




face_recognition使用世界上最簡單的人臉識別庫,在Python或命令行中識別和操作人臉。
使用dlib最先進的人臉識別技術構建而成,並具有深度學習功能。 該模型在Labeled Faces in the Wild基準中的準確率爲99.38%。
face_recognition 官方文檔 :https://pypi.org/project/face_recognition/
1|1查找圖片中的面孔
|
1 2 3 4 5 6 7 8 9 10 11 |
|

1|2查找和操作圖片中的面部特徵
|
1 2 3 4 5 6 7 8 9 |
|
/usr/bin/python3.6 /home/wjw/PycharmProjects/face/find_nose.py[{'chin': [(280, 439), (282, 493), (283, 547), (290, 603), (308, 654), (340, 698), (380, 733), (427, 760), (485, 770), (544, 766), (592, 738), (634, 704), (668, 661), (689, 613), (701, 563), (712, 514), (722, 466)], 'left_eyebrow': [(327, 373), (354, 340), (395, 323), (442, 324), (487, 337)], 'right_eyebrow': [(560, 344), (603, 340), (647, 348), (682, 372), (698, 410)], 'nose_bridge': [(519, 410), (517, 444), (515, 477), (513, 512)], 'nose_tip': [(461, 548), (485, 554), (508, 561), (532, 558), (555, 556)], 'left_eye': [(372, 424), (399, 420), (426, 420), (451, 429), (424, 433), (397, 432)], 'right_eye': [(577, 440), (605, 437), (631, 442), (655, 451), (628, 454), (601, 449)], 'top_lip': [(415, 617), (452, 600), (484, 593), (506, 600), (525, 598), (551, 610), (579, 634), (566, 630), (524, 620), (504, 619), (482, 616), (428, 616)], 'bottom_lip': [(579, 634), (546, 636), (518, 636), (498, 635), (475, 632), (447, 626), (415, 617), (428, 616), (479, 605), (500, 610), (520, 610), (566, 630)]}] Process finished with exit code 0
美圖
尋找面部特徵對於許多重要的東西非常有用,比如美圖。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
|


(醜了哈?沒關係,技術重要!!)
1|3識別圖片中的面孔
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|

“人臉識別”是人工智能的一個重要應用,聽起來技術含量很高,貌似非常複雜,具體的實現也的確非常複雜,目前的算法一般都基於深度學習神經網絡。但如果僅僅是使用識別功能,目前已有封裝好的功能模塊,並不需要訓練模型,甚至不需要了解任何算法原理,只需調用Python的三方模塊,幾行代碼即可實現人臉識別。
face_recognition是目前使用方法最簡單,效果也非常好的人臉識別庫,它的離線識別率高達99.38%。除了檢測面部位置,它還能快速識別出面部特徵:如眉毛、眼睛、鼻子、嘴,識別具體的人,對比兩張臉的相似度等等。從後面例程可以看到,識別位置相當準確。
一、安裝和原理
face_recognition底層基於dlib實現。dlib是一個人臉關鍵點檢測庫,它的核心功能由C++實現,適用於多個平臺。不同於一般的Python三方模塊,它在安裝時需要編譯,其Github上主要介紹了它在Linux和MacOS系統的安裝方法。在Windows系統下編譯安裝過程比較複雜,需要安裝Visual Studio的 Visual C++ for Linux環境,相關工具幾十個G,安裝步驟和注意事項也很多,因此還是建議使用Linux系統(儘管這可能讓一些讀者望而卻步)。
在Linux下安裝方法非常簡單:
$ pip install face_recognition
Linux將自動安裝face_recognition及其依賴的三方工具集。同時,建議下載源碼:
$ git clone https://github.com/davisking/dlib.git
$ git clone https://github.com/ageitgey/face_recognition_models
$ git clone https://github.com/ageitgey/face_recognition
下載源碼主要爲了通過其示例學習三方模塊的使用方法,以及瞭解底層調用的庫和具體的實現方法,以及相關的文檔。
dlib模塊實現最核心的功能——人臉關鍵點檢測,從源碼中可以看到,它主要由C++語言實現,並提供了C++和Python接口,因此,可以在不同環境下開發和使用,目前也有開發者將其移植到android手機上。
face_recognition_models存儲了訓練好的模型,供face_recognition模塊調用,模型的擴展名爲“.dat”。
face_recognition模塊的功能代碼並不多,主要是封裝了dlib,簡化了開發者的調用步驟。其example中有很多有趣的例程,比如:虛化人臉(類似於馬賽克效果),化妝,追蹤視頻中的人臉,甚至還啓動WebService,識別用戶上傳的圖片;還包括與機器學習模型KNN,SVM結合使用的例程,其原理也是用dlib提取人臉特徵,再加入機器學習模型訓練,根據需求,生成新的模型。可將其看作圖像識別在人臉識別垂直領域的細化和封裝。
dlib的使用方法並不複雜,而face_recognition則更加簡單,face_recognition還提供了直接運行的兩個工具:人臉檢測face_dection和人臉識別face_recognition。
二、face_recognition例程
本例程調用face_recognition模塊,實現了人臉識別,畫眉、畫眼線和塗口線的功能。
from PIL import Image, ImageDraw
import face_recognition
image = face_recognition.load_image_file("face2.png")
face_landmarks_list = face_recognition.face_landmarks(image)
for face_landmarks in face_landmarks_list:
color = [238,42,68]
pil_image = Image.fromarray(image)
d = ImageDraw.Draw(pil_image, 'RGBA')
print(face_landmarks.keys())
d.polygon(face_landmarks['left_eyebrow'], fill=(68, 54, 39, 50))
d.polygon(face_landmarks['right_eyebrow'], fill=(68, 54, 39, 50))
d.polygon(face_landmarks['top_lip'], fill=(color[0], color[1], color[2], 80))
d.polygon(face_landmarks['bottom_lip'], fill=(color[0], color[1], color[2], 80))
d.line(face_landmarks['left_eye'] + [face_landmarks['left_eye'][0]], fill=(0, 0, 0, 50), width=3)
d.line(face_landmarks['right_eye'] + [face_landmarks['right_eye'][0]], fill=(0, 0, 0, 50), width=3)
pil_image.show()
pil_image.save('out4.png')
三、dlib例程
本例程直接調用dlib模塊,使用face_recognition_models中訓練好的模型,識別人臉上的68個特徵點。
import dlib
import cv2
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor('/exports/git/face_recognition_models/face_recognition_models/models/shape_predictor_68_face_landmarks.dat')
img = cv2.imread("/tmp/face2.png")
dets = detector(img, 1)
for k, d in enumerate(dets):
print("Detection {}: Left: {} Top: {} Right: {} Bottom: {}".format(
k, d.left(), d.top(), d.right(), d.bottom()))
shape = predictor(img, d)
for index, pt in enumerate(shape.parts()):
print('Part {}: {}'.format(index, pt))
pt_pos = (pt.x, pt.y)
cv2.circle(img, pt_pos, 1, (255, 0, 0), 2)
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(img, str(index+1),pt_pos,font, 0.3, (0, 0, 255), 1, cv2.LINE_AA)
cv2.imshow('img', img)
k = cv2.waitKey()
cv2.destroyAllWindows()
四、總結
對於大多數的Python程序,開發者需要的90%功能三方模塊都已經實現完成,很多功能都已非常成熟,剩餘的10%由開發者根據需求進行適配即可完成。這使得開發者在短時間內即可實現基本功能,並且看起來非常強大,但是後期效果提升比較困難。

個人覺得:人臉識別工具真的很適合美妝賣家,買家上傳一張相片,合成各種色號的效果;在視頻通話過程中察言觀色;圖片識別,刷臉支付,美顏相機;稍加一些藝術處理,自動生成漫畫等等。
五、參考
1. 具體用法介紹
https://github.com/ageitgey/face_recognition
2.表情識別規則
https://www.jianshu.com/p/7596e428bcfe
我們也可以在Python代碼中導入face_recognition模塊來使用它,使用方式超級簡單,只需操作幾個API即可實現人臉檢測的效果。
關於項目代碼可從github上下載下來:點這裏 ,項目文件夾中包括了樣例代碼以及測試所用的圖片。
(一)檢測兩張圖片是否爲同一個人
代碼:
import face_recognition
known_image = face_recognition.load_image_file("/softs/test/known_people/Obama.jpg")
unknown_image = face_recognition.load_image_file("/softs/test/unknown_pictures/unknown1.jpg")
obama_encoding = face_recognition.face_encodings(known_image)[0]
unknown_encoding = face_recognition.face_encodings(unknown_image)[0]
results = face_recognition.compare_faces([obama_encoding], unknown_encoding)
if results[0] == True:
print ("It's a picture of Obama!")
else:
print ("It's not a picture of Obama!")
自行網上隨便找兩張奧巴馬的圖片(我們假設有一張不知道他是奧巴馬),按照上面的代碼:
調用load_image_file函數來加載這兩張圖片,face_encodings函數用於獲取這兩張圖片中的128維人臉編碼(特徵向量),一個人臉編碼對應一張人臉,如果一張圖片包括n張人臉,那麼該函數的返回值則是一個由n個人臉編碼組成的列表。
獲取兩張圖片的人臉編碼後,調用compare_faces函數識別這兩張照片的人能否匹配上,即檢測未知圖片是不是奧巴馬,該函數返回值是一個由True或False組成的列表,True表示匹配上,False表示不匹配。
輸出結果如下,表明這兩張圖片都是奧巴馬。
It's a picture of Obama!
API說明:
圖像載入函數——load_image_file
load_image_file(file, mode='RGB')加載一個圖像文件到一個numpy array類型的對象上。
參數:
file:待加載的圖像文件名字
mode:轉換圖像的格式。只支持“RGB”(8位RGB, 3通道)和“L”(黑白)
返回值:
一個包含圖像數據的numpy array類型的對象
人臉編碼函數——face_encodings
face_encodings(face_image, known_face_locations=None, num_jitters=1)給定一個圖像,返回圖像中每個人臉的128臉部編碼(特徵向量)。
參數:
face_image:輸入的人臉圖像
known_face_locations:可選參數,如果你知道每個人臉所在的邊界框
num_jitters=1:在計算編碼時要重新採樣的次數。越高越準確,但速度越慢(100就會慢100倍)
返回值:
一個128維的臉部編碼列表
人臉匹配函數——compare_faces
compare_faces(known_face_encodings, face_encoding_to_check, tolerance=0.6)比較臉部編碼列表和候選編碼,看看它們是否匹配,設置一個閾值,若兩張人臉特徵向量的距離,在閾值範圍之內,則認爲其 是同一個人
參數:
known_face_encodings:已知的人臉編碼列表
face_encoding_to_check:待進行對比的單張人臉編碼數據
tolerance=0.6:兩張臉之間有多少距離纔算匹配。該值越小對比越嚴格,0.6是典型的最佳值
返回值:
一個 True或者False值的列表,該表指示了known_face_encodings列表的每個成員的匹配結果
(二)定位圖片中的人臉
代碼:
from PIL import Image
import face_recognition
# Load the jpg file into a numpy array
image=face_recognition.load_image_file("/softs/test_images/johnsnow_test1.jpg")
# Find all the faces in the image using the default HOG-based model.
# This method is fairly accurate, but not as accurate as the CNN model and not GPU accelerated.
# See also: find_faces_in_picture_cnn.py
face_locations = face_recognition.face_locations(image)
print("I found {} face(s) in this photograph.".format(len(face_locations)))
for face_location in face_locations:
# 打印出每張人臉對應四條邊在圖片中的位置(top、right、bottom、left)
top, right, bottom, left = face_location
print ("A face is located at pixel location Top: {}, Left: {}, Bottom: {}, Right: {}")\
.format(top, right, bottom, right)
# You can access the actual face itself like this:
face_image = image[top:bottom, left:right]
pil_image = Image.fromarray(face_image)
pil_image.show()
打印信息:
I found 1 face(s) in this photograph.
A face is located at pixel location Top: 180, Left: 448, Bottom: 366, Right: 448
輸入的原圖片和輸出的人臉定位圖,分別如下左右圖:


API說明:
人臉定位函數——face_locations
face_locations(face_image,number_of_times_to_upsample=1,model="hog")利用CNN深度學習模型或方向梯度直方圖(Histogram of Oriented Gradient, HOG)進行人臉提取。返回值是一個數組(top, right, bottom, left)表示人臉所在邊框的四條邊的位置。
參數:
face_image:輸入的人臉圖像
number_of_times_to_upsample=1:從圖片的樣本中查找多少次人臉,該參數的值越高的話越能發現更小的人臉
model="hog":使用哪種人臉檢測模型。“hog” 準確率不高,但是在CPU上運行更快,“cnn” 更準確更深度(且GPU/CUDA加速,如果有GPU支持的話),默認是“hog”
返回值:
一個元組列表,列表中的每個元組包含人臉的四邊位置(top, right, bottom, left)
與face_locations相似的,可以批次進行多張圖片的人臉定位,使用batch_face_locations,有GPU的可以試一下。
批次人臉定位函數(GPU)——batch_face_locations
batch_face_locations(face_images,number_of_times_to_upsample=1,batch_size=128)使用CNN人臉檢測器返回一個包含人臉特徵的二維數組,如果使用了GPU,這個函數能夠更快速的返回結果;如果不使用GPU的話,該函數就沒必要使用
參數:
face_images:輸入多張人臉圖像組成的list
number_of_times_to_upsample=1:從圖片的樣本中查找多少次人臉,該參數的值越高的話越能發現更小的人臉
batch_size=128:每個GPU一次批處理多少個image
返回值:
一個元組列表,列表中的每個元組包含人臉的四邊位置(top, right, bottom, left)
(三)識別臉部特徵
代碼:
import face_recognition
# Load the jpg file into a numpy array
from PIL import Image, ImageDraw
image = face_recognition.load_image_file("/softs/test_images/two_people.jpg")
# 找出圖片中所有人臉的面部特徵
face_landmarks_list = face_recognition.face_landmarks(image)
print ("I found {} face(s) in this photograph.".format(len(face_landmarks_list)))
# 創建一個PIL ImageDraw對象,後面用於圖像繪製
pil_image = Image.fromarray(image)
d = ImageDraw.Draw(pil_image)
for face_landmarks in face_landmarks_list:
# 打印出圖片中每個臉部特徵的位置
for facial_feature in face_landmarks.keys():
print ("The {} in this face has the following points: {}"
.format(facial_feature, face_landmarks[facial_feature]))
# 用線段描出圖像中的每個臉部特徵
for facial_feature in face_landmarks.keys():
d.line(face_landmarks[facial_feature], width=5)
# Show the picture
pil_image.show()
代碼說明:首先我們還是加載一張人臉圖片,調用face_landmarks函數從該圖片中,得到一個由臉部特徵關鍵點位置組成的字典記錄列表(臉部特徵包括:鼻樑nose_bridge、鼻尖nose_tip、下巴chin、左眼left_eye、右眼right_eye、左眉left_eyebrow、右眉right_eyebrow、上脣top_lip、下脣bottom_lip,可參考下面程序打印輸出的信息)。
接下來爲該圖片構建一個ImageDraw對象,ImageDraw是Python圖像處理庫(PIL)中的一個模塊,模塊提供了圖像對象的簡單2D繪製,用戶可以使用這個模塊創建新的圖像,註釋或潤飾已存在圖像。我們後面調用ImageDraw.line()方法可以用線段描繪出臉部特徵。
打印輸出的部分信息如下:
I found 2 face(s) in this photograph.
The nose_bridge in this face has the following points: [(881L, 128L), (880L, 141L), (880L, 154L), (879L, 167L)]
The left_eye in this face has the following points: [(834L, 124L), (843L, 122L), (851L, 124L), (858L, 129L), (850L, 129L), (841L, 127L)]
The nose_tip in this face has the following points: [(857L, 174L), (865L, 178L), (874L, 181L), (881L, 181L), (888L, 180L)]
The chin in this face has the following points: [(789L, 129L), (788L, 150L), (787L, 171L), (788L, 191L), (795L, 211L), (808L, 227L), (824L, 239L), (842L, 249L), (862L, 253L), (881L, 254L), (897L, 247L), (911L, 236L), (921L, 222L), (928L, 206L), (933L, 188L), (937L, 171L), (940L, 153L)]
The right_eye in this face has the following points: [(896L, 138L), (906L, 136L), (914L, 138L), (920L, 143L), (913L, 144L), (904L, 142L)]
The left_eyebrow in this face has the following points: [(821L, 110L), (831L, 102L), (845L, 101L), (860L, 104L), (872L, 111L)]
The bottom_lip in this face has the following points: [(895L, 209L), (884L, 210L), (875L, 208L), (867L, 207L), (859L, 205L), (850L, 202L), (838L, 198L), (842L, 198L), (861L, 199L), (869L, 201L), (877L, 202L), (891L, 207L)]
The right_eyebrow in this face has the following points: [(891L, 117L), (905L, 116L), (918L, 118L), (929L, 124L), (935L, 135L)]
The top_lip in this face has the following points: [(838L, 198L), (852L, 196L), (863L, 196L), (870L, 200L), (878L, 199L), (887L, 203L), (895L, 209L), (891L, 207L), (877L, 203L), (869L, 202L), (862L, 200L), (842L, 198L)]
......
輸入的原圖片和輸出的臉部特徵繪製圖,分別如下左右圖所示:


API說明:
人臉特徵提取函數——face_landmarks
face_landmarks(face_image,face_locations=None,model="large")給定一個圖像,提取圖像中每個人臉的臉部特徵位置
參數:
face_image:輸入的人臉圖片
face_locations=None:可選參數,默認值爲None,代表默認解碼圖片中的每一個人臉。若輸入face_locations()[i]可指定人臉進行解碼
model="large":輸出的特徵模型,默認爲“large”,可選“small”。當選擇爲"small"時,只提取左眼、右眼、鼻尖這三種臉部特徵。
返回值:
返回值類型爲:List[Dict[str,List[Tuple[Any,Any]]]],是由各個臉部特徵關鍵點位置組成的字典記錄列表,一個Dict對象對應圖片中的一個人臉,其key爲某個臉部特徵(如輸出中的nose_bridge、left_eye等),value是由該臉部特徵各個關鍵點位置組成的List,關鍵點位置是一個Tuple(如上輸出中,nose_bridge對應的關鍵點位置組成的列表爲[(881L, 128L), (880L, 141L), (880L, 154L), (879L, 167L)] )
(四)給奧黑哥化個妝
代碼:
import face_recognition
from PIL import Image, ImageDraw
# Load the jpg file into a numpy array
image = face_recognition.load_image_file("/softs/test_images/obama.jpg")
# Find all facial features in all the faces in the image
face_landmarks_list = face_recognition.face_landmarks(image)
for face_landmarks in face_landmarks_list:
# Create a PIL imageDraw object so we can draw on the picture
pil_image = Image.fromarray(image)
d = ImageDraw.Draw(pil_image,'RGBA')
# 畫個濃眉
d.polygon(face_landmarks['left_eyebrow'], fill=(68, 54, 39, 128))
d.polygon(face_landmarks['right_eyebrow'], fill=(68, 54, 39, 128))
d.line(face_landmarks['left_eyebrow'], fill=(68, 54, 39, 150), width=5)
d.line(face_landmarks['right_eyebrow'], fill=(68, 54, 39, 150), width=5)
# 塗個性感的嘴脣
d.polygon(face_landmarks['top_lip'], fill=(150, 0, 0, 128))
d.polygon(face_landmarks['bottom_lip'], fill=(150, 0, 0, 128))
d.line(face_landmarks['top_lip'], fill=(150, 0, 0, 64), width=8)
d.line(face_landmarks['bottom_lip'], fill=(150, 0, 0, 64), width=8)
# 閃亮的大眼睛
d.polygon(face_landmarks['left_eye'], fill=(255, 255, 255, 30))
d.polygon(face_landmarks['right_eye'], fill=(255, 255, 255, 30))
# 畫眼線
d.line(face_landmarks['left_eye'] + [face_landmarks['left_eye'][0]], fill=(0, 0, 0, 110), width=6)
d.line(face_landmarks['right_eye'] + [face_landmarks['right_eye'][0]], fill=(0, 0, 0, 110), width=6)
pil_image.show()
首先還是先載入圖片,構建一個ImageDraw對象。
polygon方法用於繪製多邊形:第一個參數是多邊形的幾個頂點位置組成的list,第二個參數fill是填充該多邊形的顏色。
line()方法是用來畫多個點之間構成的線段,第一個參數是點位置組成的list,第二個參數fill是線段的顏色,第三個參數width是線段的寬度。
輸入的奧巴馬原圖與化妝後的奧巴馬,分別如下左右圖:


(五)計算人臉特徵向量距離
上述我們使用了compare_faces函數檢測兩張人臉是否能匹配,最後返回值只有True或False。而如果想知道檢測的兩張人臉之間的相似度有多高,則可以使用使用face_distance函數,函數返回的是兩個人臉特徵向量間的歐氏距離,距離越小就說明兩者越相似。除此之外,我們也可以設置一個比對閾值,默認這個閾值爲0.6,表示兩張臉之間的距離在0.6以下才算匹配上,所以閾值設置得越小,那麼對人臉檢測的要求就越高。
代碼:
import face_recognition
# Often instead of just checking if two faces match or not (True or False), it's helpful to see how similar they are.
# You can do that by using the face_distance function.
# The model was trained in a way that faces with a distance of 0.6 or less should be a match. But if you want to
# be more strict, you can look for a smaller face distance. For example, using a 0.55 cutoff would reduce false
# positive matches at the risk of more false negatives.
# Note: This isn't exactly the same as a "percent match". The scale isn't linear. But you can assume that images with a
# smaller distance are more similar to each other than ones with a larger distance.
# 加載已知人名的人臉圖像
known_obama_image = face_recognition.load_image_file("/softs/test_images/obama.jpg")
known_biden_image = face_recognition.load_image_file("/softs/test_images/biden.jpg")
# 獲取人臉編碼(特徵向量)
obama_face_encoding = face_recognition.face_encodings(known_obama_image)[0]
biden_face_encoding = face_recognition.face_encodings(known_biden_image)[0]
known_encodings = [
obama_face_encoding,
biden_face_encoding
]
# 加載測試人臉圖像
image_to_test = face_recognition.load_image_file("/softs/test_images/obama2.jpg")
image_to_test_encoding = face_recognition.face_encodings(image_to_test)[0]
# 計算距離
face_distances = face_recognition.face_distance(known_encodings, image_to_test_encoding)
# 打印:測試人臉分別與已知的兩張人臉之間的距離,並設置比對閾值。
for i, face_distance in enumerate(face_distances):
print("The test image has a distance of {:.2} from known image #{}".format(face_distance, i))
print("- With a normal cutoff of 0.6, would the test image match the known image? {}".format(face_distance < 0.6))
print("- With a very strict cutoff of 0.5, would the test image match the known image? {}".format(face_distance < 0.5))
print("-----------------------------------")
上述代碼中,計算得到測試人臉分別與兩張已知人臉的距離,並設置在不同比對閾值下是否還能匹配上,其實0.6已經可以當做是一個最佳比對閾值了,設爲0.6的時候兩張人臉能匹配上了,但有可能設爲0.5的時候就匹配不上了,因爲設爲0.5時,比對需要更加嚴格。
輸出結果:
The test image has a distance of 0.35 from known image #0
- With a normal cutoff of 0.6, would the test image match the known image? True
- With a very strict cutoff of 0.5, would the test image match the known image? True
-----------------------------------
The test image has a distance of 0.82 from known image #1
- With a normal cutoff of 0.6, would the test image match the known image? False
- With a very strict cutoff of 0.5, would the test image match the known image? False
-----------------------------------
結果表明:測試人臉與第一張人臉的距離爲0.35,與第二張的距離爲0.82。第一張已知人臉在0.5或者0.6的比對閾值之下,都能與測試人臉匹配上(兩張都是奧巴馬);第二張已知人臉在0.5或者0.6的比對閾值之下,都沒能跟測試人臉匹配上(一張奧巴馬,一張拜登)
API說明:
人臉特徵向量距離函數——face_distance
face_distance(face_encodings,face_to_compare)給定一組面部編碼,將它們與已知的面部編碼進行比較,得到歐氏距離。對於每一個比較的臉,歐氏距離代表了這些臉有多相似。
參數:
face_encodings:輸入的人臉圖片
face_to_compare:待進行對比的單張人臉編碼數據
tolerance:比對閾值,即兩張臉之間有多少距離纔算匹配。該值越小對比越嚴格,0.6是典型的最佳值
返回值:
一個numpy ndarray,數組中的歐式距離與faces數組的順序一一對應
Python的開源人臉識別庫:離線識別率高達99.38%
展開
在這篇文章中:
人臉識別的過程
人臉識別分類
DeepFace
1.DeepFace的基本框架
2. 驗證
3. 實驗評估
以往的人臉識別主要是包括人臉圖像採集、人臉識別預處理、身份確認、身份查找等技術和系統。現在人臉識別已經慢慢延伸到了ADAS中的駕駛員檢測、行人跟蹤、甚至到了動態物體的跟蹤。由此可以看出,人臉識別系統已經由簡單的圖像處理發展到了視頻實時處理。而且算法已經由以前的Adaboots、PCA等傳統的統計學方法轉變爲CNN、RCNN等深度學習及其變形的方法。現在也有相當一部分人開始研究3維人臉識別識別,這種項目目前也受到了學術界、工業界和國家的支持。
首先看看現在的研究現狀。如上的發展趨勢可以知道,現在的主要研究方向是利用深度學習的方法解決視頻人臉識別。
主要的研究人員:
如下:中科院計算所的山世光教授、中科院生物識別研究所的李子青教授、清華大學的蘇光大教授、香港中文大學的湯曉鷗教授、Ross B. Girshick等等。
主要開源項目:
SeetaFace人臉識別引擎。該引擎由中科院計算所山世光研究員帶領的人臉識別研究組研發。代碼基於C++實現,且不依賴於任何第三方的庫函數,開源協議爲BSD-2,可供學術界和工業界免費使用。
主要軟件API/SDK:
1.face++。Face++.com 是一個提供免費人臉檢測、人臉識別、人臉屬性分析等服務的雲端服務平臺。Face++是北京曠視科技有限公司旗下的全新人臉技術雲平臺,在黑馬大賽中,Face++獲得年度總冠軍,已獲得聯想之星投資。
2.skybiometry.。主要包含了face detection、face recognition、face grouping。
主要的人臉識別圖像庫:
目前公開的比較好的人臉圖像庫有LFW(Labelled Faces in the Wild)和YFW(Youtube Faces in the Wild)。現在的實驗數據集基本上是來源於LFW,而且目前的圖像人臉識別的精度已經達到99%,基本上現有的圖像數據庫已經被刷爆。下面是現有人臉圖像數據庫的總結:

現在在中國做人臉識別的公司已經越來越多,應用也非常的廣泛。其中市場佔有率最高的是漢王科技。主要公司的研究方向和現狀如下:
- 漢王科技:漢王科技主要是做人臉識別的身份驗證,主要用在門禁系統、考勤系統等等。
- 科大訊飛:科大訊飛在香港中文大學湯曉鷗教授團隊支持下,開發出了一個基於高斯過程的人臉識別技術–Gussian face, 該技術在LFW上的識別率爲98.52%,目前該公司的DEEPID2在LFW上的識別率已經達到了99.4%。
- 川大智勝:目前該公司的研究亮點是三維人臉識別,並拓展到3維全臉照相機產業化等等。
- 商湯科技:主要是一家致力於引領人工智能核心“深度學習”技術突破,構建人工智能、大數據分析行業解決方案的公司,目前在人臉識別、文字識別、人體識別、車輛識別、物體識別、圖像處理等方向有很強的競爭力。在人臉識別中有106個人臉關鍵點的識別。
人臉識別的過程
人臉識別主要分爲四大塊:人臉定位(face detection)、 人臉校準(face alignment)、 人臉確認(face verification)、人臉鑑別(face identification)。
人臉定位(face detection): 對圖像中的人臉進行檢測,並將結果用矩形框框出來。在openCV中有直接能拿出來用的Harr分類器。
人臉校準(face alignment): 對檢測到的人臉進行姿態的校正,使其人臉儘可能的”正”,通過校正可以提高人臉識別的精度。校正的方法有2D校正、3D校正的方法,3D校正的方法可以使側臉得到較好的識別。 在進行人臉校正的時候,會有檢測特徵點的位置這一步,這些特徵點位置主要是諸如鼻子左側,鼻孔下側,瞳孔位置,上嘴脣下側等等位置,知道了這些特徵點的位置後,做一下位置驅動的變形,臉即可被校”正”了。如下圖所示:
這裏介紹一種MSRA在14年的技術:Joint Cascade Face Detection and Alignment(ECCV14)。這篇文章直接在30ms的時間裏把detection和alignment都給做了。

人臉確認(face verification):Face verification,人臉校驗是基於pair matching的方式,所以它得到的答案是“是”或者“不是”。在具體操作的時候,給定一張測試圖片,然後挨個進行pair matching,matching上了則說明測試圖像與該張匹配上的人臉爲同一個人的人臉。一般在小型辦公室人臉刷臉打卡系統中採用的(應該)是這種方法,具體操作方法大致是這樣一個流程:離線逐個錄入員工的人臉照片(一個員工錄入的人臉一般不止一張),員工在刷臉打卡的時候相機捕獲到圖像後,通過前面所講的先進行人臉檢測,然後進行人臉校正,再進行人臉校驗,一旦match結果爲“是”,說明該名刷臉的人員是屬於本辦公室的,人臉校驗到這一步就完成了。在離線錄入員工人臉的時候,我們可以將人臉與人名對應,這樣一旦在人臉校驗成功後,就可以知道這個人是誰了。上面所說的這樣一種系統優點是開發費用低廉,適合小型辦公場所,缺點是在捕獲時不能有遮擋,而且還要求人臉姿態比較正(這種系統我們所有,不過沒體驗過)。下圖給出了示意說明:

人臉識別(face identification/recognition): Face identification或Face recognition,人臉識別正如下圖所示的,它要回答的是“我是誰?”,相比於人臉校驗採用的pair matching,它在識別階段更多的是採用分類的手段。它實際上是對進行了前面兩步即人臉檢測、人臉校正後做的圖像(人臉)分類。

根據上面四個概念的介紹,我們可以瞭解到人臉識別主要包括三個大的、獨立性強的模塊:

我們將上面的步驟進行詳細的拆分,得到下面的過程圖:

人臉識別分類
現在隨着人臉識別技術的發展,人臉識別技術主要分爲了三類:一是基於圖像的識別方法、二是基於視頻的識別方法、三是三維人臉識別方法。
基於圖像的識別方法: 這個過程是一個靜態的圖像識別過程,主要利用圖像處理。主要的算法有PCA、EP、kernel method、 Bayesian Framwork、SVM 、HMM、Adaboot等等算法。但在2014年,人臉識別利用Deep learning 技術取得了重大突破,爲代表的有deepface的97.25%、face++的97.27%,但是deep face的訓練集是400w集的,而同時香港中文大學湯曉鷗的Gussian face的訓練集爲2w。
基於視頻的實時識別方法: 這個過程可以看出人臉識別的追蹤過程,不僅僅要求在視頻中找到人臉的位置和大小,還需要確定幀間不同人臉的對應關係。
DeepFace是FaceBook提出來的,後續有DeepID和FaceNet出現。而且在DeepID和FaceNet中都能體現DeepFace的身影,所以DeepFace可以謂之CNN在人臉識別的奠基之作,目前深度學習在人臉識別中也取得了非常好的效果。所以這裏我們先從DeepFace開始學習。
在DeepFace的學習過程中,不僅將DeepFace所用的方法進行介紹,也會介紹當前該步驟的其它主要算法,對現有的圖像人臉識別技術做一個簡單、全面的敘述。
1.DeepFace的基本框架
1.1 人臉識別的基本流程
face detection -> face alignment -> face verification -> face identification
1.2 人臉檢測(face detection)
1.2.1 現有技術:
haar分類器: 人臉檢測(detection)在opencv中早就有直接能拿來用的haar分類器,基於Viola-Jones算法。
Adaboost算法(級聯分類器)
1.2.2 文章中所用方法
本文中採用了基於檢測點的人臉檢測方法(fiducial Point Detector)。
先選擇6個基準點,2隻眼睛中心、 1個鼻子點、3個嘴上的點。
通過LBP特徵用SVR來學習得到基準點。
效果如下:

1.3 人臉校準(face alignment)
2D alignment:
對Detection後的圖片進行二維裁剪, scale, rotate and translate the image into six anchor locations。 將人臉部分裁剪出來。
3D alignment:
找到一個3D 模型,用這個3D模型把二維人臉crop成3D人臉。67個基點,然後Delaunay三角化,在輪廓處添加三角形來避免不連續。
將三角化後的人臉轉換成3D形狀
三角化後的人臉變爲有深度的3D三角網
將三角網做偏轉,使人臉的正面朝前
最後放正的人臉
效果如下:

上面的2D alignment對應(b)圖,3D alignment依次對應© ~ (h)。
1.4 人臉表示(face verification)
1.4.1 現有技術
LBP && joint Beyesian: 通過高維LBP跟Joint Bayesian這兩個方法結合。
論文: Bayesian Face Revisited: A Joint Formulation
DeepID系列: 將七個聯合貝葉斯模型使用SVM進行融合,精度達到99.15%
論文: Deep Learning Face Representation by Joint Identification-Verification
1.4.2 文章中的方法
論文中通過一個多類人臉識別任務來訓練深度神經網絡(DNN)。網絡結構如上圖所示。

結構參數: 經過3D對齊以後,形成的圖像都是152×152的圖像,輸入到上述網絡結構中,該結構的參數如下:
- Conv:32個11×11×3的卷積核
- max-pooling: 3×3, stride=2
- Conv: 16個9×9的卷積核
- Local-Conv: 16個9×9的卷積核,Local的意思是卷積核的參數不共享
- Local-Conv: 16個7×7的卷積核,參數不共享
- Local-Conv: 16個5×5的卷積核,參數不共享
- Fully-connected: 4096維
- Softmax: 4030維
提取低水平特徵: 過程如下所示:
- 預處理階段:輸入3通道的人臉,並進行3D校正,再歸一化到152152像素大小——152152*3.
- 通過卷積層C1:C1包含32個11113的濾波器(即卷積核),得到32張特徵圖——32142142*3。
- 通過max-polling層M2:M2的滑窗大小爲3*3,滑動步長爲2,3個通道上分別獨立polling。
- 通過另一個卷積層C3:C3包含16個9916的3維卷積核。
上述3層網絡是爲了提取到低水平的特徵,如簡單的邊緣特徵和紋理特徵。Max-polling層使得卷積網絡對局部的變換更加魯棒。如果輸入是校正後的人臉,就能使網絡對小的標記誤差更加魯棒。然而這樣的polling層會使網絡在面部的細節結構和微小紋理的精準位置上丟失一些信息。因此,文中只在第一個卷積層後面接了Max-polling層。這些前面的層稱之爲前端自適應的預處理層級。然而對於許多計算來講,這是很必要的,這些層的參數其實很少。它們僅僅是把輸入圖像擴充成一個簡單的局部特徵集。
後續層: L4,L5,L6都是局部連接層,就像卷積層使用濾波器一樣,在特徵圖像的每一個位置都訓練學習一組不同的濾波器。由於校正後不同區域的有不同的統計特性,卷積網絡在空間上的穩定性的假設不能成立。比如說,相比於鼻子和嘴巴之間的區域,眼睛和眉毛之間的區域展現出非常不同的表觀並且有很高的區分度。換句話說,通過利用輸入的校正後的圖像,定製了DNN的結構。
使用局部連接層並沒有影響特徵提取時的運算負擔,但是影響了訓練的參數數量。僅僅是由於有如此大的標記人臉庫,我們可以承受三個大型的局部連接層。局部連接層的輸出單元受到一個大型的輸入圖塊的影響,可以據此調整局部連接層的使用(參數)(不共享權重)
比如說,L6層的輸出受到一個74743的輸入圖塊的影響,在校正後的人臉中,這種大的圖塊之間很難有任何統計上的參數共享。
頂層: 最後,網絡頂端的兩層(F7,F8)是全連接的:每一個輸出單元都連接到所有的輸入。這兩層可以捕捉到人臉圖像中距離較遠的區域的特徵之間的關聯性。比如,眼睛的位置和形狀,與嘴巴的位置和形狀之間的關聯性(這部分也含有信息)可以由這兩層得到。第一個全連接層F7的輸出就是我們原始的人臉特徵表達向量。
在特徵表達方面,這個特徵向量與傳統的基於LBP的特徵描述有很大區別。傳統方法通常使用局部的特徵描述(計算直方圖)並用作分類器的輸入。
最後一個全連接層F8的輸出進入了一個K-way的softmax(K是類別個數),即可產生類別標號的概率分佈。用Ok表示一個輸入圖像經過網絡後的第k個輸出,即可用下式表達輸出類標號k的概率:

訓練的目標是最大化正確輸出類別(face 的id)的概率。通過最小化每個訓練樣本的叉熵損失實現這一點。用k表示給定輸入的正確類別的標號,則叉熵損失是:

通過計算叉熵損失L對參數的梯度以及使用隨機梯度遞減的方法來最小化叉熵損失。
梯度是通過誤差的標準反向傳播來計算的。非常有趣的是,本網絡產生的特徵非常稀疏。超過75%的頂層特徵元素是0。這主要是由於使用了ReLU激活函數導致的。這種軟閾值非線性函數在所有的卷積層,局部連接層和全連接層(除了最後一層F8)都使用了,從而導致整體級聯之後產生高度非線性和稀疏的特徵。稀疏性也與使用使用dropout正則化有關,即在訓練中將隨機的特徵元素設置爲0。我們只在F7全連接層使用了dropout.由於訓練集合很大,在訓練過程中我們沒有發現重大的過擬合。
給出圖像I,則其特徵表達G(I)通過前饋網絡計算出來,每一個L層的前饋網絡,可以看作是一系列函數:

歸一化: 在最後一級,我們把特徵的元素歸一化成0到1,以此降低特徵對光照變化的敏感度。特徵向量中的每一個元素都被訓練集中對應的最大值除。然後進行L2歸一化。由於我們採用了ReLU激活函數,我們的系統對圖像的尺度不變性減弱。
對於輸出的4096-d向量:
- 先每一維進行歸一化,即對於結果向量中的每一維,都要除以該維度在整個訓練集上的最大值。
- 每個向量進行L2歸一化。
2. 驗證
2.1 卡方距離
該系統中,歸一化後的DeepFace特徵向量與傳統的基於直方圖的特徵(如LBP)有一下相同之處:
- 所有值均爲負
- 非常稀疏
- 特徵元素的值都在區間 [0, 1]之間
卡方距離計算公式如下:

2.2 Siamese network
文章中也提到了端到端的度量學習方法,一旦學習(訓練)完成,人臉識別網絡(截止到F7)在輸入的兩張圖片上重複使用,將得到的2個特徵向量直接用來預測判斷這兩個輸入圖片是否屬於同一個人。這分爲以下步驟: a. 計算兩個特徵之間的絕對差別; b,一個全連接層,映射到一個單個的邏輯單元(輸出相同/不同)。
3. 實驗評估
3.1 數據集
- Social Face Classification Dataset(SFC): 4.4M張人臉/4030人
- LFW: 13323張人臉/5749人
- restricted: 只有是/不是的標記
- unrestricted:其他的訓練對也可以拿到
- unsupervised:不在LFW上訓練
- Youtube Face(YTF): 3425videos/1595人
result on LFW:

result on YTF:

DeepFace與之後的方法的最大的不同點在於,DeepFace在訓練神經網絡前,使用了對齊方法。論文認爲神經網絡能夠work的原因在於一旦人臉經過對齊後,人臉區域的特徵就固定在某些像素上了,此時,可以用卷積神經網絡來學習特徵。
本文的模型使用了C++工具箱dlib基於深度學習的最新人臉識別方法,基於戶外臉部數據測試庫Labeled Faces in the Wild 的基準水平來說,達到了99.38%的準確率。
模型提供了一個簡單的 face_recognition 命令行工具讓用戶通過命令就能直接使用圖片文件夾進行人臉識別操作。
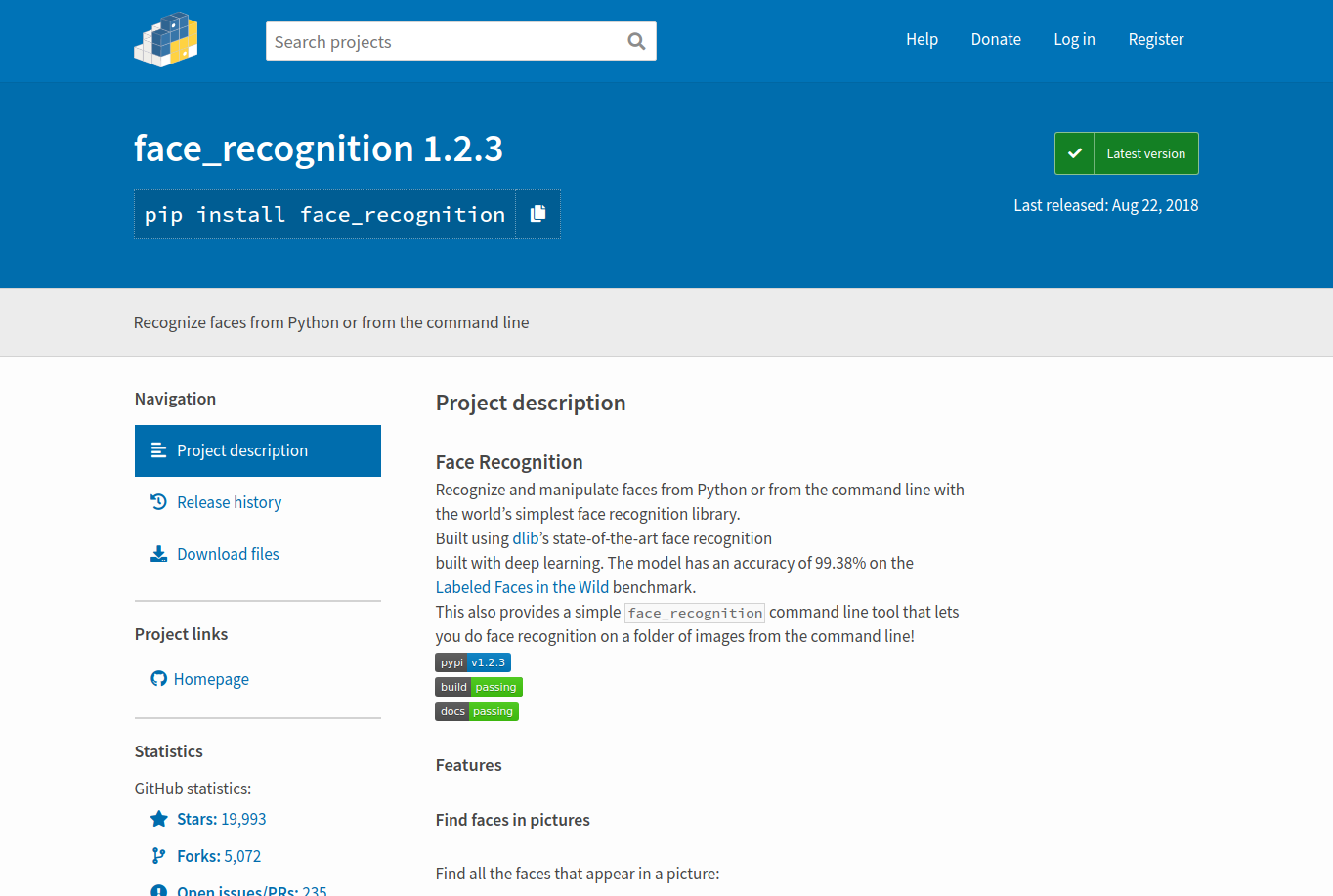
在圖片中捕捉人臉特徵
在一張圖片中捕捉到所有的人臉

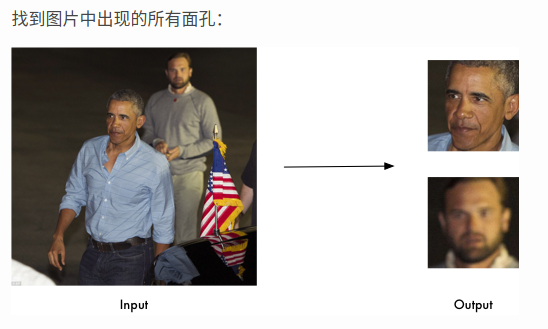
找到並處理圖片中人臉的特徵
找到每個人眼睛、鼻子、嘴巴和下巴的位置和輪廓。
import face_recognition
image = face_recognition.load_image_file(“your_file.jpg”)
face_locations = face_recognition.face_locations(image)

捕捉臉部特徵有很重要的用途,當然也可以用來進行圖片的數字美顏digital make-up
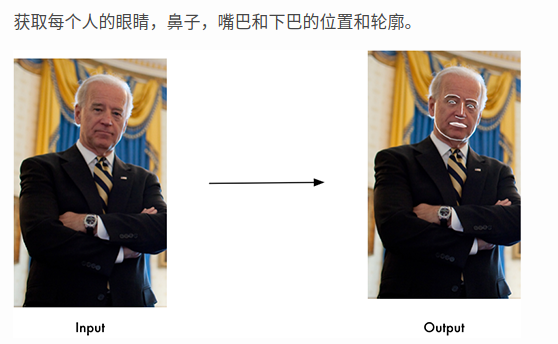
識別圖片中的人臉
識別誰出現在照片裏


安裝步驟
本方法支持Python3/python2,我們只在macOS和Linux中測試過,還不知是否適用於Windows。
使用pypi的pip3 安裝此模塊(或是Python 2的pip2)
重要提示:在編譯dlib時可能會出問題,你可以通過安裝來自源(而不是pip)的dlib來修復錯誤,請見安裝手冊How to install dlib from source
https://gist.github.com/ageitgey/629d75c1baac34dfa5ca2a1928a7aeaf
通過手動安裝dlib,運行pip3 install face_recognition來完成安裝。
使用方法命令行界面
當你安裝face_recognition,你能得到一個簡潔的叫做face_recognition的命令行程序,它能幫你識別一張照片或是一個照片文件夾中的所有人臉。
首先,你需要提供一個包含一張照片的文件夾,並且你已經知道照片中的人是誰,每個人都要有一張照片文件,且文件名需要以該人的姓名命名;

然後你需要準備另外一個文件夾,裏面裝有你想要識別人臉照片;

接下來你只用運行face_recognition命令,程序能夠通過已知人臉的文件夾識別出未知人臉照片中的人是誰;

針對每個人臉都要一行輸出,數據是文件名加上識別到的人名,以逗號分隔。
如果你只是想要知道每個照片中的人名而不要文件名,可以進行如下操作:
