




對於多副本應用,當執行 Scale Up 操作時,新副本會作爲 backend 被添加到 Service 的負責均衡中,與已有副本一起處理客戶的請求。考慮到應用啓動通常都需要一個準備階段,比如加載緩存數據,連接數據庫等,從容器啓動到正真能夠提供服務是需要一段時間的。我們可以通過 Readiness 探測判斷容器是否就緒,避免將請求發送到還沒有 ready 的 backend。
下面是示例應用的配置文件。
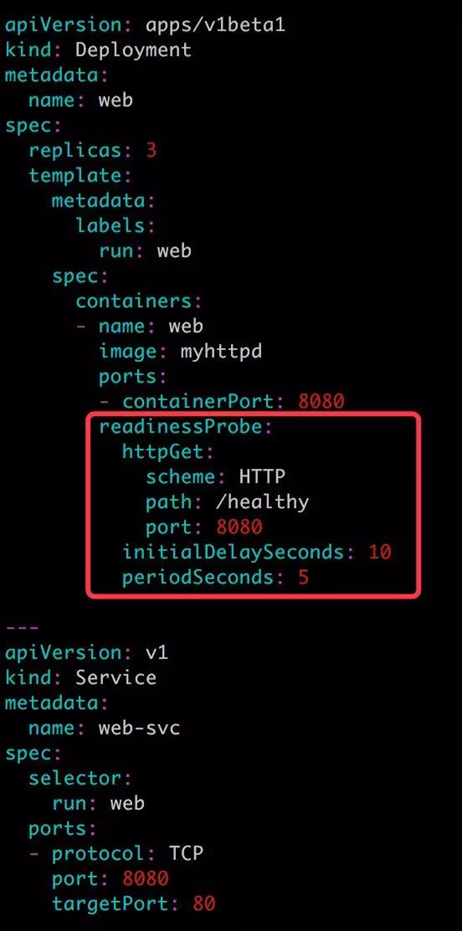
重點關注 readinessProbe 部分。這裏我們使用了不同於 exec 的另一種探測方法 -- httpGet。Kubernetes 對於該方法探測成功的判斷條件是 http 請求的返回代碼在 200-400 之間。
schema 指定協議,支持 HTTP(默認值)和 HTTPS。
path 指定訪問路徑。
port 指定端口。
上面配置的作用是:
- 容器啓動 10 秒之後開始探測。
- 如果 http://[container_ip]:8080/healthy 返回代碼不是 200-400,表示容器沒有就緒,不接收 Service web-svc 的請求。
- 每隔 5 秒再探測一次。
- 直到返回代碼爲 200-400,表明容器已經就緒,然後將其加入到 web-svc 的負責均衡中,開始處理客戶請求。
- 探測會繼續以 5 秒的間隔執行,如果連續發生 3 次失敗,容器又會從負載均衡中移除,直到下次探測成功重新加入。
對於 http://[container_ip]:8080/healthy,應用則可以實現自己的判斷邏輯,比如檢查所依賴的數據庫是否就緒,示例代碼如下:
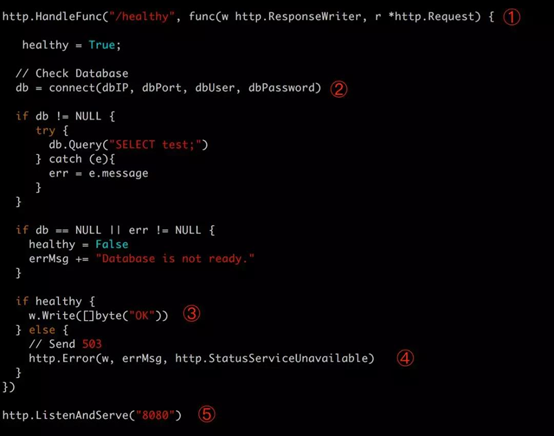
① 定義 /healthy 的處理函數。
② 連接數據庫並執行測試 SQL。
③ 測試成功,正常返回,代碼 200。
④ 測試失敗,返回錯誤代碼 503。
⑤ 在 8080 端口監聽。
對於生產環境中重要的應用都建議配置 Health Check,保證處理客戶請求的容器都是準備就緒的 Service backend。
以上是 Health Check 在 Scale Up 中的應用,下一節我們討論在 Rolling Update 中如果應用。
在滾動更新中使用 Health Check
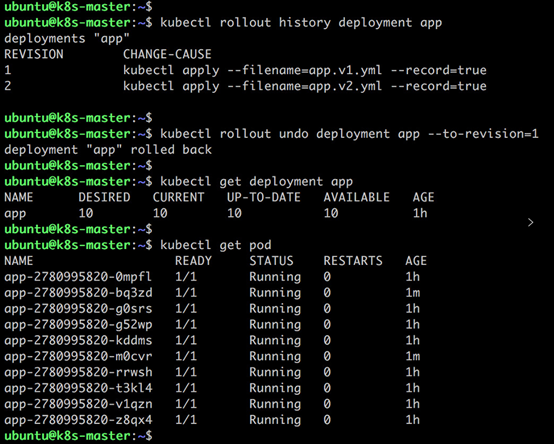
kubectl rollout history deployment app.v
查看歷史版本
kubectl rollout undo deployment app --to-revision=1
回退之前的版本
healthcheck]# kubectl rollout history deployment app
第146篇
在滾動更新中使用 Health Check
上一節討論了 Health Check 在 Scale Up 中的應用,Health Check 另一個重要的應用場景是 Rolling Update。試想一下下面的情況:
現有一個正常運行的多副本應用,接下來對應用進行更新(比如使用更高版本的 image),Kubernetes 會啓動新副本,然後發生瞭如下事件:
- 正常情況下新副本需要 10 秒鐘完成準備工作,在此之前無法響應業務請求。
- 但由於人爲配置錯誤,副本始終無法完成準備工作(比如無法連接後端數據庫)。
先別繼續往下看,現在請花一分鐘思考這個問題:如果沒有配置 Health Check,會出現怎樣的情況?
因爲新副本本身沒有異常退出,默認的 Health Check 機制會認爲容器已經就緒,進而會逐步用新副本替換現有副本,其結果就是:當所有舊副本都被替換後,整個應用將無法處理請求,無法對外提供服務。如果這是發生在重要的生產系統上,後果會非常嚴重。
如果正確配置了 Health Check,新副本只有通過了 Readiness 探測,纔會被添加到 Service;如果沒有通過探測,現有副本不會被全部替換,業務仍然正常進行。
下面通過例子來實踐 Health Check 在 Rolling Update 中的應用。
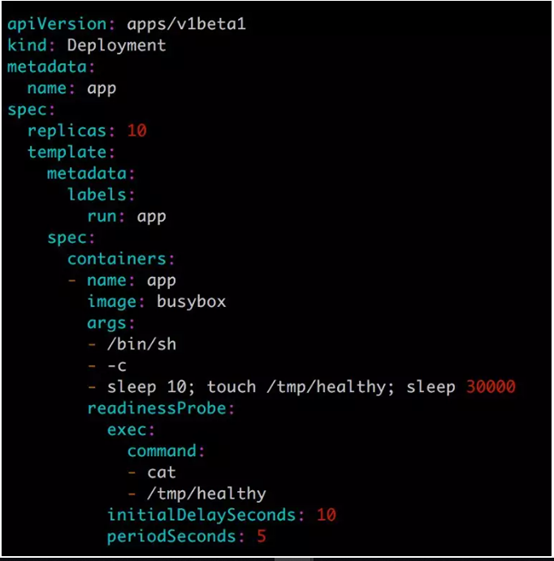
用如下配置文件 app.v1.yml 模擬一個 10 副本的應用:![readness健康性檢測與maxSurge 和 maxUnavailable更新策略]()
接下來滾動更新應用,配置文件 app.v2.yml 如下: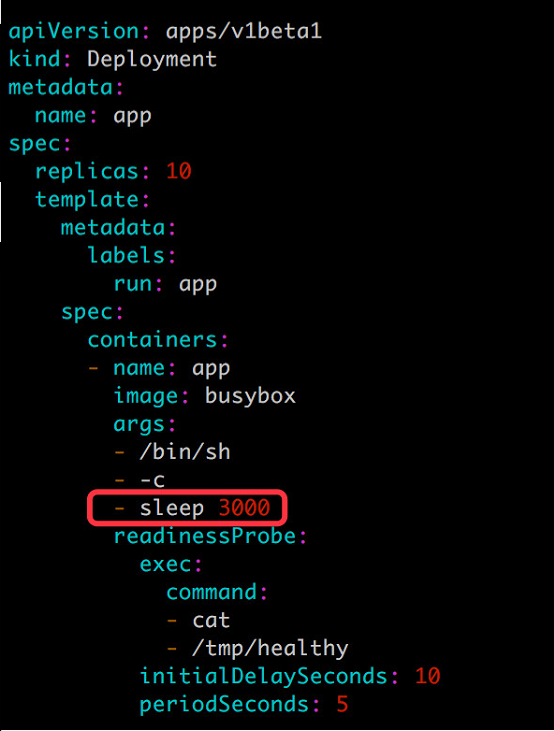
很顯然,由於新副本中不存在 /tmp/healthy,是無法通過 Readiness 探測的。驗證如下:
接下來滾動更新應用,配置文件 app.v2.yml 如下: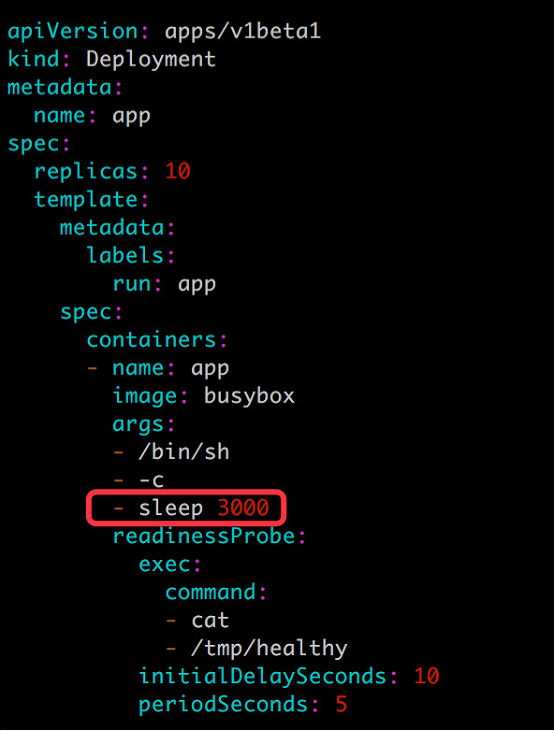
這個截圖包含了大量的信息,值得我們詳細分析。
先關注 kubectl get pod 輸出:
- 從 Pod 的 AGE 欄可判斷,最後 5 個 Pod 是新副本,目前處於 NOT READY 狀態。
- 舊副本從最初 10 個減少到 8 個。
再來看 kubectl get deployment app 的輸出: - DESIRED 10 表示期望的狀態是 10 個 READY 的副本。
- CURRENT 13 表示當前副本的總數:即 8 箇舊副本 + 5 個新副本。
- UP-TO-DATE 5 表示當前已經完成更新的副本數:即 5 個新副本。
- AVAILABLE 8 表示當前處於 READY 狀態的副本數:即 8箇舊副本。
在我們的設定中,新副本始終都無法通過 Readiness 探測,所以這個狀態會一直保持下去。
上面我們模擬了一個滾動更新失敗的場景。不過幸運的是:Health Check 幫我們屏蔽了有缺陷的副本,同時保留了大部分舊副本,業務沒有因更新失敗受到影響。
接下來我們要回答:爲什麼新創建的副本數是 5 個,同時只銷毀了 2 箇舊副本?
原因是:滾動更新通過參數 maxSurge 和 maxUnavailable 來控制副本替換的數量。
maxSurge
此參數控制滾動更新過程中副本總數的超過 DESIRED 的上限。maxSurge 可以是具體的整數(比如 3),也可以是百分百,向上取整。maxSurge 默認值爲 25%。
在上面的例子中,DESIRED 爲 10,那麼副本總數的最大值爲:
roundUp(10 + 10 25%) = 13
所以我們看到 CURRENT 就是 13。
maxUnavailable
此參數控制滾動更新過程中,不可用的副本相佔 DESIRED 的最大比例。 maxUnavailable 可以是具體的整數(比如 3),也可以是百分百,向下取整。maxUnavailable 默認值爲 25%。
在上面的例子中,DESIRED 爲 10,那麼可用的副本數至少要爲:
10 - roundDown(10 25%) = 8
所以我們看到 AVAILABLE 就是 8。
maxSurge 值越大,初始創建的新副本數量就越多;maxUnavailable 值越大,初始銷燬的舊副本數量就越多。
理想情況下,我們這個案例滾動更新的過程應該是這樣的: - 首先創建 3 個新副本使副本總數達到 13 個。
- 然後銷燬 2 箇舊副本使可用的副本數降到 8 個。
- 當這 2 箇舊副本成功銷燬後,可再創建 2 個新副本,使副本總數保持爲 13 個。
- 當新副本通過 Readiness 探測後,會使可用副本數增加,超過 8。
- 進而可以繼續銷燬更多的舊副本,使可用副本數回到 8。
- 舊副本的銷燬使副本總數低於 13,這樣就允許創建更多的新副本。
- 這個過程會持續進行,最終所有的舊副本都會被新副本替換,滾動更新完成。
而我們的實際情況是在第 4 步就卡住了,新副本無法通過 Readiness 探測。這個過程可以在 kubectl describe deployment app 的日誌部分查看。![readness健康性檢測與maxSurge 和 maxUnavailable更新策略]()

如果滾動更新失敗,可以通過 kubectl rollout undo 回滾到上一個版本。
如果要定製 maxSurge 和 maxUnavailable,可以如下配置: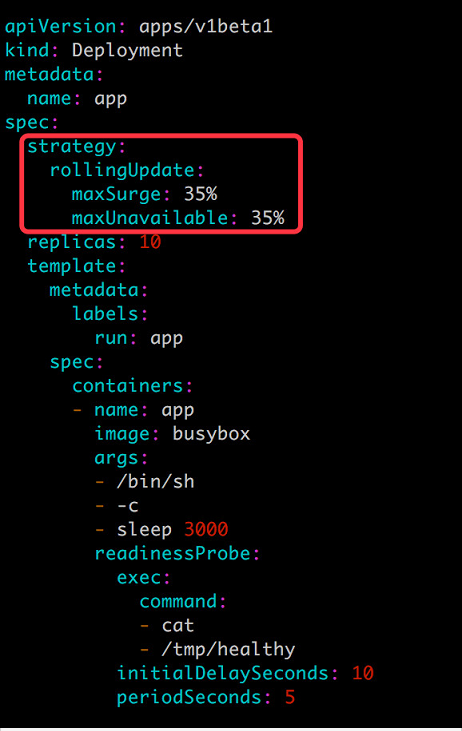
小結
本章我們討論了 Kubernetes 健康檢查的兩種機制:Liveness 探測和 Readiness 探測,並實踐了健康檢查在 Scale Up 和 Rolling Update 場景中的應用。