




一、標籤計算
數據
86913510 {"reviewPics":[],"extInfoList":null,"expenseList":null,"reviewIndexes":[1,2],"scoreList":[{"score":5,"title":"環境","desc":""},{"score":5,"title":"服務","desc":""},{"score":5,"title":"口味","desc":""}]}
86913510 {"reviewPics":null,"extInfoList":[{"title":"contentTags","values":["午餐","分量適中"],"desc":"","defineType":0},{"title":"tagIds","values":["684","240"],"desc":"","defineType":0}],"expenseList":null,"reviewIndexes":[2],"scoreList":null}
77287793 {"reviewPics":null,"extInfoList":null,"expenseList":null,"reviewIndexes":[1,2],"scoreList":null}
77287793 {"reviewPics":null,"extInfoList":[{"title":"contentTags","values":["乾淨衛生","服務熱情"],"desc":"","defineType":0},{"title":"tagIds","values":["852","22"],"desc":"","defineType":0}],"expenseList":null,"reviewIndexes":[1,2],"scoreList":null}
處理過程分析
(1) 第一步:篩選出extInfoList不爲空的記錄,並去除values中的標籤值
獲取到的記錄形式
86913510 午餐,分量適中
77287793 乾淨衛生,服務熱情
(2) 第二步:分離標籤
獲取到的記錄形式
86913510 午餐,1
86913510 午餐,1
86913510 分量適中,1
77287793 乾淨衛生,1
77287793 服務熱情,1
(3) 第三步:統計標籤
獲取到的記錄形式
JSON解析代碼
public class JsonParse {
public static String parseTag(String json) {
JSONObject jsonObject = JSONObject.parseObject(json);
JSONArray extInfoList = jsonObject.getJSONArray("extInfoList");
if (extInfoList == null) {
return "";
}
for (Object obj : extInfoList) {
JSONObject jsonObject1 = (JSONObject) obj;
if (jsonObject1.getString("title").equals("contentTags")) {
String array2 = jsonObject1.getString("values");
return array2.replace("[", "").replace("]", "").replace("\"", "");
}
}
return "";
}
}
Spark統計代碼
object TagCompute {
def main(args: Array[String]): Unit = {
// 創建Spark配置對象
val conf = new SparkConf().setMaster("local[4]").setAppName("MyApp")
// 通過conf創建sc
val sc = new SparkContext(conf)
// 讀取文件
val rdd1 = sc.textFile("/Users/opensource/dev-problem/source/temptags.txt");
// 計算
val rdd2 = rdd1.map(line => line.split("\t"))
.map(e => e(0) -> JsonParse.parseTag(e(1)))
// (77287793,環境優雅,性價比高,乾淨衛生,停車方便,音響效果好)
.filter(e => e._2.length > 0)
// (70611801,["環境優雅","性價比高"])
.map(e => e._1 -> e._2.split(",")(0))
// (77287793,環境優雅,性價比高,乾淨衛生,停車方便,音響效果好)
.flatMapValues(e => e)
// ((70611801,價格實惠),1)
.map(e => (e._1, e._2) -> 1)
// ((78824187,乾淨衛生),7)
.reduceByKey(_ + _)
// (73963176,List((環境優雅,6)))
.map(e => e._1._1 -> List((e._1._2, e._2)))
// (83084036,List((乾淨衛生,1), (價格實惠,1)))
.reduceByKey(_ ::: _)
// (79197522,List(服務熱情:2, 乾淨衛生:1, 技師專業:1, 體驗舒服:1, 放鬆舒服:1, 價格實惠:1))
.map(e => e._1 -> e._2.sortBy(_._2).reverse.take(10).map(a => a._1 + ":" + a._2.toString));
/*
* 85648235 List(味道贊:17, 服務熱情:15, 乾淨衛生:13, 上菜快:12, 回頭客:11,
* 性價比高:10, 體驗好:9, 價格實惠:8, 環境優雅:8, 分量足:7)
*/
rdd2.map(e => e._1 + "\t" + e._2).foreach(println);
}
}
二、用戶畫像
用戶畫像介紹
根據用戶的信息和行爲動作,用標籤將用戶的特徵描繪出來,用於描繪的標籤就是用戶畫像。這些標籤都是根據一些行爲來推算出來。構建用戶畫像的核心工作,主要是利用存儲在服務器上的海量日誌和數據庫裏的大量數據進行分析和挖掘,給用戶貼“標籤”,而“標籤”是能表示用戶某一維度特徵的標識。
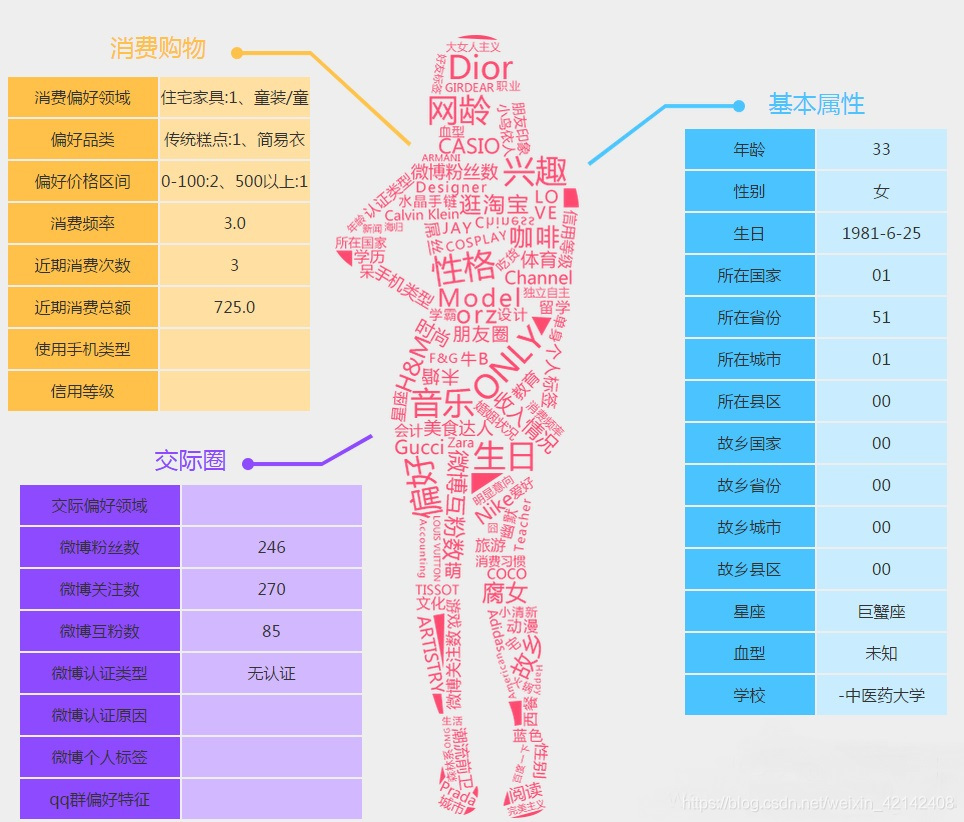
用戶畫像作用
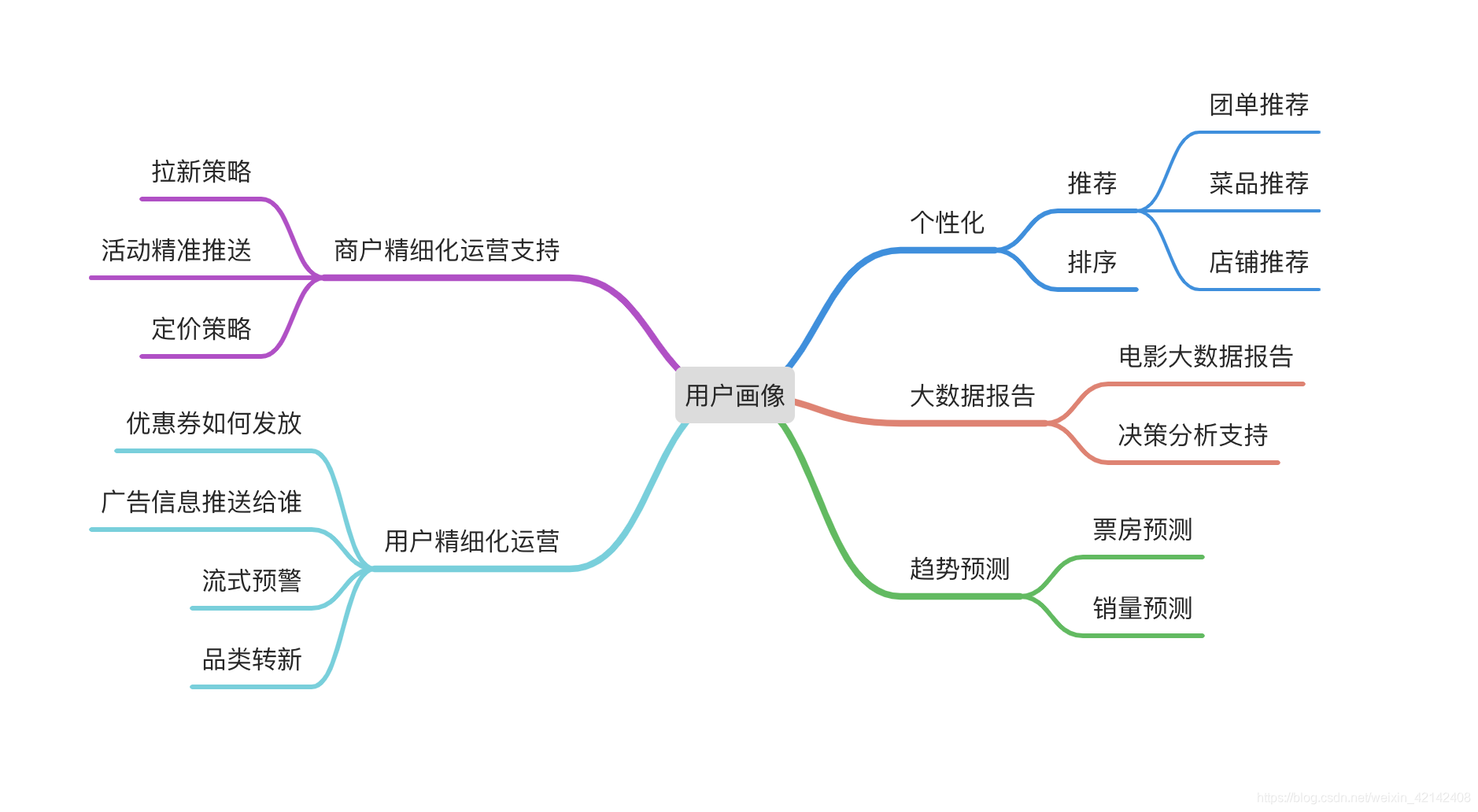
挑戰
- 記錄和存儲億級用戶的畫像
- 支持和擴展不斷增加的維度和偏好
- 毫秒級更新
- 支撐個性化推薦、廣告投放、精細化營銷的產品
用戶畫像處理流程
- 明確問題、需求、數據預處理
- 數據清洗、缺失值處理、噪聲數據
特徵工程
數據和特徵決定了機器學習的上限,而模型和算法只是逼近這個上限。
特徵:對解決問題有幫助的屬性。
特徵的提取、選擇與構造:
- 特徵提取
- 業務日誌
- WEB公開數據抓取
- 第三方合作
- 針對所解決的問題選擇最有用的特徵集合
- 通過相關係數計算特徵的重要性
- 人工篩選
- 算法篩選:Random Forest
- 維度過多,PCA自動降維
模型與算法
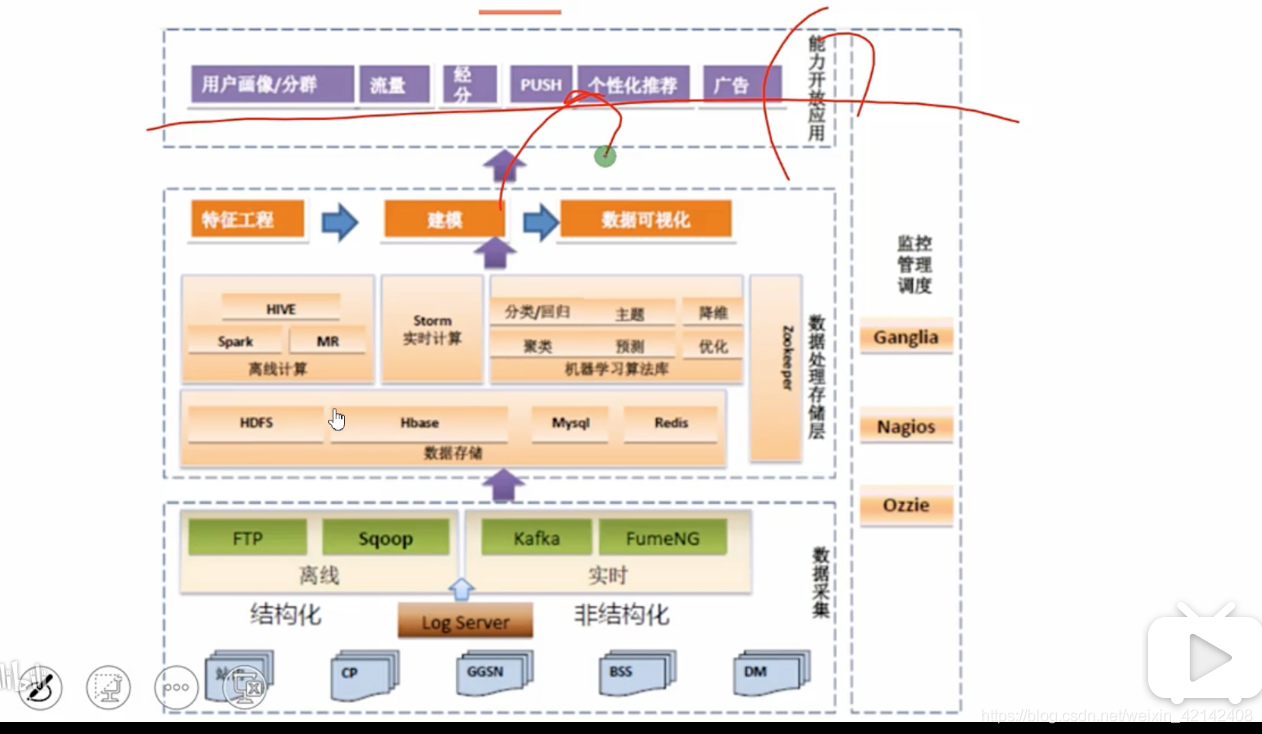
用戶畫像系統架構
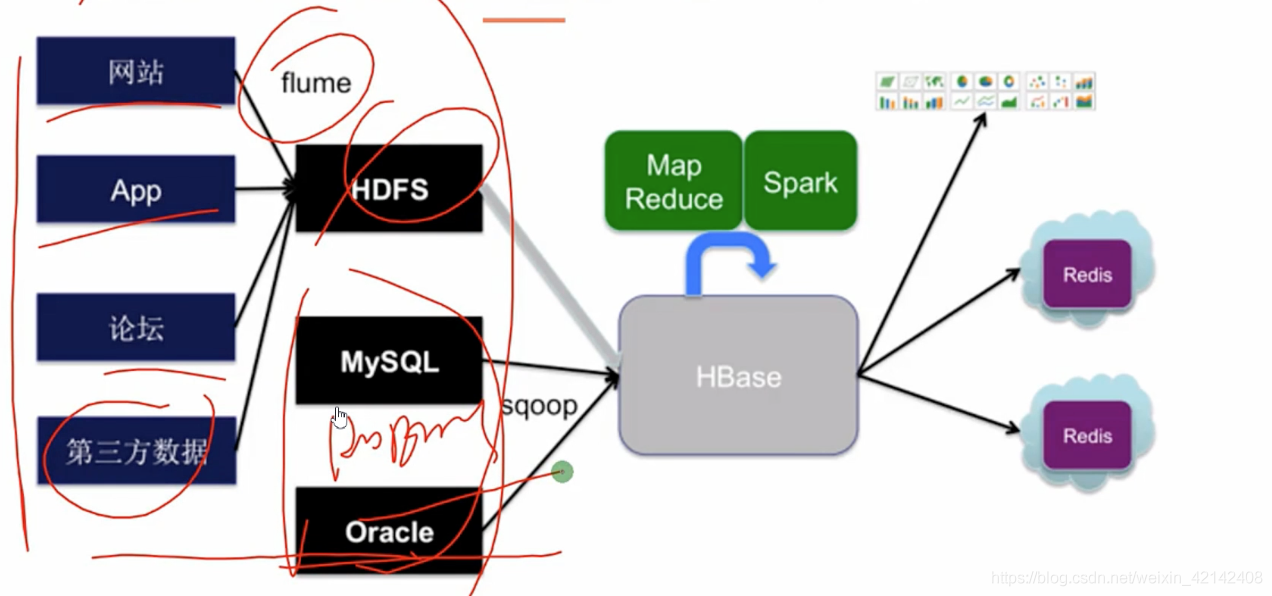
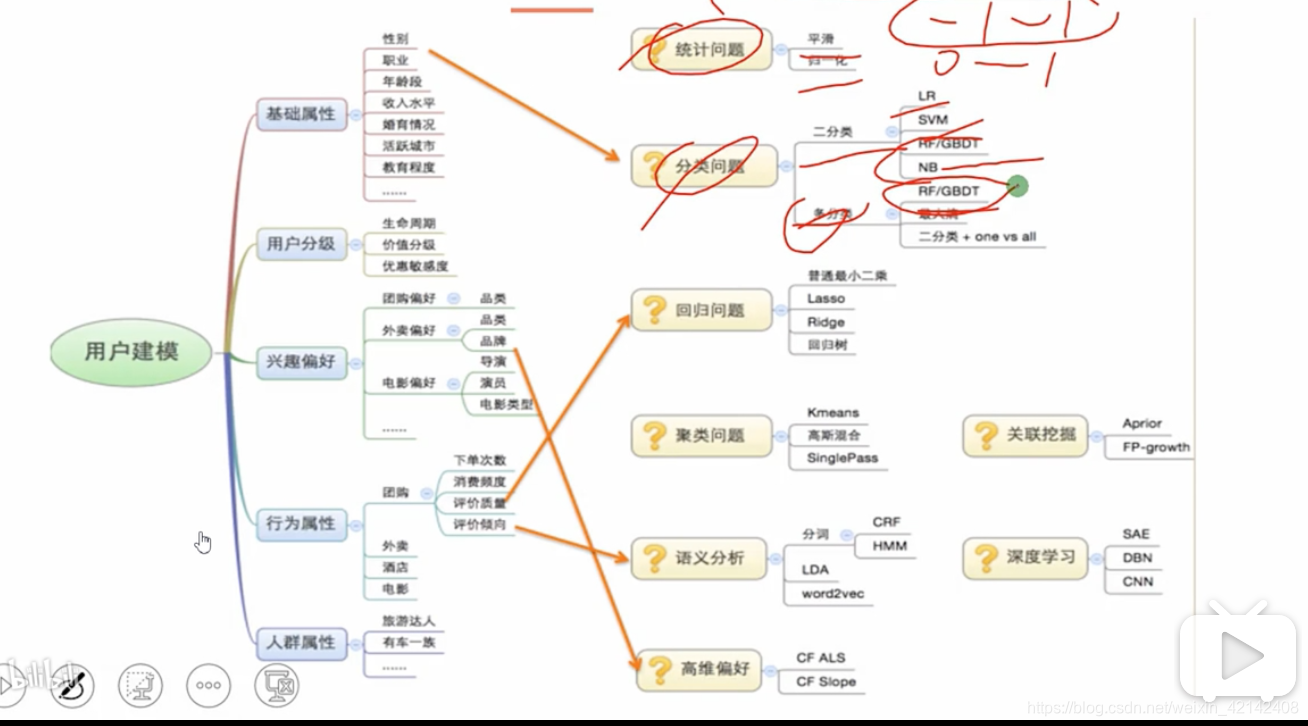
用戶畫像實現
(1) 實例一:性別判斷
性別判斷屬於數據挖掘中分類問題。
(2) 需求描述
根據用戶數據判斷用戶性別。
(3) 已知數據
- 數據1:用戶使用App的行爲數據
- 數據2:用戶瀏覽網頁的行爲數據
(4) 實現代碼
object UserPicture {
def main(args: Array[String]): Unit = {
// 創建Spark配置對象
val conf = new SparkConf().setMaster("local[4]").setAppName("MyApp");
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.config(conf)
.getOrCreate();
// 創建訓練集
val training = spark.createDataFrame(Seq(
(1.0,Vectors.dense(2.0,1.1,0.1)),
(1.0,Vectors.dense(2.0,1.1,0.1)),
(1.0,Vectors.dense(2.0,1.1,0.1)),
(1.0,Vectors.dense(2.0,1.1,0.1))
)).toDF("label","features");
val lr = new LogisticRegression();
println(lr.explainParams())
// Set the maximum number of iterations.
lr.setMaxIter(10)
//Set the regularization parameter.
.setRegParam(0.01)
// Fits a model to the input data.
val model1 = lr.fit(training)
var paramMap = ParamMap(lr.maxIter -> 20).put(lr.maxIter,30)
.put(lr.regParam -> 0.1,lr.threshold -> 0.55)
// The parent estimator that produced this model.
// extractParamMap with no extra values.
println(model1.parent.extractParamMap())
}
}
參考文檔
Spark大數據互聯網項目實戰推薦系統
騰訊防刷負責人:基於用戶畫像大數據的電商防刷架構
讓機器讀懂用戶--大數據中的用戶畫像
大數據開發用戶畫像案例分析
大數據工程師 dmp用戶畫像系統開發項目(完)
Spark大數據互聯網項目實戰推薦系統(全套)