




本賬號爲第四範式智能推薦產品先薦的官方賬號。賬號立足於計算機領域,特別是人工智能相關的前沿研究,旨在把更多與人工智能相關的知識分享給公衆,從專業的角度促進公衆對人工智能的理解;同時也希望爲人工智能相關人員提供一個討論、交流、學習的開放平臺,從而早日讓每個人都享受到人工智能創造的價值。
以下內容由第四範式先薦編譯、整理,僅用於學習交流,版權歸原作者所有。
1.背景
推薦系統能夠預測用戶未來的興趣偏好,並向用戶推薦排序最靠前的item。在現代社會中,推薦系統之所以被人們需要,關鍵是由於互聯網的普及,人們面臨着太多的選擇。過去,人們習慣在實體店購物,實體店的商品有限,人們的選擇也有限。相比之下,如今互聯網允許人們在線訪問任何資源。儘管可用信息量增加,但人們很難選出他們真正想要的東西,問題來了——這就是推薦系統的用武之地。
本文將簡要介紹構建推薦系統的兩種典型方法,即協同過濾和奇異值分解。
2.傳統方法
傳統上,構建推薦系統有兩種方法:
- 基於內容的推薦
- 協同過濾
第一種方法需要分析每一項的屬性。例如,對每位詩人的詩歌作品進行自然語言處理,然後向用戶推薦詩人。但是,協同過濾卻不需要有關項或用戶本身的任何信息,而是根據用戶的過去行爲進行推薦。以下我們將重點講解協同過濾。
3.協同過濾
如上所述,協同過濾(CF)是基於用戶過去行爲的推薦平均值。協同過濾可分兩類:
基於用戶:測量目標用戶與其他用戶之間的相似性
基於項目:測量目標用戶評價/交互過的項目與其他項目之間的相似性
同過濾背後的關鍵思想是相似的用戶共享相同的興趣,並且喜歡相似的項目。
假設現有m個用戶和n個項目,我們用m * n的矩陣來表示用戶過去的行爲。矩陣中的每個單元格表示用戶持有的相關反饋,例如,M {i,j}表示用戶i對項目 j的喜歡程度,這種矩陣稱爲效用矩陣(utility matrix)。
基於用戶的協同過濾
基於用戶的協同過濾首先需要計算用戶之間的相似性。計算相似性有兩種辦法,皮爾遜相關係數或餘弦相似度。設u {i,k}表示用戶i和用戶k之間的相似度,v {i,j}表示用戶i對項目j的評級,如果用戶沒有評定該項目,則v_ {i,j} =?。
這兩種方法可以表示如下:
-
皮爾遜相關係數 (Pearson Correlation)
![想要了解推薦系統?看這裏!(1)——協同過濾與奇異值分解]()
- 餘弦相似度(Cosine Similarity)
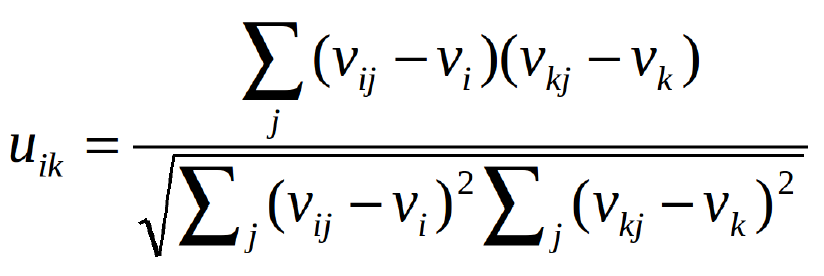

這兩種方法很常用,但區別在於用皮爾遜相關係數計算的話,向所有元素添加常量不變。
現在,我們可以使用以下等式預測用戶對未評級項目的反饋意見:
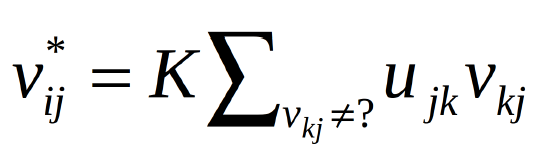
未評級項目預測
在以下矩陣中,每行代表一個用戶,而列對應於不同的電影,每個單元格代表用戶爲該電影提供的評級,最後一列爲該用戶和目標用戶之間的相似性。假設用戶E是目標用戶。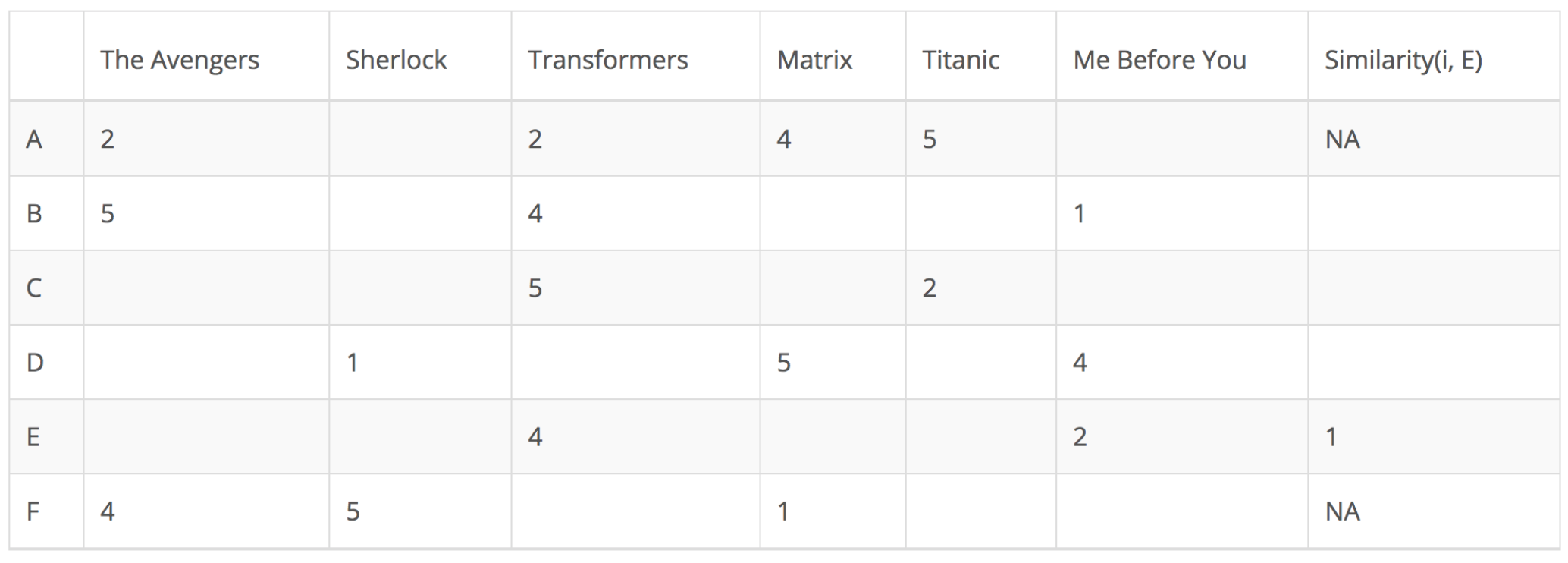
由於用戶A和F不共享與用戶E共同的任何電影評級,因此他們與用戶E的相似性未在中皮爾遜相關係數中定義。因此只需要考慮用戶B、C和D。基於皮爾遜相關係數,計算如下: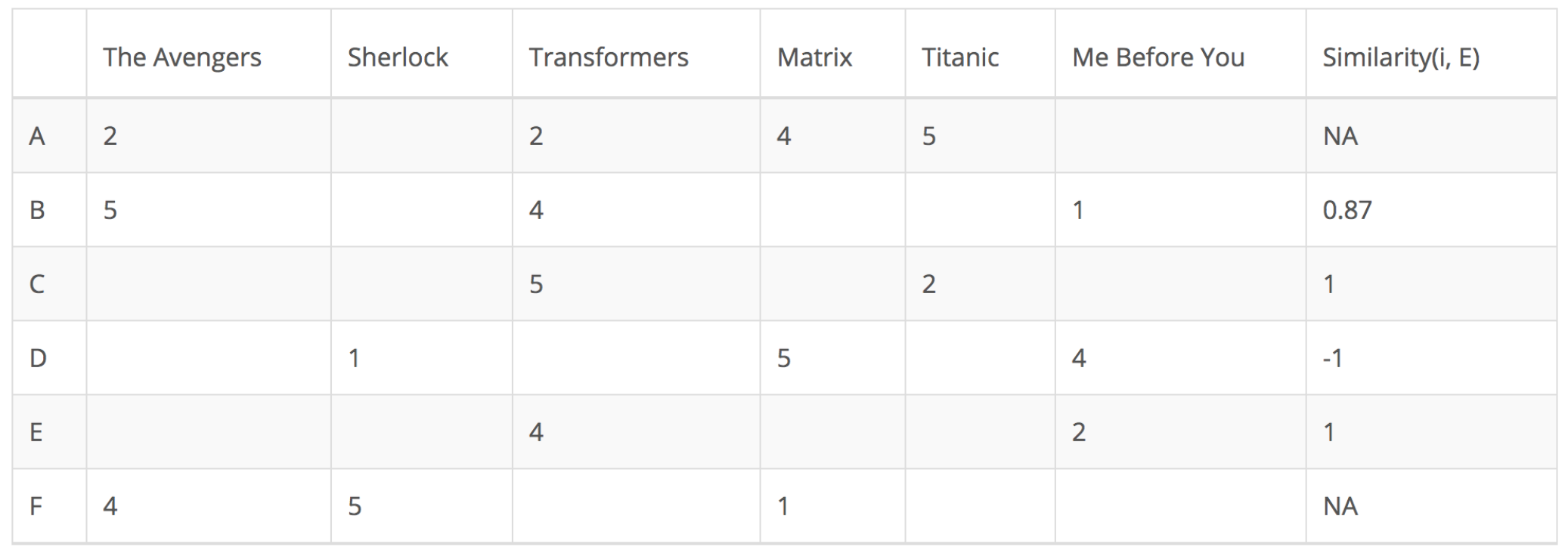
從上表可以看出,用戶D與用戶E差異很大,二者之間的皮爾遜相關性爲負。用戶D對電影Me Before You的評價高於他的評分平均值,而用戶E的表現則相反。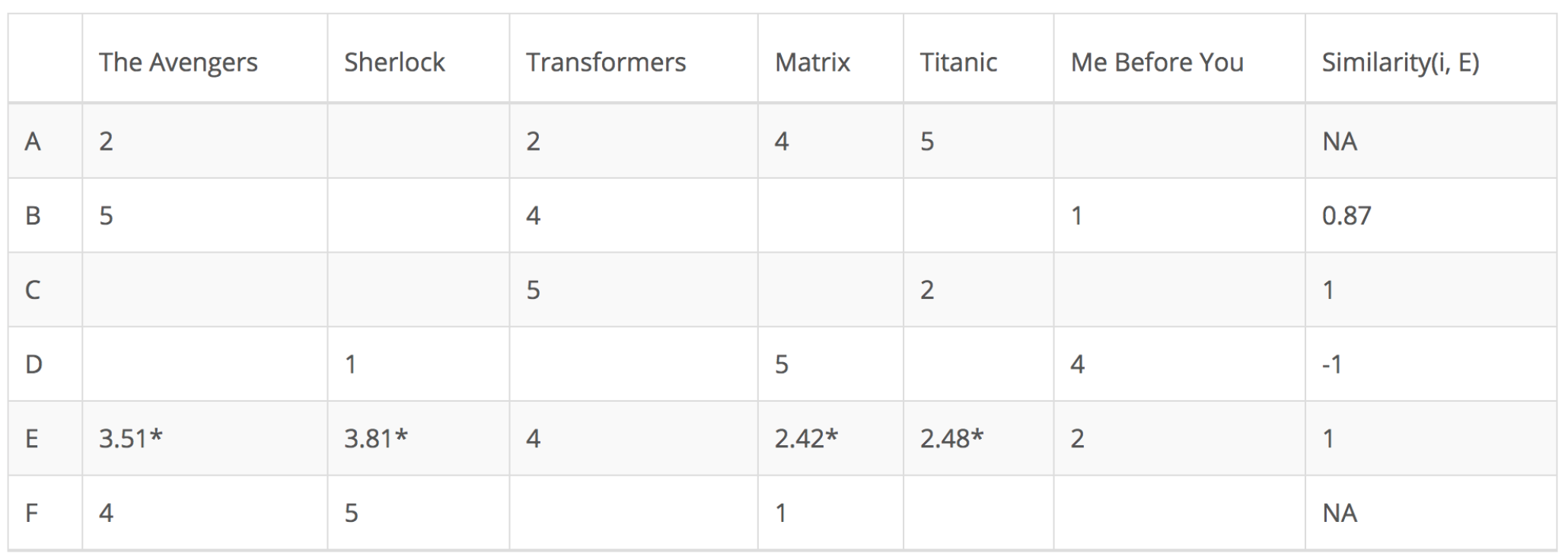
基於用戶的協同過濾雖然很簡單,但它存在幾個問題。一個主要問題是用戶的偏好會隨着時間的推移而改變,這意味着基於其相鄰用戶預先計算矩陣這種方法可能導致推薦效果不準確。爲了解決這個問題,我們可以採用基於項目的協同過濾。
基於項目的協同過濾
基於項目的協同過濾並不計算用戶之間的相似性,而是基於用戶與目標用戶評定的項目之間的相似性來推薦項目。同樣,可以使用皮爾遜相關係數或餘弦相似度計算相似度。主要區別在於,使用基於項目的協同過濾,我們垂直填補空白,與基於用戶的協同過濾的水平方式相反。下表展示瞭如何爲電影Me Before You執行此操作。
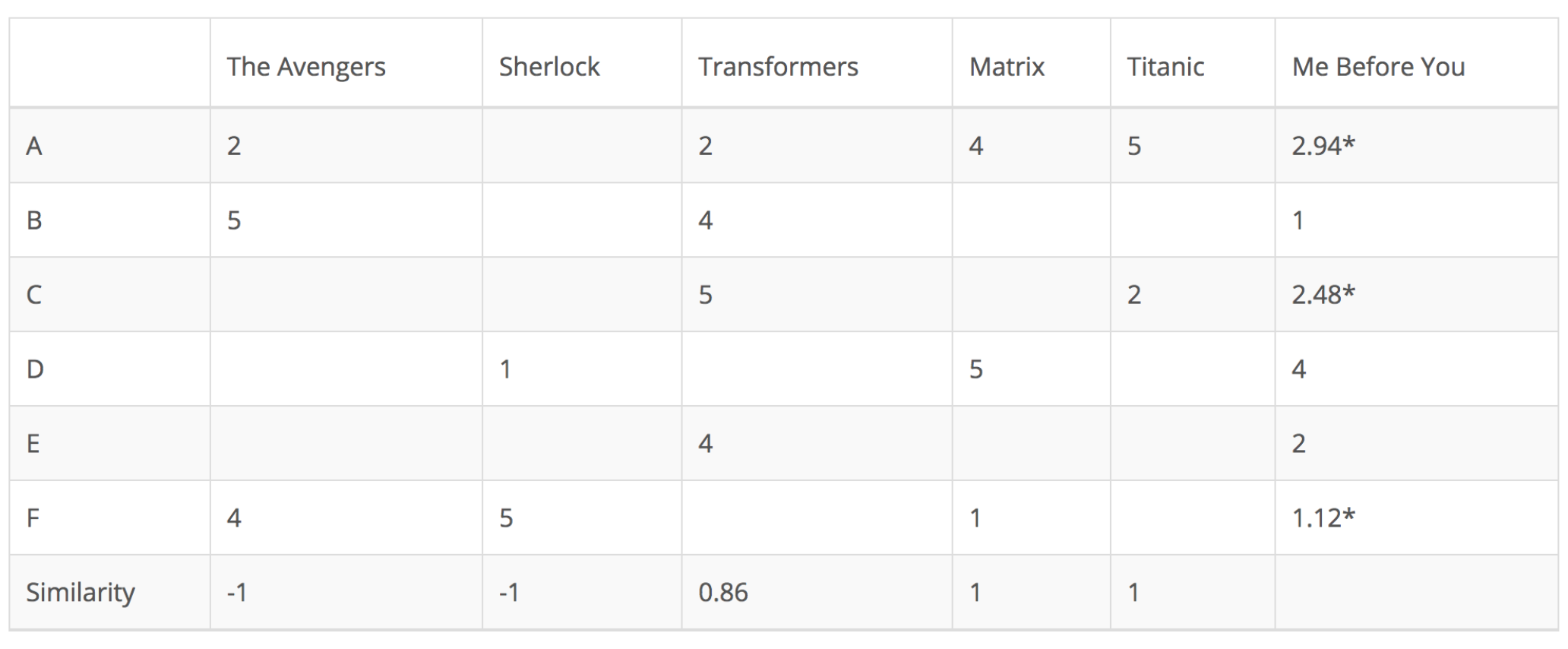
這種方法成功地避免了動態的用戶偏好帶來的問題,因爲基於項目的CF更加靜態。但是,這種方法仍然存在一些問題。第一個問題是可擴展性。數據計算量隨用戶和項目的增長而增長。最壞的情況複雜度是O(mn),即m個用戶和n個項目。稀疏性是另一個問題。在上表中,雖然只有一個用戶對Matrix和Titanic都進行了評級,但它們之間的相似性爲1。在極端情況下,我們可能擁有數百萬用戶,兩部截然不同的電影之間的相似性也可能非常高,因爲唯一一個對這兩部電影評分的用戶給了它們相似的評分。
4. 奇異值分解(Singular Value Decomposition)
處理CF中可擴展性和稀疏性問題的方法之一是利用潛在因子模型來捕獲用戶和項之間的相似性。從本質上講,我們希望將推薦問題轉化爲優化問題,把它看做系統預測用戶給定項目的評級的性能。
一個常見的指標是均方根誤差(RMSE,Root Mean Square Error)。 RMSE越低,性能越好。由於我們不知道不可見項目的評級,因此會暫時忽略它們。也就是說,我們只在效用矩陣中的已知條目上最小化RMSE。爲了實現最小RMSE,採用奇異值分解(SVD)如下面的公式所示。
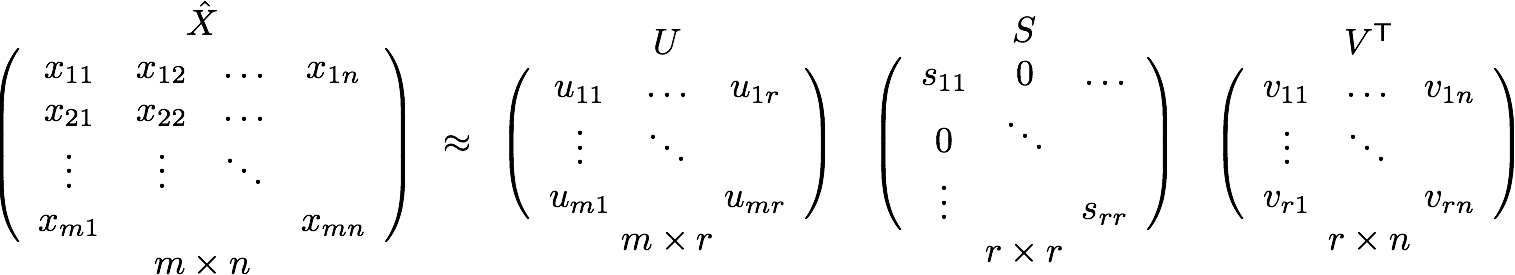
奇異矩陣分解
X表示效用矩陣,U是左奇異矩陣,表示用戶和潛在因子之間的關係。 S是描述每個潛在因子強度的對角矩陣,而V轉置是右奇異矩陣,表示項和潛在因子之間的相似性。什麼是潛在因子呢?這是一個廣義的概念,用來描述用戶或項目具有的屬性。以音樂爲例,潛在因子可以指音樂所屬的類型。 SVD通過提取其潛在因子來減小效用矩陣的維數。基本上,我們將每個用戶和每個項目映射到維度爲r的潛在空間。潛在空間有助於我們更好地理解用戶和項目之間的關係,如下所示:
SVD將用戶和項目映射到潛在空間SVD具有最小的重建平方誤差和(SSE,Sum of Square Error);因此,它也常用於降維。在下面的公式中,用A代替X,用Σ代替S。
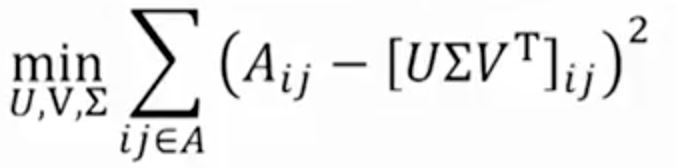
平方誤差總和
這與開頭提到的RMSE有什麼關係呢?事實證明,RMSE和SSE呈單調相關。這意味着SSE越低,RMSE越低。既然SVD可以最大限度地降低SSE,那麼就可以最小化RMSE。
因此,SVD是解決此優化問題的絕佳工具。爲了預測用戶不可見的項目,我們簡單地將U、Σ和T相乘。
Python Scipy爲稀疏矩陣提供了很好的SVD實現。

SVD成功解決了CF帶來的可擴展性和稀疏性問題,然而SVD並非沒有缺陷。 SVD的主要缺點是向用戶推薦項目的原因幾乎沒有解釋。如果用戶想知道爲什麼要向他們推薦特定項目,這可能是一個很大的問題。這個問題將會在下一篇文章中提到。
5.結論
本文討論了構建推薦系統的兩種典型方法,協同過濾和奇異值分解。 在下一篇文章中,將繼續討論一些用於構建推薦系統的更高級算法。