




在看具體源碼前,我們先回顧一下之前我們所實現的內容,從而找一個合適的切入口去分析。首先,服務註冊中心、服務提供者、服務消費者這三個主要元素來說,後兩者(也就是Eureka客戶端)在整個運行機制中是大部分通信行爲的主動發起者,而註冊中心主要是處理請求的接收者。所以,我們可以從Eureka的客戶端作爲入口看看它是如何完成這些主動通信行爲的。
我們在將一個普通的Spring Boot應用註冊到Eureka Server中,或是從Eureka Server中獲取服務列表時,主要就做了兩件事:
- 在應用主類中配置了
@EnableDiscoveryClient註解 - 在
application.properties中用eureka.client.serviceUrl.defaultZone參數指定了服務註冊中心的位置
順着上面的線索,我們先查看@EnableDiscoveryClient的源碼如下:
/**
* Annotation to enable a DiscoveryClient implementation.
* @author Spencer Gibb
*/
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@Import(EnableDiscoveryClientImportSelector.class)
public @interface EnableDiscoveryClient {
}
|
從該註解的註釋我們可以知道:該註解用來開啓DiscoveryClient的實例。通過搜索DiscoveryClient,我們可以發現有一個類和一個接口。通過梳理可以得到如下圖的關係:
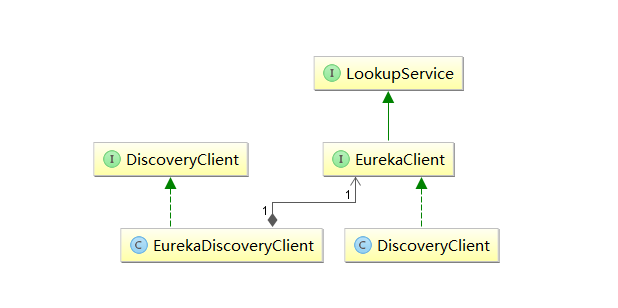
其中,左邊的org.springframework.cloud.client.discovery.DiscoveryClient是Spring Cloud的接口,它定義了用來發現服務的常用抽象方法,而org.springframework.cloud.netflix.eureka.EurekaDiscoveryClient是對該接口的實現,從命名來就可以判斷,它實現的是對Eureka發現服務的封裝。所以EurekaDiscoveryClient依賴了Eureka的com.netflix.discovery.EurekaClient接口,EurekaClient繼承了LookupService接口,他們都是Netflix開源包中的內容,它主要定義了針對Eureka的發現服務的抽象方法,而真正實現發現服務的則是Netflix包中的com.netflix.discovery.DiscoveryClient類。
那麼,我們就看看來詳細看看DiscoveryClient類。先解讀一下該類頭部的註釋有個總體的瞭解,註釋的大致內容如下:
這個類用於幫助與Eureka Server互相協作。 Eureka Client負責了下面的任務: - 向Eureka Server註冊服務實例 - 向Eureka Server爲租約續期 - 當服務關閉期間,向Eureka Server取消租約 - 查詢Eureka Server中的服務實例列表 Eureka Client還需要配置一個Eureka Server的URL列表。 |
在具體研究Eureka Client具體負責的任務之前,我們先看看對Eureka Server的URL列表配置在哪裏。根據我們配置的屬性名:eureka.client.serviceUrl.defaultZone,通過serviceUrl我們找到該屬性相關的加載屬性,但是在SR5版本中它們都被@Deprecated標註了,並在注視中可以看到@link到了替代類com.netflix.discovery.endpoint.EndpointUtils,我們可以在該類中找到下面這個函數:
public static Map<String, List<String>> getServiceUrlsMapFromConfig(
EurekaClientConfig clientConfig, String instanceZone, boolean preferSameZone) {
Map<String, List<String>> orderedUrls = new LinkedHashMap<>();
String region = getRegion(clientConfig);
String[] availZones = clientConfig.getAvailabilityZones(clientConfig.getRegion());
if (availZones == null || availZones.length == 0) {
availZones = new String[1];
availZones[0] = DEFAULT_ZONE;
}
……
int myZoneOffset = getZoneOffset(instanceZone, preferSameZone, availZones);
String zone = availZones[myZoneOffset];
List<String> serviceUrls = clientConfig.getEurekaServerServiceUrls(zone);
if (serviceUrls != null) {
orderedUrls.put(zone, serviceUrls);
}
……
return orderedUrls;
}
|
Region、Zone
在上面的函數中,我們可以發現客戶端依次加載了兩個內容,第一個是Region,第二個是Zone,從其加載邏上我們可以判斷他們之間的關係:
- 通過
getRegion函數,我們可以看到它從配置中讀取了一個Region返回,所以一個微服務應用只可以屬於一個Region,如果不特別配置,就默認爲default。若我們要自己設置,可以通過eureka.client.region屬性來定義。
public static String getRegion(EurekaClientConfig clientConfig) {
String region = clientConfig.getRegion();
if (region == null) {
region = DEFAULT_REGION;
}
region = region.trim().toLowerCase();
return region;
}
|
- 通過
getAvailabilityZones函數,我們可以知道當我們沒有特別爲Region配置Zone的時候,將默認採用defaultZone,這也是我們之前配置參數eureka.client.serviceUrl.defaultZone的由來。若要爲應用指定Zone,我們可以通過eureka.client.availability-zones屬性來進行設置。從該函數的return內容,我們可以Zone是可以有多個的,並且通過逗號分隔來配置。由此,我們可以判斷Region與Zone是一對多的關係。
public String[] getAvailabilityZones(String region) {
String value = this.availabilityZones.get(region);
if (value == null) {
value = DEFAULT_ZONE;
}
return value.split(",");
}
|
ServiceUrls
在獲取了Region和Zone信息之後,纔開始真正加載Eureka Server的具體地址。它根據傳入的參數按一定算法確定加載位於哪一個Zone配置的serviceUrls。
int myZoneOffset = getZoneOffset(instanceZone, preferSameZone, availZones); String zone = availZones[myZoneOffset]; List<String> serviceUrls = clientConfig.getEurekaServerServiceUrls(zone); |
具體獲取serviceUrls的實現,我們可以詳細查看getEurekaServerServiceUrls函數的具體實現類EurekaClientConfigBean,該類是EurekaClientConfig和EurekaConstants接口的實現,用來加載配置文件中的內容,這裏有非常多有用的信息,這裏我們先說一下此處我們關心的,關於defaultZone的信息。通過搜索defaultZone,我們可以很容易的找到下面這個函數,它具體實現了,如何解析該參數的過程,通過此內容,我們就可以知道,eureka.client.serviceUrl.defaultZone屬性可以配置多個,並且需要通過逗號分隔。
public List<String> getEurekaServerServiceUrls(String myZone) {
String serviceUrls = this.serviceUrl.get(myZone);
if (serviceUrls == null || serviceUrls.isEmpty()) {
serviceUrls = this.serviceUrl.get(DEFAULT_ZONE);
}
if (!StringUtils.isEmpty(serviceUrls)) {
final String[] serviceUrlsSplit = StringUtils.commaDelimitedListToStringArray(serviceUrls);
List<String> eurekaServiceUrls = new ArrayList<>(serviceUrlsSplit.length);
for (String eurekaServiceUrl : serviceUrlsSplit) {
if (!endsWithSlash(eurekaServiceUrl)) {
eurekaServiceUrl += "/";
}
eurekaServiceUrls.add(eurekaServiceUrl);
}
return eurekaServiceUrls;
}
return new ArrayList<>();
}
|
當客戶端在服務列表中選擇實例進行訪問時,對於Zone和Region遵循這樣的規則:優先訪問同自己一個Zone中的實例,其次才訪問其他Zone中的實例。通過Region和Zone的兩層級別定義,配合實際部署的物理結構,我們就可以有效的設計出區域性故障的容錯集羣。
服務註冊
在理解了多個服務註冊中心信息的加載後,我們再回頭看看DiscoveryClient類是如何實現“服務註冊”行爲的,通過查看它的構造類,可以找到它調用了下面這個函數:
private void initScheduledTasks() {
...
if (clientConfig.shouldRegisterWithEureka()) {
...
// InstanceInfo replicator
instanceInfoReplicator = new InstanceInfoReplicator(
this,
instanceInfo,
clientConfig.getInstanceInfoReplicationIntervalSeconds(),
2); // burstSize
...
instanceInfoReplicator.start(clientConfig.getInitialInstanceInfoReplicationIntervalSeconds());
} else {
logger.info("Not registering with Eureka server per configuration");
}
}
|
在上面的函數中,我們可以看到關鍵的判斷依據if (clientConfig.shouldRegisterWithEureka())。在該分支內,創建了一個InstanceInfoReplicator類的實例,它會執行一個定時任務,查看該類的run()函數了解該任務做了什麼工作:
public void run() {
try {
discoveryClient.refreshInstanceInfo();
Long dirtyTimestamp = instanceInfo.isDirtyWithTime();
if (dirtyTimestamp != null) {
discoveryClient.register();
instanceInfo.unsetIsDirty(dirtyTimestamp);
}
} catch (Throwable t) {
logger.warn("There was a problem with the instance info replicator", t);
} finally {
Future next = scheduler.schedule(this, replicationIntervalSeconds, TimeUnit.SECONDS);
scheduledPeriodicRef.set(next);
}
}
|
相信大家都發現了discoveryClient.register();這一行,真正觸發調用註冊的地方就在這裏。繼續查看register()的實現內容如下:
boolean register() throws Throwable {
logger.info(PREFIX + appPathIdentifier + ": registering service...");
EurekaHttpResponse<Void> httpResponse;
try {
httpResponse = eurekaTransport.registrationClient.register(instanceInfo);
} catch (Exception e) {
logger.warn("{} - registration failed {}", PREFIX + appPathIdentifier, e.getMessage(), e);
throw e;
}
if (logger.isInfoEnabled()) {
logger.info("{} - registration status: {}", PREFIX + appPathIdentifier, httpResponse.getStatusCode());
}
return httpResponse.getStatusCode() == 204;
}
|
通過屬性命名,大家基本也能猜出來,註冊操作也是通過REST請求的方式進行的。同時,這裏我們也能看到發起註冊請求的時候,傳入了一個com.netflix.appinfo.InstanceInfo對象,該對象就是註冊時候客戶端給服務端的服務的元數據。
服務獲取與服務續約
順着上面的思路,我們繼續來看DiscoveryClient的initScheduledTasks函數,不難發現在其中還有兩個定時任務,分別是“服務獲取”和“服務續約”:
private void initScheduledTasks() {
if (clientConfig.shouldFetchRegistry()) {
// registry cache refresh timer
int registryFetchIntervalSeconds = clientConfig.getRegistryFetchIntervalSeconds();
int expBackOffBound = clientConfig.getCacheRefreshExecutorExponentialBackOffBound();
scheduler.schedule(
new TimedSupervisorTask(
"cacheRefresh",
scheduler,
cacheRefreshExecutor,
registryFetchIntervalSeconds,
TimeUnit.SECONDS,
expBackOffBound,
new CacheRefreshThread()
),
registryFetchIntervalSeconds, TimeUnit.SECONDS);
}
if (clientConfig.shouldRegisterWithEureka()) {
int renewalIntervalInSecs = instanceInfo.getLeaseInfo().getRenewalIntervalInSecs();
int expBackOffBound = clientConfig.getHeartbeatExecutorExponentialBackOffBound();
logger.info("Starting heartbeat executor: " + "renew interval is: " + renewalIntervalInSecs);
// Heartbeat timer
scheduler.schedule(
new TimedSupervisorTask(
"heartbeat",
scheduler,
heartbeatExecutor,
renewalIntervalInSecs,
TimeUnit.SECONDS,
expBackOffBound,
new HeartbeatThread()
),
renewalIntervalInSecs, TimeUnit.SECONDS);
// InstanceInfo replicator
……
}
}
|
從源碼中,我們就可以發現,“服務獲取”相對於“服務續約”更爲獨立,“服務續約”與“服務註冊”在同一個if邏輯中,這個不難理解,服務註冊到Eureka Server後,自然需要一個心跳去續約,防止被剔除,所以他們肯定是成對出現的。從源碼中,我們可以清楚看到了,對於服務續約相關的時間控制參數:
eureka.instance.lease-renewal-interval-in-seconds=30 eureka.instance.lease-expiration-duration-in-seconds=90 |
而“服務獲取”的邏輯在獨立的一個if判斷中,其判斷依據就是我們之前所提到的eureka.client.fetch-registry=true參數,它默認是爲true的,大部分情況下我們不需要關心。爲了定期的更新客戶端的服務清單,以保證服務訪問的正確性,“服務獲取”的請求不會只限於服務啓動,而是一個定時執行的任務,從源碼中我們可以看到任務運行中的registryFetchIntervalSeconds參數對應eureka.client.registry-fetch-interval-seconds=30配置參數,它默認爲30秒。
繼續循序漸進的向下深入,我們就能分別發現實現“服務獲取”和“服務續約”的具體方法,其中“服務續約”的實現較爲簡單,直接以REST請求的方式進行續約:
boolean renew() {
EurekaHttpResponse<InstanceInfo> httpResponse;
try {
httpResponse = eurekaTransport.registrationClient.sendHeartBeat(instanceInfo.getAppName(), instanceInfo.getId(), instanceInfo, null);
logger.debug("{} - Heartbeat status: {}", PREFIX + appPathIdentifier, httpResponse.getStatusCode());
if (httpResponse.getStatusCode() == 404) {
REREGISTER_COUNTER.increment();
logger.info("{} - Re-registering apps/{}", PREFIX + appPathIdentifier, instanceInfo.getAppName());
return register();
}
return httpResponse.getStatusCode() == 200;
} catch (Throwable e) {
logger.error("{} - was unable to send heartbeat!", PREFIX + appPathIdentifier, e);
return false;
}
}
|
而“服務獲取”則相對複雜一些,會根據是否第一次獲取發起不同的REST請求和相應的處理,具體的實現邏輯還是跟之前類似,有興趣的讀者可以繼續查看服務客戶端的其他具體內容,瞭解更多細節。
服務註冊中心處理
通過上面的源碼分析,可以看到所有的交互都是通過REST的請求來發起的。下面我們來看看服務註冊中心對這些請求的處理。Eureka Server對於各類REST請求的定義都位於:com.netflix.eureka.resources包下。
以“服務註冊”請求爲例:
@POST
@Consumes({"application/json", "application/xml"})
public Response addInstance(InstanceInfo info,
@HeaderParam(PeerEurekaNode.HEADER_REPLICATION) String isReplication) {
logger.debug("Registering instance {} (replication={})", info.getId(), isReplication);
// validate that the instanceinfo contains all the necessary required fields
...
// handle cases where clients may be registering with bad DataCenterInfo with missing data
DataCenterInfo dataCenterInfo = info.getDataCenterInfo();
if (dataCenterInfo instanceof UniqueIdentifier) {
String dataCenterInfoId = ((UniqueIdentifier) dataCenterInfo).getId();
if (isBlank(dataCenterInfoId)) {
boolean experimental = "true".equalsIgnoreCase(
serverConfig.getExperimental("registration.validation.dataCenterInfoId"));
if (experimental) {
String entity = "DataCenterInfo of type " + dataCenterInfo.getClass()
+ " must contain a valid id";
return Response.status(400).entity(entity).build();
} else if (dataCenterInfo instanceof AmazonInfo) {
AmazonInfo amazonInfo = (AmazonInfo) dataCenterInfo;
String effectiveId = amazonInfo.get(AmazonInfo.MetaDataKey.instanceId);
if (effectiveId == null) {
amazonInfo.getMetadata().put(
AmazonInfo.MetaDataKey.instanceId.getName(), info.getId());
}
} else {
logger.warn("Registering DataCenterInfo of type {} without an appropriate id",
dataCenterInfo.getClass());
}
}
}
registry.register(info, "true".equals(isReplication));
return Response.status(204).build(); // 204 to be backwards compatible
}
|
在對註冊信息進行了一大堆校驗之後,會調用org.springframework.cloud.netflix.eureka.server.InstanceRegistry對象中的register(InstanceInfo info, int leaseDuration, boolean isReplication)函數來進行服務註冊:
public void register(InstanceInfo info, int leaseDuration, boolean isReplication) {
if (log.isDebugEnabled()) {
log.debug("register " + info.getAppName() + ", vip " + info.getVIPAddress()
+ ", leaseDuration " + leaseDuration + ", isReplication "
+ isReplication);
}
this.ctxt.publishEvent(new EurekaInstanceRegisteredEvent(this, info,
leaseDuration, isReplication));
super.register(info, leaseDuration, isReplication);
}
|
在註冊函數中,先調用publishEvent函數,將該新服務註冊的事件傳播出去,然後調用com.netflix.eureka.registry.AbstractInstanceRegistry父類中的註冊實現,將InstanceInfo中的元數據信息存儲在一個ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>>對象中,它是一個兩層Map結構,第一層的key存儲服務名:InstanceInfo中的appName屬性,第二層的key存儲實例名:InstanceInfo中的instanceId屬性。