




作爲一名在數據行業打拼了兩年多的數據分析師,雖然目前收入還算ok,但每每想起房價,男兒三十還未立,內心就不免彷徨不已~
兩年時間裏曾經換過一份工作,一直都是從事大數據相關的行業。目前是一家企業的BI工程師,主要工作就是給業務部門出報表和業務分析報告。
回想自己過去的工作成績也還算是不錯的,多次通過自己分析告,解決了業務的疑難雜症,領導們各種離不開。
但安逸久了總會有點莫名的慌張,所以我所在的這個崗位未來會有多大發展空間,十年之後我能成爲什麼樣的人呢?自己的收入空間還有多少?
一番惆悵之後,別再問路在何方了,於是抄起自己的“傢伙”,花了一小會時間爬了智聯招聘上BI崗位的數據信息,做了個分析。
PS:所用工具爲Python+BI
數據分析的過程如同燒一頓飯,先要數據採集(買菜),然後數據建模(配菜)、數據清洗(洗菜)、數據分析(做菜)、數據可視化(擺盤上菜)。
所以第一步,要採集/選擇數據。
一、Python爬取智聯招聘崗位信息(附源碼)
選擇智聯招聘,通過Python來進行“BI工程師”的關鍵數據信息的爬取,這裏大家也可以試着爬取自己崗位的關鍵詞,如“數據分析師”、“java開發工程師 ”等。經過F12分析調試,數據是以JSON的形式存儲的,可以通過智聯招聘提供的接口調用返回。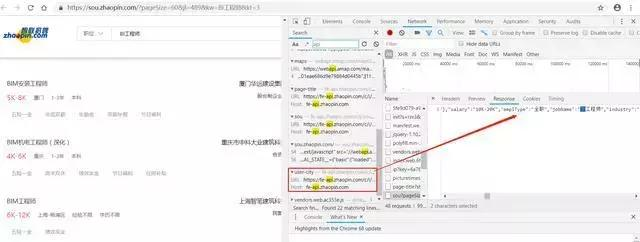
那麼我這邊通過Python對智聯招聘網站的數據進行解析,爬取了30頁數據,並且將崗位名稱、公司名稱、薪水、所在城市、所屬行業、學歷要求、工作年限這些關鍵信息用CSV文件保存下來。
附上完整Python源碼:
<pre style="-webkit-tap-highlight-color: transparent; box-sizing: border-box; font-family: Consolas, Menlo, Courier, monospace; font-size: 16px; white-space: pre-wrap; position: relative; line-height: 1.5; color: rgb(153, 153, 153); margin: 1em 0px; padding: 12px 10px; background: rgb(244, 245, 246); border: 1px solid rgb(232, 232, 232); font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: normal; letter-spacing: normal; orphans: 2; text-align: start; text-indent: 0px; text-transform: none; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; text-decoration-style: initial; text-decoration-color: initial;">import requests
import json
import csv
from urllib.parse import urlencode
import time
def saveHtml(file_name,file_content): #保存conten對象爲html文件
with open(filename.replace('/','')+'.html','wb') as f:
f.write(file_content)
def GetData(url,writer):#解析並將數據保存爲CSV文件
response= requests.get(url)
data=response.content
saveHtml('zlzp',data) #保存html文件
jsondata=json.loads(data)
dataList=jsondata['data']['results']
print(jsondata)
for dic in dataList:
jobName=dic['jobName'] #崗位名稱
company=dic['company']['name'] #公司名稱
salary=dic['salary'] #薪水
city=dic['city']['display'] #城市
jobtype = dic['jobType']['display'] #所屬行業
eduLevel=dic['eduLevel']['name'] #學歷要求
workingExp=dic['workingExp']['name'] #工作經驗
print(jobName,company,salary,city,jobtype,eduLevel,workingExp)
writer.writerow([jobName,company,salary,city,jobtype,eduLevel,workingExp])
param={ 'start':0,
'pageSize':60,
'cityId':489,
'workExperience':-1,
'education':-1,
'companyType': -1,
'employmentType': -1,
'jobWelfareTag': -1,
'kw': 'BI工程師', #搜索關鍵詞,可以根據你需要爬取的崗位信息進行更換
'kt': 3,
'lastUrlQuery': {"p":1,"pageSize":"60","jl":"681","kw":"python","kt":"3"}
}#參數配置
pages=range(1,31)#爬取1-30頁數據
out_f = open('test.csv', 'w', newline='')
writer = csv.writer(out_f)
writer.writerow(['jobName','company','salary','city','jobtype','eduLevel','workingExp'])
for p in pages: #自動翻頁
param['start']=(p-1)*60
param['lastUrlQuery']['p']=p
url = 'https://fe-api.zhaopin.com/c/i/sou?' + urlencode(param)
GetData(url,writer)
time.sleep(3)#間隔休眠3秒,防止IP被封
print(p)
out_f.close()
</pre>
經過一番編譯調試,代碼成功運行。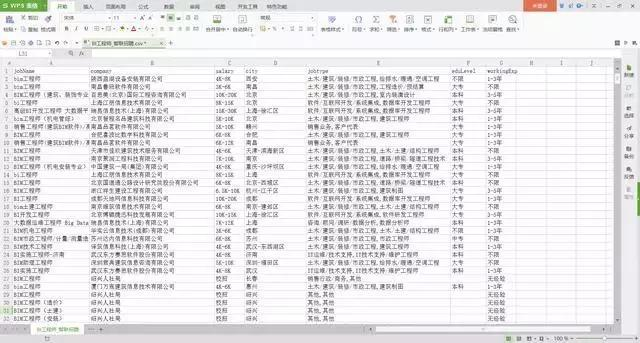
全部數據爬取完畢,一共1800條,保存在本地CSV文件中。
數據是爬到了,具體我想了解哪些信息呢:各城市的BI崗位需求情況以及薪資水平;薪水隨工作經驗的漲幅情況,以及有哪些具體的高薪崗。
由此可見,想要分析的角度很多,且看了源數據,還要做不少的數據處理。最簡單快速出可視化的方法自然是用BI工具,來對數據做簡單清洗加工,並呈現可視化。
BI能應付絕大多數場景的數據分析,尤其擅長多維數據切片,不需要建模;甚至數據清洗環節也能放在前端,通過過濾篩選、新建計算公式等來解決。最後呈現可視化,並可設計數據報告。
這裏我用FineBI來做這樣一份分析。
FineBI做分析大體是這樣的流程:連接/導入數據——數據處理/清洗(過濾、篩選、新增公式列)——探索式分析——數據可視化——出報告。
二、數據清洗加工
1.薪水上下限分割:
將CSV文件數據導入FineBI中(新建數據鏈接,建立一個分析業務包,然後導入這張excel表)。因爲薪水是以xxK-xxk(還有一些類似校招/薪資面議的數據)的形式進行存儲的,我這邊使用FineBI新增公式列(類似excel函數)將這些字符進行分割:
薪水下限(數值):left( indexofarray ( split (salary,"-") ,1),find( "K",INDEXOFARRAY( split(salary,"-") ,1))-1)
薪水上限(含K字符):right ( indexofarray( split(salary,"-") ,2),len(salary)- find("K",indexofarray(split(salary,"-"),2 ) ) )
薪水上限(數值):left( 薪水上限(文本),find("K",薪水上限(文本))-1 )
這樣就得到每個崗位的數值格式的薪水區間了: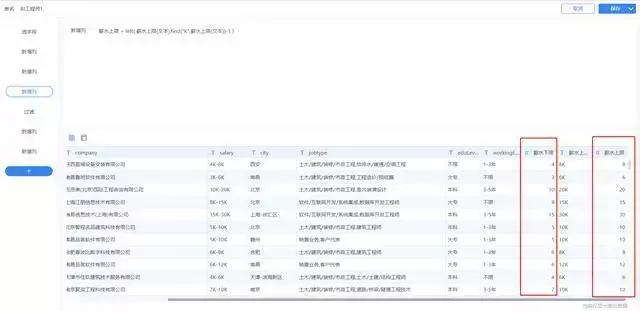
2.髒數據清洗:
瀏覽了一下數據,沒有大問題,但是發現裏面有一些類似BIM工程師的崗位信息,這些應該都是土木行業的工程師,這邊我直接過濾掉即可(不包含“BIM”且不包含“bim”)。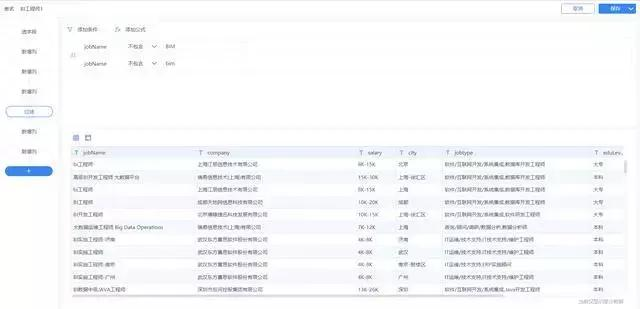
3.崗位平均數據計算
再新增列,平均薪水=(薪水下限+薪水上限)/2,即可得到每個崗位的平均薪水。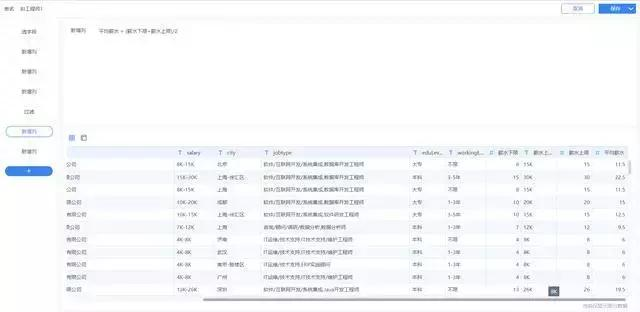
4.真實城市截取
由於城市字段存儲有的數據爲“城市-區域”格式,例如“上海-徐彙區”,爲了方便分析每個城市的數據,最後新增列“城市”,截取“-”前面的真實城市數據。
城市:if(find("-",city)>0 , left(city, find("-",city)-1 ),city)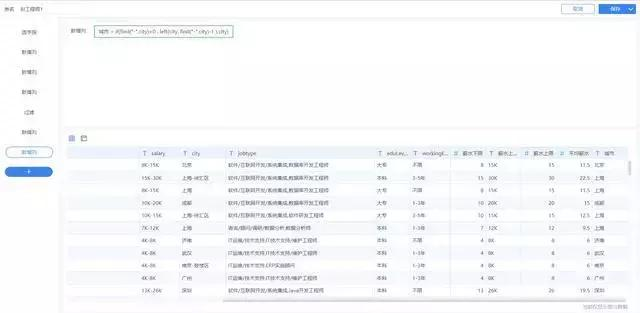
至此,18000多條數據差不多清洗完畢,食材已經全部準備好,下面可以正式開始數據可視化的美食下鍋烹飪。
三、數據可視化
數據可視化可以說是很簡單了,拖拽要分析的數據字段即可。
但是這裏用finebi分析要理解一個思路。常規我們用excel做分析或者說做圖表,是先選用鑽則圖表然後設定系列、數值。這裏沒有系列和數值的概念,只有橫軸和豎軸。拖入什麼字段,該字段就以該軸進行擴展,至於圖表嘛,finebi會自動判別推薦。
我這邊以各城市平均薪水/崗位數量分析爲例給大家簡單展示FineBI的可視化呈現過程。
1、橫軸以“城市”字段擴展,展現兩類數據。先是薪水值,拖拽到縱軸,默認對數值類的字段是彙總求和的。點擊字段可直接對改字段修改計算、過濾等操作。
此圖來自官網,圖中數據不是本次分析的數據,僅供參考
2、然後分析每個城市BI崗位的情況。將數據記錄數這個指標拖入到縱軸展示。同樣的方式,可以修改字段名。這裏爲了區分兩者,將其修改爲折線圖,並且倒敘展示。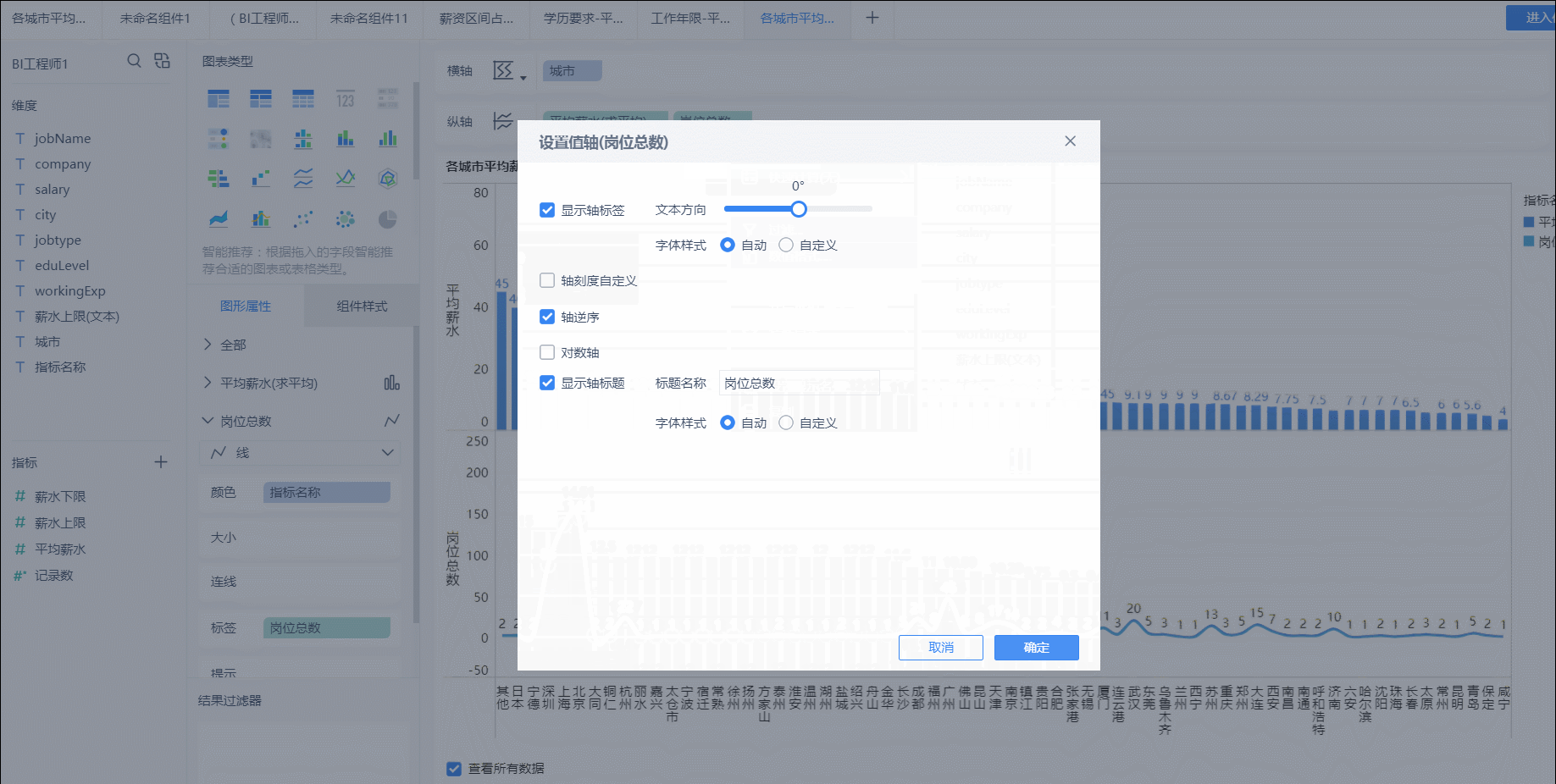
同理,其他圖表也是這樣的操作,想清楚展現什麼樣的數據,怎樣展現,數據要作何處理。就得心應手了。其他圖表就不一一贅述了。
最後,大概花了15分鐘,一份完整的智聯招聘網站-BI工程師崗位數據分析的可視化報告就製作完成啦~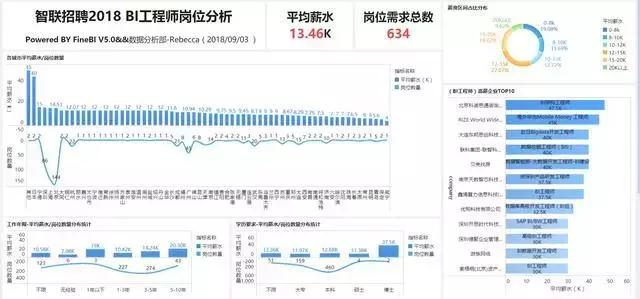
審美有限,只能做成這樣,其實這個FineBI還能做出這樣的效果。

四、分析結果
1.目前BI工程師崗位在智聯招聘網站的平均薪資爲13.46K(痛哭。。。拉低平均薪水的存在),主要薪水區間大概在12-15K(佔比27.07%),相關工作需求總數爲634個(僅僅爲某一天的招聘需求數據)。
2.從城市崗位需求數量分佈來看,BI工程師需求主要集中在北京、上海、深圳、廣州區域;各城市BI工程師平均薪水方面,去除崗位需求量較少的城市來看,國內排在前面的分別爲深圳(14.72K)、上海(14.59K)、北京(14.51)、杭州(12.07K)、成都(11.13K)、廣州(10.94K)。
3.從工作年限的平均薪水和崗位需求數量來看,工作5-10年的資深BI工程師的平均薪水可以達到20K以上(朝資深BI工程師方向奮鬥!!!1年以下年限的計算出來的平均薪水雖然爲19K,但是由於樣本量只有3個,所以參考意義不大),其中大部分的工作需求年限爲3-5年,平均薪水爲14.24K。
4.從學歷方面來看,最低學歷需求主要以本科/大專爲主,本科和大專學歷要求的平均薪資分別爲12.68K和11.97K(感覺差距並不大,過硬的技術實力可能纔是企業最爲看重的吧),博士和碩士學歷需求很少。
5.看了一些高薪的招聘企業,最高的可以給到30K~40K的薪酬水平,其中主要是互聯網、IT類公司爲主。
好啦,以上就是我的分享,如果你跟我一樣都喜歡python,想成爲一名優秀的程序員,也在學習python的道路上奔跑,歡迎你加入python學習羣:839383765 羣內每天都會分享最新業內資料,分享python免費課程,共同交流學習,讓學習變(編)成(程)一種習慣!