




需求背景
業務系統將各類的報表和統計數據存放於ES中,由於歷史原因,系統每天均以全量方式進行統計,隨着時間的推移,ES的數據存儲空間壓力巨大。同時由於沒有規劃好es的索引使用,個別索引甚至出現超過最大文檔數限制的問題,現實情況給運維人員帶來的挑戰是需要以最小的代價來解決這個問題。下面以內網開發、測試環境舉例使用python腳本解決這個問題。
Each Elasticsearch shard is a Lucene index. There is a maximum number of documents you can have in a single Lucene index. As of LUCENE-5843, the limit is 2,147,483,519 (= Integer.MAX_VALUE - 128) documents. You can monitor shard sizes using the _cat/shards API.
實現思路
es本身支持“_delete_by_query”的形式對查詢出來的數據進行刪除。首先我們通過”_cat/indices“入口獲取當前es服務上所有的索引信息。
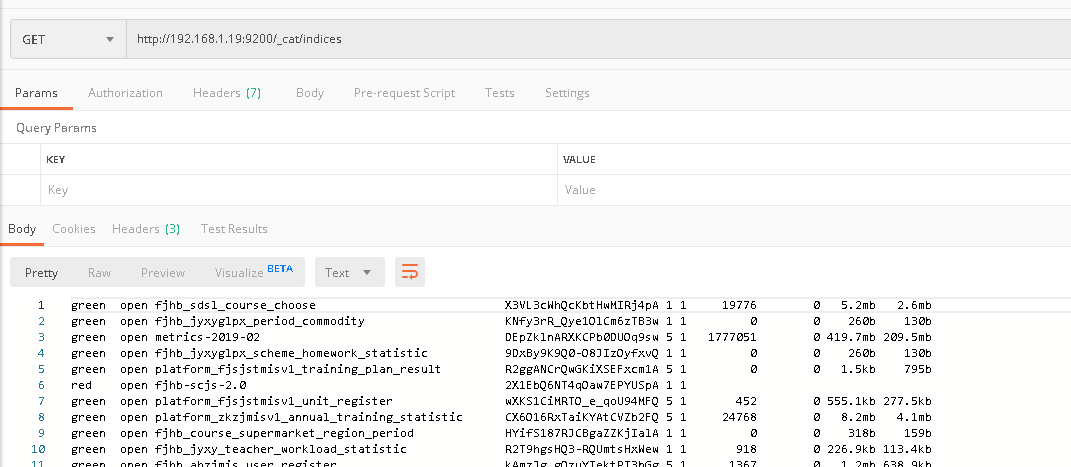
第一列表示索引當前的健康狀態
第三列表示索引的名稱
第四列表示索引在服務器上的存儲目錄名
第五、六列表示索引的副本數和分片信息
第七列表示當前索引的文檔數
最後兩列分別表示當前索引的存儲佔用空間,倒數第二列等於倒數第一列乘以副本數
其次我們通過curl形式拼接成刪除命令發送給es服務端執行,其中createtime字段爲數據的產生時間,單位爲毫秒
curl -X POST "http://192.168.1.19:9400/fjhb-surveyor-v2/_delete_by_query?pretty" -H 'Content-Type: application/json' -d '
{"query":{ "range": {
"createTime": {
"lt": 1580400000000,
"format": "epoch_millis"
}
}
}}'具體實現
#!/usr/bin/python
# -*- coding: UTF-8 -*-
###導入必須的模塊
import requests
import time
import datetime
import os
#定義獲取ES數據字典函數,返回索引名和索引佔用存儲空間大小字典
def getData(env):
header = {"Content-Type": "application/x-www-form-urlencoded",
"user-agent": "User-Agent:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36"
}
data = {}
with open('result.txt','w+') as f:
req = requests.get(url=env+'/_cat/indices',headers=header).text
f.write(req)
f.seek(0)
for line in f.readlines():
data[line.split()[2]] = line.split()[-1]
return data
#定義unix時間轉換函數,以毫秒形式返回,返回值爲int類型
def unixTime(day):
today = datetime.date.today()
target_day = today + datetime.timedelta(day)
unixtime = int(time.mktime(target_day.timetuple())) * 1000
return unixtime
#定義刪除es數據函數,調用系統curl命令進行刪除,需要傳入環境、需要刪除數據的時間範圍(即多少天之前的數據)參數,由於索引數量衆多,我們只處理超過1G的索引即可
def delData(env,day):
header = 'Content-Type: application/json'
for key, value in getData(env).items():
if 'gb' in value:
size = float(value.split('gb')[0])
if size > 1:
url = dev + '/' + key + '/_delete_by_query?pretty'
command = ("curl -X POST \"%s\" -H '%s' "
"-d '{\"query\":{ \"range\": {\"createTime\": {\"lt\": %s,\"format\": \"epoch_millis\"}}}}'" % (
url, header, day))
print(command)
os.system(command)
if __name__ == '__main__':
dev = 'http://192.168.1.19:9400'
test1 = 'http://192.168.1.19:9200'
test2 = 'http://192.168.1.19:9600'
day = unixTime(-30)
delData(dev,day)
delData(test1,day)
delData(test2,day)
結果驗證
刪除前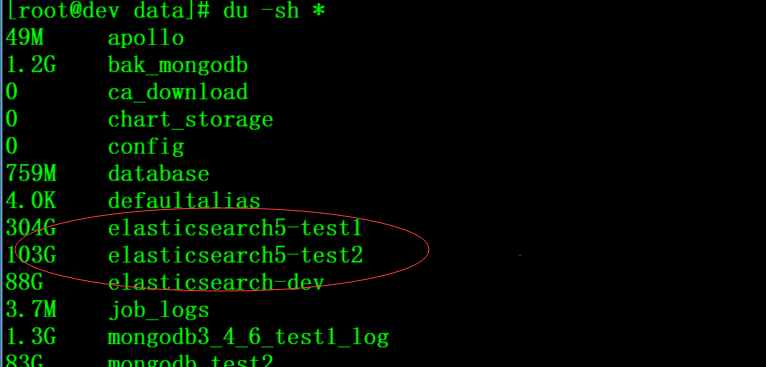
刪除後
注意事項
1、目前腳本採用操作系統crontab方式調度,一天運行一次
2、首次刪除因爲數據量龐大,需要耗費較長時間,後續每天刪除一天的數據量,刪除效率尚可
3、腳本未考慮服務器報錯等例外情況與告警通知,實際應用場景需要進行補充
4、腳本未考慮日誌記錄,實際應用場景需要進行補充