




AWS S3
業務場景
挑戰
- Web服務器傳輸大型文件可能引起網絡延遲
- 用戶生成的內容需要分配到所有的web服務器中
解決方案
- 靜態資產存放在S3中
- S3中的對象設置爲公開,用戶可以直接訪問
S3的好處
- 通過API或者HTTP進行訪問
- S3是以冗餘方式將對象存儲,至少在三個可用區存放副本
- S3使用校驗和來驗證數據的完整性
- 提供完善的版本控制使用戶能夠保存、檢索和還原每個對象的各個版本
- 多副本的數據一致性
S3 屬性
存儲桶 Buckets
- 存儲S3的容器
- Bucket 名 最多包含63個字符,且在全球AWS都必須是唯一的
- 最佳實踐是包含並符合DNS域名規範來對Bucket命名
- 在靠近用戶的區域創建Bucket以優化性能
- 每用戶最多可創建100個存儲桶
- 存儲桶需要指定區域,但是不能指定可用區
對象 Object
- 每一個存儲在S3的實體或文件都是對象
- 最大支持單個對象5TB
- 對象由文件本身和元數據組成
- 文件本身在S3看來只是一串字節流
- 元數據包含了對象的名稱和鍵值,系統元數據包括了MD5,上次修改日期等系統信息,用戶元數據是用戶的可選項
-
獲取對象使用的Request包頭
- x-amz-meta-
- x-amz-storage-class
- Content-MD5
- Content-Length
-
數據結構
- 鍵(Key):可以認爲是數據的名字
- 值(Value):表示數據本身
- 版本號(Version ID):對於啓用了版本控制的存儲桶來說很重要
- 元數據(Metadata):關於數據的描述,比如說數據的創建時間,更改時間,文件類型,文件大小等信息
- 訪問控制信息:能管理對Bucket內文件的訪問權限
-
Key
- 每個對象的標識,在存儲桶內唯一
- 最大支持1024字節的UTF-8字符,可以包含斜槓等
- 存儲桶名+Key 組成S3對象的唯一標識
- 最佳命名實踐是利用/進行命名對對象進行邏輯組織,但記住這並不代表文件是被層次組織的,S3對象始終處於一個平面而不是一個真正的File System
- S3對象可以基於其唯一標識通過Internet直接尋址訪問,URL就是其唯一標識
- 對象標籤
- 每個對象添加最多10個標籤
- 用標籤標記後可以用於IAM策略管理
S3 特性
S3 操作
- 基於REST API接口進行操作,將HTTP動詞映射到CRUD操作
- 實際使用更高級的接口(如編程語言,SDK,CLI和控制檯)來調用REST API
可用性和持久性
-
S3採用高度持久和可用的存儲基礎架構
- 持久性 = 11個9
- 可用性 = 4 個 9
- 建議採用版本控制、跨域區複製、MFA刪除等方式來防止用戶意外造成的邏輯錯誤
一致性
- S3會自動在區域內對數據進行自動複製
- S3是一個最終一致性系統,保證所有的獲取都是一致的
- 爲新對象PUTS 提供 先寫後讀一致性
- 爲 Overwrite PUTS和DELETE提供最終一致性
S3 定價策略
- 存儲容量
- 讀取操作
- 數據傳輸
S3高級功能
存儲級別
-
S3-Standard
- 提供高耐用、高可用、低延遲和高性能的存儲對象
-
S3-Standard-IA
- 提供較低的高可用標準但仍然是多可用區部署的,但設計用於長期存取和訪問頻率較低的數據,
- 利用規模效應對存儲超過30天以上的提供更低成本的選項,最小收費粒度128KB,最短使用30天。
-
S3-ONEZONE-IA
- 類似於Standard-IA,但是僅部署在一個可用區內提供高可用
- 用於非關鍵性和易重現數據,用於替代RRS
-
INTELLIGENT_TIERING
- 自動分層的數據,類似於IA的持久性和可用性
- 能夠提供標準的讀寫性能但不是一致的,取決於讀寫請求頻率
- 有額外的監控和自動分層的成本,最短使用30天,小於128K的對象沒有資格進行自動分層但仍收費。
-
S3減少冗餘存儲 RRS
- 適用於非關鍵數據或易於重現的派生數據,支持低延遲訪問,不支持高可用的(4個9持久性)
- 目前已經不再推薦,使用S3-ONEZONE-IA替代
- Glacier
- 成本極低的歸檔數據存儲,不需要實時數據訪問
| 存儲類 | 設計專門針對 | 持久性(設計目標) | 可用性(設計目標) | 可用區 | 最小持續時間 | 最小可計費對象大小 | 其他考慮因素 | 每GB費用 |
|---|---|---|---|---|---|---|---|---|
| STANDARD | 經常訪問的數據 | 99.999999999% | 99.99% | >=3 | 無 | 無 | 無 | 0.022 USD |
| STANDARD_IA | 長時間存在,不經常訪問的數據 | 99.999999999% | 99.99% | >=3 | 30天 | 128KB | 按每 GB 收取檢索費用。 | 0.0125 USD |
| INTELLIGENT_TIERING | 訪問模式發生變化或未知的長時間存在的數據 | 99.999999999% | 99.9% | >=3 | 30天 | 無 | 按對象收取監控和自動化費用。無檢索費用。 | |
| ONEZONE_IA | 長時間存在的、不經常訪問的、非關鍵數據 | 99.999999999% | 99.5% | 1 | 30天 | 128KB | 按每 GB 收取檢索費用。無法靈活地應對可用區丟失的情況。 | 0.01 USD |
| GLACIER | 檢索時間從數分鐘到數小時不等的長期數據存檔 | 99.999999999% | 99.99%(在您還原對象之後) | >=3 | 90天 | 無 | 按每 GB 收取檢索費用。您必須先還原存檔對象,然後纔可以訪問它們。 | 0.004 USD |
| DEEP_ARCHIVE | 存檔很少訪問的數據,默認檢索時間爲 12 小時 | 99.999999999% | 99.99%(在您還原對象之後) | >=3 | 180天 | 無 | 按每 GB 收取檢索費用。您必須先還原存檔對象,然後纔可以訪問它們。 | 0.00099 USD |
| RRS(不推薦) | 經常訪問的非關鍵數據 | 99.99% | 99.99% | >=3 | 無 | 無 | 無 |
對象生命週期管理
- 類似於自動存儲分層的解決方案
-
S3可以利用生命週期配置規則,將數據從一個存儲級別向另一個存儲級別轉換,指導最終自動刪除
- Transition :轉換存儲類別
- Expiration:指定對象過期時間
- 如: 最初在S3 Standard,30天后 S3 Standard IA, 90天后 Glacier, 3年後自動刪除
數據訪問
-
桶策略
- 默認只有存儲桶和對象所有者才能訪問他們創建的S3資源
- 利用IAM可以修改和管理用戶訪問S3資源的權限
- 存儲桶策略可以對全部或部分S3對象的訪問進行授權管理
-
S3 ACL
- 使用S3 ACL可以爲S3的對象提供其他AWS對其的訪問權限管理
數據傳輸及其加速
-
S3傳輸加速 (Amazon S3 Transfer Acceleration),可以利用AWS CloudFront CDN網絡的邊緣節點(Edge Locations)加速傳輸的過程。可以將數據上傳到離我們最近的邊緣節點,然後再通過AWS內部網絡(更高速,更穩定)傳輸到目標區域的S3存儲桶。
- 您位於全球各地的客戶需要上傳到集中式存儲桶
- 您定期跨大洲傳輸數 GB 至數 TB 數據
- 您在上傳到 Amazon S3 時未充分利用 Internet 上的可用帶寬
- 上傳需要指定專用的兩個S3雙堆棧加速節點
- S3支持客戶端加密和服務器端加密兩種方式傳輸數據
- 服務器端加密使用SSE AES-256 加密
- S3對通過互聯網傳入傳出流量收費,但對區域內部存儲桶之間或者AWS服務之間的傳輸不收費
版本管理
- S3允許每個對象的多個版本保存在存儲桶中,在數據被意外或者惡意刪除時,可以利用對象的唯一標識+版本ID進行恢復
- 版本控制是一個存儲桶級別的可選項,一旦打開只能暫停而不能關閉
- 開啓版本管理後,刪除一個對象實際是新增了一個刪除標記使得對象不可見,在版本控制中刪除這個刪除標記即可恢復對象
- 只有存儲桶所有者才能永久刪除版本,也可以設置生命週期規則來進行版本管理
MFA刪除
- 支持需要額外驗證來永久刪除對象版本或者更改存儲桶版本控制狀態
- 僅能採用Root 用戶執行該操作,且一般採用額外的硬件生成驗證碼
預先簽名的網址
- 默認S3對象是私有的,但是可以通過預先簽名授權其他用戶採用安全憑證授予有時間限制的訪問
- 安全憑證必須制定存儲桶名稱、對象Key、HTTP方法和過期時間等
靜態網站託管
- S3可以直接將Html對象作爲靜態網站的託管
- 不能做PHP、ASP.net、JSP等服務器端處理
- 可以通過客戶端腳本完成動態和交互,如嵌入靜態HTML網頁的JavaScript
- 創建一個與網站同名的存儲桶,並指定一個索引和錯誤文檔,
-
需要單獨打開靜態託管功能,並指定index.html 和 error.html
分段上傳 API
- 主要用於大型對象的上傳,100MB以上建議使用,5GB以上必須採用
- 被拆分之後的零件可以以任意順序上傳,在全部傳輸完成後再進行組裝
- 可以通過設置對象生命週期,在指定天數後終止不完整的分段上傳
- 好處
- 提高吞吐量 – 您可以並行上傳分段以提高吞吐量。
- 從任何網絡問題中快速恢復 - 較小的分段大小可以將由於網絡錯誤而需重啓失敗的上傳所產生的影響降至最低。
- 暫停和恢復對象上傳 – 您可以在一段時間內逐步上傳對象分段。啓動分段上傳後,不存在過期期限;您必須顯式地完成或中止分段上傳。
- 在您知道對象的最終大小前開始上傳 – 您可以在創建對象時將其上傳。
Range GET
- 在S3或者Glacier 中僅下載對象的一部分內容,主要用於更高效的處理大型對象
- 最小可以到1個字節的範圍
隨時查詢
- Amazon S3 允許客戶對存儲數據運行復雜的查詢,無需將數據移動到獨立的分析平臺。
-
S3 Select
- 利用簡單的 SQL 語句檢索對象內較小且具有針對性的數據集。
- 您可以將 S3 Select 與 AWS Lambda 搭配使用,來構建無服務器應用程序,此類應用程序可使用 S3 Select 有效且輕鬆地檢索 Amazon S3 中的數據,而不是檢索和處理整個對象。
-
Amazon Athena
- Amazon Athena 是一項交互式查詢服務,讓您能夠輕鬆使用標準 SQL 查詢分析 Amazon S3 中的數據。
- Athena 是無服務器式服務,因此您無需設置或管理基礎設施即可馬上開始分析數據。您甚至無需將數據加載到 Athena 中,因爲它可以直接處理所有 S3 存儲類中存儲的數據。
-
Amazon Redshift Spectrum
- Amazon Redshift Spectrum 是 Amazon Redshift 的一項功能,藉助這項功能,您可以對 Amazon S3 中的 EB 級的數據運行查詢,而無需進行加載或 ETL 操作。
- 當您發佈查詢時,查詢會進入 Amazon Redshift SQL 終端節點,該終端節點會生成查詢方案並對其進行優化。
跨區域複製(CRR)
- S3的一個可選項,可以把AWS區域中的源存儲桶中的新對象異步複製到另一個區域中的目標存儲桶
- 與對象關聯的元數據和ACL也會被複制
- 源和目標存儲桶都必須啓用版本控制
- 支持分別爲源目標創建生命週期規則,也可以無視規則直接將數據複製到跨區域的Glacier中
- 功能啓動後,只有新對象會被跨區域複製,現有對象必須手工通過單獨的命令複製過去
- 支持跨賬戶CCR
- 刪除操作(包括文件刪除和版本刪除)都不會被同步到目標區域
存儲類分析
- 藉助存儲類分析,您可以分析存儲訪問模式並將相應數據傳輸給正確的存儲類。這一新的 S3 功能可自動識別不頻繁訪問模式,從而幫助您將存儲轉換爲 S3 標準 – IA。
- 您可以配置存儲類分析策略來監視整個存儲桶、前綴或對象標籤。
- 最後在控制檯上可視化,也可以導出至S3以便用Amazon QuickSight 商業智能分析工具。
對象鎖定
- 可以在客戶定義的保留期內阻止刪除對象版本,讓您能夠通過實施保留策略來進一步保護數據或滿足監管要求。
- 在對象級別或存儲桶級別配置 S3 對象鎖定,防止在預定義的保留到期日期或依法保留日期之前刪除對象版本。無論對象在哪個存儲類中,S3 對象鎖定保護都將保留,並且會在存儲類之間的整個 S3 生命週期轉換期間保留。
S3 清單
- 爲S3同步列表提供的預定替代方案
- 通過S3清單,提供每日,每週的對象元數據進行輸入,以加快業務工作流和大數據作業的查詢。
檢測數據損壞
- 是利用Content MD5 以及 CRC來檢測數據損壞
- 在空閒時對數據執行檢測,並使用冗餘數據修復任何損壞
記錄日誌
- 跟蹤對S3存儲桶的訪問日誌,默認關閉
- 日誌記錄採用盡力而爲方式記錄,會稍有延遲
- 日誌包含 請求者賬戶和IP、存儲桶名稱、請求時間、請求操作和錯誤代碼
事件通知
- 在S3反應操作或上載等事件時,啓用通知執行工作流,發送警報或執行其他操作來響應該事件
- 通知消息結合SNS、SQS、Lambda函數進行響應觸發
跨源資源共享 CORS
- 現代瀏覽器默認使用了同源策略阻止JavaScript或HTML5加載其他站點的內容以確保不會有惡意內容被加載
- S3可以配置明確啓用跨源請求,實現外部網頁、樣式表、H5等程序安全的引用S3的資源
S3實踐和場景
S3使用實踐
- 選擇離用戶較近的區域,距離對性能影響非常大
- 與計算資源和其他AWS資源位於同一位置會影響性能
- 使用全球唯一的字符串(3-63字符)來命名對象,是存儲桶提供一致的性能
S3應用場景
- 本地或雲數據的備份和歸檔
- 媒體和軟件存儲和分發
- 大數據分析
- 靜態網站託管
- 雲原生移動互聯網應用程序託管
- 作爲批量數據的Blob存儲,同時在另一數據庫中保留數據索引實現快速搜索和複雜查詢
- 靜態網站託管
S3請求處理性能優化
- 當S3存儲桶中的對象超過1000個時,存儲桶會進行分區
- 如果順序命名這些對象,可能導致每次對多個鄰近對象的讀取都在一個分區裏而影響性能
- 通過在對象名前綴添加hash值得方式,使得對象隨機的分佈在不同分區裏,則可以提升處理性能
- 以前存儲桶常規可以支持 每秒 100個以上的PUT/LIST/DELETE 以及 300 個以上的GET,
- 2018年後,提升到3500個PUT 和 5500個GET,一般情況下不再需要對處理性能進行優化

- 爲了更有效的檢索,還建議保留二級索引並存儲在數據庫中,如DynamoDB

S3 安全性
訪問控制
-
Identity and Access Management (IAM) 策略
- IAM 讓擁有多名員工的組織能夠使用一個 AWS 賬戶創建和管理多個用戶。使用 IAM 策略,公司可向 IAM 用戶授予對 Amazon S3 存儲桶或對象的精細控制權,同時保留對用戶執行的所有操作的完全控制。
-
存儲桶策略
- 用存儲桶策略,客戶可以定義廣泛適用於其 Amazon S3 資源的所有請求的規則,例如爲 Amazon S3 資源的子集授予寫入權限。客戶還可以基於請求的某種特徵(例如 HTTP 引用站點和 IP 地址)來限制訪問。
- 可以利用存儲桶策略配合IAM策略,以及查詢字符串認證來實現細粒度訪問控制 (推薦)
-
訪問控制列表 (ACL)
- 使通過 ACL,客戶可爲特定用戶授予對單個存儲桶或數據對象的特定權限,例如讀取、寫入、完全控制。
這是一種粗粒度的訪問控制。
- 使通過 ACL,客戶可爲特定用戶授予對單個存儲桶或數據對象的特定權限,例如讀取、寫入、完全控制。
-
查詢字符串身份驗證
- 藉助查詢字符串身份驗證,客戶可以爲 Amazon S3 對象創建一個僅在有限時間內有效的 URL。
S3的數據加密
- 數據加密是可選項
- 默認情況下,S3是私有數據,需要AWS憑證才能訪問
- 但是可以通過預簽名URL分享對象,通過HTTP和HTTPS訪問
- S3提供日誌功能審覈所有對象的訪問
- S3支持爲每個存儲桶、前綴和對象設置訪問控制列表和策略
- 最佳實踐是對所有敏感數據加密
- 傳輸中的數據使用SSL API,確保所有數據都採用HTTPS傳輸
-
服務器端加密:
- 數據在S3中存儲是被加密,採用SSE的不同組合解決方案
- 如果是授權的訪問,訪問加密數據和非加密數據的過程實際上是沒有區別的
- AWS加密密鑰可以通過輪換密鑰來進一步加密
-
SSE-S3
- 使用256位AES-256加密標準進行加密,並且主密鑰會定期輪換
- 提供了一種集成式解決方案,Amazon 通過其使用多個安全層處理密鑰管理和密鑰保護問題。如果您希望 Amazon 管理您的密鑰,您應該選擇 SSE-S3。
-
SSE-C
- 客戶來提供和管理加密密鑰,S3負責加密和解密
- 讓您能利用 Amazon S3 對對象執行加密和解密操作,同時保持對加密對象所用密鑰的控制權。藉助 SSE-C,您無需實施或使用客戶端庫來對 Amazon S3 中儲存的對象執行加密和解密,但是需要對您發送到 Amazon S3 中執行對象加密和解密操作的密鑰進行管理。如果您希望保留自己的加密密鑰而不想實施或使用客戶端加密庫時,請使用 SSE-C。
-
SSE-KMS
- 使用AWS提供的密鑰管理系統,有更多的密鑰管理能力
- 可讓您使用 AWS Key Management Service (AWS KMS) 來管理您的加密密鑰。使用 AWS KMS 管理您的密鑰有幾項額外的好處。利用 AWS KMS,會設置幾個單獨的主密鑰使用權限,從而提供額外的控制層並防止 Amazon S3 中存儲的對象遭到未授權訪問。AWS KMS 提供審計跟蹤,因此您能看到誰使用了您的密鑰在何時訪問了哪些對象,還能查看用戶在沒有解密數據的權限下所作的訪問數據失敗嘗試次數。同時,AWS KMS 還提供額外的安全控制,從而支持客戶努力符合 PCI-DSS、HIPAA/HITECH 和 FedRAMP 行業要求。
- 客戶端加密
- 使用 Amazon S3 加密客戶端之類的加密客戶端庫,
- 您可以保持對密鑰的控制並使用您選擇的加密庫完成對象客戶端側的加密和解密。一些客戶傾向於對加密和解密對象擁有端到端的控制權;這樣一來,只有經過加密的對象纔會通過互聯網傳輸到 Amazon S3。如果您想掌握對加密密鑰的控制權,應該使用客戶端庫,這樣便可實施或使用客戶端加密庫,同時在將對象傳輸到 Amazon S3 進行儲存之前需要對其進行加密。
- 數據在存入S3前已經被客戶應用程序加密,除了用戶自己進行完全管理外,也可以選擇使用AWS KMS進行密鑰管理
- 是嵌入AWS開發工具包中的一組開源API取×××源的加密工具,客戶端將從KMI中提供一個密鑰,作爲S3調用的一部分用於加密或解密
- 通過AWS EMR 數據寫入 S3時,可以使用S3DistCp請求服務器端加密,也可以在寫入前進行客戶端加密,需要將S3DistCP複製到EMR集羣裏
數據訪問審計
- 可以選擇爲存儲桶配置創建訪問日誌記錄
- 也可以利用CloudTrail監控訪問日誌。
Amazon Macie
- Amazon Macie 是一種支持 AI 技術的安全服務,可以幫助您通過自動發現、分類和保護存儲在 Amazon S3 中的敏感數據來防止數據丟失。
- Amazon Macie 使用機器學習來識別敏感數據(例如,個人身份信息 [PII] 或知識產權),分配業務價值,提供此數據的存儲位置信息及其在組織中的使用方式信息
- Amazon Macie 爲您提供一種自動化和低接觸的方式來發現和分類業務數據。Amazon Macie 識別客戶在其 S3 存儲桶中的對象,並將對象內容流式傳輸到內存中進行分析。當需要對複雜文件格式進行更深入的分析時,Amazon Macie 將下載對象的完整副本,並在短時間內保存,直到完成對象的全面分析。
- Amazon Macie 可持續監控數據訪問活動異常,並在檢測到未經授權的訪問或意外數據泄漏風險時發出警報。通過模板化的 Lambda 函數進行控制,可在發現可疑行爲或對實體或第三方應用程序進行未經授權的數據訪問時撤銷訪問或觸發密碼重置策略。發出警報時,您可以使用 Amazon Macie 進行事件響應,並使用 Amazon CloudWatch Events 迅速採取行動,保護您的數據。
AWS S3 Glacier
概述
- 成本極低的歸檔服務
- 不支持實時讀取,通常需要3-5個小時完成檢索,但可以使用加急檢索(1-5分鐘)
- 支持傳統磁帶的TAR歸檔和ZIP文件歸檔
- 每個AWS賬號支持1000個存檔庫,每個存檔庫可以無限量支持存檔文件,每個存檔文件1KB-40TB,每個文件需要額外32K+8K用於索引和元數據。
- 達到11個9的數據持久性
- Glacier數據是默認加密
- 按照存儲容量和檢索容量收費
- 最少存儲90天,否則需要收取提前刪除費
屬性
Archives 檔案
- 每個檔案最大支持40TB數據
- 每個檔案有唯一檔案ID,但不支持用戶友好的存檔名稱
- 歸檔創建完成後,無法被修改
Vaults保管庫
- 存放歸檔的容器,每個賬戶最多擁有1000個Vault
- 基於Vault可以實現訪問策略控制,支持IAM策略
Vaults Locks 保管庫鎖
- 強制執行各個Vaults的合規性策略,包括一次寫入多次讀取控件
- 一旦鎖定,策略將不可改變
數據檢索
- 每月可以免費檢索10GB的歸檔數據
-
需要使用Amazon S3 API 或 S3 控制檯來對Glacier 進行檢索和操作
- 標準檢索 3-5個小時
- 批量檢索 5-12小時
- 加急檢索 1-5分鐘,通過預置容量保證每5分鐘執行3次加急檢索
- 建議使用策略來限制檢索數據大小以確保經濟性
- 讀取Glacier 數據會在S3-IA中創建一個臨時副本
- 檢索部分存檔時,只要提取的範圍和整個文檔的哈希樹對齊就能驗證文檔的完整性
- 只可以維護一份Glacier的數據索引來列出所有存檔清單,一天更新一次
數據傳輸和訪問
- 所有到Glacier的數據傳輸都是SSL加密的,不管是對內還是對外
- 通過文件庫訪問策略在資源級別設計權限
- 使用IAM在用戶權限級別設計權限
- 僅允許自身的AWS賬戶及授權的IAM用戶可以對Glacier 進行訪問,但可以供IAM Role授予跨賬戶只讀權限
Glacier Select
- Amazon S3 Glacier Select 是一項功能,可讓您對存儲在 Amazon S3 Glacier 中的數據運行查詢,而不需要將整個對象恢復到 Amazon S3 等較熱的層。
- 藉助 Amazon S3 Glacier Select,您現在可以使用 SQL 子集直接對 Amazon S3 Glacier 中的數據進行篩選和基本查詢。
- 您提供 SQL 查詢和 Amazon S3 Glacier 對象列表,Amazon S3 Glacier Select 將就地運行查詢,並將輸出結果寫入您在 Amazon S3 中指定的存儲桶
AWS上存儲的文件生命週期策略

Elastic Block Store (EBS)
概述
- EBS僅在單個可用區有效
- 每個EBS塊會在可用區內自動複製,以提供高持久和高可用。
- EBS卷可以掛載到EC2,一次只能將EBS連接到一個EC2
- 要共享磁盤卷,需要使用EFS
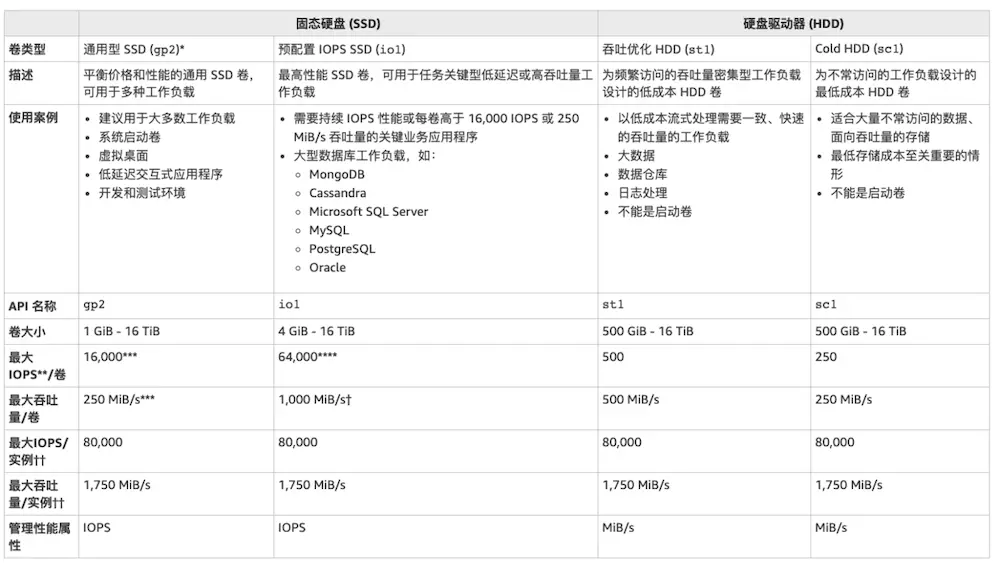
EBS類型
-
磁性卷(Megnetic Volume)
- 最低的性能和最經濟的存儲
- EBS磁盤大小從1GB - 1TB 不等,不管實際存儲大小,均按預配置存儲收費
- 平均支持100 IOPS,但最大可突破到數百IOPS,吞吐量 40-90MB
- 適用於 不常訪問數據的工作負載,連續讀取需要低成本存儲的情況
-
通用SSD (gp2)
- 經濟高效的存儲,適合各種工作負載
- 容量範圍從1GB到16TB
- 每GB提供3個IOPS基準性能,上限爲10000IOPS,吞吐量160MB
- 1TB以下可以支持突破3000IOPS,如當有500G硬盤標準IO爲1500IOPS,在不使用磁盤時做IO信用積累,用於在大量IO是採用爆裂行爲至3000IOPS
- 無論實際使用多少容量,都按照預配置容量收費
- 支持掛載多個卷條帶化實現更高性能
- 適用於:系統啓動卷,中小型數據庫,開發和測試環境
-
預置IOPS SSD卷 (lo1)
- 適合於對存儲性能、隨機IO一致性非常敏感的應用,即IO密集型工作負載,如大型數據庫
- 容量範圍從4GB 到 16TB
- IOPS上限爲容量的30倍或32000IOPS, 吞吐量 320MB
- 可以通過RAID0進行卷分割
- 支持掛載多個卷條帶化實現高性能,最大75000IOPS
- 用戶需要對預置的磁盤大小和IOPS進行付費
-
吞吐量優化HDD (st1)
- 適用於頻繁訪問、吞吐量密集型的工作負載的高性能低成本HDD
- 容量範圍 500GB - 16GB
- 最大IOPS 500, 最大吞吐量 500MB/s
-
冷硬盤 (sc1)
- 容量範圍 500GB - 16GB
- 較少訪問的工作負載,IOPS 250 , 最大吞吐量250MB
-
EBS優化實例
- 使用任何標準EBS之外的數據卷掛載,都建議使用基於EBS優化的實例。
- EBS優化實例需要爲每小時租用支付額外一小筆費用
保護數據
-
數據快照
- 無論任何類型的卷,都可以採用EBS快照進行備份,並存儲在S3中
- 快照是增量備份, 但每個快照文件利用快照鏈接是獨立的可恢復的
- 快照本身免費,僅需爲快照數據存儲付費
- 快照完成後可繼續操作數據庫,但快照文件在傳輸完成之前將無法進行下一次快照
- 快照存儲雖然採用和S3相同技術,但是並不能像S3一樣訪問和管理,必須採用專門的快照管理功能
-
數據恢復
- 快照恢復只能在當前區域操作,如果要跨區域恢復快照,需要先跨區域拷貝快照
- 快照恢復會首先創建卷,然後在逐塊恢復數據,優先訪問的塊會被優先恢復
- 數據第一次從快照恢復的時候,其讀取速率會較慢
- 數據快照可以用來作爲當前EBS卷的擴容操作,即先做快照,再往新大小的捲上恢復快照
- 當數據卷從當前實例中被分離後,即可掛載到新的實例,快照恢復卷本身就是個分離卷
-
加密選項
- ESS掛載前需要被指定加密選項
- EBS卷加密通常使用KMS來管理密鑰
- 數據通常會在未訪問時被自動加密,所以讀取非加密數據和加密數據的各方面性能是一致的
- 從加密卷獲取的快照會被自動加密,加密快照文件本身也會被加密存儲
- 不能對已存在的捲進行加密,需要對其快照進行加密恢復成一個新的卷, 也可以將一個未加密快照拷貝成一個加密快照
- EBS根卷默認不能加密,需要使用第三方軟件加密
- 除根卷之外的其他卷是可以加密的
EBS Volume 屬性
- EBS Root Volume必須在關機狀態下進行掛載和卸載,但是Addtional Volume可以進行在線掛載刪除
- EBS數據是是持久性的,但是默認刪除EC2會自動刪除EBS的數據,可手工選擇保留
- EC2關機後 EBS數據存儲會持續計費
EBS 安全性
- EBS 卷的訪問權限僅限於創建它的AWS賬戶以及授權的IAM賬戶
- EBS快照可以有限制的分享給其他賬戶,但需要謹慎
- EBS卷建立時是未格式化設備,所有數據都被擦除
- EBS卷可以支持用戶定製化的擦除數據
- 建議對EBS數據用AES-256進行加密及其快照
提升EBS性能
-
確保選擇了可以支持EBS優化的實例
- C3,R3,M3會產生額外成本
- M4,C4,C5和D2是免費支持的
- 關閉EBS的RAID0提高吞吐量
- 儘可能減少或者進行有計劃的Snapshot,特別對於HDD
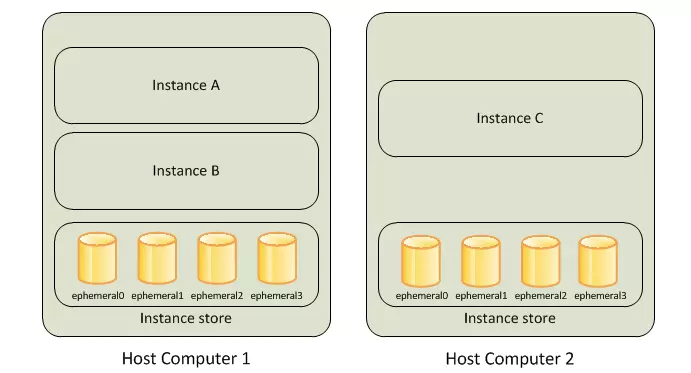
實例存儲
概述
- 只有部分EC2實例支持實例存儲
- 掛載在EC2下面的臨時塊級存儲
- 主要用於臨時存儲頻繁修改的信息: 緩衝區、緩存、臨時數據和其他臨時內容
- EC2可掛載的存儲大小取決於實例類型,最大可掛載24個2TB的實例存儲,也有HDD和SSD可選,這都是與實例本身綁定的,無需另行付費
- 實例終止或停止,底層磁盤失效都會導致實例存儲數據丟失
- 實例存儲允許重啓,但不允許停止
- 支持用戶自定義配置RAID0/1/5等
- 雖然可以通過RAID或HDFS等方式支持冗餘,但是對於持久性數據仍然建議使用更持久的解決方案如S3或EBS
EFS (Elastic File System)
概述
- 支持GB-PB的自動擴展的數據容量
- 提供延遲低每秒多GB並行的性能,並且支持預置吞吐量
- 實現實例間的數據共享
- 支持Network File System vesion 4 (NFSv4) 協議
- EFS自動分配全局唯一ID,所以命名無需唯一
- 使用掛載方式+文件系統的DNS連接到EC2
- EC2和EFS必須在同一個安全組裏面才能掛載
- 只爲使用的EFS份額付費
- 可以同時間支持成千上萬的NFS連接
- 支持一個到上千個EC2掛載同一個EFS
- EFS的數據會保存在一個區域內的多個可用區
- EFS除了能夠掛載到EC2,還支持掛載到本地的服務器(ClassicLink)
-
數據從本地移動到EFS
- 可以使用Direct Connect
- 使用DataSync 使用專用協議來加速和保護通過 Internet 或 AWS Direct Connect 傳輸的數據,速度比開源工具快 10 倍。使用 DataSync,您可以執行一次性數據遷移,傳輸本地數據以進行及時的雲端分析,並自動複製到 AWS 以進行數據保護和恢復
- 區域級服務,在不同可用區之間進行冗餘複製(可手工選擇)
- 可以利用AWS Backup來安排自動增量式備份
- 讀寫一致性(Read After Write Consistency)
- 支持使用IAM來控制和管理文件系統
- 支持使用KMS進行靜態數據加密