




我們知道,大數據的計算模式主要分爲批量計算(batch computing)、流式計算(stream computing)、交互計算(interactive computing)、圖計算(graph computing)等。其中,流式計算和批量計算是兩種主要的大數據計算模式,分別適用於不同的大數據應用場景。
目前主流的流式計算框架有Storm、Spark Streaming、Flink三種,其基本原理如下:
Apache Storm
在Storm中,需要先設計一個實時計算結構,我們稱之爲拓撲(topology)。之後,這個拓撲結構會被提交給集羣,其中主節點(master node)負責給工作節點(worker node)分配代碼,工作節點負責執行代碼。在一個拓撲結構中,包含spout和bolt兩種角色。數據在spouts之間傳遞,這些spouts將數據流以tuple元組的形式發送;而bolt則負責轉換數據流。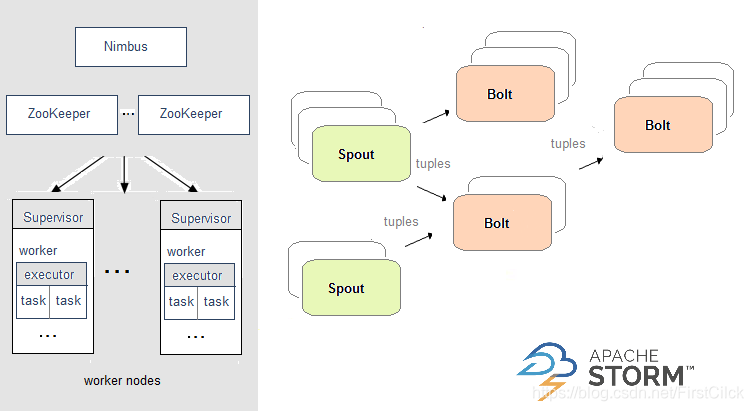
Apache Spark
Spark Streaming,即核心Spark API的擴展,不像Storm那樣一次處理一個數據流。相反,它在處理數據流之前,會按照時間間隔對數據流進行分段切分。Spark針對連續數據流的抽象,我們稱爲DStream(Discretized Stream)。 DStream是小批處理的RDD(彈性分佈式數據集), RDD則是分佈式數據集,可以通過任意函數和滑動數據窗口(窗口計算)進行轉換,實現並行操作。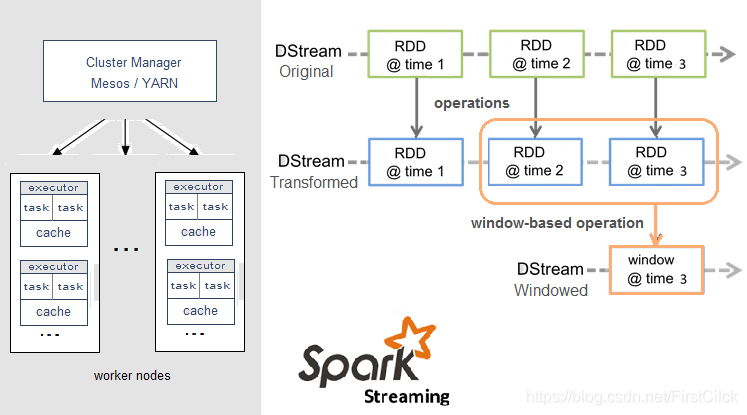
Apache Flink
針對流數據+批數據的計算框架。把批數據看作流數據的一種特例,延遲性較低(毫秒級),且能夠保證消息傳輸不丟失不重複。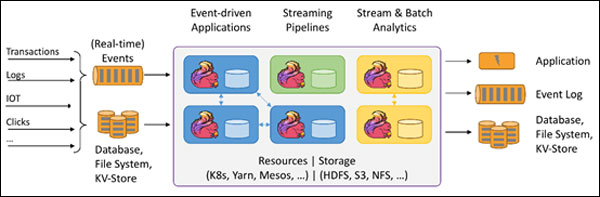
Flink創造性地統一了流處理和批處理,作爲流處理看待時輸入數據流是**的,而批處理被作爲一種特殊的流處理,只是它的輸入數據流被定義爲有界的。Flink程序由Stream和Transformation這兩個基本構建塊組成,其中Stream是一箇中間結果數據,而Transformation是一個操作,它對一個或多個輸入Stream進行計算處理,輸出一個或多個結果Stream。
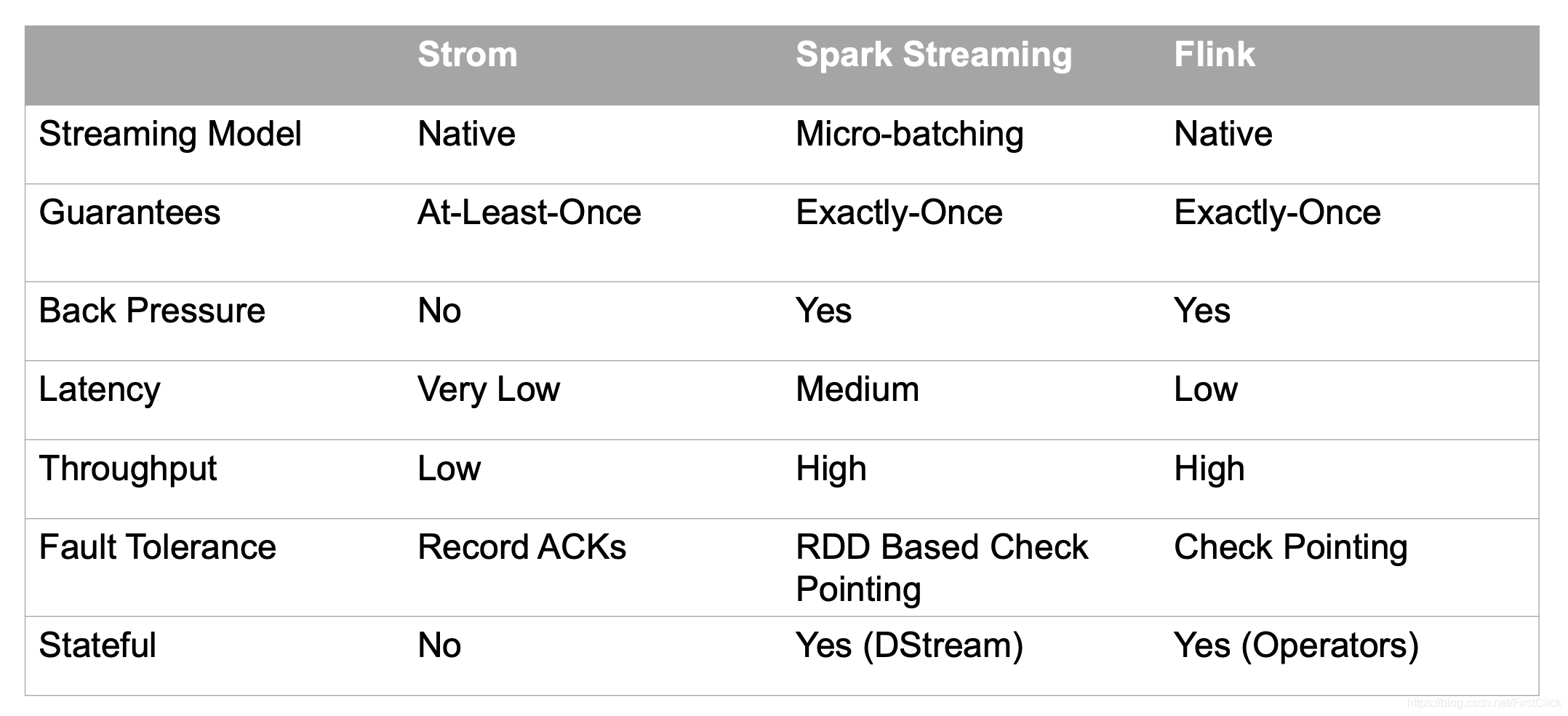
這三種計算框架的對比如下:
參考文章: