




Calico在橫向擴展或者雲環境中,提供了數據終端(endpoint,後面直接使用英文原文)之間端到端的IP互連網絡。爲了做到這一點,它需要一個互連結構(interconnect fabric)爲Calico的運行提供物理網絡層連通性。
注:這個互連結構提供了Calico vRouter(大部分情況下是服務器,後稱爲宿主機)節點之間的連通性,以及vRouter和結構中其它設備(比如,其他物理服務器,邊界路由器和應用程序等)的連通性。
雖然Calico被設計成可以與任何支持IP流量的底層互聯結構協同工作,但是需要考慮事項最小的架構卻是之前討論過的以太網結構(Ethernet Fabric)。
在大部分情況下,以太網結構是一個合適的選擇,但是當L3(一個IP 網絡)已經被部署或者將要被部署的環境中,運行Calico就變得意義了。
Calico本身就是一個路由基礎設施,儘管當它運行在一個IP路由互聯結構中時,需要考慮更多的工程、架構和運行注意事項等諸多問題。但是,通過我們後面的介紹,你會發現Calico在IP互聯結構中的表現與在以太網結構中的同樣出色。
1 背景
1.1 Calico架構概述
在Calico網絡中,每一臺宿主機對於本身承載的endpoint來說都是一臺路由器,我們稱其爲vRouter 。Linux內核爲它提供數據路徑,BGP協議提供控制平面服務,Calico的服務代理Felix負責管理平面的工作。
每個endpoint只能通過本地vRouter與外界建立通訊連接,任何Calico數據包路由第一跳和最後一跳都要經過vRouter。每個vRouter使用BGP協議將本地所有endpoints宣告給其他vRouter,以及物理網絡,這個過程中經常會用到路由反射器去增加彈性。
訪問控制列表及其他增強安全策略,和另外一些Calico架構組件,因爲和互聯網絡架構無關,故不在本文討論範圍之內。
1.2 常見的IP擴展結構架構綜述
到目前爲止,使用IP結構構建可擴展基礎設施的方法有兩種,這兩種方法都將機櫃交換機(ToR Switch,後面簡稱爲ToR)視作基礎網絡中的邊界路由器。而在Calico網絡中,邊界路由器的功能被降到宿主機。
另外,在目前大部分虛擬環境中,工作狀態的endpoint均不能被底層物理網絡(underlay,後使用英文原文)尋址。如果endpoint是一個VM,會被封裝到上層網絡中(overlay,後面使用英文原文),如果endpoint是一個容器(container,後面使用英文原文),它可能被封裝到overlay,也可能被一些代理NAT處理,比如Weave網絡模型,或者標準docker網絡中的路由器。
下面是對兩種方法描述,我們在本文中將只討論第二種方法,因爲它更爲常見。
- 基於某種IGP的路由基礎設施。因爲IGP網絡規模的限制(參見《爲什麼Calico只是用BGP作爲互連協議》一文中關於這個話題的討論) ,Calico項目組不認爲IGP協議路由分發能力可以支撐Calico環境承載endpoints的數量規模。然而,這種方法可能是在互聯結構中將IGP和BGP混合使用,IGP負責下一跳路由器(在Calico中經常是宿主機)的可達性,BGP用於分發endpoint的路由信息。這是一個有效的模型,並且在大部分運營商骨幹網絡中被採用。這些網絡的設計有些複雜,本文不予討論。
- 完全基於BGP的路由基礎設施。在這個模型中,IP網絡要求足夠緊湊的或者半徑足夠小,這樣BGP就可以被用來分發endpoints路由,並且這些路由的下一跳路徑是被網絡中所有路由器知道的(包括物理網絡中三層設備以及Calico網絡的宿主機)
1.3 只運行BGP的互聯結構
構建純BGP互聯架構網絡有多種方法。我們將關注三個模型,以及每個模型的兩個常見變體。
其中兩個模型是:
- 每個ToR及其下聯宿主機使用一個唯一的自治系統號(
AS Number),ToR之間可以使用spine交換機提供的以太網交換平面互聯(假設這是一個Leaf/spine結構),或者通過一組使用不同AS號的spine交換機互聯,我們稱其爲“AS Per Rack”(每機櫃獨立AS)模型。這個模型的細節在IETF RFC 7938中有所描述。 - 另一種BGP互聯結構是:每臺宿主機使用一個唯一的AS號,ToR扮演傳輸AS的角色。我們稱這個是“AS per server”(每服務器一個AS號)模型。
每個模型都會有一個以太網或者IP spine節點。在以太網結構的spine情景,每個spine節點提供一個獨立的以太網連接平面,ToR會連接到每個spine節點上面。
而IP互聯結構的spine情景,每個spine交換機擁有一個唯一的AS號,ToR和每個spine交換機都是eBGP對等體關係。
兩種情景下,ToR都會通過ECMP充分利用與每個活躍spine交換機之間所有可用鏈路,實現均衡負載流量。
1.4 BGP網絡設計要點
與大家通常的觀念不同,BGP實際上是一個非常簡單的協議。比如,BGP在Calico宿主機上的配置信息大約只有60行(不包括註釋)。讓人覺得複雜的其實是使用BGP實現的那些具體事情。許多BGP的應用場景使用了複雜的策略規則,因爲技術、商業、金融、法規等方面的要求,BGP對數據包的默認處理行爲被修改了。而默認的Calico網絡時不會涉及這些領域的,它更專注於直接轉發。
即便如此,在Calico網絡設計一張連接各個節點的IP網絡時,BGP的一些設計規則也是需要銘記於心的,並且最好是由非常擅長高級BGP設計的人員來完成。
這些要點如下:
AS continuityAS連續性:一個AS號下的所有路由器之間的數據要求不穿越其他AS直接相互通訊。Next hop behavior下一跳行爲:默認情況下,BGP路由器在收到同一AS號對等體宣告的路由不會修改下一跳。相反,BGP路由器從不同AS號對等體收到的路由會把下一跳地址改爲自己。Router Reflection路由反射器:一個給定AS內的所有BGP路由器之間必須都建立對等體關係。這被稱爲BGP全互聯。當自治系統內路由器數量增加這可能會成爲一個問題。使用路由反射器可以減少BGP全互聯需求,但是路由反射器也存在規模和擴展的考慮Endpoints數據終端:在calico網絡每一個endpoint都是一條路由。硬件網絡平臺會受到設備路由表最大條目數的限制,這個限制通常是10000到100000條路由。路由聚合可以緩解路由條目數的壓力,但是這要依賴於調度程序所使用編排軟件的功能(例如 openstack)。
後面的附錄裏還會針對以上四點做深度討論。
1.5 每機櫃獨立自治系統模型
這個模型與IETF RFC 7938中介紹的模型最爲接近。
如前文所述,這個模型存在兩種版本,一種是使用一系列以太網平面(作爲核心)互聯所有ToR,另一種核心平面則使用三層路由域。下面兩張圖可能會對理解有所幫助
圖1.5-1:每機櫃獨立AS模型1:以太網交換互聯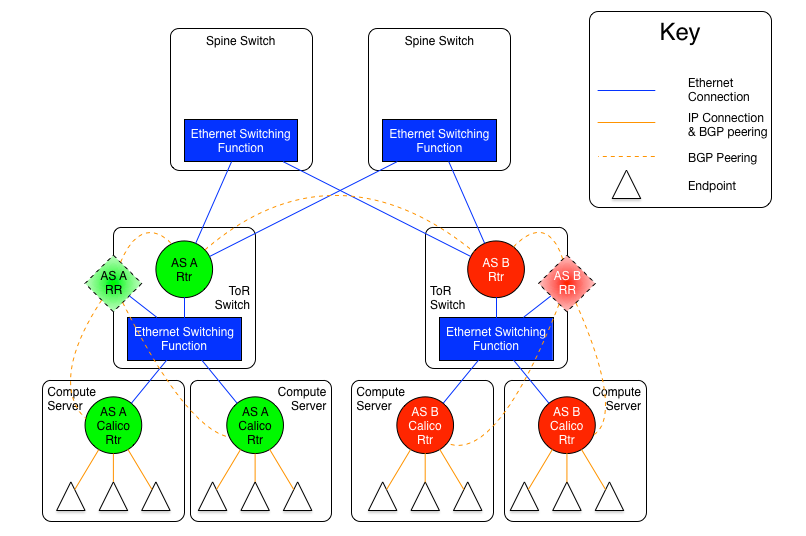
上圖顯示了每機櫃獨立AS模型之中,所有ToR,通過以太網交換平面全物理互聯的變體。
圖1.5-2:每機櫃獨立AS模型2:IP路由互聯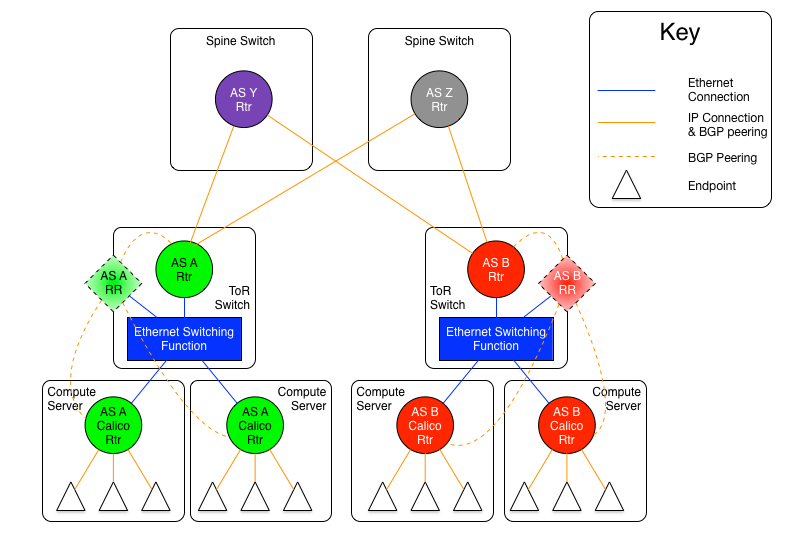
上圖顯示了每機櫃獨立AS模型之中,所有ToR通過一組各自擁有唯一AS號spine路由器使用三層路由互聯的變體。
在這個方案中,ToR與ToR之間,或者ToR與Spine(上面第二張圖的例子)之間的是EBGP對等體關係。
如果選擇spine工作在2層的版本,那麼結果就是每一個ToR必須與同一集羣內其他ToR建立對等體關係。
如果選擇spine各自擁有唯一AS號的路由版本,那麼ToR只需要與每個spine建立對等體關係(一個Pod裏通常是2個或者16個spine交換機)。但是spine交換機必須是所有ToR的對等體(再次說明,ToR的數量可能是數以百計的,但是通常spine交換機的控制平面容量要比ToR大的多,所以多數場景還是更易擴展的)。
在機櫃內,兩種變體的配置是相同的,只是ToR的北向(上聯)配置有些許差異。
在Calico網絡中,機櫃內每臺宿主機都被視爲一臺路由器,它們使用與同櫃上聯ToR相同的AS號,並且使用了ToR提供的以太網交換層直接互聯,保持了AS連續性。TOR交換機的路由功能模塊也被連接到自己提供的以太網交換層:通常ToR連接宿主機的接口被視爲屬於某個子網或者網絡分段,ToR的路由功能模塊在這些分段內也有一個單獨虛擬接口。
在本模型中,每個宿主機使用ToR的交換功能相互連接,而沒有用到TOR的路由模塊。所以,宿主機與ToR的路由模塊必須是全互聯結構,或者在機櫃中使用路由反射器,這可以在ToR交換機上開啓,或者在同機櫃一個或多個宿主機上部署虛機,承擔路由反射器的作用。
ToR作爲EBGP路由器,重分佈(或者宣告)所有來自其他ToR以及數據中心外部的路由給自己自治系統內的宿主機。同時宣告本自治系統內的路由給其他ToR和外部網絡。這就意味着每個宿主機去往外部路由的下一跳都是本機櫃ToR,而機櫃內部所有路由的下一跳都是每個具體的宿主機。
1.6 每服務器獨立AS模型
前面提到的IETF RFC 7938中假設:ToR是整個模型第一具有路由角色,且可以執行路由彙總功能的層級。而在Calico網絡中,具有路由角色的ToR也只能作爲第二個層級去實現以上功能,因爲對於一個Calico網絡中的endpoint來說,宿主機永遠都是路由過程的第一跳或者最後一跳,同時也是第一個/最後一個路由聚合點。
所以,在每服務器獨立AS架構模型中,AS的邊界是服務器而不再是ToR。下面兩張圖顯示了它們的區別。
圖1.6-1:每服務器獨立AS模型1:Spine層以太網互聯變體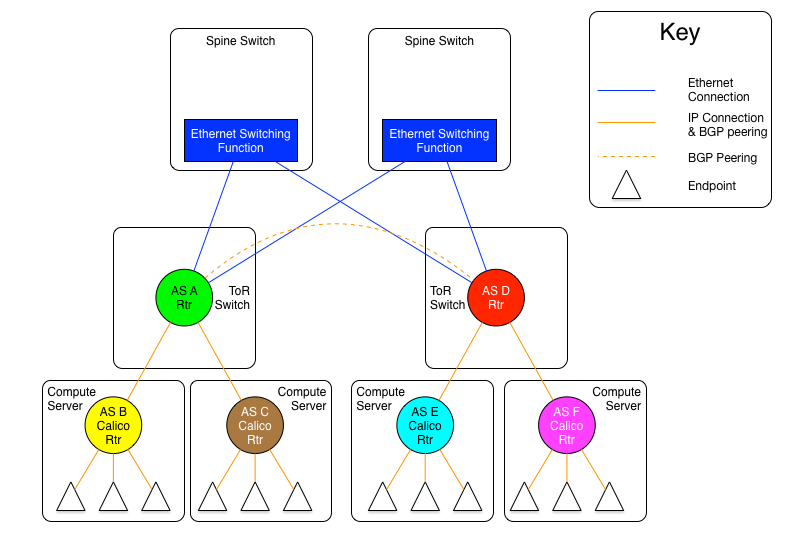
上面一張圖是每服務器獨立AS模型的其中一種變體,ToR通過一組以太網交換平面實現物理全互聯。
圖1.6-2:每服務器獨立AS模型2:Spine層IP路由互聯變體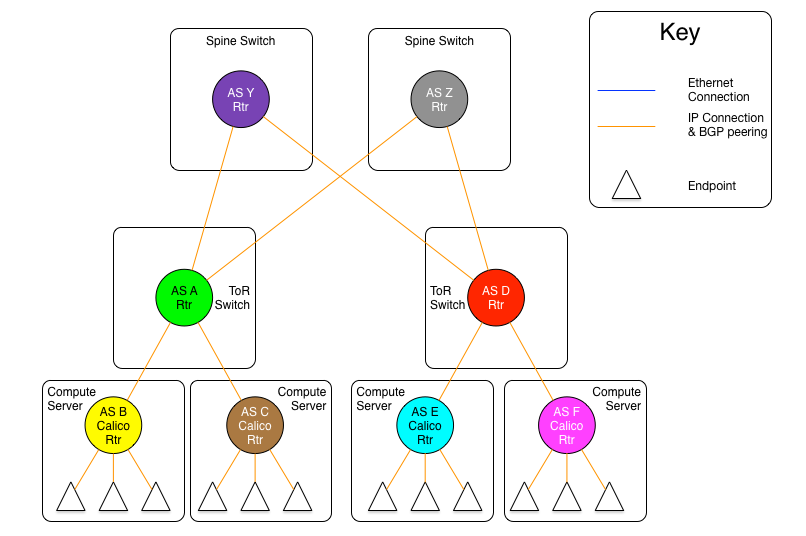
上面一張圖是每服務器獨立AS模型的另外一種變體,ToR交換機都被物理連接到一組獨立路由平面.
從這些圖中可以看到,和每機櫃獨立AS模型一樣,每服務器獨立AS模型也有兩個變體,一個是採用獨立交換平面互聯所有ToR,另一個則是通過一組獨立路由器互聯所有ToR交換機。
而它們真正的不同是,在這個模型中宿主機與ToR都是獨立的自治系統,爲了解決規模性問題,這裏使用了RFC 4893中介紹的4字節自治系統號。在不使用4字節自治系統號時,ToR和宿主機可用的AS號數量將被限制在5000個左右。而使用4字節AS號可以將這個數字增加到9200萬個,已經可以滿足Calico任何架構設計的需要了。
與每機櫃獨立AS模型相比另一個不同點是,這裏不再需要路由反射器,因爲所有的BGP對等體的類型都是EBGP。比如同機櫃的宿主機與ToR之間也是EBGP對等體關係。同機櫃兩臺服務器之間的通訊需要經過ToR路由。所以,每個服務器將同它所連接的每個ToR建立一個對等體連接,每個ToR也將對它所連接的宿主機有一個對等體連接(通常是機架中的所有宿主機)。
ToR之間的連接在規模和範圍上與每機櫃獨立AS模型相同。
1.7 下發默認路由模型
最後的模型有點不同。在前面兩個模型中,基礎結構中的路由器都攜帶完整的路由表,並且保持它們的AS路徑不變,而這個模型在路由路徑的每一跳都會刪除AS號。這是爲了防止網絡中其他節點的路由,因爲它們來自本地(路由的源和目的IP都在相同的AS中)而不被安裝到路由表中。
下圖顯示了這個模型中AS之間的關係
圖1.7:向下默認模型拓撲圖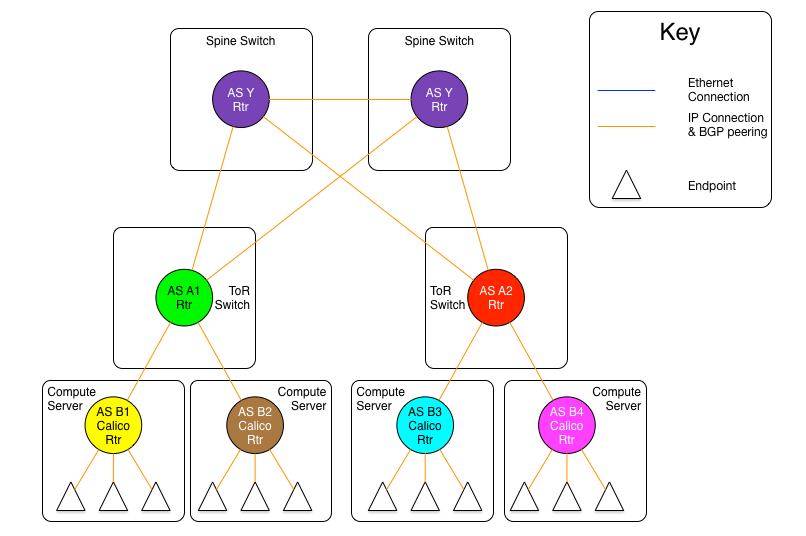
在上面的圖中,我們看到所有Calico nodes 共享相同的AS號,ToR也是一樣。但是他們的AS是不同的(A1和A1是不同的網絡,儘管它們共享AS號 A)。
所有ToR只使用一個AS號,所與宿主機使用另外一個,這樣不但簡化了配置(使用標準化的配置),而且ToR路由表壓力被卸載了。
在這個模型中,每個路由器角色宣告它的所有路由信息給上游對等體(Calico路由器宣告給ToR,ToR宣告給Spine交換機)。而反向路徑上,上游路由器只宣告默認路由給下游。這樣,一個Calico路由器只會有自己承載的endpoints的路由和一條去往ToR的默認路由。ToR是Calico網絡去往網絡中其他位置的唯一通路,這與現實環境相符。ToR交換機與Spnine交換機之間的情形也類似,ToR只需要安裝附着到它下游Calico node中的endpoints路由。即使我們每個Calico nodes上承載200個endpoints,每個機櫃部署80個Calico nodes,每個ToR的路由表條目數也會被限制在16000條(普通數據中心交換機承載這種量級的路由數是沒有壓力的)。
因爲默認路由初始是被Spine產生的,不存在Spine收到一條起源於接收方AS的默認路由的可能,防止了AS Puddling問題。
這個模型有一個小的缺點,那就是所有到無效目標地址的流量(目標IP不存在),在丟棄之前需要都被轉發到spine交換機。
需要注意的是,spine交換機仍然需要承載所有Calico網絡的路由,就像前面例子中路由架構spine所做的那樣。簡而言之,這個模型比起其他兩個沒有增加spine的負載壓力,卻大幅度減少了ToR路由表佔用空間。也減少了Calico nodes的路由數量,但是這對現在的服務器計算能力再說,不是問題,完整路由表所使用的內存量是服務器內存的很小一部分。
2 推薦意見
- Calico工程團隊建議,在考慮到了業務量增長的前提下,如果ToR和spine可以承載估算過的路由規模,那麼推薦使用“AS per rack”模型。
- 如果在ToR交換機上遇到了路由表容量的問題,建議使用“Downward Default”模型。
- 如果ToR和Spine交換機都遇到了路由表容量的問題,或者對Calico nodes僅提供簡單的L2交換網絡架構,建議參考之前文章介紹的以太網架構。
- 如果Calico用戶對“AS per compute server”模型感興趣,Calico工程團隊將非常有樂意介紹它的部署情況(但是本文中並沒有提到)
3 附錄
3.1 其他選項
在本文和之前以太網互聯的文章介紹的架構中,一條給定路由的下一跳,對收到該路由的設備來說總是直連的。這就不需要再有其他協議幫助分發下一跳路由信息。
然而,很多(可以說大部分)廣域網BGP網絡,一個給定AS中的路由器之間可能不是直連鄰居。所以,一個路由器可能收到一條路由,它的下一跳並不是自己直連的。這時候,路由器需要使用一種IGP比如OSPF或者IS-IS,去幫助確定去往BGP下一跳的路徑。
在某些Calico架構中某些類似模型中,可能的確存在一個AS中的路由器是非直連的,這時候就需要使用到IGP,但這超出了本文的範圍。
3.2 IP架構設計注意事項
3.2.1 AS puddling AS混淆
第一條注意事項是AS必須保持連續,這意味着一個給定AS的兩個node之間必須能夠直接通訊,而不需要經過任何傳輸AS.如果這個規則被打破了,影響是會導致AS混亂(AS Puddling),網絡不能正常運行。
這個注意事項的一個延伸是:任意兩個共享同一個AS號管理域,將被視爲同屬於這個AS中,儘管這不是設計者的初衷。因爲BGP除了AS號外沒有其它方式區分一個自制系統是本地的還是外部的。所以,如果不對BGP路由器實施大量策略修改,那麼兩個非直連(經過其它傳輸AS互通)卻複用同一個AS號的網絡是不能正常工作的。
另外一個延伸是BGP路由器不會將一條AS-PATH屬性中包含對等體AS號的路由 發送給該對等體。這是一種EBGP防環機制,效果是防止兩個同一自治系統內的路由器,通過一個傳輸路由器(可能是其他AS的)相互通訊。
3.2.2 Next hop behavior 下一跳行爲
另一個需要考慮的問題是iBGP和eBGP的區別。BGP有兩種運行模式,如果兩個路由器是BGP對等體,共享相同的AS號碼,那麼它們被稱爲iBGP對等體關係。如果它們使用不同的AS號碼,則被稱爲外部或者EBGP關係。
BGP的原始設計模型是:在一個給定AS內,所有BGP路由器都知道如何去往其它BGP路由器(通過靜態路由,IGP路由協議,或其他類似協議),而不同AS之間的路由器是不知道如何到達另外一個AS的,除非它們之間是直連的。
基於上面的設計原則,在一個給定AS內處於iBGP對等體關係的路由器,它們之間傳輸流量是不需要通過其他iBGP路由器的(比如,A與C之間的通訊是不需要B去路由的),所以是不需要改變BGP下一跳屬性的。(---- 譯者注:作者的觀點是建立在iBGP對等體之間全互聯結構基礎上的。)
另一方面,處於eBGP對等體關係的路由器,認爲它的eBGP鄰居不知道如何去往下一條路由,將使用它自己擁有的地址替換到原有下一跳字段的內容,這種行爲被稱爲“下一跳自我”
在Calico以太網互聯模型中,所有服務器(Calico網絡中的路由器)之間都是通過一個或者多個以太網絡直接互聯的,直連可達。因此Calico網絡中的路由器是不需要設置下一跳自我的。
在本文我們所展示的模型中,已確保所有可能通過非Calico路由器傳遞的路由都是eBGP路由,所以下一跳自我是會被自動正確設置的。但是客戶在一個IP互連網絡中部署Calico,而沒有遵從模型約束條件時,則必須確保“下一跳自我”被適當的配置。
3.2.3 Route reflection 路由反射
如上所述,BGP期望網絡中所有iBGP路由路由之間可以直接連接,這被稱爲BGP全互聯結構。如果在一個小型網絡中可能不是一個問題,但當路由器的數量不斷增加時,就變得有趣了。舉例來說,如果在一個AS內原有99臺BGP路由器在運行,現在需要新增一臺,你就不得不讓新路由器與已經存在的99臺逐一建立對等體關係。這不僅僅是配置時間的問題,而且還會極大的消耗路由器有限的資源。當只有100臺路由器的時候可能還是一個“有趣”的問題,當路由器是1000臺或者10000臺的規模呢(Calico網絡極有可能達到這種規模)?這將成爲一個不可能完成的任務。
在差不多20年前,大型互聯網規模的網絡中通過使用BGP路由反射器( 'RFC 1966' 中定義)很容易的解決了這個問題。目前這已經是被大部分BGP路由器支持的技術。在一個大型網絡中,路由反射器是合理分佈的,每個IBGP路由器都與1個或者多個(通常是2-3個)路由反射器建立對等體關係,每個路由反射器可以爲10+或者100+路由反射器客戶端(Calico網絡中就是一個服務器)提供服務,實際數量取決與所使用的反射器規格。這些路由反射器之間也是對等體體關係。這就比全互聯的結構節省很多對等體連接,每個反射器客戶端只與2-3個路由反射器客戶端建立對等體關係。這就更加容易管理了。
當然也存在其他路由反射器的架構設計,但是這些已經超出了本文的範圍。
3.2.4 Endpoints 數據終端
最後一個建議是關於Calico網絡中endpoint的數量的。在以太網互聯的場景下endpoints的規模不會受到互聯結構容量的制約,因爲互聯結構不關心活躍的endpoints,它只能看到vRouters。而且IP互聯場景下情況就不一樣了。IP網絡是按照數據包中的目標地址轉發,在Calico網絡中目標地址是endpoints。這時候IP互聯節點(比如ToR和/或者Spine交換機)就必須知道去往網絡中每個endpoints的路由。它們通過作爲BGP 路由反射器的客戶端可以學到這些路由,就像Calico vRouter/服務器所做的一樣。
然而,物理交換機不像服務器一樣有大量可用內存,它的性價比非常低。這決定了物理交換機可以處理的路由條目數量是有限的。當前業界標準商業交換機的路由表規格是128k,使用IP互聯結構的Calico是受到所使用網絡硬件路由表規格限制的,比較合理的上限是128K個endpoints。
原文鏈接:https://docs.projectcalico.org/v3.0/reference/private-cloud/l3-interconnect-fabric