




1.2 Master/Slave
多副本最早的是Master/Slave架構,即簡單地用Slave去同步Master的數據,RocketMQ最早也是這種實現。分爲同步模式(Sync Mode)和異步模式(Async Mode),區別就是Master是否等數據同步到Slave之後再返回Client。這兩種方式目前在RocketMQ社區廣泛使用的版本中都有支持,原理圖如下圖1所示。
圖1 Master-Slave
1.2 基於Zookeeper服務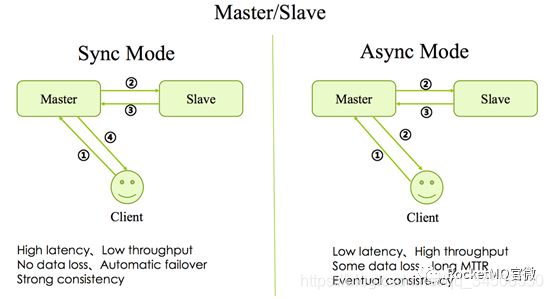
隨着Google三篇核心技術論文的發表(MapReduce、GFS和BigTable),分佈式領域開啓了快速發展。在Hadoop 生態中,誕生了一個基於 Paxos 算法選舉Leader的分佈式協調服務 Zookeeper。由於Zookeeper本身擁有高可用和高可靠的特性,隨之誕生了很多基於Zookeeper的高可用高可靠的系統。具體做法如下圖2
圖2 Based on Zookeeper/Etcd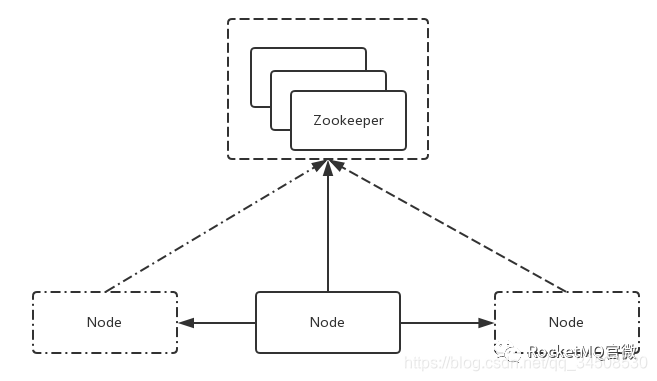
如圖所示,假如系統裏有3個節點,通過Zookeeper提供的一些接口,可以從3個節點中自動的選出一個master來。選出一個master後,另外兩個沒成功的就自然變成slave。選完之後,後續過程與傳統實現方式中的複製一樣。故基於Zookeeper的系統與基於Master/Slave系統最大的區別就是:選master的過程由手動選舉變成依賴一個第三方的服務(比如Zookeeper或Etcd)的選舉。基於Zookeeper的服務還存在一個變種,具體做法如下圖3: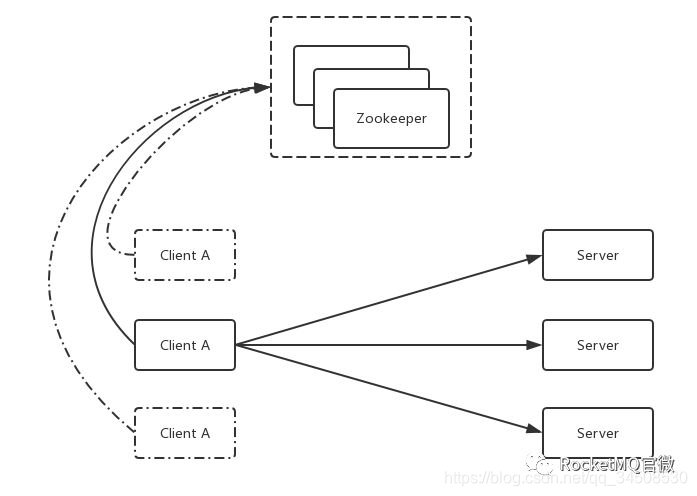
圖3 Based on Zookeeper/Etcd
在第一種方式中,發起者(Client)和接收者(Server)都是在同一個進程中的。而在這種方式中Client是脫離於Server之外的,通過Zookeeper,從這三個Client中選出一個master來,選完master後把請求同時發送到3個Server裏,這樣也可以達到多副本的效果。
但是基於Zookeeper的服務也帶來一個比較嚴重的問題:依賴加重,部署、運維和故障診斷成本都大大提高。因爲運維Zookeeper是一件很複雜的事情。
1.3 基於Raft服務方式
Raft可以認爲是Paxos的簡化版。基於Raft的方式如下圖4所示,與上述兩種方式最大的區別是:leader 的選舉是由自己完成的。比如一個系統有3個節點,這3個節點的leader是利用Raft的算法通過協調選舉自己去完成的,選舉完成之後,master到slave同步的過程仍然與傳統方式類似。最大的好處就是去除了依賴,即本身變得很簡單,可以自己完成自己的協調。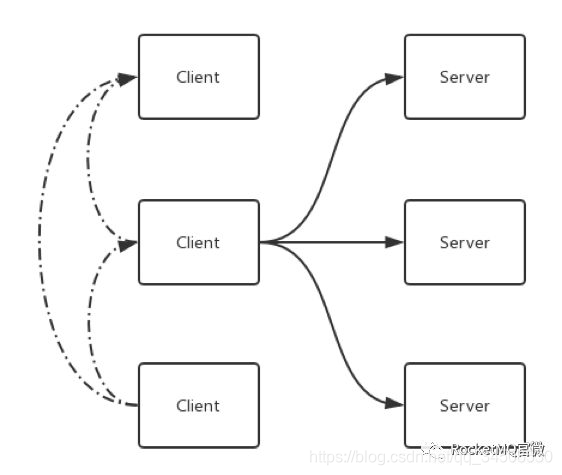
圖4 Raft
Raft Leader Election機制
Raft最大的好處就是可以實現自身leader選舉。如果一個分佈系統要自我協調,通常是採用“投票”的方式,在“投票”的時候,爲了解決衝突問題,就採用了兩個機制:Term和Quorum。
Term,即給每一次投票編號,以1、2、3這樣的數字命名。
Quorum,即少數服從多數原則,每一次投票必須要得到多數派(N/2 + 1)的同意才認爲是成功。
根據這兩個機制,在一個Term中,一個節點只能投出一票,保證在一個Term中只有一個節點能選舉成功。如果在一個Term中,沒有節點獲得大多數節點(N/2+1)的選票,選舉失敗,會重新發起選舉。選舉失敗後,給每個節點設置合適的隨機等待時間,會容易更快選舉完成。選舉成功之後就是跟之前比較相似的複製過程。
三種實現高可靠和高可用的方法優劣對比
Master/Slave,Based on Zookeeper/Etcd和Raft,這三種是目前分佈式系統中,做到高可靠和高可用的基本的實現方法,各有優劣。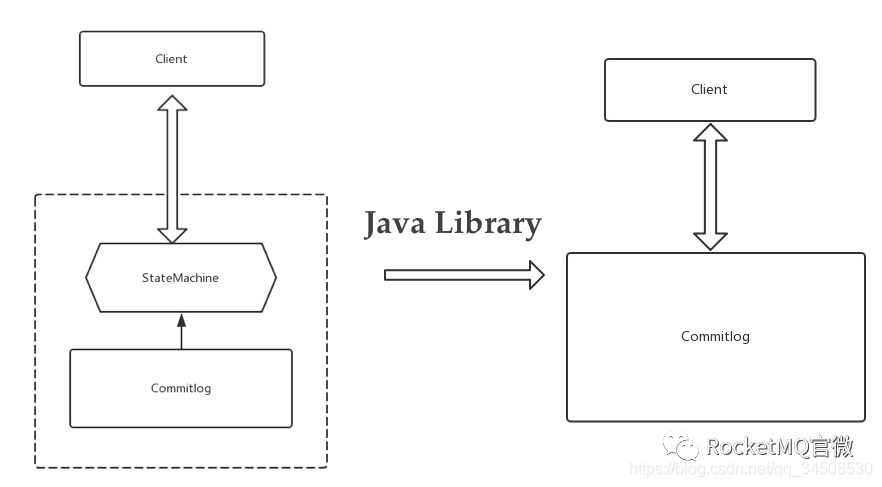
Master/Slave
優點:實現簡單
缺點:不能自動控制節點切換,一旦出了問題,需要人爲介入。
Based on Zookeeper/Etcd
優點:可以自動切換節點
缺點:部署、運維、診斷成本很高。
Raft
優點:可以自己協調,並且去除依賴。
缺點:實現Raft,在編碼上比較困難。
DLedger的介紹
2.1 DLedger的定位
前文介紹了目前分佈式系統中,做到高可靠和高可用的三種基本的實現方法。Raft算法現在解析的比較多,也比較成熟,代碼實現難度也有所降低。DLedger 作爲一個輕量級的Java Library,它的作用就是將Raft有關於算法方面的內容全部抽象掉,開發人員只需要關心業務即可。
圖5 DLedger Proposition
如上圖所示,DLedger 只做一件事情,就是CommitLog。Etcd雖然也實現了Raft協議,但它是自己封裝的一個服務,對外提供的接口全是跟它自己的業務相關的。在這種對Raft的抽象中,可以簡單理解爲有一個StateMachine和CommitLog。CommitLog是具體的寫入日誌、操作記錄,StateMachine是根據這些操作記錄構建出來的系統的狀態。在這樣抽象之後,Etcd對外提供的是自己的StateMachine的一些服務。DLedger 的定位就是把上一層的StateMachine給去除,只留下CommitLog。這樣的話,系統就只需要實現一件事:就是把操作日誌變得高可用和高可靠。
這樣做對消息系統還有非常特別的含義。消息系統裏面如果還採用StateMachine + CommitLog的方式,會出現double IO的問題。因爲消息本身可以理解爲是一個操作記錄,Dledger 會提供一些對原生CommitLog訪問的API。通過這些API可以直接去訪問CommitLog。這樣的話,只需要寫入一次就可以拿到寫入的內容。DLedger 對外提供的是簡單的API,如下圖6所示。可以把它理解爲一個可以無限寫入操作記錄的文件,可以不停append,每一個append的記錄會加上一個編號。所以直接去訪問DLedger 的話就是兩個API:一個是append(data),另一個是get(index),即根據編號拿到相應的entry(一條記錄)。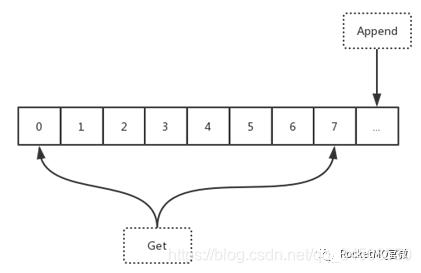
圖6 DLedger API
2.2 DLedger 的架構
DLedger的架構如下圖7所示: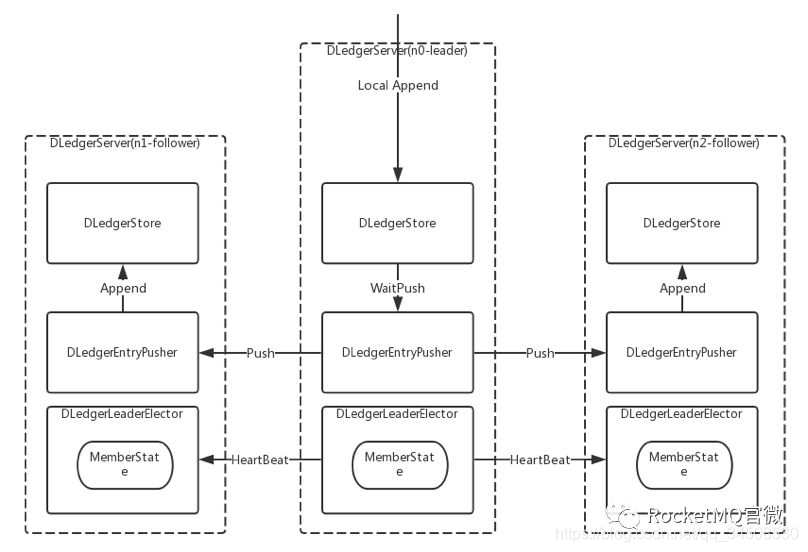
圖7 DLedger Architecture
從前面介紹的多副本技術的歷史可以知道,我們要做的主要有兩件事:選舉和複製,對應到上面的架構圖中,也就是兩個核心類:DLedgerLeaderElector和DLedgerStore,選舉和文件存儲。選出leader後,再由leader去接收數據的寫入,同時同步到其他的follower,這樣就完成了整個Raft的寫入過程。
2.3 DLedger 的代碼
因爲DLedger 只有CommitLog,沒有StateMachine,所以代碼很精簡,只有4000多行,總體代碼測試覆蓋率大概是70%。通過如下幾行命令便可以快速地體驗:
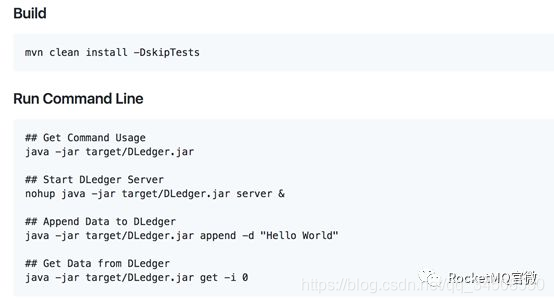
圖8 Dledge Quick Start
DLedger源代碼地址:https://github.com/openmessaging/openmessaging-storage-DLedger
RocketMQ on DLedger
3.1 DLedger 在RocketMQ上的應用
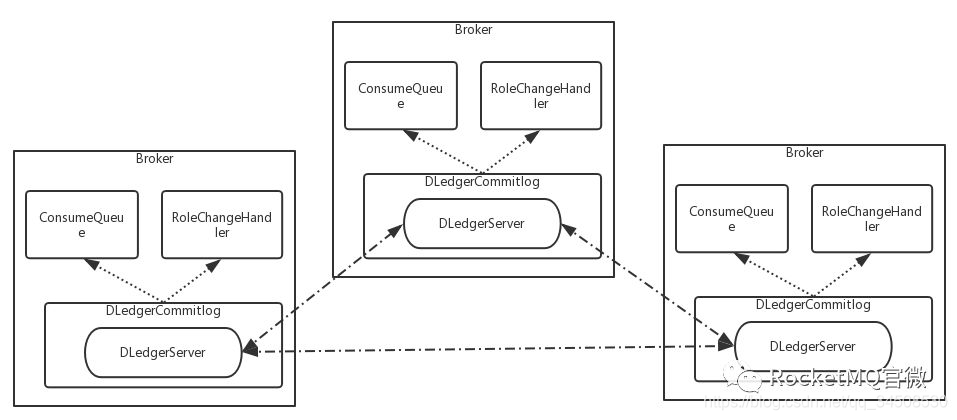
圖9 RocketMQ on DLedger Architecture
DLedger雖然只需要寫CommitLog,但是基於CommitLog是可以做很多事情的。RocketMQ原來的架構裏是有CommitLog的,現在用DLedger 去替代原來的CommitLog。由於DLedger 提供了一些可以直接讀取CommitLog的API,於是就可以很方便地根據CommitLog去構建ConsumerQueue或者其他的模塊。這就是DLedger 在RocketMQ上最直接的應用。
3.2 DLedger 與RocketMQ對接時格式上的區別
加了DLedger 之後,其實就是在原來的消息上面加了一個頭。這個頭就是DLedger 的頭,本質上是一些簡單的屬性,例如size等。如下圖10所示。
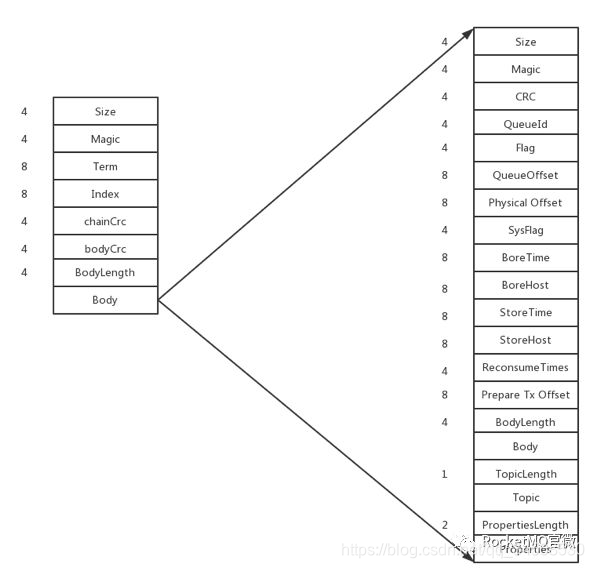
圖10 RocketMQ on DLedger Format
在使用的時候會有格式上的差異,所以社區在升級的時候做了一個平滑升級的考慮,如圖11所示。要解決的問題是:如何將原來已有的CommitLog和現在基於DLedger 的CommitLog混合?現在已經支持自動混合,但是唯一的一個要求是舊版的CommitLog需要自己去保持它的一致性。因爲DLedger 的複製是從新寫入的記錄開始。假設舊的CommitLog已經是一致的情況下,然後直接啓動DLedger ,是可以在舊的CommitLog基礎上繼續append,同時保證新寫消息的一致性,高可靠和高可用。這是DLedger 直接應用到RocketMQ上的時候一個格式上的區別。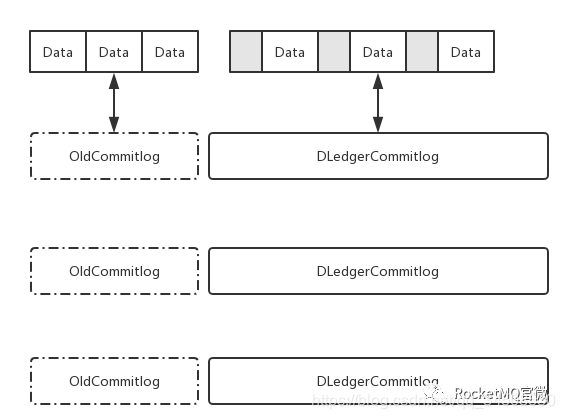
圖11 RocketMQ on DLedger Smooth Upgrade
對於用戶來說,這樣做最直接的好處是:若使用Master/Slave架構模式,一旦一個broker掛了,則需要手動控制。但是使用DLedger 之後不需要這麼做。因爲DLedger 可以通過自己選舉,然後把選舉結果直接傳給RocketMQ的broker,這樣通過nameserver拿到路由的時候就可以自動找到leader節點去訪問消息,達到自動切換的目的。如下圖12所示: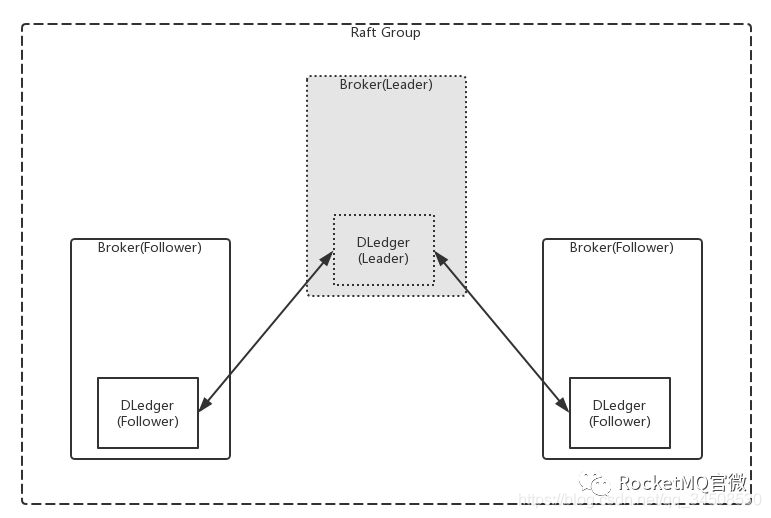
圖12 RocketMQ on DLedger Failover
3.3 DLedger 多中心
上面只是最基本的應用,更直接的應用如圖13所示:(容災切換)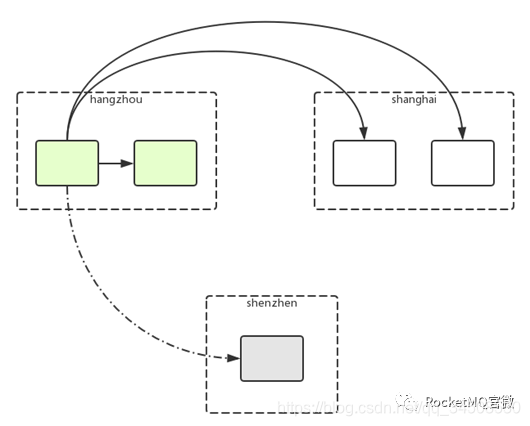
圖13 RocketMQ on DLedger Multi Center
這裏舉一個真實的金融應用場景:杭州、深圳和上海分別代表系統中三個節點,進行消息傳輸。要求:數據一條都不能丟,滿足實時高可用並且考慮城市之間的容災。
Raft的論文中沒有提及如何優先選擇某個節點作爲leader,但是我們實現的時候可以自己優化。假設杭州節點服務更好,我們可以指定優先選擇杭州節點爲leader。如果杭州節點宕機,可以再把leader節點切換到上海,如果上海節點也掛掉,雖然集羣不可用了,但是大部分數據還在深圳節點有災備。深圳主要起復制和災備的作用,一般情況下不會被選爲leader。
3.4 DLedger 使用方式
社區4.4.0剛剛發佈,RocketMQ on DLedger計劃在4.5.0發佈,目前可以在分支上獲取代碼:
https://github.com/apache/rocketmq/blob/store_with_DLedger/docs/cn/DLedger/
下載代碼之後,可以通過運行社區提供的簡單腳本fast-try.sh來體驗一下。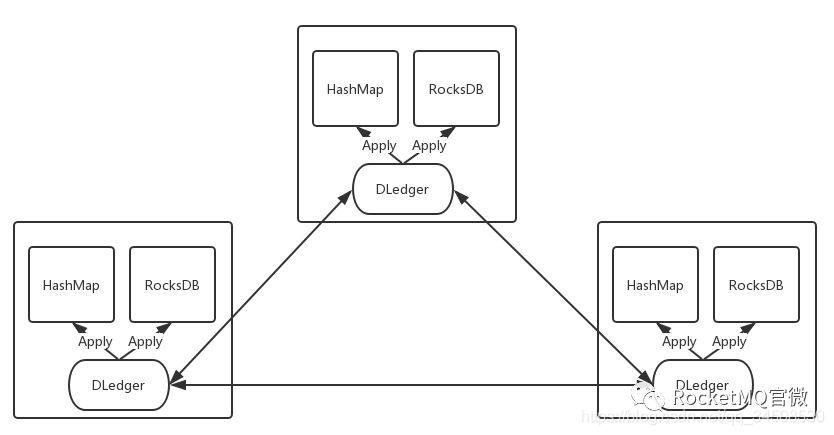
圖14 RocketMQ on DLedger Quick Start
社區發展
4.1 功能點展望
前面主要講了兩個東西:RocketMQ和DLedger。DLedger主要是作爲openmessaging社區的一個項目在孵化,openmessaging針對消息的存儲也抽象出了一套API,DLedger是其一個標準的實現。 目前Github上的DLedger只是實現了Raft一些基礎功能。後續有很多可以擴展的功能點,比如:123
Leader節點優先選擇
手動配置leader
自動降級到master/slave架構
4.2 openmessaging-hakv
再看一下跟DLedger定位相似的java library:openmessaging-hakv。openmessaging-hakv結構圖如圖15所示。代碼詳見:
https://github.com/openmessaging/openmessaging-hakv
圖15 openmessaging-hakv
目前來看,我們沒有一個嵌入式且高可用的解決方案。RocksDB可以直接用,但是它本身不支持高可用。有了DLedger之後,我們可以把操作的記錄直接寫入DLedger,但是基於這些記錄恢復過程我們可以自己選擇。假如數據量少,對高可用要求高,比如元數據,我們可以直接存在內存的hashmap中,根據DLedger的寫入記錄來構建自己的hashmap,從而達到數據的一致性和容災功能。