




前言
java相較於c、c++語言的優勢之一是自帶垃圾回收器,程序開發人員不用手動管理內存,內存的分配和釋放完全由gc(Garbage Collector)來做,極大地提高了軟件開發效率及程序健壯性(手動管理內存容易造成內存泄漏)。凡事皆有兩面性,java gc在給我們帶來內存管理便捷性的同時,也面臨STW(Stop The World)影響程序吞吐的缺陷。作爲java開發人員,只有深入理解jvm垃圾回收的機制,才能在程序性能出現瓶頸時,更好的對程序進行優化。
垃圾確定
在垃圾回收之前,jvm需要確定哪些對象已死,即需要當做垃圾被回收。垃圾確認的方法傳統的有引用計數法:用一個引用計數器來標記對象當前的引用次數,當引用計數爲0時,對象可回收。這種方法有個弊端是無法解決循環引用的問題,如兩個對象相互引用則它們永遠不會釋放。另外一種方法是可達性分析算法,目前主流的語言(java、c#、golang等)都是採用這種方法來判定一個對象是否存活。可達性分析算法的思路是:將一系列根對象作爲起點,沿着這些起點向下搜索,搜索經過的所有路徑成爲引用鏈,沒有在引用鏈中的對象則爲不可達對象,這類對象會被判斷爲可回收對象。可達性分析圖如下:
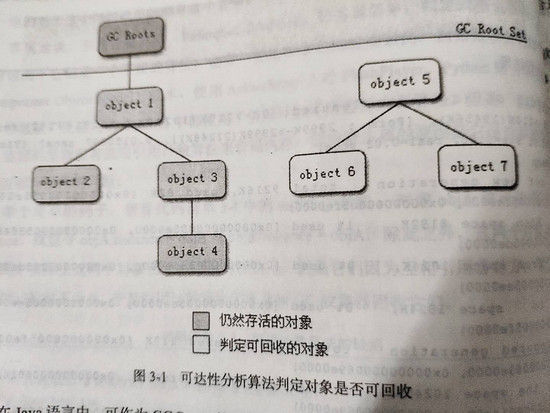
可達性分析
標記-清除算法(Mark-Sweep)
標記清除算法是最基礎的收集算法,顧名思義,算法分爲兩個階段:首先標記需要回收的對象,然後統一回收所有被標記的對象。這種垃圾回收算法比較簡單,但是存在兩個不足之處:一個是效率問題,標記和清除都需要掃描整個內存空間的對象,效率較低;另一個是標記清除後會產生大量的內存碎片。標記-清除算法流程如下所示:
標記-清除算法
複製算法
爲了解決上面的效率和內存碎片問題,有人提出了“複製”算法,它的思路是將內存一分爲二,每次分配對象時只使用其中一半內存空間,當一塊內存空間用完時,就將該塊內存空間上存活的對象複製到另外一塊內存上,然後將已使用過的內存空間一次清理掉,這樣每次只對一半的內存進行回收,同時也解決了內存碎片的問題。同樣,複製算法也有很明顯的缺點:1. 犧牲了一半的內存空間,內存利用率最大也就50%;2. 當內存中存活的對象較多時,會進行大量的複製操作,效率會較低。複製算法的執行過程如下所示:

複製算法
標記-整理算法(Mark-Compact)
複製算法在存在大量存活對象的情況下效率低下,更關鍵的是50%的內存空間得不到利用,如果存活對象過多,內存空間可能不夠,則需要額外的空間作爲擔保,因此,對於老年代不適合使用這種算法(新生代有老年代做擔保)。
因此,根據老年代的特點,有人提出了“標記-整理”算法,標記-整理算法和標記-清除算法的第一步相同,即對所有需要回收的對象進行標記,不同的是,標記-整理算法在第二階段並不是直接對可回收的對象進行清理,而是將所有存活的對象向一端移動,然後一把清理掉存活邊界之外的內存。這種算法結合了標記-清除和複製算法的思想,即未浪費內存也避免了內存碎片的產生。“標記-整理”算法如下所示:
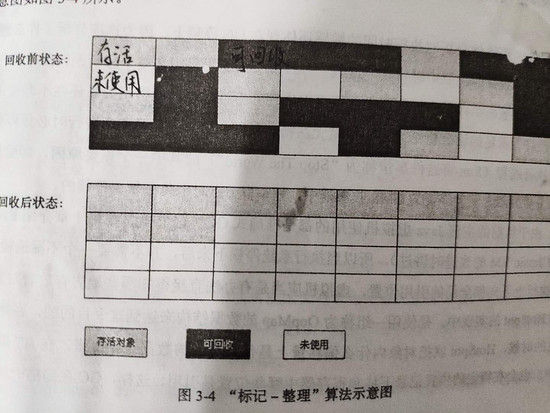
標記-整理算法
分代收集算法
分代收集並沒有什麼創新之處,這種算法只是將jvm堆內存分爲不同的區域,再根據區域的特點採用不同的垃圾回收算法。一般分爲新生代和老年代,新生代在再細分爲Eden和Survivor區(8:1),在新生代中,對象的存活率低,因此採用“複製”算法,將Edian區存活的對象複製到Survivor區,而老年代中對象存活率高且沒有額外的中間做擔保,因此採用“標記-清除”或者“標記-整理”算法來進行垃圾回收。