




Datawhale 零基礎入門CV賽事-Task3 字符識別模型
在前面的章節,我們講解了賽題的背景知識和賽題數據的讀取。本章開始構建一個字符識別模型,基於對賽題理解本章將構建一個定長多字符分類模型。
3 字符識別模型
本章將會講解卷積神經網絡(Convolutional Neural Network, CNN)的常見層,並從頭搭建一個字符識別模型。
3.1 學習目標
- 學習CNN基礎和原理
- 使用Pytorch框架構建CNN模型,並完成訓練
3.2 CNN介紹
卷積神經網絡(簡稱CNN)是一類特殊的人工神經網絡,是深度學習中重要的一個分支。CNN在很多領域都表現優異,精度和速度比傳統計算學習算法高很多。特別是在計算機視覺領域,CNN是解決圖像分類、圖像檢索、物體檢測和語義分割的主流模型。
CNN每一層由衆多的卷積核組成,每個卷積覈對輸入的像素進行卷積操作,得到下一次的輸入。隨着網絡層的增加捲積核會逐漸擴大感受野,並縮減圖像的尺寸。

CNN是一種層次模型,輸入的是原始的像素數據。CNN通過卷積(convolution)、池化(pooling)、非線性激活函數(non-linear activation function)和全連接層(fully connected layer)構成。
如下圖所示爲LeNet網絡結構,是非常經典的字符識別模型。兩個卷積層,兩個池化層,兩個全連接層組成。卷積核都是5×5,stride=1,池化層使用最大池化。

通過多次卷積和池化,CNN的最後一層將輸入的圖像像素映射爲具體的輸出。如在分類任務中會轉換爲不同類別的概率輸出,然後計算真實標籤與CNN模型的預測結果的差異,並通過反向傳播更新每層的參數,並在更新完成後再次前向傳播,如此反覆直到訓練完成 。
與傳統機器學習模型相比,CNN具有一種端到端(End to End)的思路。在CNN訓練的過程中是直接從圖像像素到最終的輸出,並不涉及到具體的特徵提取和構建模型的過程,也不需要人工的參與。
3.3 CNN發展
隨着網絡結構的發展,研究人員最初發現網絡模型結構越深、網絡參數越多模型的精度更優。比較典型的是AlexNet、VGG、InceptionV3和ResNet的發展脈絡。






3.4 Pytorch構建CNN模型
在上一章節我們講解了如何使用Pytorch來讀取賽題數據集,本節我們使用本章學習到的知識構件一個簡單的CNN模型,完成字符識別功能。
在Pytorch中構建CNN模型非常簡單,只需要定義好模型的參數和正向傳播即可,Pytorch會根據正向傳播自動計算反向傳播。
在本章我們會構建一個非常簡單的CNN,然後進行訓練。這個CNN模型包括兩個卷積層,最後並聯6個全連接層進行分類。
import torch
torch.manual_seed(0)
torch.backends.cudnn.deterministic = False
torch.backends.cudnn.benchmark = True
import torchvision.models as models
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable
from torch.utils.data.dataset import Dataset
# 定義模型
class SVHN_Model1(nn.Module):
def __init__(self):
super(SVHN_Model1, self).__init__()
# CNN提取特徵模塊
self.cnn = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=(3, 3), stride=(2, 2)),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(16, 32, kernel_size=(3, 3), stride=(2, 2)),
nn.ReLU(),
nn.MaxPool2d(2),
)
#
self.fc1 = nn.Linear(32*3*7, 11)
self.fc2 = nn.Linear(32*3*7, 11)
self.fc3 = nn.Linear(32*3*7, 11)
self.fc4 = nn.Linear(32*3*7, 11)
self.fc5 = nn.Linear(32*3*7, 11)
self.fc6 = nn.Linear(32*3*7, 11)
def forward(self, img):
feat = self.cnn(img)
feat = feat.view(feat.shape[0], -1)
c1 = self.fc1(feat)
c2 = self.fc2(feat)
c3 = self.fc3(feat)
c4 = self.fc4(feat)
c5 = self.fc5(feat)
c6 = self.fc6(feat)
return c1, c2, c3, c4, c5, c6
model = SVHN_Model1()
接下來是訓練代碼:
# 損失函數
criterion = nn.CrossEntropyLoss()
# 優化器
optimizer = torch.optim.Adam(model.parameters(), 0.005)
loss_plot, c0_plot = [], []
# 迭代10個Epoch
for epoch in range(10):
for data in train_loader:
c0, c1, c2, c3, c4, c5 = model(data[0])
loss = criterion(c0, data[1][:, 0]) + \
criterion(c1, data[1][:, 1]) + \
criterion(c2, data[1][:, 2]) + \
criterion(c3, data[1][:, 3]) + \
criterion(c4, data[1][:, 4]) + \
criterion(c5, data[1][:, 5])
loss /= 6
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_plot.append(loss.item())
c0_plot.append((c0.argmax(1) == data[1][:, 0]).sum().item()*1.0 / c0.shape[0])
print(epoch)
在訓練完成後我們可以將訓練過程中的損失和準確率進行繪製,如下圖所示。從圖中可以看出模型的損失在迭代過程中逐漸減小,字符預測的準確率逐漸升高。

當然爲了追求精度,也可以使用在ImageNet數據集上的預訓練模型,具體方法如下:
class SVHN_Model2(nn.Module):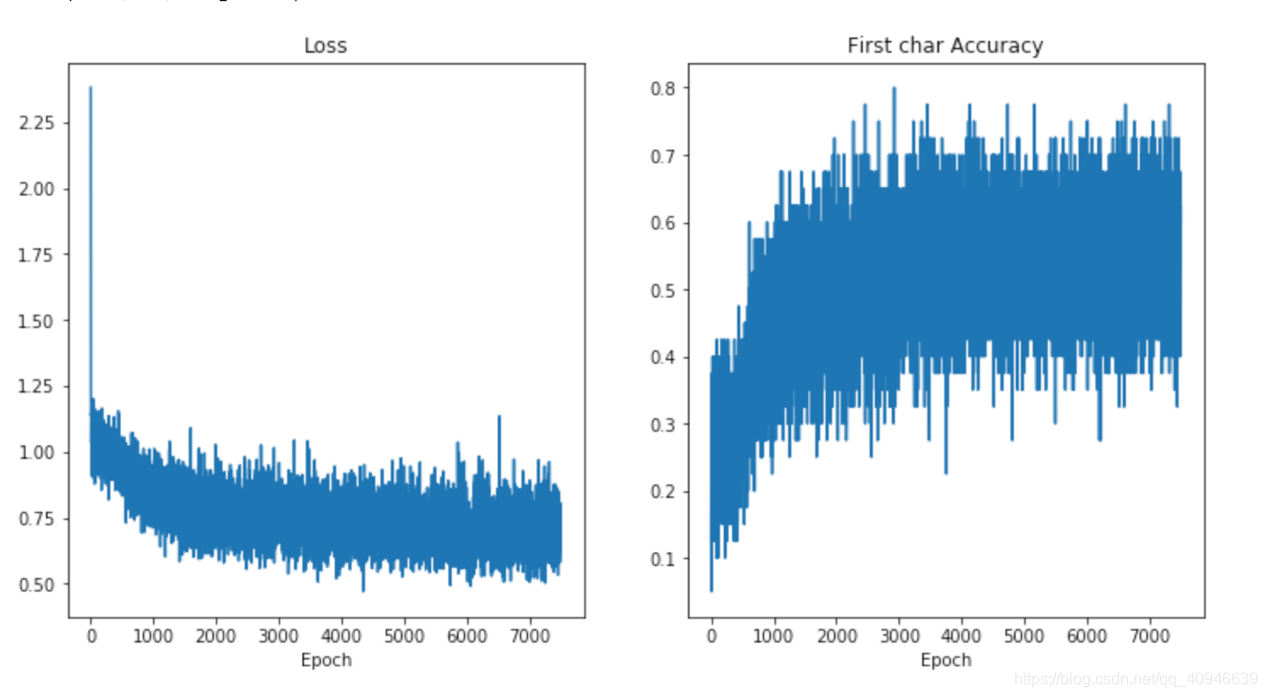
def __init__(self):
super(SVHN_Model1, self).__init__()
model_conv = models.resnet18(pretrained=True)
model_conv.avgpool = nn.AdaptiveAvgPool2d(1)
model_conv = nn.Sequential(*list(model_conv.children())[:-1])
self.cnn = model_conv
self.fc1 = nn.Linear(512, 11)
self.fc2 = nn.Linear(512, 11)
self.fc3 = nn.Linear(512, 11)
self.fc4 = nn.Linear(512, 11)
self.fc5 = nn.Linear(512, 11)
def forward(self, img):
feat = self.cnn(img)
# print(feat.shape)
feat = feat.view(feat.shape[0], -1)
c1 = self.fc1(feat)
c2 = self.fc2(feat)
c3 = self.fc3(feat)
c4 = self.fc4(feat)
c5 = self.fc5(feat)
return c1, c2, c3, c4, c5
3.5 本章小節
在本章中我們介紹了CNN以及CNN的發展,並使用Pytorch構建構建了一個簡易的CNN模型來完成字符分類任務。