全網最簡單理解的索引
一個面試題引發
user表 name字段 創建基於name唯一索引,那麼下面的會走索引嗎?
select * from user where name like '%abc'
答案是走或者不走,不同時候不同討論。


如何選擇加還是不加索引呢,某列去重數據/count數據=值,這個值越小,越用不到索引,

三星索引基本上也是這些內容,
那麼索引是什麼?

幫助Mysql提高查詢數據效率的,存儲在硬盤中的一種數據結構。
資料經常講到“參考”書的目錄,書有目錄,佔用幾頁的空間,通過目錄可以快速的找到需要的內容信息,
這就是索引特點:通過物理空間,換取執行時間。
數據結構在線測試網站https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
索引可能根據不同的存儲引擎有不同的類型,主要Hash B+Tree
知道Hash 需要了解HashMap
什麼是HashMap??????
B+Tree 需要了二叉查找和平衡二叉樹 B樹演化而來。
二分查找集折半查找
二叉查找
如果按順序找235678,找到8肯定次數就多了。發現如果就是按id自增順序插入數據,那麼可能不是這種圖形了。

引出了一種平衡二叉樹:滿足二叉樹定義,左子樹小於右子樹,同時任何節點的兩個子樹的高度差最大爲1,

問題是什麼呢,平衡二叉樹每次插入和更新都需要調整平衡,通過左旋或者右旋,所以維護成本比較高,好在這個多用於內存結構中,相對開銷小點
B樹圖
B+Tree圖


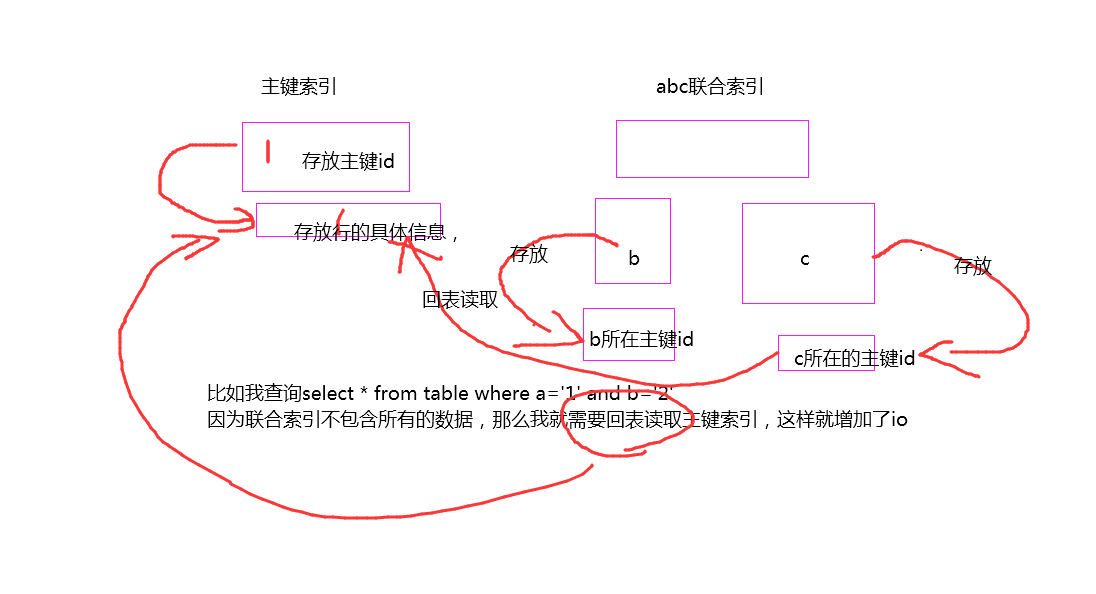
聚集索引,每張表的主鍵構造的一顆B+Tree樹,只能有一個,多數情況查詢優化器傾向於這個聚集索引,
聯合索引,對錶上的多個字段進行索引,記住最左匹配
另外注意比如創建了聯合索引abc where條件 b='4' and a='1'同樣也會使用,爲什麼優化器做了選擇。
覆蓋索引,不需要回表操作。