




任何可以傳輸IP報文的技術,都可以用於組建Calico網絡的交換結構,比如MPLS和以太網技術。
1 經典以太網在規模上遇到瓶頸
近些年業界的一個共識:當網絡達到一定規模,經典以太網絡已經不適合在生產環境部署了。大規模網絡以太網故障的主要原因是:
- 大量的終端(end points)。每一個以太網交換機,必須學習去往同一個廣播域內所有終端的路徑,當終端的數量是帶到十萬級規模,就會成爲一個十分困難的任務。
- 網絡中高頻率的翻動(churn)。私有云網絡中大部分的終端是臨時性的(比如虛機或者容器),存在大量的翻動(批量創建、刪除虛擬機/容器,以及遷移帶來的重複地址學習),學習這些路徑信息會對大部分以太網交換機的控制平面處理機造成嚴重負擔。
- 大量的廣播流量。以太網中的終端依靠廣播包去發現對等體及實現其他目的,這將導致每個數據包都會被複制給其它終端,造成廣播風暴。
- 生成樹。生成樹是在以太網中防止環路的一種協議。它是在網絡規模很小結構很簡單的時代被設計出來。隨着以太網絡中鏈路和互聯關係的增長,生成樹協議變得十分脆弱。當以太網中的生成樹失效時,將引起災難性的結果,且難以排除和解決。
2 Calico如何改變經典以太網運行方式
Calico是如何被應用在二層以太網互聯網絡中的。最重要的是:以太網中是看不到直連IP路由器另一端的任何東西,它只能看到路由器自身。這就是爲什麼以太網交換機被ISP連接客戶使用:客戶處於一個與ISP互聯的一個二層網絡,只能看到ISP的路由器,而看不到其它任何ISP客戶的節點。在Calico中有類似的作用。
爲了解決第1節提到的問題,我們在Calico環境下重新討論這些問題:
- 大量的終端(end points)。在Calico網絡中,以太網互聯網絡只能看到路由器/宿主服務器,而不是真正的終端(VM/容器)。這樣,在一個每臺服務器中存在數十個VMs(或者幾百個容器)的標準雲模型裏,以太網看到(需要去學習的)的節點數量減少了一到兩個數量級。甚至在一個非常大的Pod中(號稱兩萬臺服務器),以太網絡仍舊只需要學習幾萬個終端路徑。這是在每個TOR交換機能力範圍內的數量。
- 網絡中高速的翻動(churn)。經典以太網數據中心中,一個終端被創建、銷燬或者移動都會觸發一次翻動事件。一個數十萬終端大型數據中心,翻動事件的平均值是每秒發生數十次,而峯值可以達到每秒可數萬次。而在Calico網絡中,翻動是非常低的。只有在服務器、交換機或者物理鏈路的增加和減少時,纔會導致一次翻動事件。
- 大量的廣播流量。由於在Calico網絡中的任何流量的第一跳(也是最後一跳)都是一個IP跳轉,IP 跳轉終止了廣播流量。實際上,在以太網結構中能夠唯一看到的廣播流量是宿主服務器之間彼此定位的ARPs。
- 生成樹。根據以太網結構架構選擇的不同,甚至可以關閉生成樹協議。然而,隨着節點數量的減少,翻轉事件的減少,大部分生成樹的實施都可以在負載允許範圍內執行。
綜上,在二層以太網互聯網上運行Calico網絡,是可行並且實用的。
二層以太網互聯和三層IP互聯都可以作爲Calico網絡實施基礎,不同的是二層以太網互聯則更沒有那麼多架構方面的因素需要考慮,而三層IP互聯需要考慮的更多。
3 關於以太網拓撲的簡要說明
本文以最常見的Spine/Leap二層以太網結構加以說明。
Calico是IP路由互聯結構,可以使用ECMP在多條鏈路上負載分發流量(而不是使用如M-LAG等以太網技術)。憑藉Calico宿主機上的ECMP負載均衡,僅需要在Calico節點運行IP路由(不需要引入其他技術),就能構建由多個獨立leaf/spine平面組成的互聯結構。這些平面可以完全獨立運行,而不用共享同一個故障域。這將允許一個(或多個)平面以太網互連結構發生災難性故障時,不會損失整個pod(故障只會減少pod的互連帶寬),這是一種比起整個Pod範圍發生IP或者以太網故障來說相對溫和的故障情況。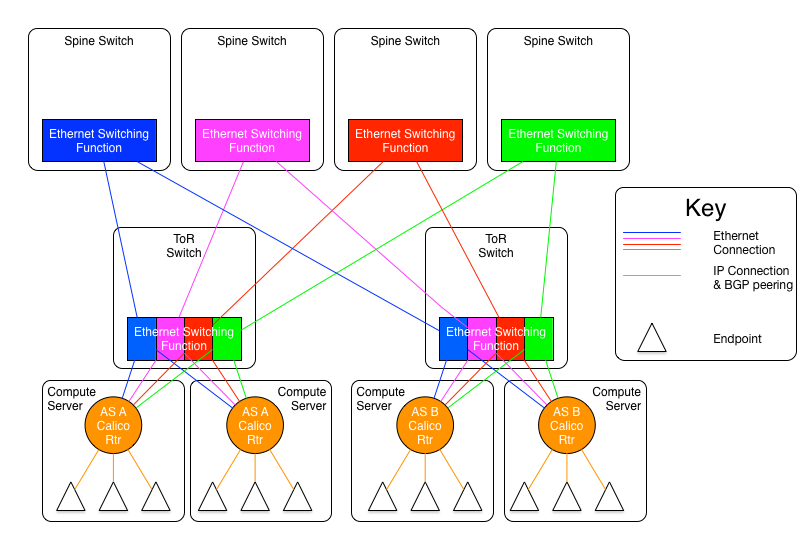
在上圖所示模型中,endpoints對互聯結構上發生的任何事情都無從感知。
在上圖所示模型中,ToR被分成了四個邏輯交換機(使用VLAN),每臺宿主機到ToR上的每個邏輯交換機都一條連接。我們使用藍、綠、橙、紅四種不同的顏色去標識這些邏輯交換機。每個顏色的邏輯交換機都是該顏色平面的成員,所以對應就有藍、綠、橙、紅四個平面。每個平面都有一個專用的spine交換機,每個ToR上對應顏色的邏輯交換機都會與相同顏色的spine交換機相連,不同顏色的邏輯交換機與spine交換機之間沒有連接關係。
每個平面都是形成一個IP網絡,藍色平面可能是2001:db8:1000::/36,綠色平面可能是2001:db8:2000::/36,橙色和綠色則是2001:db8:3000::/36和2001:db8:4000::/36。
每個IP網絡(交換平面)需要它自己的BGP路由反射器。同一平面內的路由反射器之間需要建立對等體關係,而不同平面的反射器則不需要。所以,四個平面組成的互聯結構應該有四個全互聯的路由反射器組。每個宿主機,邊界路由器及其他三層設備,要求成爲每個平面內至少一個路由發射器的客戶端,最好是2個或者更多。
下圖顯示了路由反射器環境的互聯結構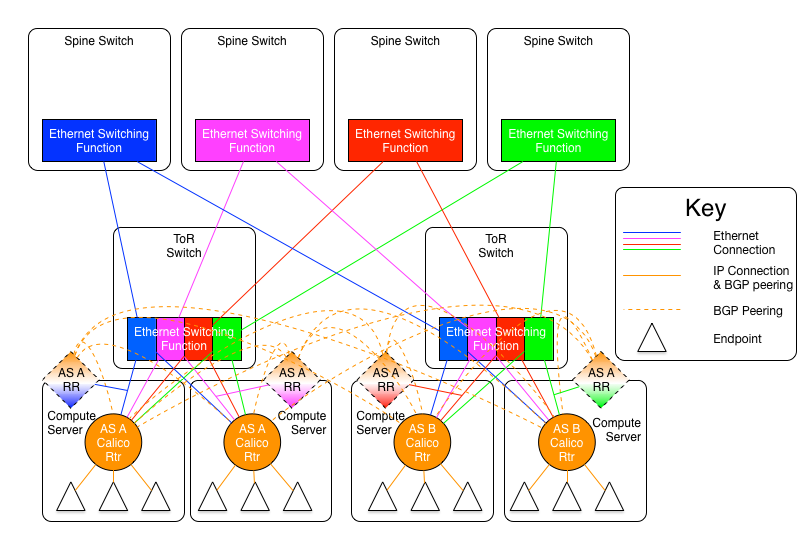
這些路由反射器可以是連接到spine交換機的專門的硬件(或者spine交換機自己啓用路由反射器服務),也可以是連接到邏輯leaf交換機的物理/虛擬路由反射器。它可能是一個運行在宿主機上,擁有直連到當前平面連接的路由反射器,並且它不能通過vRouter進行路由,避免先有蛋還是先有雞的問題。
當然還存在其他的物理和邏輯方案,這裏僅僅是一個可行的例子。
邏輯配置使每個宿主機在每個平面的IP網絡中都有一個IP地址,並在每個IP網絡上宣告自己的endpoines。如果開啓了ECMP,那麼宿主機將使用所有平面進行流量的負載分擔。
如果一個平面失效(如生成樹故障),那麼只會有一個平面停止轉發,其餘平面將繼續正常運行。