




吾生也有涯,而知也無涯。以有涯隨無涯,殆已!
入市有風險,投資需謹慎,本文不作爲任何投資參考依據。
前面通過形態和一些基本面的數據進行了選股,這篇文章就來研究一下相似度選股以及趨勢選股吧。
相似度
我們一般比較在意股票的收盤價,比如均線或者各種指標如果需要計算一段序列值,我們一般選擇收盤價作爲序列中的值,就像5日均線計算的是五日的收盤價的均值一樣。
那麼每天的收盤價就是一個個數字,一年的收盤價就是一串大概220個數字的序列,這個序列在數學上我們可以用向量來表示,而向量與向量之間是可以計算餘弦相似度的,通過這個相似度計算我們可以比較一下兩支股票的相似程度。
餘弦相似度的值在-1與1之間,越相似就越接近1,反之越接近-1.
它的公式如下:
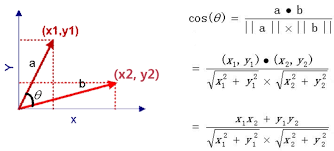
假設我們對對一支股票很熟悉,那麼和它走勢極其相似的股票我們是不是可以認爲會在以後也跟我們熟悉的那支股票大概一致呢?或者說,在某個特定的行情下,在手動選出了我認爲有利的趨勢股票,在通過相似度找到其他的股票或許是件不錯的事。
這裏研究一下最近一百個交易日內與平安銀行(000001)這隻股票最相似的前十隻股票。
爲了避免交易日範圍相差太大的情況,比如雖然都是最近100個交易日,但是被計算的股票已經停牌了10個交易日或者它沒有上市超過10個交易日,所以應該將這些情況給篩選掉。
還有就是股票之間的價格差距過大,那麼通過兩隻股票的價格來進行相似度比較顯然不夠合理,所以這裏選擇股票的漲幅大小來進行相似度比較。
# 計算餘弦相似度的函數
def cos(vector_a, vector_b):
vector_a = np.mat(vector_a)
vector_b = np.mat(vector_b)
num = float(vector_a * vector_b.T)
denom = np.linalg.norm(vector_a) * np.linalg.norm(vector_b)
cos = num / denom
return cos
def select_by_similarity(data_path, code_name, top_size=10):
day_range = 100
# 交易日的起始截至時間做大不能超過這個間隔
max_delta = timedelta(days=7)
all_df = load_all_local_data(data_path, tail_size=day_range)
# code_name = "000001.SZ"
if code_name not in all_df:
print("要比對的股票不在當前下載的股票數據中")
vector_a = all_df[code_name].pct_chg
start_date_a = vector_a.index[0]
end_date_a = vector_a.index[-1]
ret = []
for ts_code, df in all_df.items():
if ts_code == code_name:
continue
if len(df) < 100:
print("股票[%s]交易日不足%s" % (ts_code, day_range))
continue
vector_b = df.pct_chg
start_date_b = vector_b.index[0]
end_date_b = vector_b.index[-1]
# 計算開始結束交易日之間的時間間隔
start_delta = abs(start_date_a - start_date_b)
end_delta = abs(end_date_a - end_date_b)
if start_delta > max_delta or end_delta > max_delta:
print("股票[%s]與股票[%s]交易日間隔過大!" % (ts_code, code_name))
continue
cos_similarity = cos(vector_a, vector_b)
ret.append((ts_code, cos_similarity))
ret.sort(key=lambda x:x[1])
print("相似度前%s的結果如下" % top_size)
print(ret[-top_size:])
print("最不相似的股票前%s的結果如下:" % top_size)
print(ret[:top_size])
return ret[-top_size:]結果如下:
相似度前10的結果如下
[('601838.SH', 0.8413642902505222), ('600036.SH', 0.8435001924441485), ('601169.SH', 0.8446885175520177), ('600016.SH', 0.8460465823734755), ('601009.SH', 0.8472997719986147), ('601336.SH', 0.8493514488651387), ('601998.SH', 0.8501435442736384), ('601318.SH', 0.8515548626391685), ('601997.SH', 0.8723615980483687), ('601166.SH', 0.8951643562949727)]
最不相似的股票前10的結果如下:
[('600179.SH', -0.28209061607471647), ('002107.SZ', -0.2760541800360499), ('600630.SH', -0.2698469313704402), ('000790.SZ', -0.25063912833911006), ('002950.SZ', -0.24371742830236853), ('601718.SH', -0.24320952954633515), ('002603.SZ', -0.23229949296048), ('002022.SZ', -0.2298724102455836), ('688399.SH', -0.22925118956499124), ('688068.SH', -0.2222771289248757)]可以發現最相似的是601838(成都銀行)。
兩隻股票最近的走勢如下
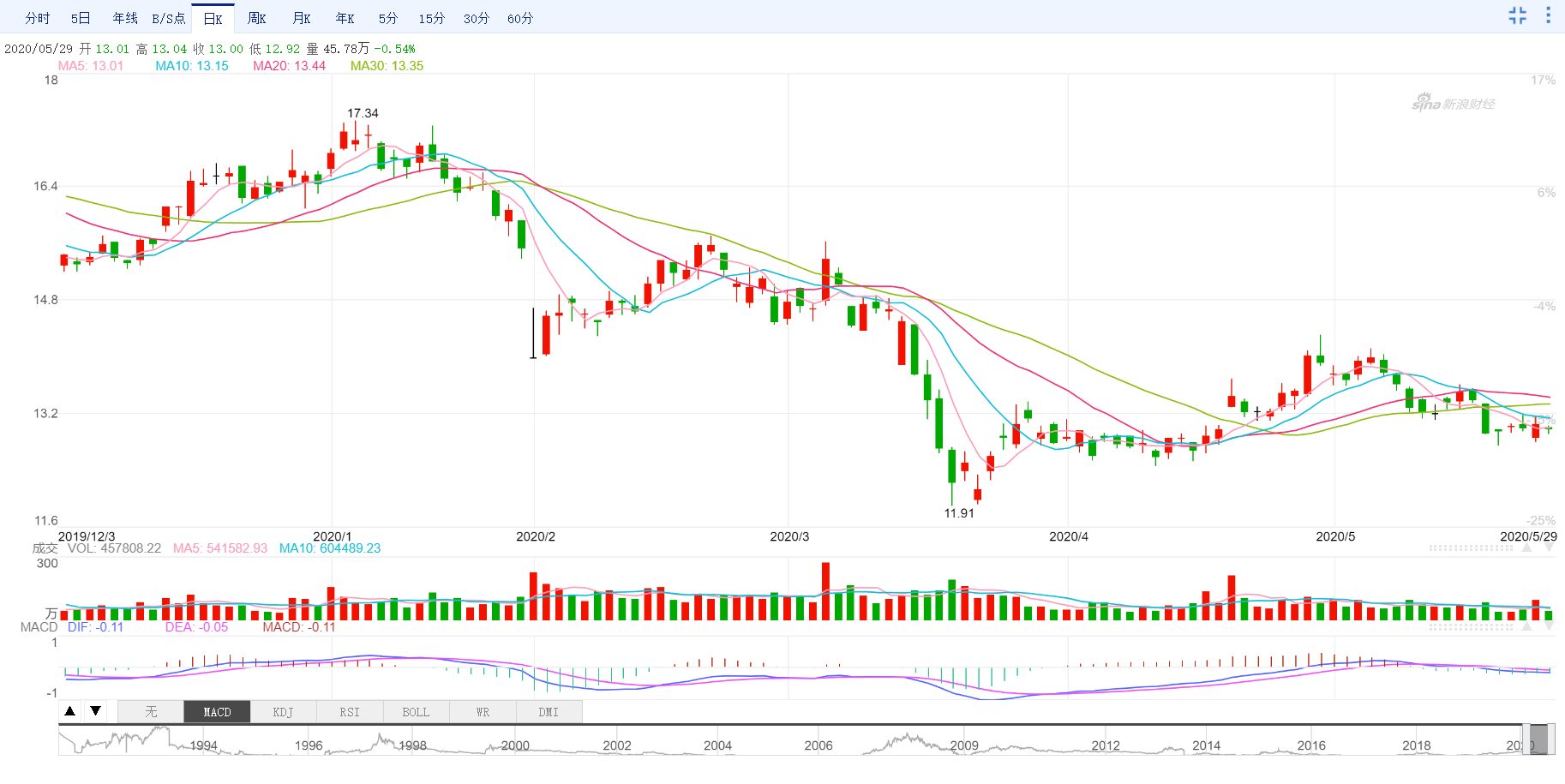
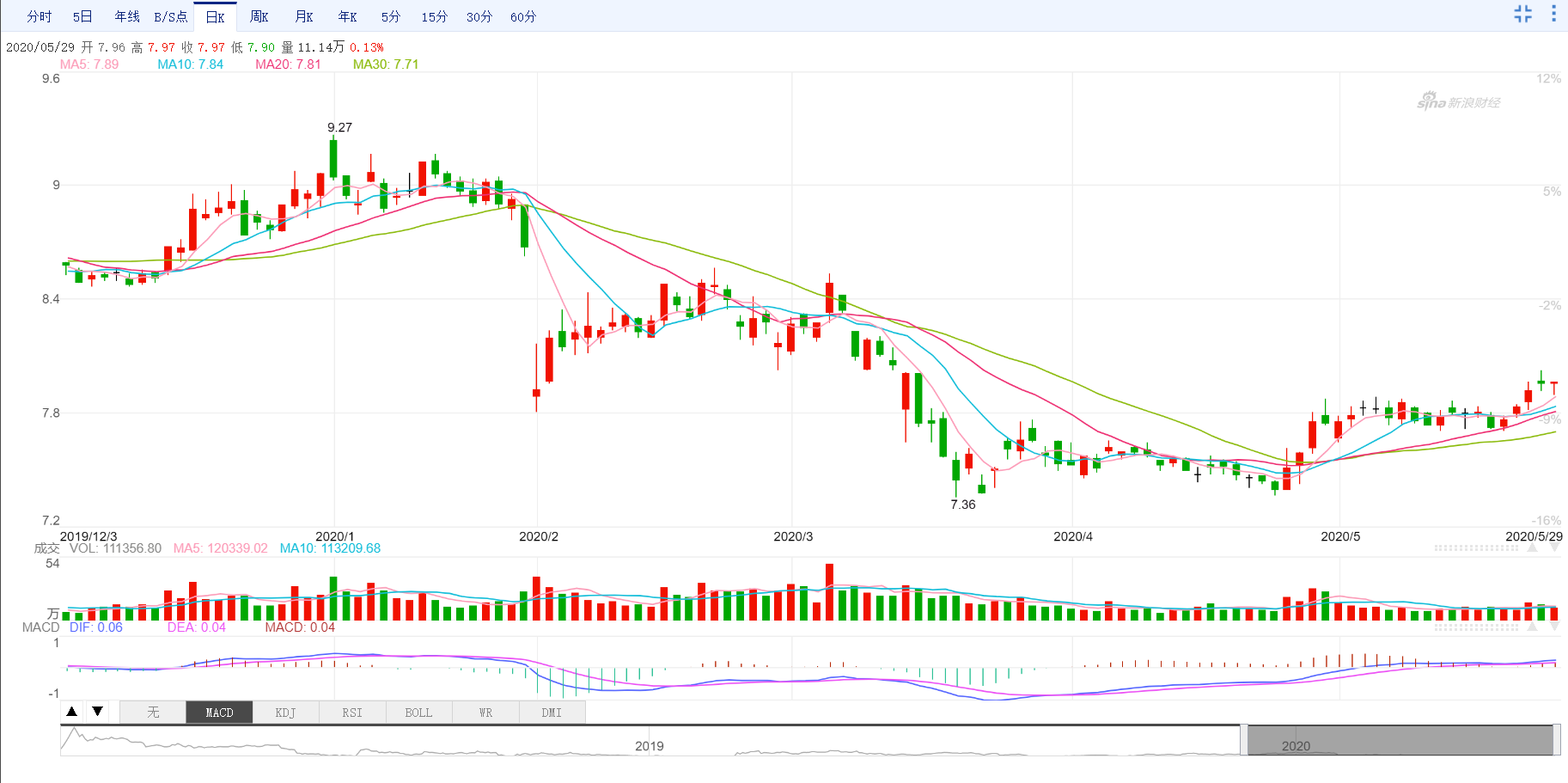
數據來自新浪財經
可以發現,雖然價格不同,但是相似度無論是通過計算公式計算還是人眼觀察都有比較強的相似度的。
趨勢選股
世上指標千千萬,獨愛均線,
首先,我們誰都不能預測未來,那麼各種指標都是滯後的,均線也不例外,我們能看到的只有過去跟現在,既然如此就簡單點吧,那些計算如此複雜的指標真的能比均線看的遠一些麼?
關於均線還有一些衍生的玩法,比如不同頻率的均線的密集程度來判斷趨勢的啓動與結束,以及股價與均線的差異值來判斷股價的偏離程度,也是因爲這些衍生的玩法,讓我覺得對於一個想做趨勢交易的我覺得,均線於我而言,遠遠足夠了。
通過均線的密集程度判斷趨勢的開端。
而後面趨勢是漲還是跌,誰知道呢。
def select_by_trend(data_path, code_name, ma_lst=None):
fp = path.join(data_path, ("%s-.csv" % code_name))
if not path.exists(fp):
print("股票[%s]不存在本地數據" % code_name)
df = pd.read_csv(fp, index_col="trade_date", parse_dates=["trade_date"])
ohlc_columns = ["open", "high", "low", "close"]
df = df[ohlc_columns]
if ma_lst is None:
ma_lst = [5, 20, 60, 120, 220]
max_ma = max(ma_lst)
ma_name_lst = []
for ma in ma_lst:
ma_name = "ma_%s" % ma
ma_name_lst.append(ma_name)
df[ma_name] = df.close.rolling(ma).mean()
# 設置圖片大小
plt.figure(figsize=(10,6))
# 過濾掉沒有最長均線數據的交易日
df2 = df.iloc[max_ma:]
# 繪製k線圖
ax = ohlc_plot(df2[ohlc_columns])
# 繪製均線圖
df2[ma_name_lst].plot(ax=ax)
plt.savefig("ma.png")
plt.show()結果如下:
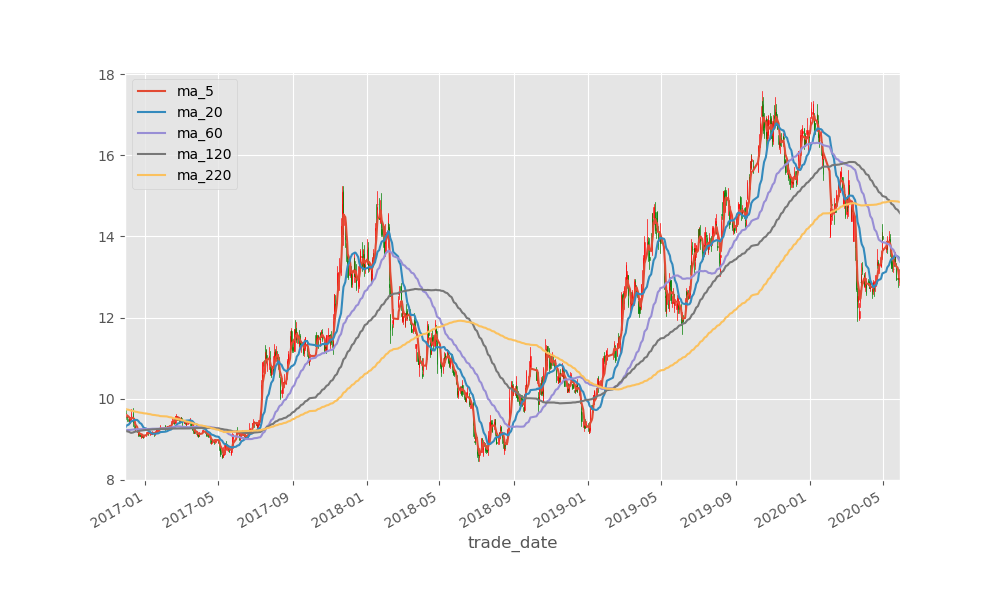
下面是本人用於分析的基本圖表,僅供參考。也歡迎討論。
代碼如下:
def select_by_nobody(data_path, code_name, ma_lst=None, threshold=20, atr_period=14, diff_ma=20):
fp = path.join(data_path, ("%s-.csv" % code_name))
if not path.exists(fp):
print("股票[%s]不存在本地數據" % code_name)
df = pd.read_csv(fp, index_col="trade_date", parse_dates=["trade_date"])
ohlc_columns = ["open", "high", "low", "close"]
df = df[ohlc_columns]
if ma_lst is None:
ma_lst = [5, 20, 60, 120, 220]
max_ma = max(ma_lst)
# 計算均線
ma_name_lst = []
for ma in ma_lst:
ma_name = "ma%s" % ma
ma_name_lst.append(ma_name)
df[ma_name] = df.close.rolling(ma).mean()
# 默認以20日最高價作爲上突破閾值, 20日最低價作爲下突破閾值
threshold_high_name = "threshold_high%s" % threshold
threshold_low_name = "threshold_low%s" % threshold
df[threshold_high_name] = df.high.rolling(threshold).max()
df[threshold_low_name] = df.low.rolling(threshold).min()
# 默認atr的計算時間範圍是14天
# talib一般通過包裝好的whl包安裝
# 參考: https://www.lfd.uci.edu/~gohlke/pythonlibs/
import talib
atr_name = "atr%s" % atr_period
df[atr_name] = talib.ATR(df.high, df.low, df.close, atr_period)
# 默認計算乖離率收盤價與20日均線的差值, 然後將這個差值比上收盤價, 這個值被稱爲乖離率
# 通過乖離率可以觀察收盤價與均值之間的差異,差異越大則可能回彈的概率比較大
if diff_ma not in ma_lst:
ma_name = "ma%s" % diff_ma
df[ma_name] = df.close.rolling(ma).mean()
diff_name = "diff%s" % diff_ma
df[diff_name] = (df["close"] - df[ma_name]) / df["close"]
# 設置圖片大小
plt.figure(figsize=(10,18))
# 配置子圖
ax1 = plt.subplot(311)
ax2 = plt.subplot(312)
ax3 = plt.subplot(313)
# 過濾掉沒有最長均線數據的交易日
df2 = df.iloc[max_ma:]
# 繪製k線圖
ohlc_plot(df2[ohlc_columns], ax1)
# 繪製均線圖
df2[ma_name_lst].plot(ax=ax1)
# 繪製上下最高最低突破線
df2[[threshold_high_name, threshold_low_name]].plot(ax=ax1)
# 繪製atr
df2[atr_name].plot(ax=ax2)
# 繪製乖離率
df2[diff_name].plot(ax=ax3)
plt.savefig("nobody.png")
plt.show()結果如下:
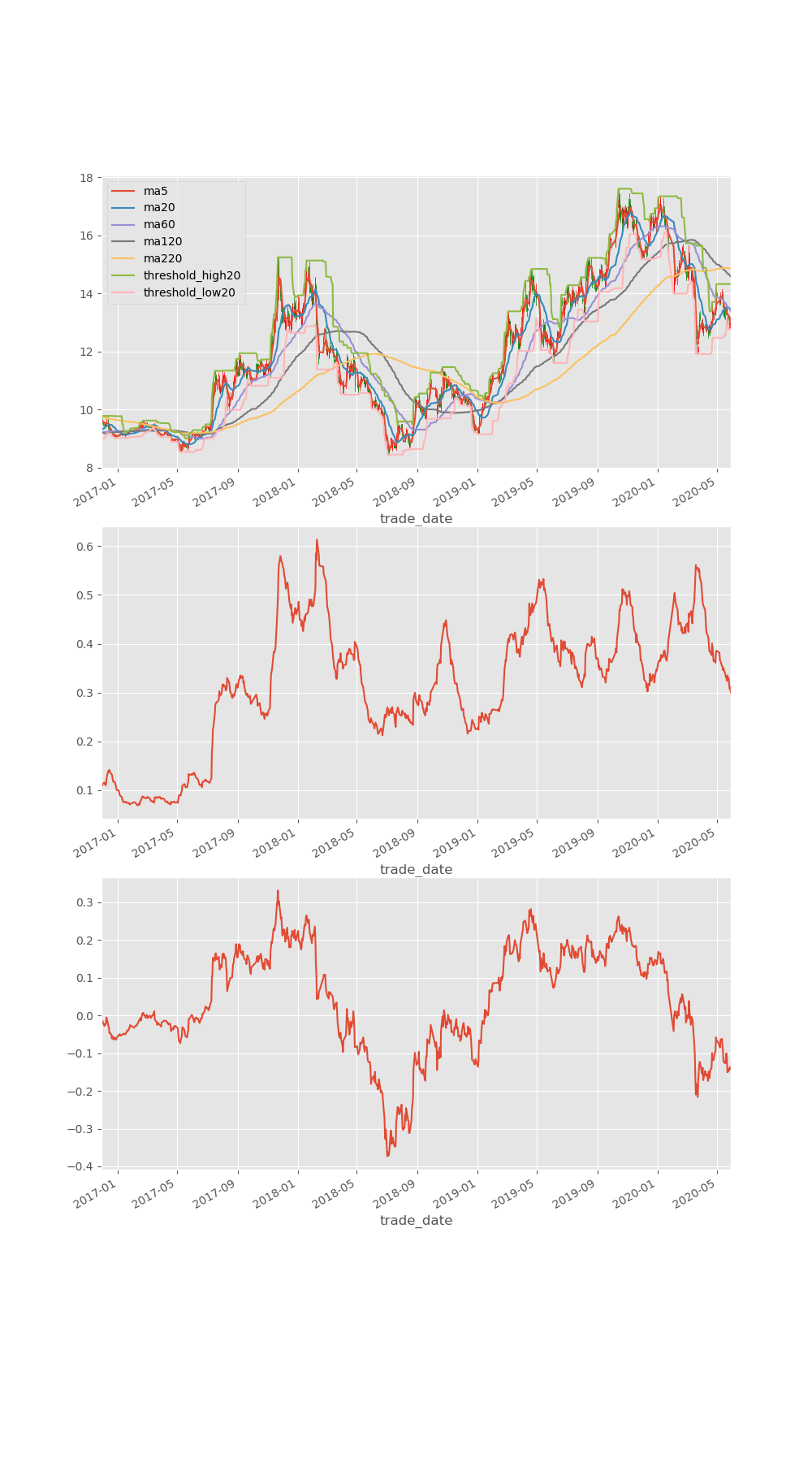
代碼裏面用了talib, 大家如果pip安裝不了, 就去https://www.lfd.uci.edu/~gohlke/pythonlibs/下載對應的安裝包吧。
源代碼
https://github.com/youerning/blog/tree/master/stock_pool
如果期待後續文章可以關注我的微信公衆號(又耳筆記),頭條號(又耳筆記),Github(youerning).
總結
這裏簡單介紹了一下我暫時所能囊括的4種選股方法,如果大家還有別的看法歡迎在評論中與我討論。
值得說明的是,我並不期望通過編程就能隨隨便便的從股市中賺錢,只是人的精力有限,本人又比較懶,那麼讓程序來完成一些我能通過程序描述的選股方法那麼何樂而不爲呢。