




1 日誌採集概述
1 日誌採集流程
生產過程中會產生大量的系統日誌,應用程序日誌,安全日誌等等日誌,通過對日誌的分析可以瞭解服務器的負載,健康狀況,可以分析客戶的分佈情況,客戶的行爲,甚至於這些分析可以做出預測
一般採集流程
日誌產出---採集 (logstash,flume,scribe) --- 存儲---分析---存儲(數據庫、NoSQL)---可視化
2 半結構化數據
日誌是半結構化數據,是有組織的,有格式的數據,可以分割成行和列,就可以當做表理解和處理了,當然也可以分析裏面的數據
文本分析
日誌是文本文件,需要依賴文件IO,字符串操作,正則表達式等技術,通經這些技術就能夠把日誌中需要的數據提取出來。
2 一般字符串格式處理日誌
1 一般匹配模式處理web日誌
#!/usr/bin/poython3.6
#conding:utf-8
lines='''192.168.1.3 - - [01/Jul/2019:21:20:48 +0800] \
"GET /favicon.ico HTTP/1.1" 404 209 "-" \
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36"'''
flag=False
lst=[]
tmp = ""
for word in lines.split():
if (word.startswith('[') or word.startswith('"')) and not flag:
if word.endswith('"') or word.endswith(']'): # 此處添加判斷是爲了避免只出現一個單詞的情況
lst.append(word.strip('"[]')) # 使用此表示將" 或 [] 都替換成空
continue
else:
tmp=word[1:] #去掉前面的相關符號
flag=True # 此處置flag爲True的含義是不讓上述匹配直接進入其中
continue
# 當flag=True時執行如下操作
if flag:
if word.endswith(']') or word.endswith('"'):
tmp+=" "+word[:-1] # 去除最後的數據,此處加空格是爲了顯示好看
lst.append(tmp)
tmp=""
flag=False # 最終得到結果後置位False
continue
else:
tmp+= " " + word
continue
lst.append(word)
print (lst)結果如下
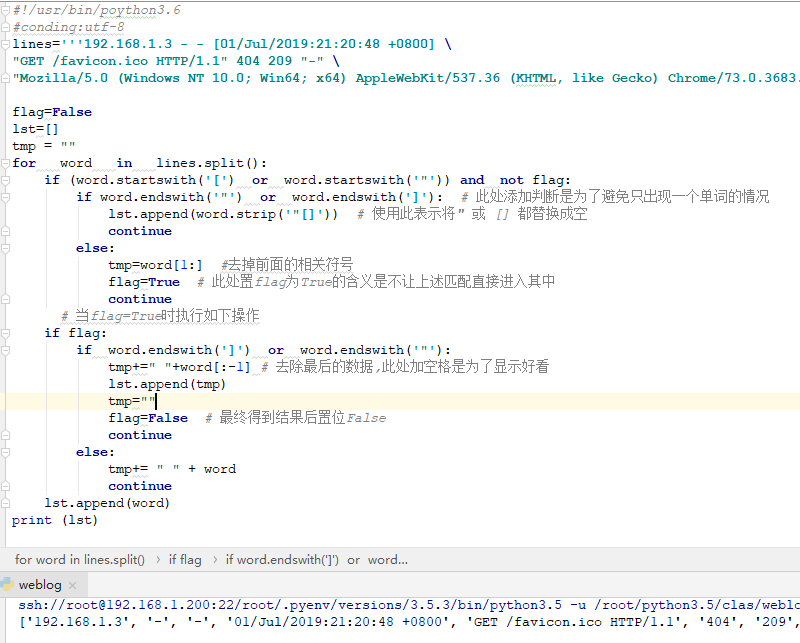
2 顯示結果爲字典
#!/usr/bin/poython3.6
#conding:utf-8
import datetime
lines='''192.168.1.3 - - [01/Jul/2019:21:20:48 +0800] \
"GET /favicon.ico HTTP/1.1" 404 209 "-" \
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36"'''
flag=False
lst=[]
tmp = ""
for word in lines.split():
if (word.startswith('[') or word.startswith('"')) and not flag:
if word.endswith('"') or word.endswith(']'): # 此處添加判斷是爲了避免只出現一個單詞的情況
lst.append(word.strip('"[]')) # 使用此表示將" 或 [] 都替換成空
continue
else:
tmp=word[1:] #去掉前面的相關符號
flag=True # 此處置flag爲True的含義是不讓上述匹配直接進入其中
continue
# 當flag=True時執行如下操作
if flag:
if word.endswith(']') or word.endswith('"'):
tmp+=" "+word[:-1] # 去除最後的數據,此處加空格是爲了顯示好看
lst.append(tmp)
tmp=""
flag=False # 最終得到結果後置位False
continue
else:
tmp+= " " + word
continue
lst.append(word)
def fm_time(strtime:str): # 格式化時間
fmtstr = "%d/%b/%Y:%H:%M:%S %z"
return datetime.datetime.strptime(strtime,fmtstr)
def fm_request(request:str):
return dict(zip(('method','url','protocol'),request.split())) # 此處返回一個字典的組合
names=['remove','','','datetime','request','status','size','','user-agent']
ops=[None,None,None,fm_time,fm_request,int,int,None,str]
d={}
for k,v in enumerate(lst):
if ops[k]:
d[names[k]]=ops[k](v)
print (d)結果如下
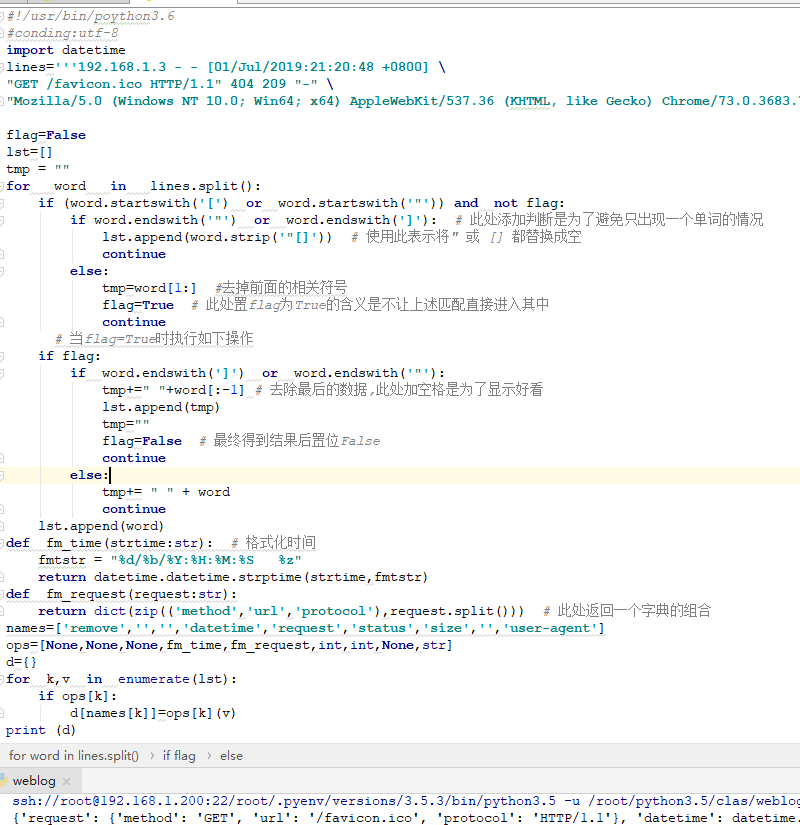
3 正則表達式處理日誌
1 基本顯示
#!/usr/bin/poython3.6
#conding:utf-8
import datetime
import re
lines='''192.168.1.3 - - [01/Jul/2019:21:20:48 +0800] \
"GET /favicon.ico HTTP/1.1" 404 209 "-" \
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36"'''
pattern='''(?P<remote>[\d\.]{7,}) - - \[(?P<datetime>[^\[\]]+)\] "(?P<request>[^"]+)" (?P<status>\d+) (?P<size>\d+) "-" "(?P<useragent>[^"]+)"'''
regex=re.compile(pattern)
def extract(line):
return regex.match(line).groupdict()
ops={
'datetime': lambda strtime: datetime.datetime.strptime(strtime,'%d/%b/%Y:%H:%M:%S %z'),
'request': lambda request: dict(zip(('method','url','protocol'),request.split())),
'size': int,
'status' :int,
}
d={}
for k,v in extract(lines).items():
v1=ops.get(k,lambda x:x)(v)
d[k]=v1
print (d)
2 使用lamba 表達式結果如下
#!/usr/bin/poython3.6
#conding:utf-8
import datetime
import re
lines='''192.168.1.3 - - [01/Jul/2019:21:20:48 +0800] \
"GET /favicon.ico HTTP/1.1" 404 209 "-" \
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36"'''
pattern='''(?P<remote>[\d\.]{7,}) - - \[(?P<datetime>[^\[\]]+)\] "(?P<request>[^"]+)" (?P<status>\d+) (?P<size>\d+) "-" "(?P<useragent>[^"]+)"'''
regex=re.compile(pattern)
def extract(line):
return regex.match(line).groupdict()
ops={
'datetime': lambda strtime: datetime.datetime.strptime(strtime,'%d/%b/%Y:%H:%M:%S %z'),
'request': lambda request: dict(zip(('method','url','protocol'),request.split())),
'size': int,
'status' :int,
}
d={ k:ops.get(k,lambda x:x)(v) for k,v in extract(lines).items() }
print (d)結果和上述相同
4 時間窗口分析
1 概念
很多數據,如日誌,都是和時間相關的,都是按照時間順序產生的,產生的數據分析的時候,按照時間求值,其中interval 表示每一次求值的時間間隔,width 表示時間窗口寬度,指的是每一次求值的時間窗口寬度
2 模式
1 當width > interval 時,其會有重疊部分
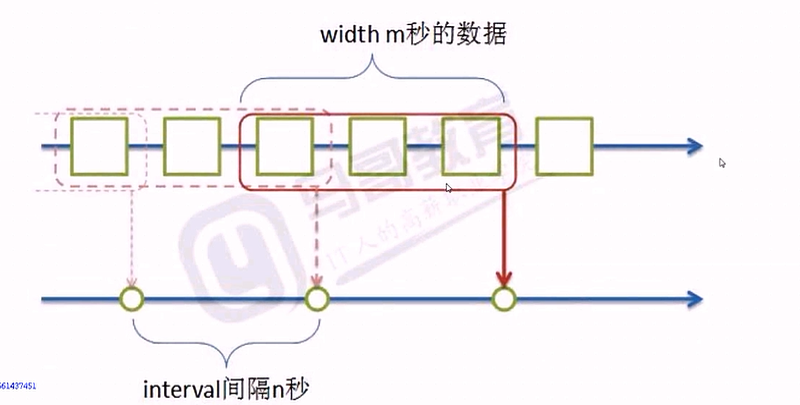
此種方式通常可用於統計日誌的相關性趨勢計算
2 當 width = interval 時,其剛好無重疊部分
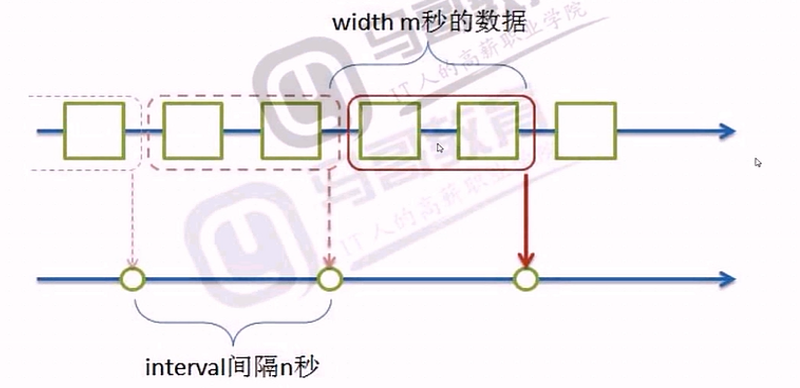
此種方式通常用於統計日誌的相關狀態碼訪問情況
3 當width < interval 時,其會有遺漏部分
數據分析基本程序結構
無限產生隨機函數,產生時間相關的數據,返回時+隨機數,每次去3個數據,求平均值
#!/usr/bin/poython3.6
#conding:utf-8
import datetime
import random
import time
# 產生數據的原函數
def Source():
while True:
yield { 'value':random.randint(1,100),'datetime':datetime.datetime.now()} # 此處返回時間
time.sleep(1)
s=Source()
# 定義產生數據的結果,並返回列表
itmes=[ next(s) for _ in range(3)]
# 處理函數
def handler(iterable:list):
vals=[x['value'] for x in iterable]
return sum(vals)/len(vals)
print (itmes)
print ("{:.2f}".format(handler(itmes)))3 窗口函數的實現
將上面獲取數據的程序擴展爲windows 函數,使用重疊方案,及wdith> interval
#!/usr/bin/poython3.6
#conding:utf-8
import datetime
import re
pattern='''(?P<remote>[\d\.]{7,}) - - \[(?P<datetime>[^\[\]]+)\] "(?P<request>[^"]+)" (?P<status>\d+) (?P<size>\d+) "-" "(?P<useragent>[^"]+)"'''
regex=re.compile(pattern)
def extract(line):
matcher=regex.match(line)
if matcher: #此處若匹配成立,則進行返回值處理
return { k:ops.get(k, lambda x: x)(v) for k, v in matcher.groupdict().items()}
ops={
'datetime': lambda strtime: datetime.datetime.strptime(strtime,'%d/%b/%Y:%H:%M:%S %z'),
'request': lambda request: dict(zip(('method','url','protocol'),request.split())),
'size': int,
'status' :int,
}
def load(path:str):
with open(path) as f:
for line in f:
d=extract(line) # 此處返回字典
if d: # 若字典存在,則返回,若不存在,則直接返回循環進行下一次
yield d
else:
continue
def windows(src,headler,wdith,interval):
# 時間相關處理
starttime=datetime.datetime.strptime('1970-01-01 01:01:01 +0800','%Y-%m-%d %H:%M:%S %z') # 默認時間窗口的起始值
current=datetime.datetime.strptime('1970-01-01 01:01:02 +0800','%Y-%m-%d %H:%M:%S %z') # 默認時間窗口的結束值
delta=datetime.timedelta(wdith-interval) # 此處獲取到的是時間的差值,此處是s,需要和上述的時間進行匹配
bugffer=[]
for line in src:
if line:
bugffer.append(line) # 此處獲取到的是在窗口內的數據的值
print (line)
current=line['datetime'] # 此處獲取starttime的初始值,用於選擇窗口的起始位置
if (current-starttime).total_seconds()>=interval: # 表示窗口大,可以進行相關的操作了
ret=headler(bugffer)
print (ret)
starttime=current
# bugffer=[ i for i in bugffer if current-delta < i['datetime']]
bugffer1=[] # 通過此臨時變量來存儲那些重疊的部分
for i in bugffer:
if current - delta < i['datetime']: # 此處若成立,則表明其已經進入到了重疊區域,可進行保留並進行下一次的計算
bugffer1.append(i)
bugffer=bugffer1
def donothing_handler(iterable:list):
print(iterable)
return iterable
windows(load('/var/log/httpd/access_log-20190702'),donothing_handler,10,5)5 分發
1 生產者消費者模型
對於一個監控系統,需要處理很多數據,包括日誌,被監控對象就是數據的生產者producer,數據的處理就是數據的消費者consumer
傳統的生產者消費者模型,生產者生產,消費者消費,但這種模型有些問題
開發的代碼耦合太高,如果生產規模變大,不易擴展,且生產者和消費者的速度很難匹配。
用消費者的速度來決定生產者的速度
當生產者生產過剩而消費者來不急處理時,便產生了問題 ,及解決的方式便是解耦,通過隊列來完成其之間的操作
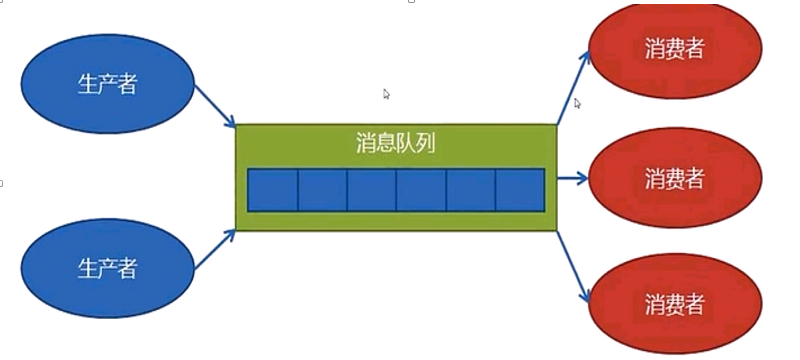
中間隊列形成了程序,做成了消息隊列MQ
2 消息隊列的基本類型
1 概述
1 一對一的發佈,及就是數據只能被一個消費者處理,及這個處理了這個數據,另一個則不能處理
2 一對多的發佈,同一個數據可以被多個消費者進行處理,此處猶如廣播類似
消息隊列內部分類:
消息需要分組,有的需要多個副本,有的需要一個副本。消息隊列中可能包含多個隊列
2 應用
不同模塊之間的通信,需要使用消息隊列,其中間需要加上消息中間鍵
消息隊列的作用:
1 程序之間實現程序的解耦
2 緩衝,防洪蓄水
3 queue 模塊--隊列
1 簡介
queue 模塊提供了一個先進先出的隊列queue
相關說明:
queue.Queue(maxsize=0)
創建FIFO隊列,返回Queue對象
maxsize 小於等於0,隊列長度無限制
2 相關方法
Queue.get(block=True,timeout=None)
從隊列中移除元素並返回這個元素
block爲阻塞,timeout爲超時
如果block爲True,是阻塞,timeout爲None就表示如果隊列中其需要提取的對應數據就一直阻塞下去
如果block爲True且timeout 有值,就阻塞到一定秒數拋出Empty異常
如果block 爲False,則是非阻塞,timeout將會被忽略,要麼成功返回一個元素,要麼就拋出empty 異常
Queue.get_nowait()
等價於get(False),也就是說要麼成功返回一個元素,要麼拋出empty異常,但是queue的這種阻塞效果,需要多線程的時候進行演示
Queue.put(item,block=True,timeout=None)
把一個元素添加到隊列中去
block=True,timeout=None,一直阻塞直到有空位放元素
block=True,timeout=5,阻塞5秒若沒空位則拋出異常。
block=False,timeout失效,立即返回,能put就put,不能則拋出異常Queue.put_nowait(item)
等價於put(item,False),也就是能put進去就put進去,不能則拋出異常
3 實例
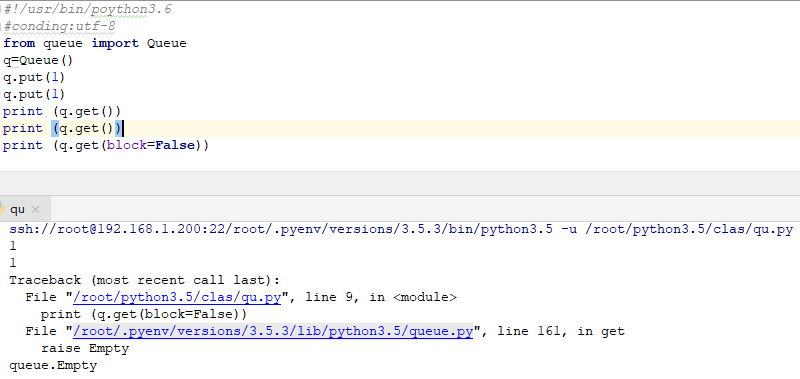
#!/usr/bin/poython3.6
#conding:utf-8
from queue import Queue
q=Queue()
q.put(1)
q.put(1)
print (q.get())
print (q.get())
print (q.get(block=False))結果如下
4 分發器的實現
1 概念
由生產者提供服務,消費者處理服務,當時間達到設置的時間後,其將自動交給handler進行處理,這就是分發器
分發器需要將數據發送給不同的消費者,此處需要和對應的消費者之間建立連接每個消費者的處理速度是不同的,消費者放需要進行處理的暫存處理,其需要防止到各自的暫存區域,每個消費者內部維護
分發器決定發送給誰,暫存器負責進行暫存處理
分發器中可以有隊列,也可以沒有
暫存區可使用隊列和列表,其主要取決於其的不同業務
當對於一個大系統時,需要在分發器中進行消息的暫存,來獲取一定的消息存儲量 ,其相當於大壩到水池的概念。
生產者(數據源)生產數據,緩衝到消息隊列中
2 數據處理流程
數據加載---數據提取---數據分析
處理大量數據的時候,對於一個數據源來說,需要多個消費者進行處理,但如何分配數據就是問題
3 相關流程
需要一個分發器,把數據分發給不同的消費者處理
每一個消費者拿到數據後,有自己的處理函數,所以要一種註冊機制,
如何註冊: 在調度器內部記錄有哪些消費者,記錄消費者自己的隊列
每一個消費者的統計方式是不同的,因此其統計結果也是各有差異,及就是handler的不同,其結果是不同的
分發: 輪詢,一對多副本發送,一個數據通過分發器,發送給n個消費者
線程
由於一條數據會被不同的註冊過的handler處理,因此最好的方式就是多線程一般遇到阻塞問題就會使用多線程,將處理數據的問題應用到多線程上去
進程: 程序獨立運行的一個空間
真正幹活的是線程,內存中保留着進程的相關的狀態,線程纔是真正跑的指令,
多個線程之間的CPU之間是調度的,但CPU的調度是操作系統的原因,優先級越高,分的時間越多,CPU實現的是分時的概念,對線程來說,CPU是不能被獨佔的。
5 線程配置
#!/usr/bin/poython3.6
#conding:utf-8
import datetime
import re
from queue import Queue
import threading
pattern='''(?P<remote>[\d\.]{7,}) - - \[(?P<datetime>[^\[\]]+)\] "(?P<request>[^"]+)" (?P<status>\d+) (?P<size>\d+) "-" "(?P<useragent>[^"]+)"'''
regex=re.compile(pattern)
def extract(line):
matcher=regex.match(line)
if matcher: #此處若匹配成立,則進行返回值處理
return { k:ops.get(k, lambda x: x)(v) for k, v in matcher.groupdict().items()}
ops={
'datetime': lambda strtime: datetime.datetime.strptime(strtime,'%d/%b/%Y:%H:%M:%S %z'),
'request': lambda request: dict(zip(('method','url','protocol'),request.split())),
'size': int,
'status' :int,
}
def load(path:str):
with open(path) as f:
for line in f:
d=extract(line) # 此處返回字典
if d: # 若字典存在,則返回,若不存在,則直接返回循環進行下一次
yield d
else:
continue
# 構建時間窗口
def windows(src:Queue,headler,wdith,interval):
# 時間相關處理
starttime=datetime.datetime.strptime('1970-01-01 01:01:01 +0800','%Y-%m-%d %H:%M:%S %z') # 默認時間窗口的起始值
current=datetime.datetime.strptime('1970-01-01 01:01:02 +0800','%Y-%m-%d %H:%M:%S %z') # 默認時間窗口的結束值
delta=datetime.timedelta(wdith-interval) # 此處獲取到的是時間的差值,此處是s,需要和上述的時間進行匹配
bugffer=[]
# for line in src:
while True:
data=src.get(block=True,timeout=15)
if data:
bugffer.append(data) # 此處獲取到的是在窗口內的數據的值
current=data['datetime'] # 此處獲取starttime的初始值,用於選擇窗口的起始位置
if (current-starttime).total_seconds()>=interval: # 表示窗口大,可以進行相關的操作了
ret=headler(bugffer)
print (ret)
starttime=current
# bugffer=[ i for i in bugffer if current-delta < i['datetime']]
bugffer1=[] # 通過此臨時變量來存儲那些重疊的部分
for i in bugffer:
if current - delta < i['datetime']: # 此處若成立,則表明其已經進入到了重疊區域,可進行保留並進行下一次的計算
bugffer1.append(i)
bugffer=bugffer1
def donothing_handler(iterable:list):
print(iterable)
return iterable
# 構建分發器
def dispather(src):
queues=[] # 隊列的列表,用於保存其中的隊列
threads=[] # 線程列表,用於保存線程
def reg(handler,width,interval): # 註冊流程
q=Queue() # 分配隊列
queues.append(q) #爲了後期能夠調用,需要將其保留到列表中
t=threading.Thread(target=windows,args=(q,handler,width,interval)) #此處是多線程,此處執行了一個函數
threads.append(t)
def run():
for t in threads:
t.start()
for x in src:
for q in queues:
q.put(x) # 所有的queues中推送q,此處便是一對多的情況,此處啓動數據引擎
return reg,run
reg,run=dispather(load('/var/log/httpd/access_log-20190702'))
reg(donothing_handler,10,5)
run() #此處啓動並運行數據引擎6 狀態碼分析
1 狀態碼簡介
狀態碼中包含了很多信息,如
304,服務其收到客戶端提交的請求參數,發現資源未變化,要求瀏覽器使用靜態資源的緩存
404,服務器找不到請求
304,佔比大,說明靜態緩存效果鳴謝,404佔比大,說明出現了錯誤連接,或者常使嗅探網絡資源
如果400,500佔比突然增加,網站一定出問題了。
2 相關程序處理
#!/usr/bin/poython3.6
#conding:utf-8
import datetime
import re
from queue import Queue
import threading
from collections import defaultdict
pattern='''(?P<remote>[\d\.]{7,}) - - \[(?P<datetime>[^\[\]]+)\] "(?P<request>[^"]+)" (?P<status>\d+) (?P<size>\d+) "-" "(?P<useragent>[^"]+)"'''
regex=re.compile(pattern)
def extract(line):
matcher=regex.match(line)
if matcher: #此處若匹配成立,則進行返回值處理
return { k:ops.get(k, lambda x: x)(v) for k, v in matcher.groupdict().items()}
ops={
'datetime': lambda strtime: datetime.datetime.strptime(strtime,'%d/%b/%Y:%H:%M:%S %z'),
'request': lambda request: dict(zip(('method','url','protocol'),request.split())),
'size': int,
'status' :int,
}
def load(path:str):
with open(path) as f:
for line in f:
d=extract(line) # 此處返回字典
if d: # 若字典存在,則返回,若不存在,則直接返回循環進行下一次
yield d
else:
continue
# 構建時間窗口
def windows(src:Queue,headler,wdith,interval):
# 時間相關處理
starttime=datetime.datetime.strptime('1970-01-01 01:01:01 +0800','%Y-%m-%d %H:%M:%S %z') # 默認時間窗口的起始值
current=datetime.datetime.strptime('1970-01-01 01:01:02 +0800','%Y-%m-%d %H:%M:%S %z') # 默認時間窗口的結束值
delta=datetime.timedelta(wdith-interval) # 此處獲取到的是時間的差值,此處是s,需要和上述的時間進行匹配
bugffer=[]
# for line in src:
while True:
data=src.get(block=True,timeout=15)
if data:
bugffer.append(data) # 此處獲取到的是在窗口內的數據的值
current=data['datetime'] # 此處獲取starttime的初始值,用於選擇窗口的起始位置
if (current-starttime).total_seconds()>=interval: # 表示窗口大,可以進行相關的操作了
ret=headler(bugffer)
print (ret)
starttime=current
# bugffer=[ i for i in bugffer if current-delta < i['datetime']]
bugffer1=[] # 通過此臨時變量來存儲那些重疊的部分
for i in bugffer:
if current - delta < i['datetime']: # 此處若成立,則表明其已經進入到了重疊區域,可進行保留並進行下一次的計算
bugffer1.append(i)
bugffer=bugffer1
def donothing_handler(iterable:list):
print(iterable)
return iterable
def status_handler(iterable:list):
status=defaultdict(lambda :0)
for i in iterable:
key = i['status']
status[key]+=1
total=sum(status.values())
return {k:v/total*100 for k,v in status.items()}
# 構建分發器
def dispather(src):
queues=[] # 隊列的列表,用於保存其中的隊列
threads=[] # 線程列表,用於保存線程
def reg(handler,width,interval): # 註冊流程
q=Queue() # 分配隊列
queues.append(q) #爲了後期能夠調用,需要將其保留到列表中
t=threading.Thread(target=windows,args=(q,handler,width,interval)) #此處是多線程,此處執行了一個函數
threads.append(t)
def run():
for t in threads:
t.start()
for x in src:
for q in queues:
q.put(x) # 所有的queues中推送q,此處便是一對多的情況,此處啓動數據引擎
return reg,run
reg,run=dispather(load('/var/log/httpd/access_log-20190702'))
# reg(donothing_handler,10,5)
reg(status_handler,5,5)
run() #此處啓動並運行數據引擎7 瀏覽器分析
1 簡介
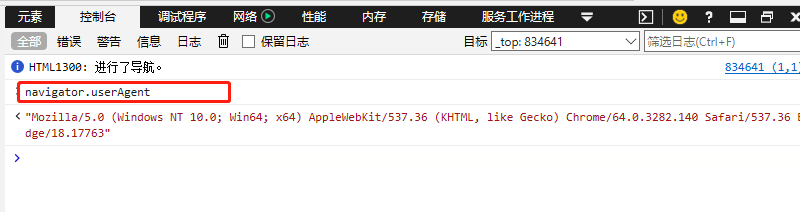
useragent 這裏是指,軟件按照一定的格式像遠端服務器提供一個標識自己的字符串,在http協議中,使用user-agent字段傳送這個字符串
通過參數navigator.userAgent 可在瀏覽器的控制檯中獲取userAgent
2 信息提取及模塊安裝
需要安裝的模塊
pyyaml,ua-parser,user-agents模塊
安裝pip install pyyaml ua-parser user-agents3 基礎實例
#!/usr/bin/poython3.6
#conding:utf-8
from user_agents import parse
u='''Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36'''
ua=parse(u)
print (ua.browser)
print (ua.browser.family,ua.browser.version_string)#獲取瀏覽器類型和版本結果如下

4 具體代碼如下
#!/usr/bin/poython3.6
#conding:utf-8
import re
import datetime
from queue import Queue
import threading
from pathlib import Path
from user_agents import parse
from collections import defaultdict
pattern = '''(?P<remote>[\d\.]{7,}) - - \[(?P<datetime>[^\[\]]+)\] "(?P<request>[^"]+)" (?P<status>\d+) (?P<size>\d+) "([^"]+)" "(?P<useragent>[^"]+)"'''
regex = re.compile(pattern) # 此處編譯一次就夠了
def extract(line)->dict:
matcher=regex.match(line)
if matcher:
return {k:ops.get(k,lambda x:x)(v) for k,v in matcher.groupdict().items()}
ops= {
'datetime' :lambda timestr:datetime.datetime.strptime(timestr,"%d/%b/%Y:%H:%M:%S %z"), # 此處得到的是datatime,
'status': int,
'size' : int,
'request':lambda request:dict(zip(('method','url','protocol'),request.split())),
'useragent': lambda useragent : parse(useragent)
}
def openfile(path:str):
with open(path) as f:
for line in f:
d = extract(line)
if d:
yield d
else:
# TODO 不合格的數據
continue
def load(*path): # 需要可迭代對象
for file in path:
p = Path(file)
if not p.exists(): # 判斷是否存在文件或目錄
continue # 此處不存在,直接返回下一個循環
if p.is_dir():
for x in p.iterdir():
if x.is_file(): # 此處若是文件,則進行相關的處理,如果是目錄,則不進行處理
yield from openfile(str(x)) #多個處理完,因此不是使用return直接輸出,需要通過列表實現
elif p.is_file():
yield from openfile(str(p))
############################################################## 窗口器
def windows(src:Queue,handler,wdith:int,interval:int):
#{'request': {'protocol': 'HTTP/1.1', 'url': '/favicon.ico', 'method': 'GET'}, 'remote': '192.168.1.3', 'useragent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36', 'status': 404, 'datetime': datetime.datetime(2019, 6, 20, 23, 4, 16, tzinfo=datetime.timezone(datetime.timedelta(0, 28800))), 'size': 209}
# 和時間求值相關
start =datetime.datetime.strptime('1970/01/01 01:01:01 +0800','%Y/%m/%d %H:%M:%S %z')
current=datetime.datetime.strptime('1970/01/01 01:01:02 +0800','%Y/%m/%d %H:%M:%S %z')
# 和緩衝區相關
buffer=[] # 數據的存儲大小,存儲一點,消耗一點
delta=datetime.timedelta(wdith-interval) #此處返回是一個int類型,但其需要的是時間類型,因此此處需要進行類型轉換
# for x in src: # 真實的q中是沒有迭代的
while True:
data=src.get() #當其沒有數據時會阻塞,其是在另一個線程中,不會影響主線程的顯示
if data:
buffer.append(data) # 此處插入的是一個字典,若對於多個情況,則可通過傳入整個字典比較合適
current= data['datetime'] # 對觀察數據的時間進行查看
if (current - start).total_seconds()>=interval: # 若其相減大於 interval,則滿足條件,則可以開始進行計算了,查看時間走出的情況
ret= handler(buffer) # 此處進行相關的計算即可
print (ret) #返回值,返回結束時間和平均值
start = current # 其變化必須在處理完成後達成
# buffer的處理,當前時間減去delta,窗口是時間範圍留下的數據形成的
buffer=[ i for i in buffer if current - delta < i['datetime'] ] # 當前時間減去delta就是buffer中需要留下來的部分
# 如果相減之後值小於當前進行的值,則表示其應該保留,否則應該刪除
def donothing_handler(iterable:list):
print (iterable)
return (iterable)
#此處是生成器
def status_handler(iterable:list):
d={}
for item in iterable: # 獲取到的元素是一個字典
key= item['status'] # 此處表示狀態碼
if key not in d.keys(): # 取出其中的值,真實的是需要多個狀態碼的
d[key]=0
d[key]+=1
total=sum(d.values())
return {k:v/total*100 for k,v in d.items()} # 做的是某一個時間點的小統計
# 瀏覽器分析
ua_dict=defaultdict(lambda :0) # 創建默認字典
def browser_handler(iterable:list):
for item in iterable:
ua = item['useragent']
key= (ua.browser.family,ua.browser.version_string) #瀏覽器的名稱和版本號
ua_dict[key]+=1
return ua_dict
######################################################## 分發源
# windows(load('/var/log/httpd/access_log'),donothing_handler,10,5) #此處不用了
#創建分發器
def dispatcher(src):
# 隊列的列表,用於保存隊列
queues=[]
threads=[]
def reg(handler,width,interval): # 就差一個q
q=Queue() #分配一個郵箱
queues.append(q) # 爲了後期能夠調用,需要將其保留到列表中
# windows(q,handler,width,interval) # 註冊一次,需要分配一個q
t = threading.Thread(target=windows,args=(q,handler,width,interval)) # 此處是多線程,此處是執行了一個函數
threads.append(t)
def run():
for t in threads: #此處需要運行
t.start()
for x in src:
for q in queues:
q.put(x) # 所有的queues中推送q,此處便是一對多的情況,此處啓動數據引擎
return reg,run
reg,run=dispatcher(load('/var/log/httpd/access_log-20190702'))
# reg註冊窗口,每個窗口有不同的參數handler,width,interval
# reg(donothing_handler,10,5)
# reg(status_handler,10,5)
reg(browser_handler,5,5) # 窗口調用
run() # 此處啓動並運行數據引擎