




一、前言
關於RCU的文檔包括兩份,一份講基本的原理(也就是本文了),一份講linux kernel中的實現。第二章描述了爲何有RCU這種同步機制,特別是在cpu core數目不斷遞增的今天,一個性能更好的同步機制是如何解決問題的,當然,再好的工具都有其適用場景,本章也給出了RCU的一些應用限制。第三章的第一小節描述了RCU的設計概念,其實RCU的設計概念比較簡單,比較容易理解,比較困難的是產品級別的RCU實現,我們會在下一篇文檔中描述。第三章的第二小節描述了RCU的相關操作,其實就是對應到了RCU的外部接口API上來。最後一章是參考文獻,perfbook是一本神奇的數,喜歡並行編程的同學絕對不能錯過的一本書,強烈推薦。和perfbook比起來,本文顯得非常的醜陋(主要是有些RCU的知識還是理解不深刻,可能需要再仔細看看linux kernel中的實現才能瞭解其真正含義),除了是中文表述之外,沒有任何的優點,英語比較好的同學可以直接參考該書。
二、爲何有RCU這種同步機制呢?
前面我們講了spin lock,rw spin lock和seq lock,爲何又出現了RCU這樣的同步機制呢?這個問題類似於問:有了刀槍劍戟這樣的工具,爲何會出現流星錘這樣的兵器呢?每種兵器都有自己的適用場合,內核同步機制亦然。RCU在一定的應用場景下,解決了過去同步機制的問題,這也是它之所以存在的基石。本章主要包括兩部分內容:一部分是如何解決其他內核機制的問題,另外一部分是受限的場景爲何?
1、性能問題
我們先回憶一下spin lcok、RW spin lcok和seq lock的基本原理。對於spin lock而言,臨界區的保護是通過next和owner這兩個共享變量進行的。線程調用spin_lock進入臨界區,這裏包括了三個動作:
(1)獲取了自己的號碼牌(也就是next值)和允許哪一個號碼牌進入臨界區(owner)
(2)設定下一個進入臨界區的號碼牌(next++)
(3)判斷自己的號碼牌是否是允許進入的那個號碼牌(next == owner),如果是,進入臨界區,否者spin(不斷的獲取owner的值,判斷是否等於自己的號碼牌,對於ARM64處理器而言,可以使用WFE來降低功耗)。
注意:(1)是取值,(2)是更新並寫回,因此(1)和(2)必須是原子操作,中間不能插入任何的操作。
線程調用spin_unlock離開臨界區,執行owner++,表示下一個線程可以進入。
RW spin lcok和seq lock都類似spin lock,它們都是基於一個memory中的共享變量(對該變量的訪問是原子的)。我們假設系統架構如下:

當線程在多個cpu上爭搶進入臨界區的時候,都會操作那個在多個cpu之間共享的數據lock(玫瑰色的block)。cpu 0操作了lock,爲了數據的一致性,cpu 0的操作會導致其他cpu的L1中的lock變成無效,在隨後的來自其他cpu對lock的訪問會導致L1 cache miss(更準確的說是communication cache miss),必須從下一個level的cache中獲取,同樣的,其他cpu的L1 cache中的lock也被設定爲invalid,從而引起下一次其他cpu上的communication cache miss。
RCU的read side不需要訪問這樣的“共享數據”,從而極大的提升了reader側的性能。
2、reader和writer可以併發執行
spin lock是互斥的,任何時候只有一個thread(reader or writer)進入臨界區,rw spin lock要好一些,允許多個reader併發執行,提高了性能。不過,reader和updater不能併發執行,RCU解除了這些限制,允許一個updater(不能多個updater進入臨界區,這可以通過spinlock來保證)和多個reader併發執行。我們可以比較一下rw spin lock和RCU,參考下圖:
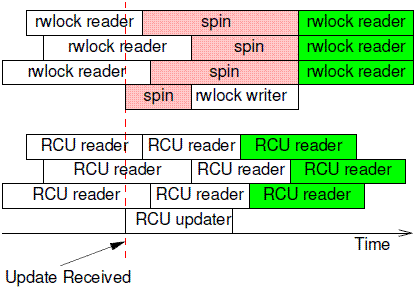
rwlock允許多個reader併發,因此,在上圖中,三個rwlock reader愉快的並行執行。當rwlock writer試圖進入的時候(紅色虛線),只能spin,直到所有的reader退出臨界區。一旦有rwlock writer在臨界區,任何的reader都不能進入,直到writer完成數據更新,立刻臨界區。綠色的reader thread們又可以進行愉快玩耍了。rwlock的一個特點就是確定性,白色的reader一定是讀取的是old data,而綠色的reader一定獲取的是writer更新之後的new data。RCU和傳統的鎖機制不同,當RCU updater進入臨界區的時候,即便是有reader在也無所謂,它可以長驅直入,不需要spin。同樣的,即便有一個updater正在臨界區裏面工作,這並不能阻擋RCU reader的步伐。由此可見,RCU的併發性能要好於rwlock,特別如果考慮cpu的數目比較多的情況,那些處於spin狀態的cpu在無謂的消耗,多麼可惜,隨着cpu的數目增加,rwlock性能不斷的下降。RCU reader和updater由於可以併發執行,因此這時候的被保護的數據有兩份,一份是舊的,一份是新的,對於白色的RCU reader,其讀取的數據可能是舊的,也可能是新的,和數據訪問的timing相關,當然,當RCU update完成更新之後,新啓動的RCU reader(綠色block)讀取的一定是新的數據。
3、適用的場景
我們前面說過,每種鎖都有自己的適用的場景:spin lock不區分reader和writer,對於那些讀寫強度不對稱的是不適合的,RW spin lcok和seq lock解決了這個問題,不過seq lock傾向writer,而RW spin lock更照顧reader。看起來一切都已經很完美了,但是,隨着計算機硬件技術的發展,CPU的運算速度越來越快,相比之下,存儲器件的速度發展較爲滯後。在這種背景下,獲取基於counter(需要訪問存儲器件)的鎖(例如spin lock,rwlock)的機制開銷比較大。而且,目前的趨勢是:CPU和存儲器件之間的速度差別在逐漸擴大。因此,那些基於一個multi-processor之間的共享的counter的鎖機制已經不能滿足性能的需求,在這種情況下,RCU機制應運而生(當然,更準確的說RCU一種內核同步機制,但不是一種lock,本質上它是lock-free的),它克服了其他鎖機制的缺點,但是,甘蔗沒有兩頭甜,RCU的使用場景比較受限,主要適用於下面的場景:
(1)RCU只能保護動態分配的數據結構,並且必須是通過指針訪問該數據結構
(2)受RCU保護的臨界區內不能sleep(SRCU不是本文的內容)
(3)讀寫不對稱,對writer的性能沒有特別要求,但是reader性能要求極高。
(4)reader端對新舊數據不敏感。
三、RCU的基本思路
1、原理
RCU的基本思路可以通過下面的圖片體現:
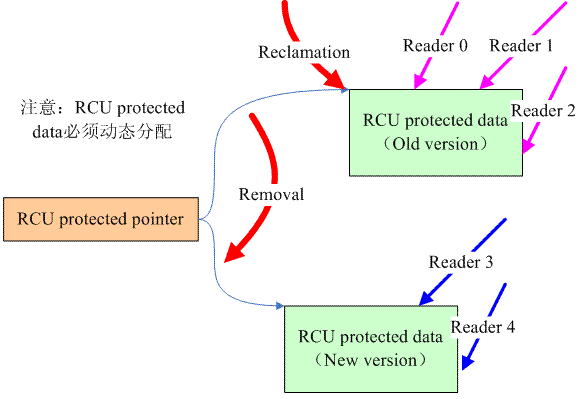
RCU涉及的數據有兩種,一個是指向要保護數據的指針,我們稱之RCU protected pointer。另外一個是通過指針訪問的共享數據,我們稱之RCU protected data,當然,這個數據必須是動態分配的 。對共享數據的訪問有兩種,一種是writer,即對數據要進行更新,另外一種是reader。如果在有reader在臨界區內進行數據訪問,對於傳統的,基於鎖的同步機制而言,reader會阻止writer進入(例如spin lock和rw spin lock。seqlock不會這樣,因此本質上seqlock也是lock-free的),因爲在有reader訪問共享數據的情況下,write直接修改data會破壞掉共享數據。怎麼辦呢?當然是移除了reader對共享數據的訪問之後,再讓writer進入了(writer稍顯悲劇)。對於RCU而言,其原理是類似的,爲了能夠讓writer進入,必須首先移除reader對共享數據的訪問,怎麼移除呢?創建一個新的copy是一個不錯的選擇。因此RCU writer的動作分成了兩步:
(1)removal。write分配一個new version的共享數據進行數據更新,更新完畢後將RCU protected pointer指向新版本的數據。一旦把RCU protected pointer指向的新的數據,也就意味着將其推向前臺,公佈與衆(reader都是通過pointer訪問數據的)。通過這樣的操作,原來read 0、1、2對共享數據的reference被移除了(對於新版本的受RCU保護的數據而言),它們都是在舊版本的RCU protected data上進行數據訪問。
(2)reclamation。共享數據不能有兩個版本,因此一定要在適當的時機去回收舊版本的數據。當然,不能太着急,不能reader線程還訪問着old version的數據的時候就強行回收,這樣會讓reader crash的。reclamation必鬚髮生在所有的訪問舊版本數據的那些reader離開臨界區之後再回收,而這段等待的時間被稱爲grace period。
順便說明一下,reclamation並不需要等待read3和4,因爲write端的爲RCU protected pointer賦值的語句是原子的,亂入的reader線程要麼看到的是舊的數據,要麼是新的數據。對於read3和4,它們訪問的是新的共享數據,因此不會reference舊的數據,因此reclamation不需要等待read3和4離開臨界區。
2、基本RCU操作
對於reader,RCU的操作包括:
(1)rcu_read_lock,用來標識RCU read side臨界區的開始。
(2)rcu_dereference,該接口用來獲取RCU protected pointer。reader要訪問RCU保護的共享數據,當然要獲取RCU protected pointer,然後通過該指針進行dereference的操作。
(3)rcu_read_unlock,用來標識reader離開RCU read side臨界區
對於writer,RCU的操作包括:
(1)rcu_assign_pointer。該接口被writer用來進行removal的操作,在witer完成新版本數據分配和更新之後,調用這個接口可以讓RCU protected pointer指向RCU protected data。
(2)synchronize_rcu。writer端的操作可以是同步的,也就是說,完成更新操作之後,可以調用該接口函數等待所有在舊版本數據上的reader線程離開臨界區,一旦從該函數返回,說明舊的共享數據沒有任何引用了,可以直接進行reclaimation的操作。
(3)call_rcu。當然,某些情況下(例如在softirq context中),writer無法阻塞,這時候可以調用call_rcu接口函數,該函數僅僅是註冊了callback就直接返回了,在適當的時機會調用callback函數,完成reclaimation的操作。這樣的場景其實是分開removal和reclaimation的操作在兩個不同的線程中:updater和reclaimer。
以上轉自:http://www.wowotech.net/kernel_synchronization/rcu_fundamentals.html
以下使用內核input子系統來介紹其具體應用:
static void evdev_events(struct input_handle *handle,
const struct input_value *vals, unsigned int count)
{
struct evdev *evdev = handle->private;
struct evdev_client *client;
ktime_t time_mono, time_real;
time_mono = ktime_get();
time_real = ktime_mono_to_real(time_mono);
rcu_read_lock();
client = rcu_dereference(evdev->grab);
if (client)
evdev_pass_values(client, vals, count, time_mono, time_real);
else
list_for_each_entry_rcu(client, &evdev->client_list, node)
evdev_pass_values(client, vals, count,
time_mono, time_real);
rcu_read_unlock();
}