




一、python操作excel之openpyxl
前言
根據官方文檔,openpyxl 是一個第三方庫, 它可以可以處理 xlsx/xlsm 格式的 Excel 文件(A Python library to read/write Excel 2010 xlsx/xlsm files)。
openpyxl 中主要的三個概念: Workbook(工作表),Sheet(表頁)和Cell(格)。
openpyxl 中主要的操作: 打開 Workbook,定位 Sheet,操作 Cell。
(1)支持excel格式
- xlsx
- xlsm
- xltx
- xltm
(2)基本用法
首先介紹下Excel的一些基本概念,Workbook相當於是一個文件,WorkSheet就是文件裏面的每個具體的表,比如新建Excel文件裏面的'Sheet1'這個,一個Workbook裏面有一個或多個WorkSheet.
- workbook: 工作簿,一個excel文件包含多個sheet。
- worksheet:工作表,一個workbook有多個,表名識別,如“sheet1”,“sheet2”等。
- cell: 單元格,存儲數據對象
1、安裝openpyxl
pip install openpyxl2、參數介紹
(一)常遇到的情況
就我自己來說,常遇到的情況可能就下面幾種:
- 讀取excel整個sheet頁的數據。
- 讀取指定行、列的數據
- 往一個空白的excel文檔寫數據
- 往一個已經有數據的excel文檔追加數據
下面就以這幾種情況爲例進行說明。
(二) 涉及的模塊及函數說明
就我知道的,有3個模塊可以操作excel文檔,3個模塊通過pip都可以直接安裝。
- xlrd:讀數據
- xlwt:寫數據
- openpyxl:可以讀數據,也可以寫數據
這裏就就只說明openpyxl了,因爲這個模塊能滿足上面的需要了。
openpyxl函數
| 函數 | 說明 |
|---|---|
load_workbook(filename) |
打開excel,並返回所有sheet頁訪問指定sheet頁的方法:*#打開excel文檔 wb = openpyxl.load_workbook(file_name) #訪問sheet頁 *sheet = wb[‘sheet頁的名稱’]#關閉excel文檔wb.close() |
Workbook() |
創建excel文檔wb = openpyxl.Workbook()#保存excel文檔wb.save('文件名.xlsx') |
| 下面的函數是針對sheet頁的sheet = wb[‘sheet頁的名稱’]訪問指定單元格的方式sheet['A1']、sheet['B1']... | |
min_row |
返回包含數據的最小行索引,索引從1開始例如:sheet.min_row |
max_row |
返回包含數據的最大行索引,索引從1開始 |
min_column |
返回包含數據的最小列索引,索引從1開始 |
max_column |
返回包含數據的最大列索引,索引從1開始 |
values |
獲取excel文檔所有的數據,返回的是一個generator對象 |
| iter_rows(min_row=None, max_row=None, min_col=None, max_col=None) | min_row:最小行索引max_row:最大行索引min_col:最小列索引max_col:最大列索引獲取指定行、列的單元格,沒指定就是獲取所有的 |
title |
WorkSheet的名稱 |
現在我有這麼一個excel,下面以這個excel進行說明。
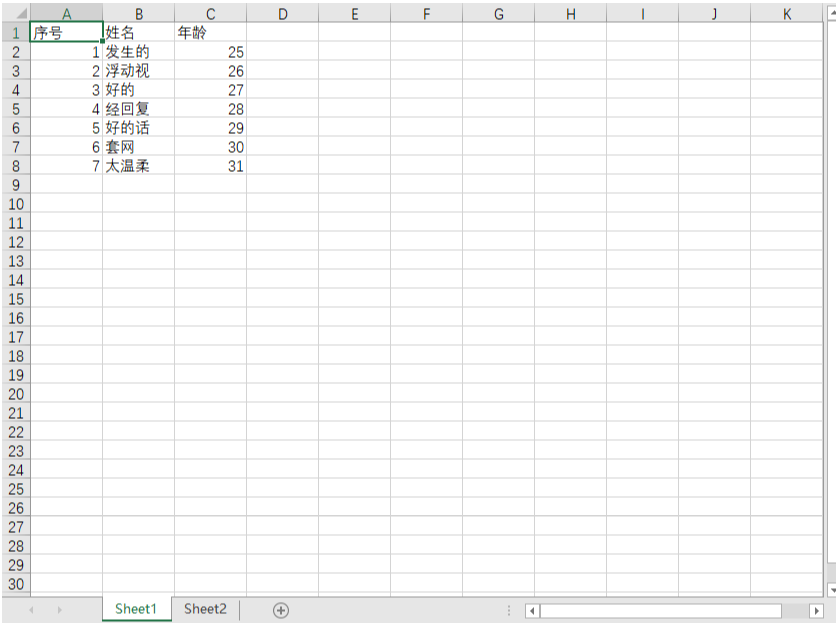
3、讀取文件屬性
import openpyxl
# 打開一個EXcel文檔
wb = openpyxl.load_workbook('test.xlsx')
sheet2 = wb['Sheet2']
print('表名爲:',sheet2.title)
print('數據的行數和列數:',sheet2.dimensions)
print('最小行數爲:',sheet2.max_row)
print('最大行數爲:',sheet2.min_row)
print('最大列數爲:',sheet2.max_column)
print('最小列數爲:',sheet2.min_column)
# 獲取指定單元格
print('單元格A1:',sheet2['A1'])
print('單元格B1:',sheet2.cell(row=1, column=2))
# 獲取行
print('行:',sheet2.rows)
# 獲取列
print('列:',sheet2.columns)
# 獲取所有的數據
print('所有的數據:',sheet2.values)
# 查看Excel文檔的屬性
print('是否只讀:',wb.read_only)
print('文檔的屬性:',wb.properties)
#文檔的字符集格式
print('字符集格式:',wb.encoding)
# 獲取活躍的工作表
print('活躍的工作表:',wb.active)
# 獲取所有的工作表
print('所有的工作表:',wb.worksheets)
# 獲取所有的工作表的名稱
print('輸出文件所有工作表名:', wb.sheetnames)
# 根據表格名稱獲取worksheet對象,區分大小寫
print('表名:',wb['Sheet2'])輸出結果爲:
表名爲: Sheet2 數據的行數和列數: A1:C8 最小行數爲: 8 最大行數爲: 1 最大列數爲: 3 最小列數爲: 1 單元格A1: <Cell 'Sheet2'.A1> 單元格B1: <Cell 'Sheet2'.B1> 行: <generator object Worksheet._cells_by_row at 0x000002612197F2E0> 列: <generator object Worksheet._cells_by_col at 0x000002612197F2E0> 所有的數據: <generator object Worksheet.values at 0x000002612197F2E0> 是否只讀: False 文檔的屬性: <openpyxl.packaging.core.DocumentProperties object> Parameters: creator='小鋼炮', title=None, description=None, subject=None, identifier=None, language=None, created=datetime.datetime(2015, 6, 5, 18, 17, 20), modified=datetime.datetime(2020, 5, 7, 4, 9, 19), lastModifiedBy='xxx', category=None, contentStatus=None, version=None, revision=None, keywords=None, lastPrinted=None 字符集格式: utf-8 活躍的工作表: <Worksheet "成績表"> 所有的工作表: [<Worksheet "Sheet2">, <Worksheet "Sheet3">, <Worksheet "成績表">] 輸出文件所有工作表名: ['Sheet2', 'Sheet3', '成績表'] 表名: <Worksheet "Sheet2">
4、讀取文件內容
import openpyxl
wb = openpyxl.load_workbook('test.xlsx')
sheet2 = wb['Sheet2']
# 獲取單元格內容
# 方式一
print('方法一')
for row in sheet2.values:
print(*row)
print('=========================')
# 方式二
print('方法二')
for row in sheet2.rows:
print(*[cell.value for cell in row])
print('=========================')
# 方式三
print('方法三')
for row in sheet2.iter_rows():
print(*[cell.value for cell in row])
print('=========================')
# 方式四(最複雜,最原始)
print('方法四')
for i in range(sheet2.min_row, sheet2.max_row + 1):
for j in range(sheet2.min_column, sheet2.max_column + 1):
print(sheet2.cell(row=i,column=j).value,end=' ')
print()輸出結果爲:
方法一 序號 姓名 年齡 1 發生的 25 2 浮動視 26 3 好的 27 4 經回覆 28 5 好的話 29 6 套網 30 7 太溫柔 31 ========================= 方法二 序號 姓名 年齡 1 發生的 25 2 浮動視 26 3 好的 27 4 經回覆 28 5 好的話 29 6 套網 30 7 太溫柔 31 ========================= 方法三 序號 姓名 年齡 1 發生的 25 2 浮動視 26 3 好的 27 4 經回覆 28 5 好的話 29 6 套網 30 7 太溫柔 31 ========================= 方法四 序號 姓名 年齡 1 發生的 25 2 浮動視 26 3 好的 27 4 經回覆 28 5 好的話 29 6 套網 30 7 太溫柔 31
5、刪除和創建表
import openpyxl
# 打開一個EXcel文檔
wb = openpyxl.load_workbook('test.xlsx')
sheet2 = wb['Sheet2']
# 刪除表
sheet1 = wb.get_sheet_by_name('Sheet1')
wb.remove_sheet(sheet1)
# 保存workbook的修改
wb.save('test.xlsx')
# 創建一個新的worksheet
wb.create_sheet('成績表')
# 保存workbook的修改
wb.save('test.xlsx')
6、在Excel中存儲學生成績
import openpyxl
# 打開workbook
wb = openpyxl.load_workbook("成績表.xlsx")
# #創建一個成績表
# wb.create_sheet("學生成績表")
#
# # 刪除表
# wb.remove_sheet(wb['Sheet1'])
# 獲取“學生成績表”
score = wb["學生成績表"]
# title = ['序號','姓名','語文','數學']
# no = range(6)
# names = ['張三','李四','王五','趙柳','田七']
# wen = [80,88,85,81,89]
# 第一行數據
score['A1'].value = '序號'
score['B1'].value = '姓名'
score['C1'].value = '語文'
score['D1'].value = '數學'
# 第二行數據
score['A2'].value = int('1')
score['B2'].value = '張三'
score['C2'].value = int('52')
score['D2'].value = int('64')
# 第三行數據
score['A3'].value = int('2')
score['B3'].value = '李四'
score['C3'].value = int('28')
score['D3'].value = int('95')
# 保存workbook
wb.save('成績表.xlsx')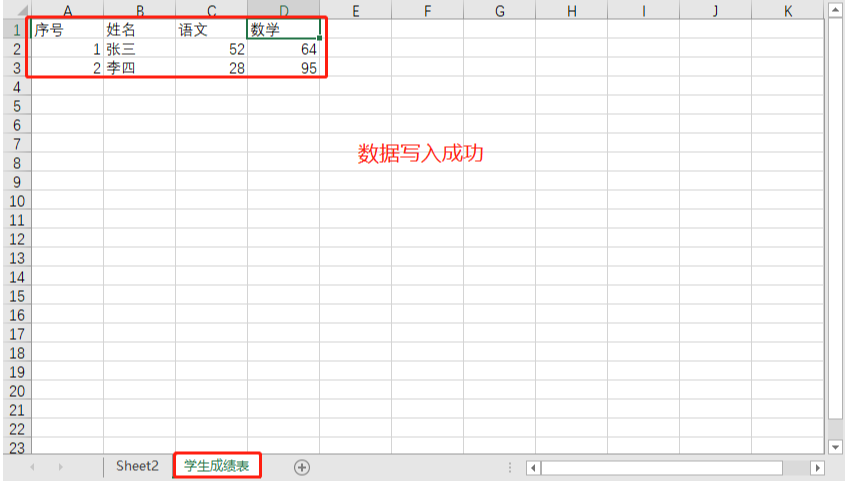
7、插入工作表內容
#coding=utf-8
import openpyxl
def process_worksheet(sheet):
# 總分所在的列
sum_column = sheet.max_column + 2
# 平均分所在的列
avg_column = sheet.max_column + 1
# 將總分和平均分保存到最後兩列
for row in sheet.iter_rows(min_row=2, min_col=3):
# 單元格
score = [cell.value for cell in row]
# 總分
sum_score = sum(score)
# 平均分
avg_score = sum_score / len(score)
# 將總分和平均分保存到最後兩列
sheet.cell(row=row[0].row, column=avg_column).value = avg_score
sheet.cell(row=row[0].row, column=sum_column).value = sum_score
# 設置平均分和總分的標題
sheet.cell(row=1, column=avg_column).value = "平均分"
sheet.cell(row=1, column=sum_column).value = "總分"
def main():
# 打開Excel文檔
wb = openpyxl.load_workbook("成績.xlsx")
# 獲取一個工作表
sheet = wb["成績表"]
# 把外部Excel文件(成績表)中的sheet(成績)插入當前Excel中
process_worksheet(sheet)
# 保存“練習.xlsx”
wb.save("練習-copy.xlsx")
if __name__ == '__main__':
main()查看練習-copy.xlsx的數據

二、Python 讀、寫Excel文件(三種模塊三種方式
python讀寫excel的方式有很多,不同的模塊在讀寫的講法上稍有區別:
- 用xlrd和xlwt進行excel讀寫;
- 用openpyxl進行excel讀寫;
- 用pandas進行excel讀寫;
pandas介紹
- Pandas是Python的一個數據分析包,該工具爲解決數據分析任務而創建。
- Pandas納入大量庫和標準數據模型,提供高效的操作數據集所需的工具。
- Pandas提供大量能使我們快速便捷地處理數據的函數和方法。
- Pandas是字典形式,基於NumPy創建,讓NumPy爲中心的應用變得更加簡單。
1、xlrd模塊
xlrd是用來從Excel中讀寫數據的,但我平常只用它進行讀操作,寫操作會遇到些問題。用xlrd進行讀取比較方便,流程和平常手動操作Excel一樣,打開工作簿(Workbook),選擇工作表(sheets),然後操作單元格(cell)。下面舉個例子,例如要打開當前目錄下名爲”data.xlsx”的Excel文件,選擇第一張工作表,然後讀取第一行的全部內容並打印出來。
#打開excel文件
data=xlrd.open_workbook('data.xlsx')
#獲取第一張工作表(通過索引的方式)
table=data.sheets()[0]
#data_list用來存放數據
data_list=[]
#將table中第一行的數據讀取並添加到data_list中
data_list.extend(table.row_values(0))
#打印出第一行的全部數據
for item in data_list:
print item上面的代碼中讀取一行用table.row_values(number),類似的讀取一列用table.column_values(number),其中number爲行索引,在xlrd中行和列都是從0開始索引的,因此Excel中最左上角的單元格A1是第0行第0列。
xlrd中讀取某個單元格用table.cell(row,col)即可,其中row和col分別是單元格對應的行和列。
下面簡單歸納一下xlrd的用法
(1)安裝xlrd模塊
到python官網下載http://pypi.python.org/cmdpypi/xlrd模塊安裝,前提是已經安裝了python 環境。
pip install xlrd(2)使用技巧
- sheet.name:sheet的名字
- sheet.nrows:sheet的行數
- sheet.ncols:sheet的列數
- sheet.get_rows():返回一個迭代器,遍歷所有行,給出每個行的值列表
- sheet.row_values(index):返回某一行的值列表
- sheet.row(index):返回一個row對象,可通過row[index]獲取這行裏的單元格cell對象
- sheet.col_values(index):返回某一列的值列表
- sheet.cell(row,col):獲取一個cell對象(row和col都從0開始算
table = data.sheets()[0] #通過索引順序獲取
table = data.sheet_by_index(0) #通過索引順序獲取
table = data.sheet_by_name(u'Sheet1')#通過名稱獲取
# 獲取整行和整列的值(數組)
table.row_values(i)
table.col_values(i)
# 獲取行數和列數
nrows = table.nrows
ncols = table.ncols
# 循環行列表數據
for i in range(nrows):
print table.row_values(i)
# 單元格
cell_A1 = table.cell(0,0).value
cell_C4 = table.cell(2,3).value
# 使用行列索引
cell_A1 = table.row(0)[0].value
cell_A2 = table.col(1)[0].value
# 簡單的寫入
row = 0
col = 0
# 類型 0 empty,1 string, 2 number, 3 date, 4 boolean, 5 error
ctype = 1 value = '單元格的值'
xf = 0 # 擴展的格式化
table.put_cell(row, col, ctype, value, xf)
table.cell(0,0) #單元格的值'
table.cell(0,0).value #單元格的值'(3)查看文件數據
import xlrd
book = xlrd.open_workbook('練習-copy.xlsx')
sheet1 = book.sheets()[0]
nrows = sheet1.nrows
print('表格總行數:', nrows)
ncols = sheet1.ncols
print('表格總列數:', ncols)
row3_values = sheet1.row_values(2)
print('第3行的值:', row3_values)
col3_values = sheet1.col_values(2)
print('第3列的值:', col3_values)
cell_2_2 = sheet1.cell(2,2).value
print('3行3列的值',cell_2_2)輸出結果如下
表格總行數: 8 表格總列數: 3 第3行的值: [2.0, '浮動視', 26.0] 第3列的值: ['年齡', 25.0, 26.0, 27.0, 28.0, 29.0, 30.0, 31.0] 3行3列的值 26.0
2、xlwt模塊
pip install xlwt如果說xlrd不是一個單純的Reader(如果把xlrd中的後兩個字符看成Reader,那麼xlwt後兩個字符類似看成Writer),那麼xlwt就是一個純粹的Writer了,因爲它只能對Excel進行寫操作。xlwt和xlrd不光名字像,連很多函數和操作格式也是完全相同。下面簡要歸納一下常用操作
(1)xlwt常用操作
新建一個Excel文件(只能通過新建寫入)
data=xlwt.Workbook()新建一個工作表
table=data.add_sheet('name')寫入數據到A1單元格
table.write(0,0,u'呵呵')注意:如果對同一個單元格重複操作,會引發overwrite Exception,想要取消該功能,需要在添加工作表時指定爲可覆蓋,像下面這樣
table=data.add_sheet('name',cell_overwrite_ok=True)保存文件
data.save('test.xls')這裏只能保存擴展名爲xls的,xlsx的格式不支持
xlwt支持一定的樣式,操作如下
#初始化樣式
style=xlwt.XFStyle()
#爲樣式創建字體
font=xlwt.Font()
#指定字體名字
font.name='Times New Roman'
#字體加粗
font.bold=True
#將該font設定爲style的字體
style.font=font
#寫入到文件時使用該樣式
sheet.write(0,1,'just for test',style)(2)實例
import xlwt # 貌似不支持excel2007的xlsx格式
wb = xlwt.Workbook()
wb_sheet = wb.add_sheet('ddd')
wb_sheet.write(0,0,'測試內容')
wb.save('d.xls')查看d.xls文件
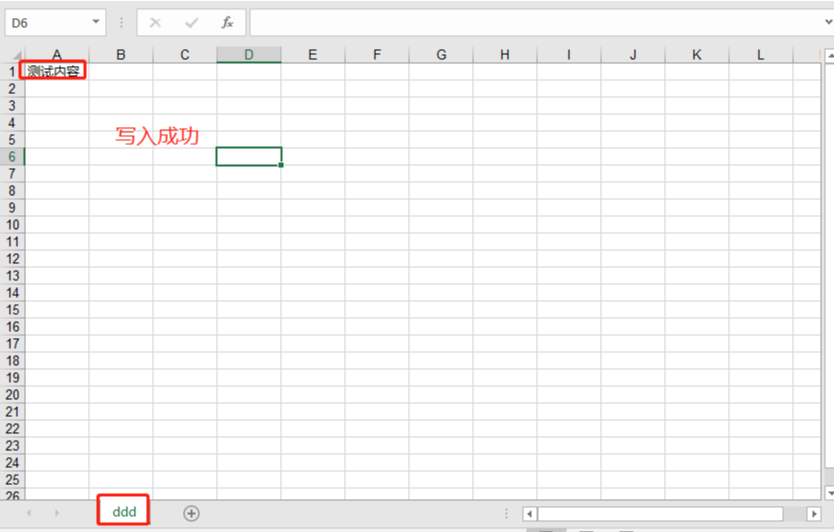
3、openpyxl模塊
pip install openpyxl該模塊支持最新版的Excel文件格式,對Excel文件具有響應的讀寫操作,對此有專門的Reader和Writer兩個類,便於對Excel文件的操作。雖然如此,但我一般還是用默認的workbook來進行操作。常用操作歸納如下:
(1)openpyxl常用操作
讀取Excel文件
from openpyxl.reader.excel import load_workbook
wb=load_workbook(filename)顯示工作表的索引範圍
wb.get_named_ranges()顯示所有工作表的名字
wb.get_sheet_names()取得第一張表
sheetnames = wb.get_sheet_names()
ws = wb.get_sheet_by_name(sheetnames[0])獲取表名
ws.title獲取表的行數
ws.get_highest_row()獲取表的列數
ws.get_highest_column()單元格的讀取,此處和xlrd的讀取方式很相近,都是通過行和列的索引來讀取
#讀取B1單元格中的內容
ws.cell(0,1).value當然也支持通過Excel座標來讀取數據,代碼如下
#讀取B1單元格中的內容
ws.cell("B1").value(2)實例
import pandas as pd
from pandas import DataFrame
# df = pd.read_excel(r'練習-copy.xlsx',sheet_name='學生成績表')
# print(df.head())
data = {
'name':['張三','李四','王五'],
'age':[11,12,13],
'sex':['男','女','未知'],
}
df = DataFrame(data)
df.to_excel('new.xlsx')查看new.xlsx文件

4、案例
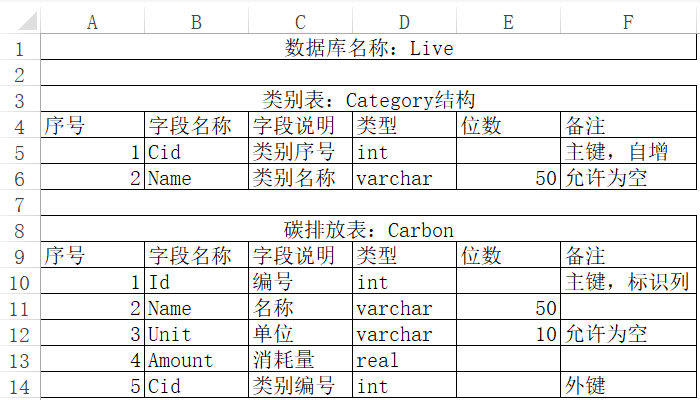
把提供的原始Excel文檔中的兩個表格提取到另外一個新的Excel文檔中,橫向排列
代碼如下:
import openpyxl
import pandas
from pandas import DataFrame
wb = openpyxl.load_workbook('Live數據庫及表結構.xlsx')
sheet = wb['Sheet1']
aa = []
for row1 in sheet.iter_rows(min_row=3,max_row=6):
score1 = [cell.value for cell in row1]
aa.append(score1)
df = DataFrame(aa)
df.to_excel('xgp.xlsx')
bb = []
for row2 in sheet.iter_rows(min_row=8,max_row=14):
score2 = [cell.value for cell in row2]
bb.append(score2)
df = pandas.DataFrame(bb)
book = openpyxl.load_workbook('xgp.xlsx')
with pandas.ExcelWriter('xgp.xlsx')as E:
E.book = book
E.sheets = dict((ws.title, ws) for ws in book.worksheets)
df.to_excel(E,sheet_name='Sheet1',index=False,startcol=12)查看xgp.xlsx文件

5、總結
讀取Excel時,選擇openpyxl和xlrd差別不大,都能滿足要求
寫入少量數據且存爲xls格式文件時,用xlwt更方便
寫入大量數據(超過xls格式限制)或者必須存爲xlsx格式文件時,就要用openpyxl了。