




基於自適應顏色屬性的目標追蹤
Adaptive Color Attributes for Real-Time Visual Tracking
基於自適應顏色屬性的實時視覺追蹤
3月講的第一篇論文,個人理解,存在很多問題,歡迎交流!
這是CVPR2014年的文章。名字翻譯爲基於自適應選擇顏色屬性的實時視覺跟蹤。首先理解什麼是Adaptive color attributes,文章中colorattributes把顏色分爲11類,就是將RGB三種顏色細化爲黑、藍、棕、灰、綠、橙、粉、紫、紅、白和黃共11種。那麼如何做到adaptive(自適應)?就是實時的選擇比較顯著的顏色,這個選擇的過程是一種類似PCA(主成分分析)中降維的思想,將11維特徵降爲2 維(代碼裏使用的就是2),文章重點之一就是這個。
主成分分析:主要用於特徵的降維。
PCA是指它可以從多元事物中解析出主要影響因素,揭示事物的本質,簡化複雜的問題,是尋找最小均方意義下、最能代表原始數據的投影方法。主成分分析的主要思想是尋找到數據的主軸方向,由主軸構成一個新的座標系,這裏的維數可以比原維數低,然後數據由原座標系向新的座標系投影,這個投影的過程就是降維的過程。
摘要
視覺跟蹤在計算機視覺中是一個很有挑戰性的問題,現在最好的(state-of-art) 視覺跟蹤器或者依賴於光照信息或是使用簡單的顏色表示來描述圖片。與視覺跟蹤不同的是,在目標識別和檢測問題中,結合光照信息和複雜的顏色特徵可以提供非常好的表現。由於跟蹤問題的複雜性,所需要的顏色特徵應該被有效的計算並且擁有一定的光學不變形同時保持較高的辨別力。
這篇文章研究基於檢測的跟蹤(tracking-by-detection)結構下顏色屬性的貢獻值。我們的結果表明顏色屬性對於視覺跟蹤問題具有優越的表現。我們進而提出一種自適應低維顏色屬性的轉化。用41個有挑戰性的基準顏色序列進行基於量化和屬性評估方法的評價。該方法比基於光照強度的跟蹤器提升了24%的距離精度。此外,可以得到我們的方法勝過最先進的追蹤方法,並且速度可達到100fps以上。
1. Introduction
目標跟蹤就是在圖片序列中找到目標的位置,(目標是提前標明的,即在第一幀給出),在計算機視覺中是最優挑戰性的問題,在許多應用中扮演了至關重要的作用,比如,人機交互,視頻監控,機器人。跟蹤問題之所以複雜是因爲,跟蹤過程中可能發生光照改變,遮擋,背景干擾,跟蹤目標發生形變。本文調查瞭如何使用顏色信息來減小上述問題的影響。
現在最先進的跟蹤器或是使用光照強度(RGB值)或是使用紋理信息。儘管現在在視覺跟蹤方面已經取得了很大的進展,但是對於顏色信息的使用還是僅限於簡單的顏色空間轉換。和視覺跟蹤不同的是,在目標檢測方面,複雜的,巧妙設計的顏色特徵顯示了非常好的效果,而利用顏色信息做視覺跟蹤是一件很難的事情。顏色測量結果在整個圖片序列中變化很大,原因包括光照改變,陰影,相機和目標幾何位置的變化。對於彩色圖像在上述情況下魯棒性的評價已經用在 圖像分類,行爲識別上,因此我們使用現在的評價方法來評價對目標跟蹤這個問題的顏色轉換的方法。
現在處理視覺跟蹤問題的方法有兩種,叫生成方法和判別方法(看過機器學習的人應該很熟)。生成方法不斷去搜索和目標最相似的區域,這類方法或者基於模板匹配或是基於子空間模型(子空間這個概念有點唬人,我覺得就是將原始的目標,分爲好多層,就像ps裏的圖層一樣)。判別方法旨在將目標從背景中區分出來,就是將跟蹤問題變爲二分類問題。生成方法只使用了目標的信息,而判別方法既使用目標信息也使用背景的信息,找到一個將目標區分出來的分類界限。這種方法在很多基於tracking by detection框架的算法中使用,即使用目標和目標附近的環境訓練出一個online的分類器。在前幾年有個對現在比較優秀跟蹤器的評價,(可以看cvpr2013年的一個benchmark),裏面有個csk的跟蹤器,排在前十名,而且擁有非常高的速度,這種跟蹤器發現了一個密度採樣的策略,就是對一幀中多個子窗口的處理,可以歸爲對一個循環矩陣的處理,由於csk良好的表現和快速,我們的方法是基於csk跟蹤器。
貢獻:本文使用顏色屬性擴展了csk跟蹤器,並取得了良好的表現。csk的模型更新機制在處理多通道信號時,是次優的,爲此我們調整了原來csk的更新機制,在實驗中證明了新機制在多通道跟蹤中的有效性。高維的顏色屬性導致計算複雜度上的增加,可能限制跟蹤器在實時應用和機器人中的使用,爲此我們提出了自適應的維度下降方法,將原始的11維下降到2維,這樣跟蹤器的幀率就可以達到100fps以上並且不影響精確度。最後我們做了大量的評價證明了。
2. The CSK Tracker
CSK是在一個單獨的圖像碎片中從目標中得到核心的最小方形分類器。首先,這篇文章使用的決策函數是一個結構風險最小化的函數:

文章中:




具體的細節後面再說。
Vapnik等人在多年研究統計學習理論基礎上對線性分類器提出了另一種設計最佳準則。其原理也從線性可分說起,然後擴展到線性不可分的情況。甚至擴展到使用非線性函數中去,這種分類器被稱爲支持向量機(Support Vector Machine,簡稱SVM)。支持向量機的提出有很深的理論背景。
支持向量機方法是在近年來提出的一種新方法。
SVM的主要思想可以概括爲兩點:⑴它是針對線性可分情況進行分析,對於線性不可分的情況,通過使用非線性映射算法將低維輸入空間線性不可分的樣本轉化爲高維特徵空間使其線性可分,從而 使得高維特徵空間採用線性算法對樣本的非線性特徵進行線性分析成爲可能;
這裏主要說代碼的思路。
首先:讀入視頻文件,得到groundtruth信息,也就得到了object的位置和大小的信息;然後得到一個在目標框圖內目標的分佈函數(高斯的分佈,這一點我不是很明白,和公式裏面不一樣);
接下來: 讀入第一張圖片,轉化爲灰度圖,對框內的數據進行窗口濾波的處理,得到一個邊緣效應比較小的數據。並且這個數據是被歸一化到-0.5~0.5的;
然後: 通過以上數據求得核函數K;然後利用K再求出f(x)需要用到的 alpha(就是上面公式裏面的c);(值得注意的是這裏對於這兩個重要的參數的求解都是從FourierDomain求得的,這裏是本文的一個創新點,也是速度如此快的原因)
接下來: 對於後面的每一幀圖像, 先轉化爲灰度圖像,然後用hann窗預處理好輸入的數據;接下來結合上一幀圖像的信息再次計算K;然後由現在的alpha和K來計算出響應值,選出響應值最大的位置。(值得注意的是這裏計算的出來的響應值是待處理的Frame裏面的每一個可能的目標區域)
最後: 根據響應值最大的位置來計算現在的K,然後更新alpha。然後處理下一幀圖像。(同時也要看到,計算響應值和更新alpha所用到的K的計算的方式是不一樣的。代碼裏面,計算響應值的K是目標和待檢測的目標img進行卷積的,而更新的時候是目標和自己卷積的)
l 高斯函數
高斯函數的形式爲:
其中 a、b 與 c 爲實數常數 ,且a > 0.
c2 = 2 的高斯函數是傅立葉變換的特徵函數。這就意味着高斯函數的傅立葉變換不僅僅是另一個高斯函數,而且是進行傅立葉變換的函數的標量倍。
在計算機視覺中,有時也簡稱爲高斯函數。高斯函數具有五個重要的性質,這些性質使得它在早期圖像處理中特別有用.這些性質表明,高斯平滑濾波器無論在空間域還是在頻率域都是十分有效的低通濾波器,且在實際圖像處理中得到了工程人員的有效使用.高斯函數具有五個十分重要的性質,它們是:
(1)二維高斯函數具有旋轉對稱性,即濾波器在各個方向上的平滑程度是相同的.一般來說,一幅圖像的邊緣方向是事先不知道的,因此,在濾波前是無法確定一個方向上比另一方向上需要更多的平滑.旋轉對稱性意味着高斯平滑濾波器在後續邊緣檢測中不會偏向任一方向.
(2)高斯函數是單值函數.這表明,高斯濾波器用像素鄰域的加權均值來代替該點的像素值,而每一鄰域像素點權值是隨該點與中心點的距離單調增減的.這一性質是很重要的,因爲邊緣是一種圖像局部特徵,如果平滑運算對離算子中心很遠的像素點仍然有很大作用,則平滑運算會使圖像失真.
(3)高斯函數的傅立葉變換頻譜是單瓣的.正如下面所示,這一性質是高斯函數付立葉變換等於高斯函數本身這一事實的直接推論.圖像常被不希望的高頻信號所污染(噪聲和細紋理).而所希望的圖像特徵(如邊緣),既含有低頻分量,又含有高頻分量.高斯函數付立葉變換的單瓣意味着平滑圖像不會被不需要的高頻信號所污染,同時保留了大部分所需信號.
(4)高斯濾波器寬度(決定着平滑程度)是由參數σ表徵的,而且σ和平滑程度的關係是非常簡單的.σ越大,高斯濾波器的頻帶就越寬,平滑程度就越好.通過調節平滑程度參數σ,可在圖像特徵過分模糊(過平滑)與平滑圖像中由於噪聲和細紋理所引起的過多的不希望突變量(欠平滑)之間取得折衷.
(5)由於高斯函數的可分離性,大高斯濾波器可以得以有效地實現.二維高斯函數卷積可以分兩步來進行,首先將圖像與一維高斯函數進行卷積,然後將卷積結果與方向垂直的相同一維高斯函數卷積.因此,二維高斯濾波的計算量隨濾波模板寬度成線性增長而不是成平方增長.
l 希爾伯特空間
完備的內積空間,在一個複數向量空間上的給定的內積可以按照如下的方式導出一個範數(norm):
此空間稱爲是一個希爾伯特空間,如果其對於這個範數來說是完備的。這裏的完備性是指,任何一個柯西列都收斂到此空間中的某個元素,即它們與某個元素的範數差的極限爲。任何一個希爾伯特空間都是巴拿赫空間,但是反之未必。
l 離散傅里葉變換和快速傅里葉變換
l 高斯RBF內核(高斯徑向基核函數)
所謂徑向基函數 (Radial Basis Function簡稱 RBF),就是某種沿徑向對稱的標量函數。通常定義爲空間中任一點x到某一中心xc之間歐氏距離的單調函數 ,可記作 k(||x-xc||),其作用往往是局部的 ,即當x遠離xc時函數取值很小。最常用的徑向基函數是高斯核函數 ,形式爲k(||x-xc||)=exp{- ||x-xc||^2/(2*σ^2) }其中xc爲核函數中心,σ爲函數的寬度參數 , 控制了函數的徑向作用範圍。
l 核函數(Kernels)
將核函數形式化定義,如果原始特徵內積是,映射後爲,那麼定義核函數(Kernel)爲
由於計算的是內積,我們可以想到IR中的餘弦相似度,如果x和z向量夾角越小,那麼核函數值越大,反之,越小。因此,核函數值是和的相似度。
SVM的核函數如何選取?
1. Linear核:主要用於線性可分的情形。參數少,速度快,對於一般數據,分類效果已經很理想了。
2. RBF核:主要用於線性不可分的情形。參數多,分類結果非常依賴於參數。有很多人是通過訓練數據的交叉驗證來尋找合適的參數,不過這個過程比較耗時。我個人的體會是:使用libsvm,默認參數,RBF核比Linear核效果稍差。通過進行大量參數的嘗試,一般能找到比linear核更好的效果。
3. 顏色視覺追蹤
爲了能合併顏色信息,我們通過定義一個合適的內核K來擴展CSK追蹤不起到多維顏色特徵。
1. a Hann Window
漢寧窗又稱升餘弦窗,漢寧窗可以看作是3個矩形時間窗的頻譜之和,或者說是 3個 sinc(t)型函數之和,而括號中的兩項相對於第一個譜窗向左、右各移動了 π/T,從而使旁瓣互相抵消,消去高頻干擾和漏能。可以看出,漢寧窗主瓣加寬並降低,旁瓣則顯著減小,從減小泄漏觀點出發,漢寧窗優於矩形窗.但漢寧窗主瓣加寬,相當於分析帶寬加寬,頻率分辨力下降。
2. 低維度自適應顏色屬性
提出一種自適應維度減少的方法,它能夠存儲有用信息的同時大大減少顏色維度的數量,從而使得速度有了顯著的提升。
Adaptivecolor attributes:
文章中colorattributes把顏色分爲11類,就是將RGB三種顏色細化爲11種基本顏色(black,blue,brown,grey,green,orange,pink,purple,red,white,yellow)。
如何做到adaptive(自適應)?就是實時的選擇比較顯著的顏色,這個選擇的過程是一種類似PCA(主成分分析)中降維的思想,將11維特徵降爲2 維(代碼裏使用的就是2) 。
對於CN(color name)映射有兩種規範化技術:
1.將11個顏色容器中各減去1/11,CN將變爲10維子空間
2.將CN投影到10維子空間的標準正交基上。(效果更好)
l 基於顏色特徵拓展CSK分類器:
目標模型由兩部分組成:
學習目標外觀(thelearned target appearance) && 變換的分類器參數A
1)CSK tracker 線性插值:
(並非前面所有的幀都同時用於更新當前的數據)
2)文獻4 MOSSE tracker:在更新方案中計算當前幀的同時考慮前面所有幀(本文所用的方法)
(但僅用於一維,我們需要將方法用於多維顏色特徵)
更新分類器:
l 最小代價函數:


l 低維自適應顏色屬性:
方法:通過最小代價函數,爲當前幀P找到一個適合的降維映射。

{kind=link}
{kind=link}
{kind=link}
{kind=link}
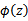{kind=link}
4. 實驗
三個評估參數:
CLE中心位置誤差:目標的估計中心位置與真實地面的平均歐氏距離;
DP距離精度:中心誤差小於一個給定閾值的幀的相對數量;
OP重複精度:邊界框重疊的地方超過一個閾值的百分比。
實驗圖見論文
1.顏色特徵的評估
2.更新方案
3.低維自適應顏色屬性
4.與最先進方法比較
結論:
CN和CN2得到較好的結果,CN2速度要快,本文提出的的方法較好!
總結:
本文提出使用顏色屬性來進行視覺追蹤,並且將CSK追蹤器的學習方案擴展到多通道顏色特徵,提出基於顏色屬性的低維自適應擴展。最終可以得到結論:文章中提出的方法在100FPS的速度的同時保持最高的精確度。
解釋:
Struck:Structuredoutput tracking with kernels基於內核的結構化輸出跟蹤
EDFT:Enhanced distribution fieldtracking using channel representations基於通道表示的增強分佈場追蹤
CSK:Exploiting the circulantstructure of tracking-by-detection with kernels
LSHT:Visual tracking via localitysensitive histograms基於局部敏感直方圖的目標跟蹤算法
有對應源碼和論文
存在的問題(慢慢的解決掉):
1' 一直沒有對a裏面的y進行更新的原因?(其實和位置無關,只和框的大小有關?)
2. 爲什麼用響應值來代表?
3. 加hann窗對數據處理的原因?難點是濾波?
4.關於A,k的更新,貌似不是一個函數更新,但是更新是在當前幀還是下一幀?
5.降維得到的投影矩陣和協方差矩陣是如何用在CSK中的?
6.csk中如果求導來得到其最大值和最小值會不會更容易,速度更快?
本文的參考文獻:
1.CSK :J.Henriques, R.Caseiro,
P. Martins, and J. Batista. Exploitingthecirculant structure oftracking-by-detection with kernels. InECCV,
2012.
2. J. van deWeijer, C.Schmid,
J. J.Verbeek, and D.Larlus. Learning color namesfor
real-world applications.TIP,18(7):1512–1524,2009.