4中總共有9個版本,序號分別是0到8。usable:8表示當前連入本Kafka Broker的客戶端API能夠使用的版本號是8,即最新的版本。
當使用低版本的kafka-broker-api-versions.sh腳本連接高版本的Kafka Broker時,Produce請求信息的usable表示低版本的客戶端API只能發送版本號是usable值的Produce請求類型。
在Kafka 0.10.2.0版本前,Kafka是單向兼容的,高版本的Broker能夠處理低版本Client發送的請求,低版本的Broker不能處理高版本的Client請求。Kafka 0.10.2.0版本開始,Kafka正式支持雙向兼容,低版本的Broker也能處理高版本Client的請求。
3、Kafka性能測試
Java生產者性能測試腳本:kafka-producer-perf-test.sh --topic test-topic --num-records 10000000 --throughput -1 --record-size 1024 --producer-props bootstrap.servers=kafka-host:port acks=-1 linger.ms=2000 compression.type=lz4
Java消費者性能測試腳本:kafka-consumer-perf-test.sh --broker-list kafka-host:port --messages 10000000 --topic test
二、TOPIC管理
1、創建TOPIC
kafka-topics.sh --bootstrap-server broker_host:port --create --topic my_topic_name --partitions 1 --replication-factor 1
--create表示創建TOPIC,--partitions表示TOPIC的分區數量,--replication-factor表示每個分區下的副本數。從Kafka 2.2版本開始,Kafka社區推薦用--bootstrap-server參數替換--zookeeper參數用於指定Kafka Broker。
Kafka社區推薦使用--bootstrap-server的原因主要有:
(1)使用--zookeeper會繞過Kafka的安全體系。即使爲Kafka集羣設置安全認證,限制TOPIC的創建,如果使用--zookeeper的命令,依然能成功創建任意TOPIC,不受認證體系的約束。
(2)使用--bootstrap-server與Kafka集羣進行交互,越來越成爲使用Kafka的標準操作。未來,越來越少的命令和API需要與ZooKeeper進行連接。
2、查詢TOPIC
查詢Kafka集羣所有TOPIC的命令:kafka-topics.sh --bootstrap-server broker_host:port --list
查詢單個TOPIC詳細數據的命令如下:kafka-topics.sh --bootstrap-server broker_host:port --describe --topic topic_name
如果describe命令不指定具體的TOPIC名稱,那麼Kafka默認會返回當前用戶的所有可見TOPIC的詳細數據。
3、生產消息
kafka-console-producer.sh --bootstrap-server kafka:9092 --topic test
啓動生產者,並將Terminal輸入寫入TOPIC。
4、消費消息
kafka-console-consumer.sh --bootstrap-server kafka:9092 --topic test --from-beginning
啓動消費者,從TOPIC消費消息數據。
5、修改TOPIC分區數量
Kafka目前不允許減少某個TOPIC的分區數,因此修改TOPIC的分區數量就是增加分區數量,可以使用kafka-topics腳本,結合--alter參數來增加某個TOPIC的分區數。kafka-topics.sh --bootstrap-server broker_host:port --alter --topic topic_name --partitions 新分區數
指定的分區數一定要比原有分區數大,否則Kafka會拋出InvalidPartitionsException異常。
6、修改TOPIC級別參數
設置TOPIC級別參數max.message.bytes。kafka-configs.sh --zookeeper zookeeper_host:port --entity-type topics --entity-name topic_name --alter --add-config max.message.bytes=10485760
設置常規的TOPIC級別參數使用--zookeeper,設置動態參數使用--bootstrap-server。
7、修改TOPIC限速
當某個TOPIC的副本在執行副本同步機制時,爲了不消耗過多的帶寬,可以設置Leader副本和Follower副本使用的帶寬。設置TOPIC各個分區的Leader副本和Follower副本在處理副本同步時,不得佔用超過100MBps(104857600)的帶寬,必須先設置Broker端參數leader.replication.throttled.rate 和 follower.replication.throttled.rate,命令如下:kafka-configs.sh --zookeeper zookeeper_host:port --alter --add-config 'leader.replication.throttled.rate=104857600,follower.replication.throttled.rate=104857600' --entity-type brokers --entity-name 0
--entity-name參數用於指定Broker ID。如果TOPIC的副本分別在多個Broker上,需要依次爲相應Broker執行。爲TOPIC的所有副本都設置限速,可以統一使用通配符*來表示,命令如下:kafka-configs.sh --zookeeper zookeeper_host:port --alter --add-config 'leader.replication.throttled.replicas=*,follower.replication.throttled.replicas=*' --entity-type topics --entity-name test
8、刪除TOPIC
刪除TOPIC命令如下:kafka-topics.sh --bootstrap-server broker_host:port --delete --topic topic_name
刪除TOPIC操作是異步的,執行完刪除命令不代表TOPIC立即就被刪除,僅僅是被標記成“已刪除”狀態而已。Kafka會在後臺默默地開啓TOPIC刪除操作,通常需要耐心地等待一段時間。
9、Kafka內置TOPIC
Kafka有兩個內TOPIC:__consumer_offsets和__transaction_state,內置TOPIC默認都有50個分區。
Kafka 0.11前,當Kafka自動創建__consumer_offsets時,會綜合考慮當前運行的Broker臺數和Broker端參數offsets.topic.replication.factor值,然後取兩者的較小值作爲__consumer_offsets的副本數,__consumer_offsets通常在只有一臺Broker啓動時被創建,因此副本數爲1。Kafka 0.11版本後,Kafka會嚴格遵守offsets.topic.replication.factor值。如果當前運行的Broker數量小於offsets.topic.replication.factor值,Kafka會創建主題失敗,並顯式拋出異常。
直接查看消費者組提交的位移數據:kafka-console-consumer.sh --bootstrap-server kafka_host:port --topic __consumer_offsets --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --from-beginning
直接讀取TOPIC消息,查看消費者組的狀態信息:kafka-console-consumer.sh --bootstrap-server kafka_host:port --topic __consumer_offsets --formatter "kafka.coordinator.group.GroupMetadataManager\$GroupMetadataMessageFormatter" --from-beginning__transaction_state內置TOPIC的信息查看需要指定kafka.coordinator.transaction.TransactionLog\$TransactionLogMessageFormatter。
10、修改TOPIC副本數
創建內置__consumer_offsets的副本配置json 文件,顯式提供50個分區對應的副本數。replicas中的3臺Broker排列順序不同,目的是將Leader副本均勻地分散在Broker上。文件具體格式如下:
{"version":1, "partitions":[
{"topic":"__consumer_offsets","partition":0,"replicas":[0,1,2]},
{"topic":"__consumer_offsets","partition":1,"replicas":[0,2,1]},
{"topic":"__consumer_offsets","partition":2,"replicas":[1,0,2]},
{"topic":"__consumer_offsets","partition":3,"replicas":[1,2,0]},
...
{"topic":"__consumer_offsets","partition":49,"replicas":[0,1,2]}
]}執行kafka-reassign-partitions腳本:kafka-reassign-partitions.sh --zookeeper zookeeper_host:port --reassignment-json-file reassign.json --execute
11、錯誤處理
(1)刪除TOPIC失敗
造成TOPIC刪除失敗最常見的原因有兩個:副本所在的Broker宕機;待刪除TOPIC的部分分區依然在執行遷移過程。
強制刪除TOPIC的方法:
A、手動刪除ZooKeeper節點/admin/delete_topics下以待刪除TOPIC爲名的znode。
B、手動刪除TOPIC在磁盤上的分區目錄。
C、在ZooKeeper中執行rmr /controller,觸發Controller重選舉,刷新Controller緩存。可能會造成大面積的分區Leader重選舉。可以不執行,只是Controller緩存中沒有清空待刪除TOPIC,不影響使用。
(2)內置__consumer_offsets佔用太多磁盤空間
如果__consumer_offsets消耗過多的磁盤空間,需要顯式地用jstack 命令查看一下kafka-log-cleaner-thread前綴的線程狀態。通常都是因爲線程掛掉無法及時清理__consumer_offsets,此時需要重啓相應的 Broker。
三、Kafka動態配置
1、Kafka動態配置簡介
Kafka安裝目錄的config/server.properties文件可以用於配置靜態參數(Static Configs)。通常會指定server.properties文件的路徑來啓動Broker。如果要設置Broker端的任何參數,必須在server.properties文件中顯式地增加一行對應的配置,啓動Broker進程,令參數生效。通常會一次性設置好所有參數後,再啓動Broker,但如果需要變更任何參數時,必須重啓Broker。
但生產環境中如果每次修改Broker端參數都需要重啓Broker,Kafka集羣的可用性必然受到限制,因此Kafka 1.1.0版本中正式引入動態Broker參數(Dynamic Broker Configs),即修改參數值後,無需重啓Broker就能立即生效。Kafka 2.3版本中Broker端參數有200多個,但Kafka社區並沒有將每個參數都升級成動態參數,僅把一部分參數升級爲可動態調整。
在Kafka 1.1後官方文檔的Broker Configs表中增加了Dynamic Update Mode列,有3類值,分別是read-only、per-broker和cluster-wide。
(1)read-only。read-only類型參數是靜態參數,只有重啓Broker,才能令修改生效。
(2)per-broker。per-broker類型參數屬於動態參數,修改後,只會在對應的Broker上生效。
(3)cluster-wide。cluster-wide類型參數也屬於動態參數,修改後,會在整個集羣範圍內生效,對所有Broker都生效。
通過運行無參數的kafka-configs.sh腳本,其說明文檔會列出當前動態Broker參數。
2、Kafka動態參數應用場景
Broker動態參數使用場景非常廣泛,包括但不限於以下幾種:
(1)動態調整Broker端各種線程池大小,實時應對突發流量。
(2)動態調整Broker端連接信息或安全配置信息。
(3)動態更新SSL Keystore有效期。
(4)動態調整Broker端Compact操作性能。
(5)實時變更JMX指標收集器(JMX Metrics Reporter)。
通常,當Kafka Broker入站流量(inbound data)激增時,會造成Broker端請求積壓(Backlog)。此時可以動態增加網絡線程數和I/O線程數,快速處理積壓請求。當流量洪峯過後,可以將線程數調整回原值,減少對資源的浪費。整個過程不需要重啓Broker,並且可以將調整線程數的操作,封裝進定時任務中,以實現自動擴縮容。
3、Kafka動態參數保存
Kafka將Broker動態參數保存在ZooKeeper中。
changes是用來實時監測動態參數變更的,不會保存參數值。
topics是用來保存Kafka TOPIC級別參數的,不屬於Broker動態參數,但能夠動態變更。
users和 clients則是用於動態調整客戶端配額(Quota)的znode節點。所謂配額,是指Kafka運維人員限制連入集羣的客戶端的吞吐量或者是限定使用的CPU資源。
/config/brokers znode纔是保存動態Broker參數的地方。znode有兩大類子節點,第一類子節點就只有一個,即< default >,保存cluster-wide範圍的動態參數;第二類以broker.id爲名,保存特定Broker的per-broker範圍參數。
4、Kafka動態參數配置
配置動態Broker參數的工具行命令是Kafka自帶的kafka-configs腳本。
設置cluster-wide範圍動態參數,需要顯式指定--entity-default。kafka-configs.sh --bootstrap-server kafka-host:port --entity-type brokers --entity-default --alter --add-config unclean.leader.election.enable=true
可以使用--describe命令查看cluster-wide範圍動態Broker參數設置:kafka-configs.sh --bootstrap-server kafka-host:port --entity-type brokers --entity-default --describe
設置per-broker範圍參數命令如下:kafka-configs.sh --bootstrap-server kafka-host:port --entity-type brokers --entity-name 1 --alter --add-config unclean.leader.election.enable=false
可以使用--describe命令查看per-broker範圍動態Broker參數設置:kafka-configs.sh --bootstrap-server kafka-host:port --entity-type brokers --entity-name 1 --describe
刪除cluster-wide範圍參數命令如下:kafka-configs.sh --bootstrap-server kafka-host:port --entity-type brokers --entity-default --alter --delete-config unclean.leader.election.enable
刪除per-broker範圍參數命令如下:kafka-configs.sh --bootstrap-server kafka-host:port --entity-type brokers --entity-name 1 --alter --delete-config unclean.leader.election.enable
5、常用Broker動態參數
(1)log.retention.ms
修改日誌留存時間,可以在Kafka集羣層面動態變更日誌留存時間。(2)num.io.threads和num.network.threads。
在實際生產環境中,Broker端請求處理能力經常要按需擴容。
(3)SSL相關的參數。
SSL相關的主要4個參數:ssl.keystore.type、ssl.keystore.location、ssl.keystore.password和ssl.key.password。動態實時調整SSL參數,可以創建過期時間很短的SSL證書。每當動態調整SSL參數時,Kafka底層會重新配置Socket連接通道並更新Keystore。
(4)num.replica.fetchers
通常,Follower副本拉取速度比較慢,常見的做法是增加num.replica.fetchers參數值,確保有充足的線程可以執行Follower副本向Leader 副本的拉取。通過調整動態參數,不需要再重啓Broker,就能立即在 Follower端生效。
四、Kafka消費者組位移
1、Kafka消費者組位移
傳統消息中間件(RabbitMQ 或 ActiveMQ)處理和響應消息的方式是破壞性的(destructive),即一旦消息被成功處理,就會被從Broker上刪除。而Kafka是基於日誌結構(log-based)的消息引擎,消費者在消費消息時,僅僅從磁盤文件上讀取數據,不會刪除消息數據,並且位移數據是由消費者控制的,因此能夠很容易地修改位移,實現重複消費歷史數據的功能。
2、位移策略
位移策略根據位移維度和時間維度分爲七種。位移維度是指根據位移值來重設,即直接把消費者的位移值重設成指定的位移值;時間維度是可以給定一個基準時間,讓消費者把位移調整成大於基準時間的最小位移。
Earliest策略表示將位移調整到TOPIC當前最早位移處。最早位移不一定是0,因爲在生產環境中,太過久遠的消息通常會被Kafka自動刪除,所以當前最早位移很可能是一個大於0的值。如果想要重新消費主題的所有消息,那麼可以使用Earliest策略。
Latest策略表示把位移重設成最新末端位移。如果想跳過所有歷史消息,從最新的消息處開始消費,可以使用Latest策略。
Current策略表示將位移調整成消費者當前提交的最新位移。
Specified-Offset策略則是比較通用的策略,表示消費者把位移值調整到指定的位移處。如消費者程序在處理某條錯誤消息時,可以手動地跳過此消息的處理。
Shift-By-N策略表示跳過的位移的相對數值,可以是負數,負數表示把位移重設成當前位移的前N條位移處。
DateTime策略表示將位移重置到指定時間後的最早位移處。如想重新消費昨天的數據,可以使用DateTime策略重設位移到昨天0點。
Duration策略表示指定相對的時間間隔,然後將位移調整到距離當前給定時間間隔的位移處,具體格式是 PnDTnHnMnS,是一個符合ISO-8601規範的Duration格式,以字母P開頭,後面由4部分組成,即 D、H、M和S,分別表示天、小時、分鐘和秒。如果想將位移調回到15分鐘前,可以指定PT0H15M0S。
3、重設消費者組位移
重設消費者組位移的方式有兩種,一種是通過消費者API來實現,一種是通過kafka-consumer-groups.sh命令行腳本來實現。
(1)消費者API方式
通過Java API重設位移,需要調用KafkaConsumer的seek系列方法。
void seek(TopicPartition partition, long offset);
void seek(TopicPartition partition, OffsetAndMetadata offsetAndMetadata);
void seekToBeginning(Collection<TopicPartition> partitions);
void seekToEnd(Collection<TopicPartition> partitions);每次調用seek方法只能重設一個分區的位移。OffsetAndMetadata是一個封裝Lon 型的位移和自定義元數據的複合類。seekToBeginning和seekToEnd擁有一次重設多個分區的能力。
設置Earliest位移策略的Java代碼如下:
Properties consumerProperties = new Properties();
consumerProperties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
consumerProperties.put(ConsumerConfig.GROUP_ID_CONFIG, groupID);
consumerProperties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
consumerProperties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
consumerProperties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
consumerProperties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList);
String topic = "test"; // 要重設位移的Kafka主題
try (final KafkaConsumer<String, String> consumer =
new KafkaConsumer<>(consumerProperties)) {
consumer.subscribe(Collections.singleton(topic));
consumer.poll(0);
consumer.seekToBeginning(
consumer.partitionsFor(topic).stream().map(partitionInfo ->
new TopicPartition(topic, partitionInfo.partition()))
.collect(Collectors.toList()));
} 消費者程序必須要禁止自動提交位移。
組ID要設置成要重設的消費者組的組ID。
調用seekToBeginning方法時,需要一次性構造主題的所有分區對象。
必須要調用帶長整型的poll方法,而不要調用consumer.poll(Duration.ofSecond(0))。
設置Latest位移策略的Java代碼如下:
consumer.seekToEnd(consumer.partitionsFor(topic).stream().map(partitionInfo->new TopicPartition(topic, partitionInfo.partition())).collect(Collectors.toList()));
設置Current 位移策略的Java代碼如下:
consumer.partitionsFor(topic).stream().map(info->new TopicPartition(topic,info.partition())).forEach(tp->{long committedOffset = consumer.committed(tp).offset();consumer.seek(tp, committedOffset);
});partitionsFor方法獲取給定主題的所有分區,然後依次獲取對應分區上的已提交位移,最後通過seek方法重設位移到已提交位移處。
(2)命令行腳本方式
Kafka 0.11版本中,引入了通過kafka-consumer-groups.sh腳本重設消費者位移的功能。
Earliest策略直接指定–to-earliest:kafka-consumer-groups.sh --bootstrap-server kafka-host:port --group test-group --reset-offsets --all-topics --to-earliest –execute
Latest策略直接指定–to-latest:kafka-consumer-groups.sh --bootstrap-server kafka-host:port --group test-group --reset-offsets --all-topics --to-latest --execute
Current策略直接指定–to-current:kafka-consumer-groups.sh --bootstrap-server kafka-host:port --group test-group --reset-offsets --all-topics --to-current --execute
Specified-Offset策略直接指定–to-offset:kafka-consumer-groups.sh --bootstrap-server kafka-host:port --group test-group --reset-offsets --all-topics --to-offset <offset> --execute
Shift-By-N策略直接指定–shift-by N:kafka-consumer-groups.sh --bootstrap-server kafka-host:port --group test-group --reset-offsets --shift-by <offset_N> --execute
DateTime策略直接指定–to-datetime:kafka-consumer-groups.sh --bootstrap-server kafka-host:port --group test-group --reset-offsets --to-datetime 2020-03-08T12:00:00.000 --execute
Duration策略直接指定–by-duration:kafka-consumer-groups.sh --bootstrap-server kafka-host:port --group test-group --reset-offsets --by-duration PT0H60M0S --execute
五、Kafka AdminClient工具
1、AdminClient引入
Kafka管理工具腳本的缺陷如下:
(1)只能運行在控制檯,集成度差,不能集成到應用程序、運維框架、監控平臺。
(2)通過連接ZooKeeper來提供服務,會繞過Kafka的用戶認證機制,不安全。
(3)需要使用Kafka服務器端的代碼。
基於上述缺陷,Kafka 0.11版本正式推出Java客戶端版的AdminClient。
2、AdminClient功能特性
(1)主題管理:包括主題的創建、刪除和查詢。
(2)權限管理:包括具體權限的配置與刪除。
(3)配置參數管理:包括Kafka各種資源的參數設置、詳情查詢。Kafka資源包括Broker、主題、用戶、Client-id等。
(4)副本日誌管理:包括副本底層日誌路徑的變更和詳情查詢。
(5)分區管理:即創建額外的主題分區。
(6)消息刪除:即刪除指定位移前的分區消息。
(7)Delegation Token管理:包括Delegation Token創建、更新、過期和詳情查詢。
(8)消費者組管理:包括消費者組的查詢、位移查詢和刪除。
(9)Preferred領導者選舉:推選指定主題分區的Preferred Broker爲領導者。
3、AdminClient工作原理
AdminClient採用雙線程設計:前端主線程和後端I/O線程,前端線程負責將用戶要執行的操作轉換成對應的請求,然後再將請求發送到後端I/O線程的隊列中;而後端I/O線程從隊列中讀取相應的請求,然後發送到對應的Broker節點上,然後把執行結果保存起來,以便等待前端線程的獲取。AdminClient內部大量使用生產者-消費者模式將請求生成與處理解耦。
前端主線程會創建名爲Call的請求對象實例,Call主要任務由兩個:
(1)構建對應的請求對象。如果要創建主題,創建CreateTopicsRequest;如果查詢消費者組位移,創建OffsetFetchRequest。
(2)指定響應的回調邏輯。如從Broker端接收到CreateTopicsResponse後要執行的動作。一旦創建好Call實例,前端主線程會將其放入到新請求隊列(New Call Queue)中,此時前端主線程的任務完成,只需要等待結果返回即可。
後端I/O線程使用3個隊列來承載不同時期的請求對象,分別是新請求隊列、待發送請求隊列和處理中請求隊列。新請求隊列的線程安全由Java的monitor鎖來保證。爲了確保前端主線程不會因爲monitor鎖被阻塞,後端I/O線程會定期地將新請求隊列中的所有Call實例全部搬移到待發送請求隊列中進行處理。待發送請求隊列和處理中請求隊列只由後端I/O線程處理,因此無需任何鎖機制來保證線程安全。
當I/O線程在處理某個請求時,會顯式地將請求保存在處理中請求隊列。一旦處理完成,I/O線程會自動地調用Call對象中的回調邏輯完成最後的處理。最後,I/O線程會通知前端主線程結果已經準備完畢,前端主線程能夠及時獲取到執行操作的結果。AdminClient使用Java Object對象的wait和notify實現的通知機制。
後端I/O線程名字的前綴是kafka-admin-client-thread。如果AdminClient程序貌似在正常工作,但執行的操作沒有返回結果或者hang住,可能是因爲I/O線程出現問題導致的。
4、構造和銷燬AdminClient實例
如果正確地引入kafka-clients依賴,那麼應該可以在編寫Java程序時看到AdminClient對象,完整類路徑是org.apache.kafka.clients.admin.AdminClient。創建AdminClient實例需要手動構造一個Properties對象或Map對象,然後傳給對應的方法。最常見而且必須要指定的參數是bootstrap.servers參數。
Properties props = new Properties();
props.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka-host:port");
props.put("request.timeout.ms", 600000);
AdminClient client = AdminClient.create(props);AdminClient實例銷燬需要顯式調用close方法。
5、AdminClient實例
(1)創建Topic
String newTopicName = "test-topic";
try (AdminClient client = AdminClient.create(props)) {
NewTopic newTopic = new NewTopic(newTopicName, 10, (short) 3);
CreateTopicsResult result = client.createTopics(Arrays.asList(newTopic));
result.all().get(10, TimeUnit.SECONDS);
}(2)消費者組位移查詢
String groupID = "test-group";
try (AdminClient client = AdminClient.create(props)) {
ListConsumerGroupOffsetsResult result = client.listConsumerGroupOffsets(groupID);
Map<TopicPartition, OffsetAndMetadata> offsets =
result.partitionsToOffsetAndMetadata().get(10, TimeUnit.SECONDS);
System.out.println(offsets);
}(3)Broker磁盤佔用查詢
try (AdminClient client = AdminClient.create(props)) {
DescribeLogDirsResult ret = client.describeLogDirs(Collections.singletonList(targetBrokerId)); // 指定Broker id
long size = 0L;
for (Map<String, DescribeLogDirsResponse.LogDirInfo> logDirInfoMap : ret.all().get().values()) {
size += logDirInfoMap.values().stream().map(logDirInfo -> logDirInfo.replicaInfos).flatMap(
topicPartitionReplicaInfoMap ->
topicPartitionReplicaInfoMap.values().stream().map(replicaInfo -> replicaInfo.size))
.mapToLong(Long::longValue).sum();
}
System.out.println(size);
}AdminClient的describeLogDirs方法獲取指定Broker上所有分區主題的日誌路徑信息。
六、Kafka認證機制
1、Kafka認證機制簡介
Kafka 0.9.0.0版本開始,Kafka正式引入認證機制,實現基礎的安全用戶認證,用於將Kafka上雲或進行多租戶管理。Kafka 2.3版本支持基於SSL和基於SASL的安全認證機制。
SSL認證主要是指Broker和客戶端的雙路認證(2-way authentication)。通常,SSL加密(Encryption)已經啓用了單向認證,即客戶端認證Broker的證書(Certificate)。如果要做SSL認證,需要啓用雙路認證,即Broker也要認證客戶端的證書。SSL通常用於通信加密,使用SASL來做Kafka認證實現。
Kafka支持通過SASL做客戶端認證,SASL是提供認證和數據安全服務的框架。Kafka支持的SASL機制有5種,在不同版本中被引入,因此需要根據Kafka版本選擇其所支持的認證機制。
(1)GSSAPI:基於Kerberos認證機制使用的安全接口,在0.9版本中被引入,用於已經實現Kerberos認證機制的場景。
(2)PLAIN:基於簡單的用戶名/密碼認證的機制,在0.10版本中被引入,與SSL加密搭配使用。PLAIN是一種認證機制,而PLAINTEXT是未使用SSL時的明文傳輸。PLAIN認證機制的配置和運維成本相對較小,適合於小型公司Kafka集羣。但PLAIN認證機制不能動態地增減認證用戶,必須重啓Kafka集羣才能令變更生效。由於所有認證用戶信息全部保存在靜態文件中,所以只能重啓Broker,才能重新加載變更後的靜態文件。
(3)SCRAM:主要用於解決PLAIN機制安全問題的新機制,在0.10.2版本中被引入。通過將認證用戶信息保存在ZooKeeper的方式,避免了動態修改需要重啓Broker的弊端。可以使用Kafka提供的命令動態地創建和刪除用戶,無需重啓整個集羣。
(4)OAUTHBEARER:基於OAuth 2認證框架的新機制,在2.0版本中被引進。OAuth是一個開發標準,允許用戶授權第三方應用訪問用戶在某網站上的資源,而無需將用戶名和密碼提供給第三方應用。Kafka不提倡單純使用OAUTHBEARER,因爲其生成的JSON Web Token不安全,必須配以SSL加密才能用在生產環境中。
(5)Delegation Token:用於補充SASL認證機制的輕量級認證機制,在1.1.0版本被引入。如果要使用Delegation Token,需要先配置好SASL 認證,然後再利用Kafka提供的API獲取對應的Delegation Token。Broker和客戶端在做認證時可以直接使用token,不用每次都去KDC 獲取對應的ticket(Kerberos 認證)或傳輸Keystore文件(SSL認證)。
2、Kafka認證機制比較

3、SASL/SCRAM-SHA-256 配置實例
(1)創建用戶
配置SASL/SCRAM首先需要創建能否連接Kafka集羣的用戶。創建3個用戶,分別是admin用戶、producer用戶和consumer用戶。admin用戶用於實現Broker間通信,producer用於生產消息,consumer用於消費消息。
創建admin:kafka-configs.sh --zookeeper zookeeper-test:2181 --alter --add-config 'SCRAM-SHA-256=[password=123456],SCRAM-SHA-512=[password=123456]' --entity-type users --entity-name admin
創建producer:kafka-configs.sh --zookeeper zookeeper-test:2181 --alter --add-config 'SCRAM-SHA-256=[password=123456],SCRAM-SHA-512=[password=123456]' --entity-type users --entity-name producer
創建consumer:kafka-configs.sh --zookeeper zookeeper-test:2181 --alter --add-config 'SCRAM-SHA-256=[password=123456],SCRAM-SHA-512=[password=123456]' --entity-type users --entity-name consumer
用戶查看:kafka-configs.sh --zookeeper zookeeper-test:2181 --describe --entity-type users --entity-name consumer
(2)創建JAAS文件
配置用戶後,需要爲每個Broker創建一個對應的JAAS文件。
KafkaServer {
org.apache.kafka.common.security.scram.ScramLoginModule required
username="admin"
password="123456";
};配置Broker的server.properties文件:
sasl.enabled.mechanisms=SCRAM-SHA-256
sasl.mechanism.inter.broker.protocol=SCRAM-SHA-256
security.inter.broker.protocol=SASL_PLAINTEXT
listeners=SASL_PLAINTEXT://localhost:9092(3)啓動BrokerKAFKA_OPTS=-Djava.security.auth.login.config=/opt/kafka/config/kafka-broker.jaas kafka-server-start.sh config/server.properties
(4)生產消息
創建Topickafka-topics.sh --bootstrap-server kafka-test:9092 --create --topic test --partitions 1 --replication-factor 1
創建Producer客戶端配置:
security.protocol=SASL_PLAINTEXT
sasl.mechanism=SCRAM-SHA-256
sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required username="producer" password="123456";生產消息:kafka-console-producer.sh --broker-list kafka-test:9092 --topic test --producer.config producer.conf
(5)消費消息
創建Consumer客戶端配置consumer.conf:
security.protocol=SASL_PLAINTEXT
sasl.mechanism=SCRAM-SHA-256
sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required username="consumer" password="123456";(6)動態增減用戶
刪除用戶:kafka-configs.sh --zookeeper zookeeper-test:2181 --alter --delete-config 'SCRAM-SHA-512' --entity-type users --entity-name producer
創建用戶:kafka-configs.sh --zookeeper zookeeper:2181 --alter --add-config 'SCRAM-SHA-256=[iterations=8192,password=123456]' --entity-type users --entity-name test
修改Producer客戶端配置:
security.protocol=SASL_PLAINTEXT
sasl.mechanism=SCRAM-SHA-256
sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required username="test" password="123456";創建每一個客戶端,Producer或Consumer都需要指定相應的配置文件。
七、Kafka授權機制
1、Kafka授權機制簡介
Kafka 授權機制(Authorization)採用ACL(Access-Control List,訪問控制列表)權限模型。Kafka提供了一個可插拔的授權實現機制,會將配置的所有ACL項保存在ZooKeeper下的/kafka-acl節點中。可以通過Kafka自帶的kafka-acls.sh腳本動態地對ACL項進行增刪改查,並讓其立即生效。
2、ACL開啓
Kafka開啓ACL的方法只需要在Broker端的配置文件中增加一行設置即可,即在server.properties文件中配置authorizer.class.name參數。
authorizer.class.name=kafka.security.auth.SimpleAclAuthorizer
authorizer.class.name參數指定了ACL授權機制的實現類。Kafka提供了Authorizer接口,允許開發者實現自己的授權機制,但通常是直接使用Kafka自帶的SimpleAclAuthorizer實現類。設置authorizer.class.name參數,並且啓動Broker後,Broker默認會開啓ACL授權驗證。
3、超級用戶設置
開啓ACL授權後,必須顯式地爲不同用戶設置訪問某項資源的權限,否則,在默認情況下,沒有配置任何ACL的資源是不能被訪問的。但超級用戶能夠訪問所有的資源,即使沒有爲超級用戶設置任何ACL項。超級用戶的設置只需要在Broker端的配置文件server.properties中設置super.users參數。
super.users=User:superuser1;User:superuser2
如果需要一次性指定多個超級用戶,使用分號作爲分隔符。
Kafka支持將所有用戶都配置成超級用戶的用法。如果在server.properties文件中設置allow.everyone.if.no.acl.found=true,那麼所有用戶都可以訪問沒有設置任何ACL的資源。但在生產環境中,特別是對安全有較高要求的環境中,採用白名單機制要比黑名單機制更安全。
4、ACL授權配置
在Kafka中,配置授權的方法是通過kafka-acls.sh腳本。kafka-acls.sh --authorizer-properties zookeeper.connect=zookeeper-test:2181 --add --allow-principal User:test --operation All --topic '*' --cluster
All表示所有操作,topic中的星號則表示所有主題,指定--cluster則說明要爲用戶test設置的是集羣權限。kafka-acls.sh --authorizer-properties zookeeper.connect=zookeeper-test:2181 --add --allow-principal User:'*' --allow-host '*' --deny-principal User:BadUser --deny-host 192.168.1.120 --operation Read --topic test
User的星號表示所有用戶,allow-host的星號則表示所有IP地址。允許所有的用戶使用任意的IP地址讀取名爲test的TOPIC數據,禁止BadUser用戶和192.168.1.120的IP地址訪問test下的消息。
5、Kafka ACL權限列表
Kafka提供了細粒度的授權機制,kafka-acls.sh直接指定--producer能同時獲得Producer所需權限,指定--consumer可以獲得 Consumer所需權限。Kafka授權機制可以不配置認證機制而單獨使用,如只爲IP地址設置權限。kafka-acls.sh --authorizer-properties zookeeper.connect=zookeeper-test:2181 --add --deny-principal User:* --deny-host 192.168.1.120 --operation Write --topic test
禁止Producer在192.168.1.120 IP上向test發送數據。
6、雲環境多租戶權限設置
如果Kafka集羣部署在雲上,對於多租戶需要設置合理的認證機制,併爲每個連接Kafka集羣的客戶端授予合適權限。
(1)開啓ACLauthorizer.class.name=kafka.security.auth.SimpleAclAuthorizer
(2)開啓白名單機制
在Kafka的server.properties文件中,不要設置allow.everyone.if.no.acl.found=true。
(3)爲SSL用戶授權
使用kafka-acls.sh爲SSL用戶授予集羣的權限。我們以前面的例子來進行一下說明。在配置 SSL 時,指定用戶的 Distinguished Name 爲“CN=Xi Hu, OU=YourDept, O=YourCompany, L=Beijing, ST=Beijing, C=CN”。在設置 Broker 端參數時,指定 security.inter.broker.protocol=SSL,即強制指定 Broker 間的通訊也採用 SSL 加密。kafka-acls.sh --authorizer-properties zookeeper.connect=zookeeper-test:2181 --add --allow-principal User:"CN=Xi Hu,OU=YourDept,O=YourCompany,L=Beijing,ST=Beijing,C=CN" --operation All --cluster
(4)爲客戶端授權
爲生產者授予producer權限:kafka-acls.sh --authorizer-properties zookeeper.connect==zookeeper-test:2181 --add --allow-principal User:"CN=Xi Hu,OU=YourDept,O=YourCompany,L=Beijing,ST=Beijing,C=CN" --producer --topic 'test'
爲消費者授予consumer權限:kafka-acls.sh --authorizer-properties zookeeper.connect=zookeeper-test:2181 --add --allow-principal User:"CN=Xi Hu,OU=YourDept,O=YourCompany,L=Beijing,ST=Beijing,C=CN" --consumer --topic 'test' --group '*'
八、MirrorMaker
1、MirrorMaker簡介
通常,大多數業務需求使用一個Kafka集羣即可滿足,但有些場景確實會需要多個Kafka集羣同時工作,比如爲了便於實現災難恢復,可以在兩個機房分別部署單獨的Kafka集羣。如果其中一個機房出現故障,可以很容易地把流量切換到另一個正常運轉的機房。如果要爲地理相近的客戶提供低延時的消息服務,而主機房離客戶很遠時,可以在靠近客戶的機房部署一套Kafka集羣,服務於客戶,從而提供低延時的服務。
爲了在多個Kafka集羣間實現數據同步,Kafka提供了跨集羣數據鏡像工具MirrorMaker。通常,數據在單個集羣下不同節點之間的拷貝稱爲備份,而數據在集羣間的拷貝稱爲鏡像(Mirroring)。
MirrorMaker本質是一個消費者+生產者的程序。消費者負責從源集羣(Source Cluster)消費數據,生產者負責向目標集羣(Target Cluster)發送消息。整個鏡像流程如下:
MirrorMaker連接的源集羣和目標集羣,會實時同步消息。實際場景中,用戶會部署多套Kafka集羣,用於實現不同的目的。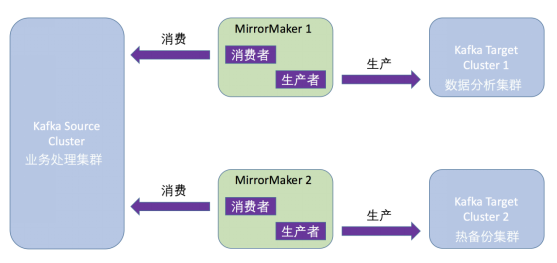
源集羣負責主要的業務處理,目標集羣1可以用於執行數據分析,目標集羣2則充當源集羣的熱備份。
2、MirrorMaker腳本工具
Kafka默認提供MirrorMaker命令行工具kafka-mirror-maker腳本,其常見用法是指定生產者配置文件、消費者配置文件、線程數以及要執行數據鏡像的TOPIC正則表達式。kafka-mirror-maker.sh --consumer.config config/consumer.properties --producer.config config/producer.properties --num.streams 8 --whitelist ".*"
--consumer.config:指定MirrorMaker中消費者的配置文件地址,最主要的配置項是bootstrap.servers,即MirrorMaker從哪個Kafka集羣讀取消息。由於MirrorMaker有可能在內部創建多個消費者實例並使用消費者組機制,因此還需要設置group.id參數。另外,需要配置auto.offset.reset=earliest,否則MirrorMaker只會拷貝在其啓動後到達源集羣的消息。
--producer.config:指定MirrorMaker內部生產者組件的配置文件地址。必須顯式地指定參數bootstrap.servers,配置拷貝的消息要發送到的目標集羣。
--num.streams:MirrorMaker要創建多少個KafkaConsumer實例,會在後臺創建並啓動多個線程,每個線程維護專屬的消費者實例。
--whitelist:接收一個正則表達式。所有匹配該正則表達式的TOPIC都會被自動地執行鏡像。“.*”表示要同步源集羣上的所有TOPIC。
3、跨集羣數據鏡像實例
(1)配置生產者和消費者
生產者配置文件producer.config:
producer.properties:
bootstrap.servers=kafka-test1:9092消費者配置文件consumer.config:
consumer.properties:
bootstrap.servers=kafka-test2:9092
group.id=mirrormaker
auto.offset.reset=earliest(2)MirrorMaker工具啓動kafka-mirror-maker.sh --producer.config producer.config --consumer.config consumer.config --num.streams 4 --whitelist ".*"
如果MirrorMaker內部消費者會使用輪詢策略(Round-robin)來爲消費者實例分配分區,需要consumer.properties文件中增加配置:partition.assignment.strategy=org.apache.kafka.clients.consumer.RoundRobinAssignor
(3)結果驗證kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list kafka-test:9092 --topic test --time -2
-1和-2分別表示獲取某分區最新的位移和最早的位移,兩個位移值的差值就是分區當前的消息數。
MirrorMaker在執行消息鏡像的過程中,如果發現要同步的Topic在目標集羣上不存在,會根據目標集羣的Kafka Broker端參數num.partitions和default.replication.factor默認值,自動將Topic創建出來。在生產環境中,推薦提前把要同步的所有主題按照源集羣上的規格在目標集羣上地創建出來,避免在源集羣某個分區的消息同步到目標集羣后位於其它分區中。MirrorMaker默認會同步內置Topic,在鏡像位移主題時,如果發現目標集羣尚未創建位移主題,會根據Broker端參數offsets.topic.num.partitions和offsets.topic.replication.factor來創建位移Topic,默認配置是50個分區,每個分區3個副本。在Kafka 0.11.0.0版本前,Kafka不會嚴格依照offsets.topic.replication.factor參數值,即如果設置offsets.topic.replication.factor參數值爲3,而當前存活的Broker數量少於3,位移主題依然能被成功創建,副本數會取offsets.topic.replication.factor參數值和存活Broker數之間的較小值。從Kafka 0.11.0.0版本開始,Kafka會嚴格遵守設定offsets.topic.replication.factor參數值,如果發現存活Broker數量小於參數值,就會直接拋出異常,通知主題創建失敗。
4、其它跨集羣數據鏡像工具
(1)uReplicator
Uber公司在使用MirrorMaker過程中發現了一些缺陷,比如MirrorMaker中的消費者使用的是消費者組機制,會不可避免地會碰到很多Rebalance問題。因此,Uber研發了uReplicator,使用Apache Helix作爲集中式的TOPIC分區管理組件來管理分區的分配,並且重寫消費者程序,替代MirrorMaker下的消費者,從而避免Rebalance各種問題。
(2)Brooklin Mirror Maker
針對MirrorMaker工具不易實現管道化的缺陷,LinkedIn進行針對性的改進並對性能進行優化研發了Brooklin Mirror Maker。
(3)Confluent Replicator
Replicator是Confluent提供的企業級的跨集羣鏡像方案,可以便捷地提供Kafka TOPIC在不同集羣間的遷移,同時還能自動在目標集羣上創建與源集羣上配置一模一樣的TOPIC,極大地方便運維管理。