




這篇博客是在我上週NYC MachineLearning做得報告基礎上改寫而成的。內容中包括Annoy,我開源的一個高維空間求(近似)最近鄰的工具庫。在第一部分,我介紹了幾個例子,並說明向量模型是非常有用的。在第二部分,我將解釋Annoy是怎麼去找近似最近鄰的(approximate nearest neighbor queries),以及相應的算法和數據結構。
言歸正傳,我們的目的是要在一個空間找到一個已知點的最近鄰集合。我們看下圖是一個二維空間,裏面有很多點,當然現實情況,向量模型的維度會比這高很多。

我們的目標是設計一個數據結構,使我們能夠以壓線性的時間查找一個點的最鄰近點集。
我們將構建一棵樹,查詢時間在 O(log n)。這就是Annoy的原理,實際上,構建的是一個二叉樹,其中每個節點都是任意劃分的。那我們先看看如何進行一次空間劃分:

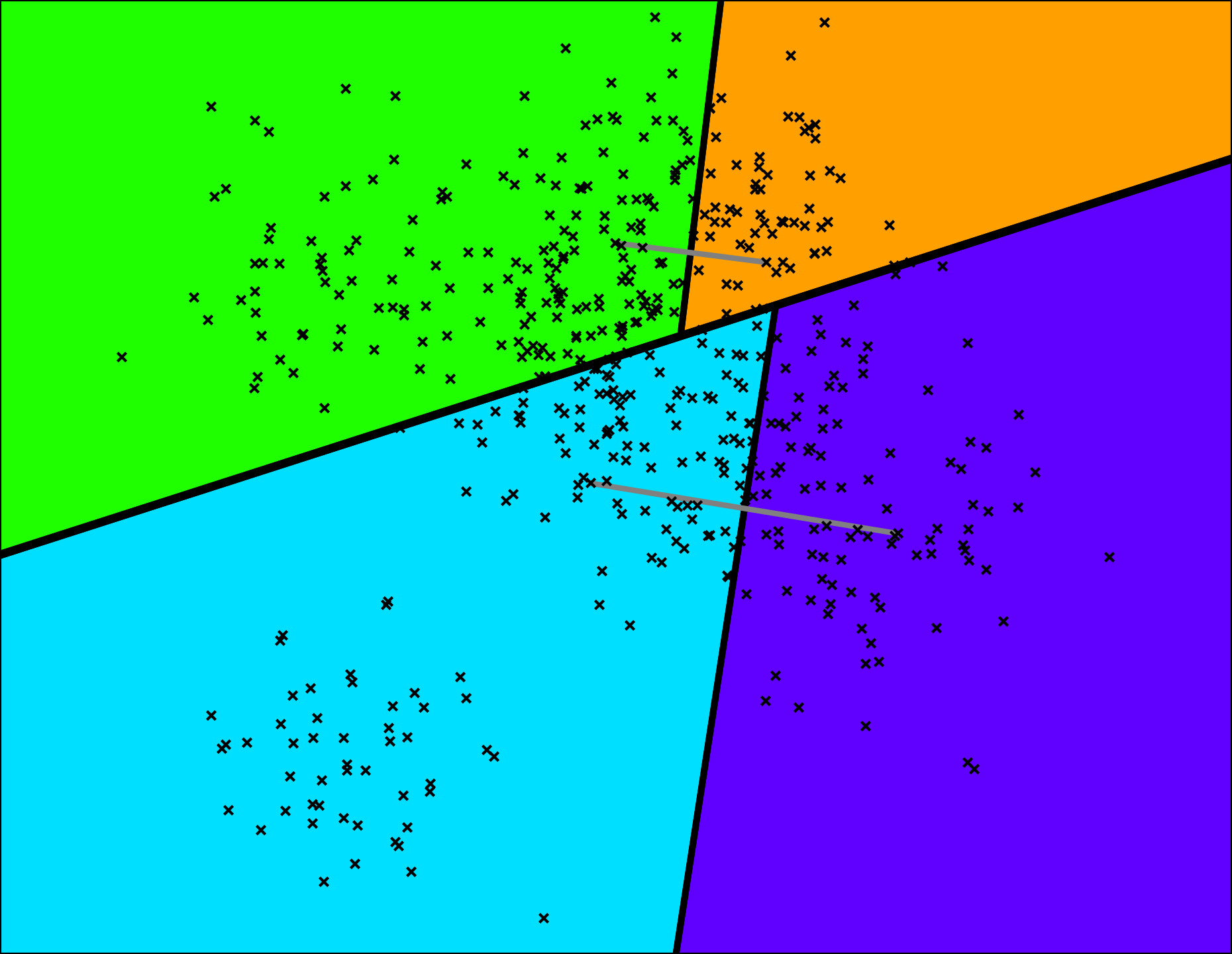
Annoy通過隨機挑選兩個點,並使用垂直於這兩個點的等距離超平面將集合劃分成兩部分。圖中灰色線是連接兩個點,超平面是加粗的黑線。
然後我們按照上述方法在每個子集上進行迭代劃分!

一個非常小的二叉樹就開始形成了:

我們繼續劃分:

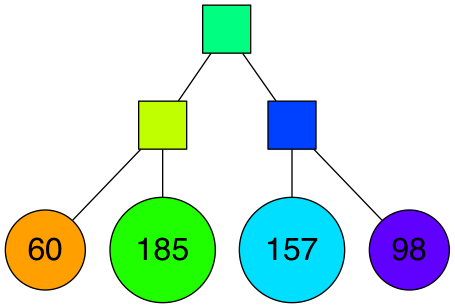
以此類推,直到每個節點最多剩下K個點。下圖是一個K=10的情況:

相應的完整二叉樹結構:

很好!最後我們得到一顆二叉樹,並且這棵樹把空間做了劃分。這樣的好處是原先空間中相鄰的點,在樹結構上也表現出相互靠近的特點。換句話說,如果兩個點在空間上相互靠近,它們也很有可能被多個超平面劃分到一起。
如果要在空間中查找鄰近點,我們只需要遍歷這個二叉樹。每個中間節點(上圖中方形節點)用超平面來定義,所以我們能夠計算出該節點的往哪個方向遍歷。搜索一個點能夠在log時間內完成,這個正好是樹的高度。
假如我們要搜索下圖中紅色X:

二叉樹的搜索路徑看上去會是這樣:

結果我們找到了7個最近鄰。非常棒,但仍然有兩個問題
1. 如果我們想找到最近鄰數目大於7,該怎麼辦?
2. 有些最近鄰在我們遍歷的葉子節點的外面
技巧1——使用優先隊列
這個技巧是,如果一個劃分的兩邊“靠得足夠近”(量化方式在後面介紹),我們就兩邊都遍歷。這樣就不只是遍歷一個節點的一邊,我們將遍歷更多的點:

與之對應的二叉樹遍歷路徑:

我們可以設置一個閾值,用來表示是否願意搜索劃分“錯”的一遍。如果設置爲0,我們將總是遍歷“對”的一片。但是如果設置成0.5,就按照上面的搜索路徑。
這個技巧實際上是利用優先級隊列,依據兩邊的最大距離。好處是我們能夠設置比0大的閾值,逐漸增加搜索範圍。
技巧2——構建一個森林
第二個技巧是構建多棵樹即森林。每棵樹都是按照任意劃分構建。我們將同時搜索所有的樹:

我們能夠用一個優先級隊列,同時搜索所有的樹。這樣有另外一個好處,搜索會聚焦到那些與已知點靠得最近的那些樹——能夠把距離最遠的空間劃分出去。
每棵樹都包含所有的點,所以當我們搜索多棵樹的時候,將找到多棵樹上的多個點。如果我們把所有的搜索結果的葉子節點都合在一起,那麼得到的最近鄰就非常符合要求。

按照這個方法,我們最後找到一個鄰近的集合。你可能會注意到,到目前爲止,我們都沒有提到如何計算點點之間的距離。下一步是計算所有的距離和對點進行排序。

我們根據點距離進行排序,然後返回K個最相近的點。很好!這就是Annoy算法的工作原理。
還是有一個問題,我們實際上仍然丟掉了一些點:

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
但是正如Annoy中的A,代表了近似(approximate),其實少一些點也是可以接受的。Annoy在實際使用的時候,提供了一種機制可以調整(搜索k),你能夠根據它來權衡性能(時間)和準確度(質量)。
近似算法的主要思想是通過犧牲一點準確度換取性能的巨大提升(數量級的)。舉例來說,我們能夠得到一個不錯的搜索結果,僅僅是計算1%的點之間的距離——卻可以帶來100倍相比於窮盡搜索的性能。
樹越多效果越好。通過增加樹,你更有可能找到你想要的劃分。一般來說,只要不超過內存,你可以增加越多越好。
Annoy算法總結:
預處理時間:
1. 構建一批二叉樹。每棵樹都按照隨機超平面迭代劃分。
Query time:
查詢時間
1. 插入每棵樹到優先級隊列
2. 搜索優先隊列中的所有樹,直到得到k個候選點
3. 對候選點去重
4. 計算候選點與已知點之間的距離
5. 對候選得到的距離進行排序
6. 返回最近的那幾個鄰近點
如果你感興趣,請查閱頭文件annoylib.h中的_make_tree和_get_all_nns
OK差不多講完了,如果你想獲取更多信息,請期待我的下一個分享。順便說一句,請查看這個幻燈片;另外文中的所有圖片繪製代碼,你也可以看看。
廖博森@DataSpark