




ZooKeeper是一個分佈式應用程序協調服務,分佈式應用程序可以基於它實現統一命名服務、狀態同步服務、集羣管理、分佈式應用配置項的管理等。在分佈式應用中,由於不能很好地使用鎖機制,因此需要有一種可靠的、可擴展的、分佈式的、可配置的協調機制來統一系統的狀態。Zookeeper的目的就在於此。
簡單的說,zookeeper=文件系統+通知機制。
1 Zookeeper的基本概念
1.1 角色
Zookeeper中的角色主要有以下三類,如下表所示:

系統模型如圖所示:

1.2 設計目的
1.最終一致性:client不論連接到哪個Server,展示給它都是同一個視圖,這是zookeeper最重要的性能。
2 .可靠性:如果消息m被到一臺服務器接受,那麼它將被所有的服務器接受。
3 .實時性:Zookeeper保證客戶端將在一個時間間隔範圍內獲得服務器的更新信息,或者服務器失效的信息。
4 .等待無關(wait-free):慢的或者失效的client不得干預快速的client的請求,使得每個client都能有效的等待。
5.原子性:更新只能成功或者失敗,沒有中間狀態。
6 .順序性:包括全局有序和偏序兩種:全局有序是指如果在一臺服務器上消息a在消息b前發佈,則在所有Server上消息a都將在消息b前被髮布;偏序是指如果一個消息b在消息a後被同一個發送者發佈,a必將排在b前面。
1.3 文件系統
Zookeeper維護一個類似文件系統的數據結構:

每個子目錄項如 NameService 都被稱作爲 znode,和文件系統一樣,我們能夠自由的增加、刪除znode,在一個znode下增加、刪除子znode,唯一的不同在於znode是可以存儲數據的。
有四種類型的znode:
1、PERSISTENT-持久化目錄節點:客戶端與zookeeper斷開連接後,該節點依舊存在
2、 PERSISTENT_SEQUENTIAL-持久化順序編號目錄節點
3、EPHEMERAL-臨時目錄節點:客戶端與zookeeper斷開連接後,該節點被刪除
4、EPHEMERAL_SEQUENTIAL-臨時順序編號目錄節點
1.4 Zookeeper能做什麼?
1、 命名服務
這個似乎最簡單,在zookeeper的文件系統裏創建一個目錄,即有唯一的path。在我們使用tborg無法確定上游程序的部署機器時即可與下游程序約定好path,通過path即能互相探索發現,不見不散了。
2、 配置管理
程序總是需要配置的,如果程序分散部署在多臺機器上,要逐個改變配置就變得困難。好吧,現在把這些配置全部放到zookeeper上去,保存在 Zookeeper 的某個目錄節點中,然後所有相關應用程序對這個目錄節點進行監聽,一旦配置信息發生變化,每個應用程序就會收到 Zookeeper 的通知,然後從 Zookeeper 獲取新的配置信息應用到系統中就好。
所謂集羣管理無在乎兩點:是否有機器退出和加入、選舉master。
對於第一點,所有機器約定在父目錄GroupMembers下創建臨時目錄節點,然後監聽父目錄節點的子節點變化消息。一旦有機器掛掉,該機器與 zookeeper的連接斷開,其所創建的臨時目錄節點被刪除,所有其他機器都收到通知:某個兄弟目錄被刪除,於是,所有人都知道:它上船了。新機器加入 也是類似,所有機器收到通知:新兄弟目錄加入,highcount又有了。
對於第二點,我們稍微改變一下,所有機器創建臨時順序編號目錄節點,每次選取編號最小的機器作爲master就好。

4、 分佈式鎖
有了zookeeper的一致性文件系統,鎖的問題變得容易。鎖服務可以分爲兩類,一個是保持獨佔,另一個是控制時序。
對於第一類,我們將zookeeper上的一個znode看作是一把鎖,通過createznode的方式來實現。所有客戶端都去創建 /distribute_lock 節點,最終成功創建的那個客戶端也即擁有了這把鎖。廁所有言:來也沖沖,去也沖沖,用完刪除掉自己創建的distribute_lock 節點就釋放出鎖。
對於第二類, /distribute_lock 已經預先存在,所有客戶端在它下面創建臨時順序編號目錄節點,和選master一樣,編號最小的獲得鎖,用完刪除,依次方便。
具體步驟
1、創建一個永久性節點,作鎖的根目錄
2、當要獲取一個鎖時,在鎖目錄下創建一個臨時有序列的節點
3、檢查鎖目錄的子節點是否有序列比它小,若有則監聽比它小的上一個節點,當前鎖處於等待狀態
4、當等待時間超過Zookeeper session的連接時間(sessionTimeout)時,當前session過期,Zookeeper自動刪除此session創建的臨時節點,等待狀態結束,獲取鎖失敗
5、當監聽器觸發時,等待狀態結束,獲得鎖


1.5 Zookeeper的數據複製
從客戶端讀寫訪問的透明度來看,數據複製集羣系統分下面兩種:
1、寫主(WriteMaster)
對數據的修改提交給指定的節點。讀無此限制,可以讀取任何一個節點。這種情況下客戶端需要對讀與寫進行區別,俗稱讀寫分離;
2、寫任意(Write Any)
對數據的修改可提交給任意的節點,跟讀一樣。這種情況下,客戶端對集羣節點的角色與變化透明。
對zookeeper來說,它採用的方式是寫任意。通過增加機器,它的讀吞吐能力和響應能力擴展性非常好,而寫,隨着機器的增多吞吐能力肯定下降(這 也是它建立observer的原因),而響應能力則取決於具體實現方式,是延遲複製保持最終一致性,還是立即複製快速響應。
我們關注的重點還是在如何保證數據在集羣所有機器的一致性,這就涉及到paxos算法。
1.6 Zookeeper的paxos算法
數據一致性與paxos算法
據說Paxos算法的難理解與算法的知名度一樣令人敬仰,所以我們先看如何保持數據的一致性,這裏有個原則就是:
在一個分佈式數據庫系統中,如果各節點的初始狀態一致,每個節點都執行相同的操作序列,那麼他們最後能得到一個一致的狀態。
Paxos算法解決的什麼問題呢,解決的就是保證每個節點執行相同的操作序列。好吧,這還不簡單,master維護一個全局寫隊列,所有寫操作都必須 放入這個隊列編號,那麼無論我們寫多少個節點,只要寫操作是按編號來的,就能保證一致性。沒錯,就是這樣,可是如果master掛了呢。
Paxos算法通過投票來對寫操作進行全局編號,同一時刻,只有一個寫操作被批准,同時併發的寫操作要去爭取選票,只有獲得過半數選票的寫操作纔會被 批准(所以永遠只會有一個寫操作得到批准),其他的寫操作競爭失敗只好再發起一輪投票,就這樣,在日復一日年復一年的投票中,所有寫操作都被嚴格編號排 序。編號嚴格遞增,當一個節點接受了一個編號爲100的寫操作,之後又接受到編號爲99的寫操作(因爲網絡延遲等很多不可預見原因),它馬上能意識到自己 數據不一致了,自動停止對外服務並重啓同步過程。任何一個節點掛掉都不會影響整個集羣的數據一致性(總2n+1臺,除非掛掉大於n臺)。
2 ZooKeeper的工作原理
Zookeeper的核心是原子廣播,這個機制保證了各個Server之間的同步。實現這個機制的協議叫做Zab協議。Zab協議有兩種模式,它們分別是恢復模式(選主)和廣播模式(同步)。當服務啓動或者在領導者崩潰後,Zab就進入了恢復模式,當領導者被選舉出來,且大多數Server完成了和leader的狀態同步以後,恢復模式就結束了。狀態同步保證了leader和Server具有相同的系統狀態。
爲了保證事務的順序一致性,zookeeper採用了遞增的事務id號(zxid)來標識事務。所有的提議(proposal)都在被提出的時候加上了zxid。實現中zxid是一個64位的數字,它高32位是epoch用來標識leader關係是否改變,每次一個leader被選出來,它都會有一個新的epoch,標識當前屬於那個leader的統治時期。低32位用於遞增計數。
每個Server在工作過程中有三種狀態:
LOOKING:當前Server不知道leader是誰,正在搜尋
LEADING:當前Server即爲選舉出來的leader
FOLLOWING:leader已經選舉出來,當前Server與之同步
2.1 選主流程
當leader崩潰或者leader失去大多數的follower,這時候zk進入恢復模式,恢復模式需要重新選舉出一個新的leader,讓所有的Server都恢復到一個正確的狀態。Zk的選舉算法有兩種:一種是基於basic paxos實現的,另外一種是基於fast paxos算法實現的。系統默認的選舉算法爲fast paxos。
fast paxos流程是在選舉過程中,某Server首先向所有Server提議自己要成爲leader,當其它Server收到提議以後,解決epoch和zxid的衝突,並接受對方的提議,然後向對方發送接受提議完成的消息,重複這個流程,最後一定能選舉出Leader。其流程圖如下所示:

2.2 同步流程
選完leader以後,zk就進入狀態同步過程。
1. leader等待server連接;
2 .Follower連接leader,將最大的zxid發送給leader;
3 .Leader根據follower的zxid確定同步點;
4 .完成同步後通知follower 已經成爲uptodate狀態;
5 .Follower收到uptodate消息後,又可以重新接受client的請求進行服務了。
流程圖如下所示:

2.3 工作流程
2.3.1 Leader工作流程
Leader主要有三個功能:
1 .恢復數據;
2 .維持與Learner的心跳,接收Learner請求並判斷Learner的請求消息類型;
3 .Learner的消息類型主要有PING消息、REQUEST消息、ACK消息、REVALIDATE消息,根據不同的消息類型,進行不同的處理。
PING消息是指Learner的心跳信息;
REQUEST消息是Follower發送的提議信息,包括寫請求及同步請求;
ACK消息是Follower的對提議的回覆,超過半數的Follower通過,則commit該提議;
REVALIDATE消息是用來延長SESSION有效時間。
Leader的工作流程簡圖如下所示,在實際實現中,流程要比下圖複雜得多,啓動了三個線程來實現功能。

2.3.2 Follower工作流程
Follower主要有四個功能:
1. 向Leader發送請求(PING消息、REQUEST消息、ACK消息、REVALIDATE消息);
2 .接收Leader消息並進行處理;
3 .接收Client的請求,如果爲寫請求,發送給Leader進行投票;
4 .返回Client結果。
Follower的消息循環處理如下幾種來自Leader的消息:
1 .PING消息: 心跳消息;
2 .PROPOSAL消息:Leader發起的提案,要求Follower投票;
3 .COMMIT消息:服務器端最新一次提案的信息;
4 .UPTODATE消息:表明同步完成;
5 .REVALIDATE消息:根據Leader的REVALIDATE結果,關閉待revalidate的session還是允許其接受消息;
6 .SYNC消息:返回SYNC結果到客戶端,這個消息最初由客戶端發起,用來強制得到最新的更新。
Follower的工作流程簡圖如下所示,在實際實現中,Follower是通過5個線程來實現功能的。

對於observer的流程不再敘述,observer流程和Follower的唯一不同的地方就是observer不會參加leader發起的投票。
3 ZooKeeper的安裝(windows環境下)
zk工具下載 鏈接:https://pan.baidu.com/s/1jdT1mHa0R8ARXHzWYxZQ4A 密碼:4p9v

修改完配置文件之後我們雙擊啓動zookeeper的zkServer.cmd

啓動zk的客戶端 進入F:\kaifa\ZK\ZooInspector\build 輸入命令 java -jar zookeeper-dev-ZooInspector.jar


Zookeeper的主流應用場景實現思路(除去官方示例)
(1)配置管理
集中式的配置管理在應用集羣中是非常常見的,一般商業公司內部都會實現一套集中的配置管理中心,應對不同的應用集羣對於共享各自配置的需求,並且在配置變更時能夠通知到集羣中的每一個機器。
Zookeeper很容易實現這種集中式的配置管理,比如將APP1的所有配置配置到/APP1 znode下,APP1所有機器一啓動就對/APP1這個節點進行監控(zk.exist("/APP1",true)),並且實現回調方法Watcher,那麼在zookeeper上/APP1 znode節點下數據發生變化的時候,每個機器都會收到通知,Watcher方法將會被執行,那麼應用再取下數據即可(zk.getData("/APP1",false,null));
以上這個例子只是簡單的粗顆粒度配置監控,細顆粒度的數據可以進行分層級監控,這一切都是可以設計和控制的。 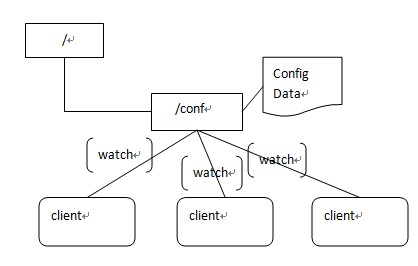
(2)集羣管理
應用集羣中,我們常常需要讓每一個機器知道集羣中(或依賴的其他某一個集羣)哪些機器是活着的,並且在集羣機器因爲宕機,網絡斷鏈等原因能夠不在人工介入的情況下迅速通知到每一個機器。
Zookeeper同樣很容易實現這個功能,比如我在zookeeper服務器端有一個znode叫/APP1SERVERS,那麼集羣中每一個機器啓動的時候都去這個節點下創建一個EPHEMERAL類型的節點,比如server1創建/APP1SERVERS/SERVER1(可以使用ip,保證不重複),server2創建/APP1SERVERS/SERVER2,然後SERVER1和SERVER2都watch /APP1SERVERS這個父節點,那麼也就是這個父節點下數據或者子節點變化都會通知對該節點進行watch的客戶端。因爲EPHEMERAL類型節點有一個很重要的特性,就是客戶端和服務器端連接斷掉或者session過期就會使節點消失,那麼在某一個機器掛掉或者斷鏈的時候,其對應的節點就會消失,然後集羣中所有對/APP1SERVERS進行watch的客戶端都會收到通知,然後取得最新列表即可。
另外有一個應用場景就是集羣選master,一旦master掛掉能夠馬上能從slave中選出一個master,實現步驟和前者一樣,只是機器在啓動的時候在APP1SERVERS創建的節點類型變爲EPHEMERAL_SEQUENTIAL類型,這樣每個節點會自動被編號
我們默認規定編號最小的爲master,所以當我們對/APP1SERVERS節點做監控的時候,得到服務器列表,只要所有集羣機器邏輯認爲最小編號節點爲master,那麼master就被選出,而這個master宕機的時候,相應的znode會消失,然後新的服務器列表就被推送到客戶端,然後每個節點邏輯認爲最小編號節點爲master,這樣就做到動態master選舉。
Zookeeper 監視(Watches) 簡介
Zookeeper C API 的聲明和描述在 include/zookeeper.h 中可以找到,另外大部分的 Zookeeper C API 常量、結構體聲明也在 zookeeper.h 中,如果如果你在使用 C API 是遇到不明白的地方,最好看看 zookeeper.h,或者自己使用 doxygen 生成 Zookeeper C API 的幫助文檔。
Zookeeper 中最有特色且最不容易理解的是監視(Watches)。Zookeeper 所有的讀操作——getData(), getChildren(), 和 exists() 都 可以設置監視(watch),監視事件可以理解爲一次性的觸發器, 官方定義如下: a watch event is one-time trigger, sent to the client that set the watch, which occurs when the data for which the watch was set changes。對此需要作出如下理解:
(一次性觸發)One-time trigger
當設置監視的數據發生改變時,該監視事件會被髮送到客戶端,例如,如果客戶端調用了 getData("/znode1", true) 並且稍後 /znode1 節點上的數據發生了改變或者被刪除了,客戶端將會獲取到 /znode1 發生變化的監視事件,而如果 /znode1 再一次發生了變化,除非客戶端再次對 /znode1 設置監視,否則客戶端不會收到事件通知。
(發送至客戶端)Sent to the client
Zookeeper 客戶端和服務端是通過 socket 進行通信的,由於網絡存在故障,所以監視事件很有可能不會成功地到達客戶端,監視事件是異步發送至監視者的,Zookeeper 本身提供了保序性(ordering guarantee):即客戶端只有首先看到了監視事件後,纔會感知到它所設置監視的 znode 發生了變化(a client will never see a change for which it has set a watch until it first sees the watch event). 網絡延遲或者其他因素可能導致不同的客戶端在不同的時刻感知某一監視事件,但是不同的客戶端所看到的一切具有一致的順序。
(被設置 watch 的數據)The data for which the watch was set
這意味着 znode 節點本身具有不同的改變方式。你也可以想象 Zookeeper 維護了兩條監視鏈表:數據監視和子節點監視(data watches and child watches) getData() and exists() 設置數據監視,getChildren() 設置子節點監視。 或者,你也可以想象 Zookeeper 設置的不同監視返回不同的數據,getData() 和 exists() 返回 znode 節點的相關信息,而 getChildren() 返回子節點列表。因此, setData() 會觸發設置在某一節點上所設置的數據監視(假定數據設置成功),而一次成功的 create() 操作則會出發當前節點上所設置的數據監視以及父節點的子節點監視。一次成功的 delete() 操作將會觸發當前節點的數據監視和子節點監視事件,同時也會觸發該節點父節點的child watch。
Zookeeper 中的監視是輕量級的,因此容易設置、維護和分發。當客戶端與 Zookeeper 服務器端失去聯繫時,客戶端並不會收到監視事件的通知,只有當客戶端重新連接後,若在必要的情況下,以前註冊的監視會重新被註冊並觸發,對於開發人員來說 這通常是透明的。只有一種情況會導致監視事件的丟失,即:通過 exists() 設置了某個 znode 節點的監視,但是如果某個客戶端在此 znode 節點被創建和刪除的時間間隔內與 zookeeper 服務器失去了聯繫,該客戶端即使稍後重新連接 zookeeper服務器後也得不到事件通知。
Zookeeper C API 常量與部分結構(struct)介紹
與 ACL 相關的結構與常量:
struct Id 結構爲:
struct Id { char * scheme; char * id; };
struct ACL 結構爲:
struct ACL { int32_t perms; struct Id id; };
struct ACL_vector 結構爲:
struct ACL_vector { int32_t count; struct ACL *data; };
與 znode 訪問權限有關的常量
const int ZOO_PERM_READ; //允許客戶端讀取 znode 節點的值以及子節點列表。
const int ZOO_PERM_WRITE;// 允許客戶端設置 znode 節點的值。
const int ZOO_PERM_CREATE; //允許客戶端在該 znode 節點下創建子節點。
const int ZOO_PERM_DELETE;//允許客戶端刪除子節點。
const int ZOO_PERM_ADMIN; //允許客戶端執行 set_acl()。
const int ZOO_PERM_ALL;//允許客戶端執行所有操作,等價與上述所有標誌的或(OR) 。
與 ACL IDs 相關的常量
struct Id ZOO_ANYONE_ID_UNSAFE; //(‘world’,’anyone’)
struct Id ZOO_AUTH_IDS;// (‘auth’,’’)
三種標準的 ACL
struct ACL_vector ZOO_OPEN_ACL_UNSAFE; //(ZOO_PERM_ALL,ZOO_ANYONE_ID_UNSAFE)
struct ACL_vector ZOO_READ_ACL_UNSAFE;// (ZOO_PERM_READ, ZOO_ANYONE_ID_UNSAFE)
struct ACL_vector ZOO_CREATOR_ALL_ACL; //(ZOO_PERM_ALL,ZOO_AUTH_IDS)
與 Interest 相關的常量:ZOOKEEPER_WRITE, ZOOKEEPER_READ
這 兩個常量用於標識感興趣的事件並通知 zookeeper 發生了哪些事件。Interest 常量可以進行組合或(OR)來標識多種興趣(multiple interests: write, read),這兩個常量一般用於 zookeeper_interest() 和 zookeeper_process()兩個函數中。
與節點創建相關的常量:ZOO_EPHEMERAL, ZOO_SEQUENCE
zoo_create 函數標誌,ZOO_EPHEMERAL 用來標識創建臨時節點,ZOO_SEQUENCE 用來標識節點命名具有遞增的後綴序號(一般是節點名稱後填充 10 位字符的序號,如 /xyz0000000000, /xyz0000000001, /xyz0000000002, ...),同樣地,ZOO_EPHEMERAL, ZOO_SEQUENCE 可以組合。
與連接狀態 Stat 相關的常量
以下常量均與 Zookeeper 連接狀態有關,他們通常用作監視器回調函數的參數。
| ZOOAPI const int | ZOO_EXPIRED_SESSION_STATE |
| ZOOAPI const int | ZOO_AUTH_FAILED_STATE |
| ZOOAPI const int | ZOO_CONNECTING_STATE |
| ZOOAPI const int | ZOO_ASSOCIATING_STATE |
| ZOOAPI const int | ZOO_CONNECTED_STATE |
與監視類型(Watch Types)相關的常量
以下常量標識監視事件的類型,他們通常用作監視器回調函數的第一個參數。
ZOO_DELETED_EVENT; // 節點被刪除,通過 zoo_exists() 和 zoo_get() 設置監視。
ZOO_CHANGED_EVENT; // 節點發生變化,通過 zoo_exists() 和 zoo_get() 設置監視。
ZOO_CHILD_EVENT; // 子節點事件,通過zoo_get_children() 和 zoo_get_children2()設置監視。
Zookeeper C API 錯誤碼介紹 ZOO_ERRORS
| ZOK | 正常返回 |
| ZSYSTEMERROR | 系統或服務器端錯誤(System and server-side errors),服務器不會拋出該錯誤,該錯誤也只是用來標識錯誤範圍的,即大於該錯誤值,且小於 ZAPIERROR 都是系統錯誤。 |
| ZRUNTIMEINCONSISTENCY | 運行時非一致性錯誤。 |
| ZDATAINCONSISTENCY | 數據非一致性錯誤。 |
| ZCONNECTIONLOSS | Zookeeper 客戶端與服務器端失去連接 |
| ZMARSHALLINGERROR | 在 marshalling 和 unmarshalling 數據時出現錯誤(Error while marshalling or unmarshalling data) |
| ZUNIMPLEMENTED | 該操作未實現(Operation is unimplemented) |
| ZOPERATIONTIMEOUT | 該操作超時(Operation timeout) |
| ZBADARGUMENTS | 非法參數錯誤(Invalid arguments) |
| ZINVALIDSTATE | 非法句柄狀態(Invliad zhandle state) |
| ZAPIERROR | API 錯誤(API errors),服務器不會拋出該錯誤,該錯誤也只是用來標識錯誤範圍的,錯誤值大於該值的標識 API 錯誤,而小於該值的標識 ZSYSTEMERROR。 |
| ZNONODE | 節點不存在(Node does not exist) |
| ZNOAUTH | 沒有經過授權(Not authenticated) |
| ZBADVERSION | 版本衝突(Version conflict) |
| ZNOCHILDRENFOREPHEMERALS | 臨時節點不能擁有子節點(Ephemeral nodes may not have children) |
| ZNODEEXISTS | 節點已經存在(The node already exists) |
| ZNOTEMPTY | 該節點具有自身的子節點(The node has children) |
| ZSESSIONEXPIRED | 會話過期(The session has been expired by the server) |
| ZINVALIDCALLBACK | 非法的回調函數(Invalid callback specified) |
| ZINVALIDACL | 非法的ACL(Invalid ACL specified) |
| ZAUTHFAILED | 客戶端授權失敗(Client authentication failed) |
| ZCLOSING | Zookeeper 連接關閉(ZooKeeper is closing) |
| ZNOTHING | 並非錯誤,客戶端不需要處理服務器的響應(not error, no server responses to process) |
| ZSESSIONMOVED | 會話轉移至其他服務器,所以操作被忽略(session moved to another server, so operation is ignored) |
Watch事件類型:
ZOO_CREATED_EVENT:節點創建事件,需要watch一個不存在的節點,當節點被創建時觸發,此watch通過zoo_exists()設置
ZOO_DELETED_EVENT:節點刪除事件,此watch通過zoo_exists()或zoo_get()設置
ZOO_CHANGED_EVENT:節點數據改變事件,此watch通過zoo_exists()或zoo_get()設置
ZOO_CHILD_EVENT:子節點列表改變事件,此watch通過zoo_get_children()或zoo_get_children2()設置
ZOO_SESSION_EVENT:會話失效事件,客戶端與服務端斷開或重連時觸發
ZOO_NOTWATCHING_EVENT:watch移除事件,服務端出於某些原因不再爲客戶端watch節點時觸發