




在我之前的文章 “Elastic可觀測性 - 數據結構化及處理”,講述瞭如果把一個非結構化的數據變爲一個結構化的數據結構。其中Grok processor 是非常重要的一個。在今天的文章中,我們來更加深入地對它進行描述。今天的這個 Grok 的實踐也適用於 Logstash 的 Grok filer。關於 Logstash Grok 的教程,你可以參閱文章 “Logstash:Grok filter 入門”。
我們先來看一下如下的一個日誌:
157.97.192.70 2019 09 29 00:39:02.912 myserver Process 107673 Initializing
在上面的日誌中,我們可以看到一個日期信息:2019 09 29 00:39:02.912。它是被空格字符串所分開,如果沒有正確的 Grok pattern 來幫我們提取的話,我們將會很難提取到一個完整的日期。我們的日誌信息符合如下的一個數據結構:
ip timestamp server Process process_id action
首先,我們打開 Kibana:

我們可以先提取 IP:
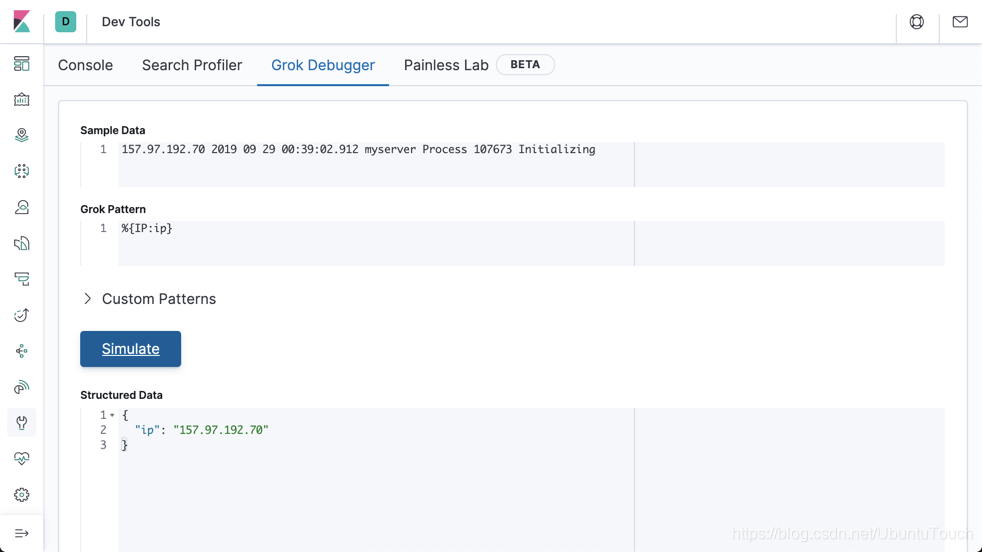
之後的,就是年,月,日,及時間。我們可以通過如下的方式來進行提取:
- 運用 YEAY 來提取年份
- 運用 MONTHNUM 來提取月份
- 運用 MONTHDAY 來提取日期
- 運用 TIME 來提取時間
- 運用 WORD 來提取一個單詞
- 運用 NUMBER 來提取一個數值
- 對於 Process 來說,我們就不提取了,忽略它
這樣,我們可以使用如下的 Grok pattern:
%{IP:ip} %{YEAR:year} %{MONTHNUM:month} %{MONTHDAY:day} %{TIME:time} %{WORD:server} Process %{NUMBER:process_id} %{WORD:action}

顯然,它正確地解析了我們的日誌,但是美中不足的是我們最終需要的是一個真正的日期,而不是用 year, month, day, time 來表示的一個時間。我們可以點擊上面的 custerm pattern,並輸入一下的句子:
EVENTDATE %{YEAR} %{MONTHNUM} %{MONTHDAY} %{TIME}

在上面,我們定義了 EVENDATE 爲 YEAR, MONTHNUM, MONTHDAY 及 TIME 的組合。那麼我們該如和應用上面的 custom patttern呢?
我們必須修改上面的 Grok pattern 爲:
%{IP:ip} %{EVENTDATE:@timestamp} %{WORD:server} Process %{NUMBER:process_id} %{WORD:action}

從上面,我們可以看出來,我們的 EVENTDATE 起作用了。它正確地解析了我們的時間。
那麼在我們實際的使用中,我們該如何地應用呢?
我們可以創建如下的一個命令:
POST /_ingest/pipeline/_simulate
{
"pipeline": {
"processors": [
{
"grok": {
"field": "message",
"patterns": [
"%{IP:ip} %{EVENTDATE:@timestamp} %{WORD:server} Process %{NUMBER:process_id} %{WORD:action}"
],
"pattern_definitions": {
"EVENTDATE": "%{YEAR} %{MONTHNUM} %{MONTHDAY} %{TIME}"
}
}
}
]
},
"docs": [
{
"_source": {
"message": "157.97.192.70 2019 09 29 00:39:02.912 myserver Process 107673 Initializing"
}
}
]
}
運行上面的命令:
{
"docs" : [
{
"doc" : {
"_index" : "_index",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"server" : "myserver",
"process_id" : "107673",
"@timestamp" : "2019 09 29 00:39:02.912",
"ip" : "157.97.192.70",
"action" : "Initializing",
"message" : "157.97.192.70 2019 09 29 00:39:02.912 myserver Process 107673 Initializing"
},
"_ingest" : {
"timestamp" : "2020-06-15T08:33:01.28191Z"
}
}
}
]
}
上面顯示我們的日誌被正確地解析並結構化。
另外一種方法是通過 set processor 來把上面的日期相關的字段來組成我們需要的 @timestamp 字段。
POST /_ingest/pipeline/_simulate
{
"pipeline": {
"processors": [
{
"grok": {
"field": "message",
"patterns": [
"%{IP:ip} %{YEAR} %{MONTHNUM} %{MONTHDAY} %{TIME} %{WORD:server} Process %{NUMBER:process_id} %{WORD:action}"
]
}
},
{
"set": {
"field": "@timestamp",
"value": "{{year}} {{month}} {{day}} {{time}}"
}
}
]
},
"docs": [
{
"_source": {
"message": "157.97.192.70 2019 09 29 00:39:02.912 myserver Process 107673 Initializing"
}
}
]
}
在上面,我們通過:
{
"set": {
"field": "@timestamp",
"value": "{{year}} {{month}} {{day}} {{time}}"
}
}
來把 @timestamp 進行定義,它組合了 year, month, day 及 time 的值。