- 事務的標識,依靠事務ID,是一個全局唯一的64bits數值
- 多版本,是元組級的多版本,而不是oracle實現的是頁面級的多版本
- 最新的數據存儲在數據頁面中,其他數據的舊版本存儲在回滾段中
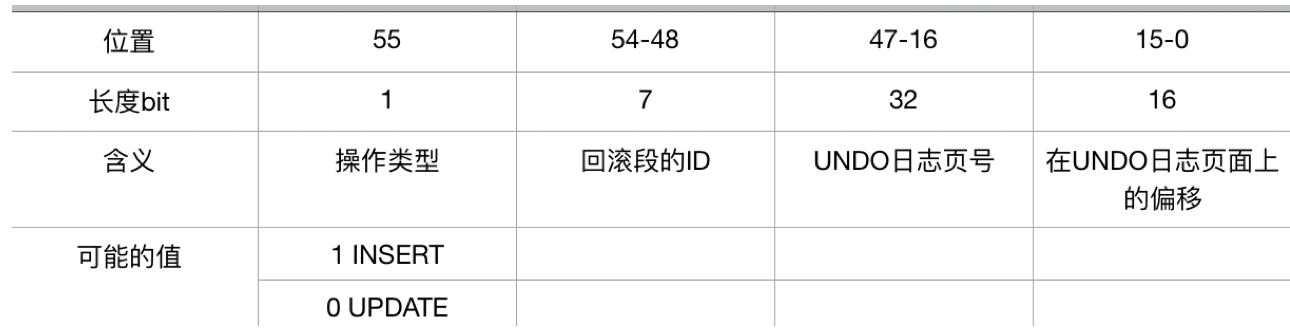
- DATA_TRX_ID: 6字節長,表示上一個執行插入或更新操作的事務
- DATA_ROLL_PTR: 7字節長,表示舊版本的數據位於回滾段中的位置,指向的是一箇舊版本,只有元組被更新,纔有會新版本產生,舊版本被置於回滾段,因此一致性無鎖讀操作按照“read view”快照需要讀取舊版本時,只能根據事務ID回到回滾段中尋找舊版本
- DATA_ROW_ID:6字節長,表示執行插入操作後生成的單調自增長的行的ID標識,如果存在聚集索引,索引項則包括的是這個DB_ROW_ID值
- DELETE_BIT: 刪除標誌位
- INSERT UNOD LOGS:插入到回滾段的日誌,僅用於事務提交時使用,當事務提交,則對應的INSETR UNDO LOGS裏面的內容被清除
- UPDATE UNDO LOGS:被用於一致性無鎖讀,爲一致性讀提供快照隔離下的可被讀取的老版本數據,當沒有需要滿足一致性讀的快照時,一些老版本數據才被清理
- innodb的MVCC,是通過在每行記錄後面保存兩個隱藏的列來實現的,這兩個列,一個保存的行的創建時間,一個保存行的過期時間,當然存儲的並不是實際的時間值,而是系統版本號(system version number),每開始一個新的事務,系統版本號就會遞增,事務開始時刻的系統本號會作爲事務的版本號,用來和查詢到的每行記錄的版本號進行記錄,下面看一個在REPEATABLE READ隔離級別下,MVCC是如何操作的
- SELECT
- innodb會根據以下兩個條件檢查每行記錄,只有符合下面兩個條件的記錄,才能返回作爲查詢結果
- innodb值只查找系統早已當前事務版本的數據行(也就是行的系統版本號小於或等於事務的系統版本號),這樣可以確保事務讀取的行,要麼是在事務開始前就已經存在的,要不是事務自身插入或者修改過的
- 行的刪除版本要不未定義,要不大於當前事務版本號,這可以確保事務讀取到的行,在事務開始之前未被刪除
- innodb會根據以下兩個條件檢查每行記錄,只有符合下面兩個條件的記錄,才能返回作爲查詢結果
- INSERT
- innodb爲新插入的每一行保存當前系統版本號作爲行版本號
- DELETE
- innodb爲刪除的每一行保存當前系統版本號作爲行刪除標識
- UPDATE
- innodb爲插入一條新紀錄,保存當前系統版本號作爲行版本號,同時保存當前系統的版本號到原先的行作爲刪除標識
*

- 我們執行step7的時候發現一個問題,怎麼id=4的查不出來呢,按照上面的規則,id=3的事務ID是2,T3的事務ID是3,這種情況id=4是可以查出來的呢,所以說上面的規則肯定還說的不是很詳細,有遺落的地方,我們接着往下面看
- 隔離級別大於等於可重複讀:事務塊的所有的SELECT操作都要使用同一個快照,此快照是在第一個SELECT操作時建立的
- 隔離級別小於等於已提交讀:事務塊內的所有的SELECT操作分別創建屬於自己的快照,因此每次讀都不同,後面的SELECT操作的讀就可以讀到本次讀之前已經提交的數據
- 當前數據可以看到哪些數據就是由這個快照決定的,快照有下面幾個屬性,並且可見性也根據這幾個屬性來判斷的
- m_up_limit_id 一個快照,有左右邊界,左邊界是最小值,右邊界是最大值,此變量是左邊界
- m_low_limit_id 右邊界
- m_createor_trx_id 正在創建事務的事務ID
- trx_ids 快照創建時,處於活動即尚未完成的讀寫事務的集合
- 舉一個列子:新建一個快照,假設當前事務的事務ID爲6,這時候讀寫事務鏈上(這個是全局的)活動的事務有{3,5,6,10},不包括只讀事務,那麼調用方法創建快照時就會把{3,5,10}存儲到當前的視圖中的trx_ids(6因爲是當前事務的ID,不記錄到視圖中),m_up_limit_id的值是3,m_low_limit__id是10,m_createor_trx_id是6
- trx_id<m_up_limit_id 可見 意味着是快照之前發生的事務
- trx_id>m_low_limit_id 不可見,意味着是快照之後發生的事務
- trx_ids對應的事務左右的修改還處於活動狀態即還沒有提交對當前事務來說不可見
- trx_id=m_createor_trx_id 可見
- 公式:通過比較事務ID的值是否在[m_up_limit_id,m_low_limit_id]區間的左側,中間,還是右側判斷是否可見
- 左側 可見
- 中間
- 在trx_ids中不可見
- 等於m_createor_trx_id 可見
- 右側 不可見
- 對於一個邏輯上的多版本生成過程,其方式如下
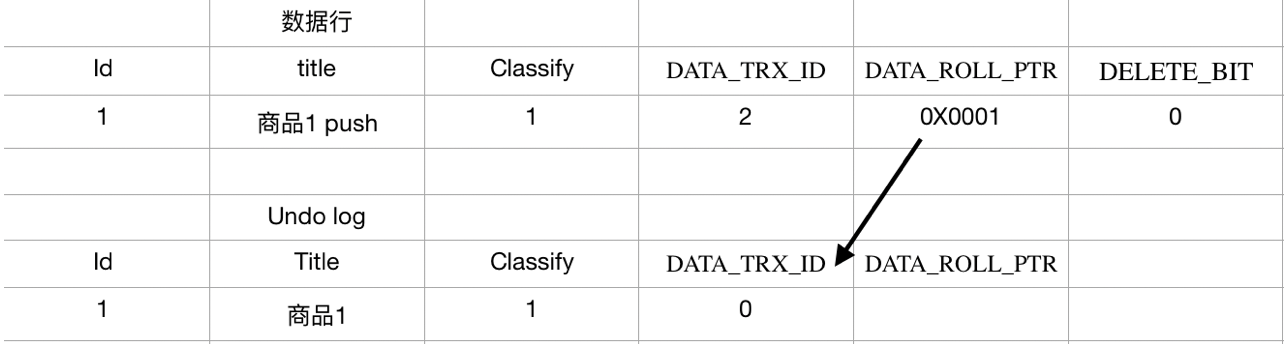
- 最老的版本,一定是插入操作暫存到UNDO日誌的版本(對於聚集索引,不是記錄的所有字段讀暫存到回滾段,而是主鍵信息被暫存)
- 更新操作,把舊值存入UNDO日誌。同一個日誌反覆被更新,則每次讀存入一箇舊值(前像)到UNDO日誌內,如此就會有多個版本,版本之間,使用DATA_POLL_PTR執行根據的版本,由此所有版本構成一個鏈表,鏈頭是索引上的記錄,鏈尾是首次插入時生成的UNDO信息。
- 刪除操作,在UNDO日誌中保存刪除標誌
- 對於聚集索引,可以根據DATA_ROLL_PTR就可以從回滾段中找出前一個版本的記錄,並知道此記錄是更新操作還是插入操作生成的,如果是插入操作生成的,則意味着此版本是最原始的版本,即使不可見也沒有必要在繼續回溯查找舊版本了
- 但是查找的過程與隔離級別緊密相關
- 如果是未提交讀隔離級別,根本不去找舊版本,在索引上讀到的記錄就被直接使用
- 如果不是未提交隔離級別,則需要進入UNDO回滾段中根據DATA_POLL_PTR進行查找,還要判斷是否可見,如果可見,則返回,如果不可見,則一直根據DATA_POLL_PTR進行查找
-
有了前面的補充,我們看下是否能解釋前面step7出現的問題
![MVCC講解]()
![MVCC講解]()
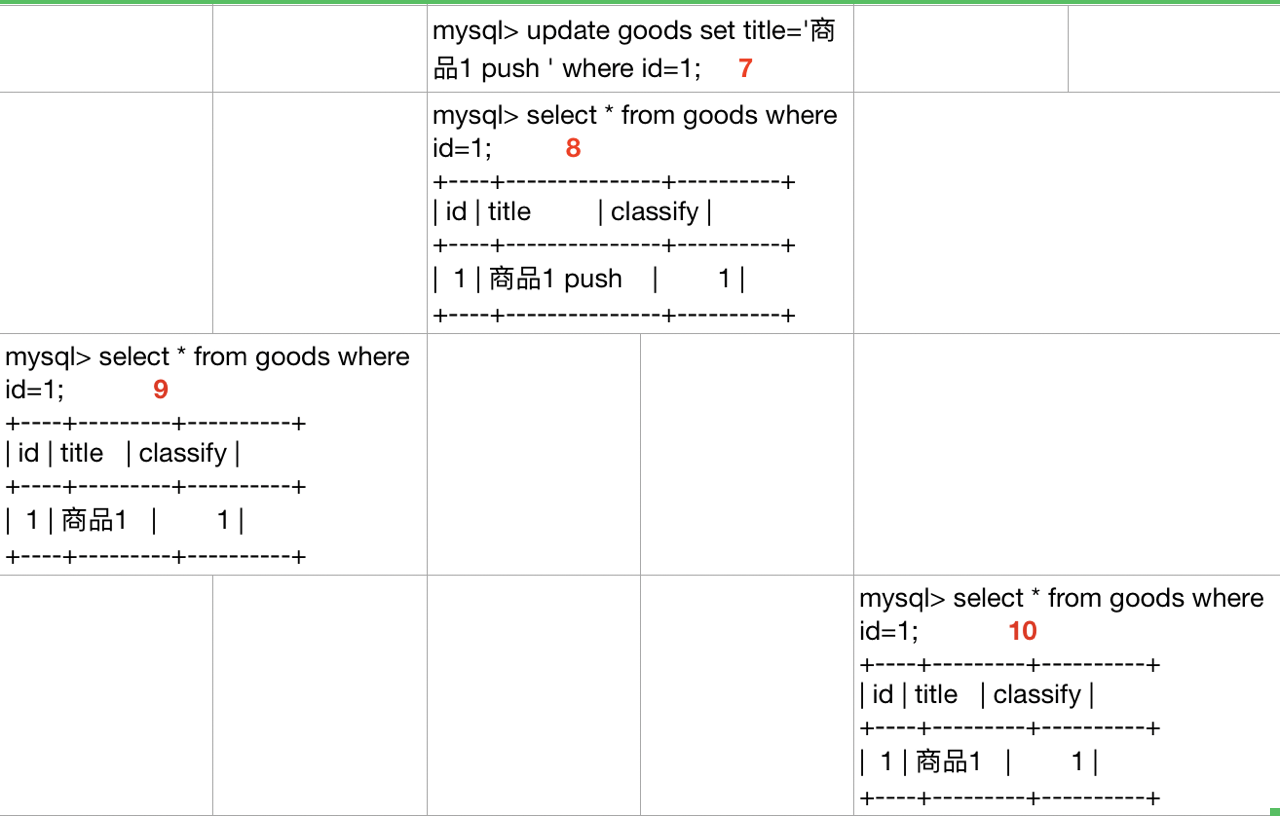
- 我們在T2的step8修改了id=1的title,但step 9,step10沒有看到,step9沒看到,大家不會有什麼意外,因爲step9對應的事務ID小於step8的事務ID,但step10的事務ID是大於step8的事務ID的,那麼我們來分析一下是什麼造成的,我們這裏不說undo log的格式,我們只需要知道根據undo log我們可以知道記錄的多個版本
- 一開始,id=1的記錄是這樣的
![MVCC講解]()
- T1的step4
- m_up_limit_id=1,m_low_limit_id=1,m_createor_trx_id=1,trx_ids={},DATA_TRX_ID=0
- DATA_TRX_ID<m_up_limit_id, 在[m_up_limit_id,m_low_limit_id]的左側,記錄可見
- T2的step 5
- m_up_limit_id=1,m_low_limit_id=2,m_createor_trx_id=2,trx_ids={1},DATA_TRX_ID=0
- DATA_TRX_ID<m_up_limit_id, 在[m_up_limit_id,m_low_limit_id]的左側,記錄可見
- T3的step 6
- m_up_limit_id=1,m_low_limit_id=3,m_createor_trx_id=3,trx_ids={1,2},DATA_TRX_ID=0
- DATA_TRX_ID<m_up_limit_id, 在[m_up_limit_id,m_low_limit_id]的左側,記錄可見
- step7修改了數據,這時候id=1的記錄是這樣的
- T2的step8
*m_up_limit_id=1,m_low_limit_id=2,m_createor_trx_id=2,trx_ids={1},DATA_TRX_ID=2- DATA_TRX_ID在[m_up_limit_id,m_low_limit_id]的中間位置,m_createor_trx_id=DATE_TRX_ID,因此可見。所以看到了title=‘商品1 push’的這一行
- T1的step9
- m_up_limit_id=1,m_low_limit_id=1,m_createor_trx_id=1,trx_ids={},DATA_TRX_ID=2
- DATA_TRX_ID在[m_up_limit_id,m_low_limit_id]的右側,記錄不可見
- 那麼接着通過DATE_ROLL_PTR,去undo找到了trx_id=0的這一行
- DATA_TRX_ID=0,DATA_TRX_ID<m_up_limit_id, 在[m_up_limit_id,m_low_limit_id]的左側,記錄可見
- step10
- m_up_limit_id=1,m_low_limit_id=3,m_createor_trx_id=3,trx_ids={1,2},DATA_TRX_ID=2
- DATA_TRX_ID在[m_up_limit_id,m_low_limit_id]的中間位置,並且在trx_ids中,記錄不可見
- 接着通過DATE_ROLL_PTR,去undo找到了trx_id=0的這一行
- DATA_TRX_ID=0, DATA_TRX_ID=0,DATA_TRX_ID<m_up_limit_id, 在[m_up_limit_id,m_low_limit_id]的左側,記錄可見
參考書籍:數據庫事務處理的藝術 事務管理與併發控制,高性能MySQL