




日前國內沒有一套比較完整的NoSQL數據庫資料,有很多先驅整理髮表了很多,但不是很系統。不材嘗試着將各家的資料整合一下,並書寫了一些自己的見解。 說起來很有趣,BASE的英文意義是鹼,而ACID是酸。真的是水火不容啊。 各種操作的時間,以2001年夏季,典型配置的 1GHz 個人計算機爲標準: 你是否需要改變對應用和硬件的思維方式,最終取決於你要用它們完成的工作。但似乎公論認爲,開發者解決性能和可伸縮性的思路已經到了該變一變的時候。 Amdahl 定律的加速比:S(n) = 使用1個處理器的串行計算時間 / 使用n個處理器的並行計算時間 S(n) = 1/(K+(1-K)/n) = n/(1+(n-1)K) Gustafson定律的加速比:S(n) = 使用n個處理器的並行計算量 / 使用1個處理器的串行計算量 S(n) = K+(1-K)n aw2.0公司的Alan Williamson撰寫了一篇報道,主要是關於他在Amazon EC2上的體驗的,他抱怨說,Amazon是公司唯一使用的雲提供商,看起來它在開始時能夠適應得很好,但是有一個臨界點: …… 然而,在最後的八個月左右,他們“盔甲”內的漏洞開始呈現出來了。第一個弱點前兆是,新加入的Amazon SMALL實例的性能出現了問題。根據我們的監控,在服務器場中新添加的機器,與原先的那些相比性能有所下降。開始我們認爲這是自然出現的怪現象,只是碰 巧發生在“吵鬧的鄰居”(Noisy Neighbors)旁邊。根據隨機法則,一次快速的停機和重新啓動經常就會讓我們回到“安靜的鄰居”旁邊,那樣我們可以達到目的。 …… Gossip協議是一個Gossip思想的P2P實現。現代的分佈式系統經常使用這個協議,他往往是唯一的手段。因爲底層的結構非常複雜,而且Gossip也很有效。 Gossip協議也被戲稱爲病毒式傳播,因爲他的行爲生物界的病毒很相似。 數據庫以行、列的二維表的形式存儲數據,但是卻以一維字符串的方式存儲,例如以下的一個表: 這個表存儲在電腦的內存(RAM)和存儲(硬盤)中。雖然內存和硬盤在機制上不同,電腦的操作系統是以同樣的方式存儲的。數據庫必須把這個二維表存儲在一系列一維的“字節”中,又操作系統寫到內存或硬盤中。 行式數據庫把一行中的數據值串在一起存儲起來,然後再存儲下一行的數據,以此類推。 列式數據庫把一列中的數據值串在一起存儲起來,然後再存儲下一列的數據,以此類推。 Memcached處理的原子是每一個(key,value)對(以下簡稱kv對),key會通過一個hash算法轉化成hash-key,便於查找、對比以及做到儘可能的散列。同時,memcached用的是一個二級散列,通過一張大hash表來維護。 Memcached有兩個核心組件組成:服務端(ms)和客戶端(mc),在一個memcached的查詢中,mc先通過計算key的hash值來 確定kv對所處在的ms位置。當ms確定後,客戶端就會發送一個查詢請求給對應的ms,讓它來查找確切的數據。因爲這之間沒有交互以及多播協議,所以 memcached交互帶給網絡的影響是最小化的。 默認情況下,ms是用一個內置的叫“塊分配器”的組件來分配內存的。捨棄c++標準的malloc/free的內存分配,而採用塊分配器的主要目的 是爲了避免內存碎片,否則操作系統要花費更多時間來查找這些邏輯上連續的內存塊(實際上是斷開的)。用了塊分配器,ms會輪流的對內存進行大塊的分配,並 不斷重用。當然由於塊的大小各不相同,當數據大小和塊大小不太相符的情況下,還是有可能導致內存的浪費。 同時,ms對key和data都有相應的限制,key的長度不能超過250字節,data也不能超過塊大小的限制 --- 1MB。 當ms的hash表滿了之後,新的插入數據會替代老的數據,更新的策略是LRU(最近最少使用),以及每個kv對的有效時限。Kv對存儲有效時限是在mc端由app設置並作爲參數傳給ms的。 同時ms採用是偷懶替代法,ms不會開額外的進程來實時監測過時的kv對並刪除,而是當且僅當,新來一個插入的數據,而此時又沒有多餘的空間放了,纔會進行清除動作。 現在memcached最流行的一種使用方式是緩存數據庫查詢,下面舉一個簡單例子說明: App需要得到userid=xxx的用戶信息,對應的查詢語句類似: “SELECT * FROM users WHERE userid = xxx” App先去問cache,有沒有“user:userid”(key定義可預先定義約束好)的數據,如果有,返回數據;如果沒有,App會從數據庫中讀取數據,並調用cache的add函數,把數據加入cache中。 當取的數據需要更新,app會調用cache的update函數,來保持數據庫與cache的數據同步。 從上面的例子我們也可以發現,一旦數據庫的數據發現變化,我們一定要及時更新cache中的數據,來保證app讀到的是同步的正確數據。當然我們可 以通過定時器方式記錄下cache中數據的失效時間,時間一過就會激發事件對cache進行更新,但這之間總會有時間上的延遲,導致app可能從 cache讀到髒數據,這也被稱爲狗洞問題。(以後我會專門描述研究這個問題) 從設計角度上,memcached是沒有數據冗餘環節的,它本身就是一個大規模的高性能cache層,加入數據冗餘所能帶來的只有設計的複雜性和提高系統的開支。 當一個ms上丟失了數據之後,app還是可以從數據庫中取得數據。不過更謹慎的做法是在某些ms不能正常工作時,提供額外的ms來支持cache,這樣就不會因爲app從cache中取不到數據而一下子給數據庫帶來過大的負載。 同時爲了減少某臺ms故障所帶來的影響,可以使用“熱備份”方案,就是用一臺新的ms來取代有問題的ms,當然新的ms還是要用原來ms的IP地址,大不了數據重新裝載一遍。 另外一種方式,就是提高你ms的節點數,然後mc會實時偵查每個節點的狀態,如果發現某個節點長時間沒有響應,就會從mc的可用server列表裏 刪除,並對server節點進行重新hash定位。當然這樣也會造成的問題是,原本key存儲在B上,變成存儲在C上了。所以此方案本身也有其弱點,最好 能和“熱備份”方案結合使用,就可以使故障造成的影響最小化。 Memcached客戶端有各種語言的版本供大家使用,包括java,c,php,.net等等,具體可參見memcached api page [2]。 有了緩存的支持,我們可以在傳統的app層和db層之間加入cache層,每個app服務器都可以綁定一個mc,每次數據的讀取都可以從ms中取得,如果 沒有,再從db層讀取。而當數據要進行更新時,除了要發送update的sql給db層,同時也要將更新的數據發給mc,讓mc去更新ms中的數據。 Yahoo!的PNUTS是一個分佈式的數據存儲平臺,它是Yahoo!雲計算平臺重要的一部分。它的上層產品通常也稱爲Sherpa。按照官方的 描述,”PNUTS, a massively parallel and geographically distributed database system for Yahoo!’s web applications.” PNUTS顯然就深諳CAP之道,考慮到大部分web應用對一致性並不要求非常嚴格,在設計上放棄了對強一致性的追求。代替的是追求更高的 availability,容錯,更快速的響應調用請求等。 SQL數據服務 是微軟 Azure 網 絡服務平臺的一部分。該SDS服務也是處於測試階段,因此也是免費的,但對數據庫大小有限制。 SQL數據服務其自身實際上是一項處在許多SQL服務器之上的應用,這些SQL服務器組成了SDS平臺底層的數據存儲。你不需要訪問到它們,雖然底層的數 據庫可能是關係式的;SDS是一個鍵/值型倉儲,正如我們迄今所討論過的其它平臺一樣。 在雲之外,也有一些可以獨立安裝的鍵/值數據庫軟件產品。大部分都還很年輕,不是alpha版就是beta版,但大都是開源的;通過看看它的代碼,比起在非開源供應商那裏,你也許更能意識到潛在的問題和限制。 CouchDB: API: JSON, Protocol: REST, Query Method: MapReduceR of JavaScript Funcs, Replication: Master Master, Written in: Erlang, Concurrency: MVCC, Misc: 應用場景 在我們的生活中,有很多document,比如信件,賬單,筆記等,他們只是簡單的信息,沒有關係的需求,我們可能僅僅需要存儲這些數據。 這樣的情況下,CouchDB應該是很好的選擇。當然其他使用關係型數據庫的環境,也可以使用CouchDB來解決。 根據CouchDB的特性,在某些偶 爾連接網絡的應用中,我們可以用CouchDB暫存數據,隨後進行同步。也可以在Cloud環境中,作爲分佈式的數據存儲。CouchDB提供給予 HTTP的API,這樣所有的常見語言都可以使用CouchDB。 使用CouchDB,意味着我們不需要在像使用RMDBS一樣,在設計應用前首先設計負責數據Table。我們的開發更加快速,靈活。 Riak: API: JSON, Protocol: REST, Query Method: MapReduce term matching , Scaling: Multiple Masters; Written in: Erlang, Concurrency: eventually consistent (stronger then MVCC via Vector Clocks), Misc: ... Links: talk ?, MongoDB: API: BSON, Protocol: lots of langs, Query Method: dynamic object-based language, Replication: Master Slave, Written in: C++,Concurrency: Update in Place. Misc: ... Links: Talk ?, ThruDB: (please help provide more facts!) Uses Apache Thrift to integrate multiple backend databases as BerkeleyDB, Disk, MySQL, S3. Amazon SimpleDB: Misc: not open source, Book ? Redis : (please help provide more facts!) API: Tons of languages, Written in: C, Concurrency: in memory and saves asynchronous disk after a defined time. Append only mode available. Different kinds of fsync policies. Replication: Master / Slave, Scalaris: (please help provide more facts!) Written in: Erlang, Replication: Strong consistency over replicas, Concurrency: non blocking Paxos. GT.M: API: M, C, Python, Perl, Protocol: native, inprocess C, Misc: Wrappers: M/DB for SimpleDB compatible HTTP ?, MDB:X for XML ?, PIP for mapping to tables for SQL ?, Features: Small footprint (17MB), Terabyte Scalability, Unicode support, Database encryption, Secure, ACID transactions (single node), eventual consistency (replication), License: AGPL v3 on x86 GNU/Linux, Links: Slides ?, Scalien: API / Protocol: http (text, html, JSON), C, C++, Python, Concurrency: Paxos. Berkley DB: API: Many languages, Written in: C, Replication: Master / Slave, Concurrency: MVCC, License: Sleepycat, BerkleyDB Java Edition: API: Java, Written in: Java, Replication: Master / Slave, Concurrency: serializable transaction isolation, License: Sleepycat MemcacheDB: API: Memcache protocol (get, set, add, replace, etc.), Written in: C, Data Model: Blob, Misc: Is Memcached writing to BerkleyDB. LightCloud: (based on Tokyo Tyrant) HamsterDB: (embedded solution) ACID Compliance, Lock Free Architecture (transactions fail on conflict rather than block), Transaction logging & fail recovery (redo logs), In Memory support – can be used as a non-persisted cache, B+ Trees – supported [Source: Tony Bain ?] TC是日本第一大SNS網站mixi開發的,而Flare是日本第二大SNS網站green.jp開發的,有意思吧。Flare簡單的說就是給 TC添加了scale功能。他替換掉了TT部分,自己另外給TC寫了網絡服務器,Flare的主要特點就是支持scale能力,他在網絡服務端之前添加了 一個node server,來管理後端的多個服務器節點,因此可以動態添加數據庫服務節點,刪除服務器節點,也支持failover。如果你的使用場景必須要讓TC可 以scale,那麼可以考慮flare。 Amazon Dynamo: Misc: not open source (see KAI below) 可以根據應用類型優化(可用性,容錯性,高效性配置) BeansDB 是一個主要針對大數據量、高可用性的分佈式KeyValue存儲系統,採用HashTree和簡化的版本號來快速同步保證最終一致性(弱),一個簡化版的Dynamo。 它採用類似memcached的去中心化結構,在客戶端實現數據路由。目前只提供了Python版本的客戶端,其它語言的客戶端可以由memcached的客戶端稍加改造得到。 Google Group: http://groups.google.com/group/beandb/ # memstorm -s localhost:7900 -n 1000 􀂄 服務器 請求數 評價時間(ms) 中位數(ms) 99% (ms) 99.9%(ms) 人人網研發中的數據庫 1. 萬事皆異步 Voldemort: (can you help) KAI: Open Source Amazon Dnamo implementation, Misc: slides , 全新的Ruby MapReduce實現 Drizzle可 被認爲是鍵/值存儲要解決的問題的反向方案。Drizzle誕生於MySQL(6.0)關係數據庫的拆分。在過去幾個月裏,它的開發者已經移走了大量非核 心的功能(包括視圖、觸發器、已編譯語句、存儲過程、查詢緩衝、ACL以及一些數據類型),其目標是要建立一個更精簡、更快的數據庫系統。Drizzle 仍能存放關係數據;正如MySQL/Sun的Brian Aker所說那樣:“沒理由潑洗澡水時連孩子也倒掉”。它的目標就是,針對運行於16核(或以上)系統上的以網絡和云爲基礎的應用,建立一個半關係型數據 庫平臺。 最近看到的另外一個介紹Twitter技術的視頻[Slides] [Video (GFWed)],這是Twitter的John Adams在Velocity 2009的一個演講,主要介紹了Twitter在系統運維方面一些經驗。 本文大部分整理的觀點都在Twitter(@xmpp)上發過,這裏全部整理出來並補充完整。 Twitter沒有自己的硬件,都是由NTTA來提供,同時NTTA負責硬件相關的網絡、帶寬、負載均衡等業務,Twitter operations team只關注核心的業務,包括Performance,Availability,Capacity Planning容量規劃,配置管理等,這個可能跟國內一般的互聯網公司有所區別。 Twitter的監控後臺幾乎都是圖表(critical metrics),類似駕駛室的轉速錶,時速表,讓操作者可以迅速的瞭解系統當前的運作狀態。聯想到我們做的類似監控後臺,數據很多,但往往還需要瀏覽者 做二次分析判斷,像這樣滿屏都是圖表的方法做得還不夠,可以學習下這方面經驗。 據John介紹可以從圖表上看到系統的瓶頸-系統最弱的環節(web, mq, cache, db?) 每個系統都需要一個自動配置管理系統,越早越好,這條一整理髮到Twitter上去之後引起很多回應。 配置界面可以enable/disable 高計算消耗或高I/O的功能,也相當於優雅降級,系統壓力過大時取消一些非核心但消耗資源大的功能。 Twitter做了一個”Seppaku” patch, 就是將Daemon在完成了n個requests之後主動kill掉,以保持健康的low memory狀態,這種做法據瞭解國內也有不少公司是這樣做。 Twitter將CPU由AMD換成Xeon之後,獲得30%性能提升,將CPU由雙核/4核換成8核之後,減少了40%的CPU, 不過John也說,這種升級不適合自己購買硬件的公司。 Twitter有上百個模塊,如果沒有一個好的制度,容易引起代碼修改衝突,並把問題帶給最終用戶。所以Twitter有一強制的source code review制度, 如果提交的代碼的svn comment沒有”reviewed by xxx”, 則pre-commit腳本會讓提交失敗, review過的代碼提交後會通過自動配置管理系統應用到上百臺服務器上。 有@xiaomics同學在Twitter上馬上就問,時間成本能否接受?如果有緊急功能怎麼辦?個人認爲緊急修改時有兩人在場,一人修改一人 review也不是什麼難事。 從部署圖表可以看到每個發佈版本的CPU及latency變化,如果某個新版本latency圖表有明顯的向上跳躍,則說明該發佈版本存在問題。另外在監控首頁列出各個模塊最後deploy版本的時間,可以清楚的看到代碼庫的現狀。 Campfire來協同工作,campfire有點像羣,但是更適合協同工作。對於Campfire就不做更多介紹,可參考Campfire官方說明。 目前報表工具最大的難點不在於報表的樣式(如斜線等),樣式雖較繁瑣但並非本質困難。最根本的難點在於業務 部門知道報表代表的真正含義,卻不知道報表的數據統計模型模型;而IT部門通過理解業務部門的描述,在數據庫端進行設置數據統計模型,卻對報表本身所代表 的價值很難理解。 幾個星期之前,我寫了一篇文章描述了常被稱作 NOSQL 的一類新型數據庫的背後驅動。幾個星期之前,我在Qcon上發表了一個演講,其中,我介紹了一個可伸縮(scalable)的 twitter 應用的構建模式,在我們的討論中,一個顯而易見的問題就是數據庫的可擴展性問題。要解答這個問題,我試圖尋找隱藏在各種 NOSQL 之後的共有模式,並展示他們是如何解決數據庫可擴展性問題的。在本文中,我將盡力勾勒出這些共有的原則。 與我們先前通過昂貴硬件之類的手段盡力去避免失效的手段不同,NOSQL實現都建立在硬盤、機器和網絡都會失效這些假設之上。我們需要認定,我們不 能徹底阻止這些時效,相反,我們需要讓我們的系統能夠在即使非常極端的條件下也能應付這些失效。Amazon S3 就是這種設計的一個好例子。你可以在我最近的文章 Why Existing Databases (RAC) are So Breakable! 中找到進一步描述。哪裏,我介紹了一些來自 Jason McHugh 的講演的面向失效的架構設計的內容(Jason 是在 Amazon 做 S3 相關工作的高級工程師)。 通過對數據進行分區,我們最小化了失效帶來的影響,也將讀寫操作的負載分佈到了不同的機器上。如果一個節點失效了,只有該節點上存儲的數據受到影響,而不是全部數據。 大部分 NOSQL 實現都基於數據副本的熱備份來保證連續的高可用性。一些實現提供了 API,可以控制副本的複製,也就是說,當你存儲一個對象的時候,你可以在對象級指定你希望保存的副本數。在 GigaSpaces,我們還可以立即複製一個新的副本到其他節點,甚至在必要時啓動一臺新機器。這讓我們不比在每個節點上保存太多的數據副本,從而降低 總存儲量以節約成本。 你還可以控制副本複製是同步還是異步的,或者兩者兼有。這決定了你的集羣的一致性、可用性與性能三者。對於同步複製,可以犧牲性能保障一致性和可用 性(寫操作之後的任意讀操作都可以保證得到相同版本的數據,即使是發生失效也會如此)。而最爲常見的 GigaSpaces 的配置是同步副本到被分界點,異步存儲到後端存儲。 要掌控不斷增長的數據,大部分 NOSQL 實現提供了不停機或完全重新分區的擴展集羣的方法。一個已知的處理這個問題的算法稱爲一致哈希。有很多種不同算法可以實現一致哈希。 一個算法會在節點加入或失效時通知某一分區的鄰居。僅有這些節點受到這一變化的影響,而不是整個集羣。有一個協議用於掌控需要在原有集羣和新節點之間重新分佈的數據的變換區間。 另一個(簡單很多)的算法使用邏輯分區。在邏輯分區中,分區的數量是固定的,但分區在機器上的分佈式動態的。於是,例如有兩臺機器和1000個邏輯 分區,那麼每500個邏輯分區會放在一臺機器上。當我們加入了第三臺機器的時候,就成了每 333 個分區放在一臺機器上了。因爲邏輯分區是輕量級的(基於內存中的哈希表),分佈這些邏輯分區非常容易。 第二種方法的優勢在於它是可預測並且一致的,而使用一致哈希方法,分區之間的重新分佈可能並不平穩,當一個新節點加入網絡時可能會消耗更長時間。一個用戶在這時尋找正在轉移的數據會得到一個異常。邏輯分區方法的缺點是可伸縮性受限於邏輯分區的數量。 更進一步的關於這一問題的討論,建議閱讀 Ricky Ho 的文章 NOSQL Patterns 。 在這個方面,不同的實現有相當本質的區別。不同實現的一個共性在於哈希表中的 key/value 匹配。一些市縣提供了更高級的查詢支持,比如面向文檔的方法,其中數據以 blob 的方式存儲,關聯一個鍵值對屬性列表。這種模型是一種無預定義結構的(schema-less)存儲,給一個文檔增加或刪除屬性非常容易,無需考慮文檔結 構的演進。而 GigaSpaces 支持很多 SQL 操作。如果 SQL查詢沒有指出特定的簡直,那麼這個查詢就會被並行地 map 到所有的節點去,由客戶端完成結果的匯聚。所有這些都是發生在幕後的,用戶代碼無需關注這些。 Map/Reduce 是一個經常被用來進行復雜分析的模型,經常會和 Hadoop 聯繫在一起。 map/reduce 常常被看作是並行匯聚查詢的一個模式。大部分 NOSQL 實現並不提供 map/reduce 的內建支持,需要一個外部的框架來處理這些查詢。對於 GigaSpaces 來說,我們在 SQL 查詢中隱含了對 map/reduce 的支持,同時也顯式地提供了一個稱爲 executors 的 API 來支持 map/reduce。在質疑模型中,你可以將代碼發送到數據所在地地方,並在該節點上直接運行復雜的查詢。 這方面的更多細節,建議閱讀 Ricky Ho 的文章 Query Processing for NOSQL DB 。 NOSQL 實現分爲基於文件的方法和內存中的方法。有些實現提供了混合模型,將內存和磁盤結合使用。兩類方法的最主要區別在於每 GB 成本和讀寫性能。 最近,斯坦福的一項稱爲“The Case for RAMCloud”的調查,對磁盤和內存兩種方法給出了一些性能和成本方面的有趣的比較。總體上說,成本也是性能的一個函數。對於較低性能的實現,磁盤方 案的成本遠低於基於內存的方法,而對於高性能需求的場合,內存方案則更加廉價。 內存雲的顯而易見的缺點就是單位容量的高成本和高能耗。對於這些指標,內存雲會比純粹的磁盤系統差50到100 倍,比使用閃存的系統差5-10倍(典型配置情況和指標參見參考文獻[1])。內存雲同時還比基於磁盤和閃存的系統需要更多的機房面積。這樣,如果一個應 用需要存儲大量的廉價數據,不需要高速訪問,那麼,內存雲將不是最佳選擇。 近來我見到的最多的問題就是 “NOSQL 是不是就是炒作?” 或 “NOSQL 會不會取代現在的數據庫?” 我的回答是——NOSQL 並非始於今日。很多 NOSQL 實現都已經存在了十多年了,有很多成功案例。我相信有很多原因讓它們在如今比以往更受歡迎了。首先是由於社會化網絡和雲計算的發展,一些原先只有很高端的 組織纔會面臨的問題,如今已經成爲普遍問題了。其次,已有的方法已經被發現無法跟隨需求一起擴展了。並且,成本的壓力讓很多組織需要去尋找更高性價比的方 案,並且研究證實基於普通廉價硬件的分佈式存儲解決方案甚至比現在的高端數據庫更加可靠。(進一步閱讀)所有這些導致了對這類“可伸縮性優先數據庫”的需求。這裏,我引用 AWS團隊的接觸工程師、VP, James Hamilton 在他的文章 One Size Does Not Fit All 中的一段話: “伸縮性優先應用是那些必須具備無限可伸縮性的應用,能夠不受限制的擴展比更豐富的功能更加重要。這些應用包括很多需要高 可伸縮性的網站,如 Facebook, MySpace, Gmail, Yahoo 以及 Amazon.com。有些站點實際上使用了關係型數據庫,而大部分實際上並未使用。這些服務的共性在於可擴展性比功能公衆要,他們無法泡在一個單一的 RDBMS 上。” 總結一下——我認爲,現有的 SQL 數據庫可能不會很快淡出歷史舞臺,但同時它們也不能解決世上的所有問題。NOSQL 這個名詞現在也變成了 Not Only SQL,這個變化表達了我的觀點。 本書不求利,只圖學術之便。感謝諸位大牛寫了那麼多的資料,如果您不願意被引用,學生會重寫相應的章節。 引用網誌多篇,由於涵蓋太廣難以一一校隊,特此致歉。 感謝Jdon,dbanotes,infoq和Timyang.您們分享和撰寫了那麼多有用的資料。 V0.1版本在2010.2.21發佈,提供了本書的主題框架 http://www.jdon.com/jivejdon/thread/37999序
本書寫了一些目前的NoSql的一些主要技術,算法和思想。同時列舉了大量的現有的數據庫實例。讀完全篇,相信讀者會對NoSQL數據庫瞭解個大概。
另外我還準備開發一個開源內存數據庫galaxydb.本書也是爲這個數據庫提供一些架構資料。思想篇
CAP

我準備提供第三種方案:實現可以配置CAP的數據庫,動態調配CAP。
最終一致性
下面以上面的場景來描述下不同程度的一致性:
變體
BASE
"Soft state" 可以理解爲"無連接"的, 而 "Hard state" 是"面向連接"的
最終一致性, 也是是 ACID 的最終目的。
BASE思想的主要實現有
1.按功能劃分數據庫
2.sharding碎片
BASE思想主要強調基本的可用性,如果你需要高可用性,也就是純粹的高性能,那麼就要以一致性或容錯性爲犧牲,BASE思想的方案在性能上還是有潛力可挖的。
其他
I/O的五分鐘法則

隨着閃存時代的來臨,五分鐘法則一分爲二:是把 SSD 當成較慢的內存(extended buffer pool )使用還是當成較快的硬盤(extended disk)使用。小內存頁在內存和閃存之間的移動對比大內存頁在閃存和磁盤之間的移動。在這個法則首次提出的 20 年之後,在閃存時代,5 分鐘法則依然有效,只不過適合更大的內存頁(適合 64KB 的頁,這個頁大小的變化恰恰體現了計算機硬件工藝的發展,以及帶寬、延時)。
不要刪除數據
Oren Eini(又名Ayende Rahien)建議開發者儘量避免數據庫的軟刪除操作,讀者可能因此認爲硬刪除是合理的選擇。作爲對Ayende文章的迴應,Udi Dahan強烈建議完全避免數據刪除。
所謂軟刪除主張在表中增加一個IsDeleted列以保持數據完整。如果某一行設置了IsDeleted標誌列,那麼這一行就被認爲是已刪除的。Ayende覺得這種方法“簡單、容易理解、容易實現、容易溝通”,但“往往是錯的”。問題在於:
刪除一行或一個實體幾乎總不是簡單的事件。它不僅影響模型中的數據,還會影響模型的外觀。所以我們纔要有外鍵去確保不會出現“訂單行”沒有對應的父“訂單”的情況。而這個例子只能算是最簡單的情況。……
當採用軟刪除的時候,不管我們是否情願,都很容易出現數據受損,比如誰都不在意的一個小調整,就可能使“客戶”的“最新訂單”指向一條已經軟刪除的訂單。
如果開發者接到的要求就是從數據庫中刪除數據,要是不建議用軟刪除,那就只能硬刪除了。爲了保證數據一致性,開發者除了刪除直接有關的數據行,還應該級聯地刪除相關數據。可Udi Dahan提醒讀者注意,真實的世界並不是級聯的:
假設市場部決定從商品目錄中刪除一樣商品,那是不是說所有包含了該商品的舊訂單都要一併消失?再級聯下去,這些訂單對應的所有發票是不是也該刪除?這麼一步步刪下去,我們公司的損益報表是不是應該重做了?
沒天理了。
問題似乎出在對“刪除”這詞的解讀上。Dahan給出了這樣的例子:
我說的“刪除”其實是指這產品“停售”了。我們以後不再賣這種產品,清掉庫存以後不再進貨。以後顧客搜索商品或者翻閱目錄的時候不會再看見這種商品,但管倉庫的人暫時還得繼續管理它們。“刪除”是個貪方便的說法。
他接着舉了一些站在用戶角度的正確解讀:
訂單不是被刪除的,是被“取消”的。訂單取消得太晚,還會產生花費。
員工不是被刪除的,是被“解僱”的(也可能是退休了)。還有相應的補償金要處理。
職位不是被刪除的,是被“填補”的(或者招聘申請被撤回)。
在上面這些例子中,我們的着眼點應該放在用戶希望完成的任務上,而非發生在某個
實體身上的技術動作。幾乎在所有的情況下,需要考慮的實體總不止一個。
爲了代替IsDeleted標誌,Dahan建議用一個代表相關數據狀態的字段:有效、停用、取消、棄置等等。用戶可以藉助這樣一個狀態字段回顧過去的數據,作爲決策的依據。
刪除數據除了破壞數據一致性,還有其它負面的後果。Dahan建議把所有數據都留在數據庫裏:“別刪除。就是別
刪除。”
RAM是硬盤,硬盤是磁帶
Jim Gray在過去40年中對技術發展有過巨大的貢獻,“內存是新的硬盤,硬盤是新的磁帶”是他的名言。“實時”Web應用不斷湧現,達到海量規模的系統越來越多,這種後浪推前浪的發展模式對軟硬件又有何影響?
Tim Bray早在網格計算成爲熱門話題之前,就討論過以RAM和網絡爲中心的硬件結構的優勢,可以用這種硬件建立比磁盤集羣速度更快的RAM集羣。
對於數據的隨機訪問,內存的速度比硬盤高几個數量級(即使是最高端的磁盤存儲系統也只是勉強達到1,000次尋道/秒)。其次, 隨着數據中心的網絡速度提高,訪問內存的成本更進一步降低。通過網絡訪問另一臺機器的內存比訪問磁盤成本更低。就在我寫下這段話的時候,Sun的 Infiniband產品線中有一款具備9個全互聯非阻塞端口交換機,每個端口的速度可以達到30Gbit/sec!Voltaire產品的端口甚至更多;簡直不敢想象。(如果你想了解這類超高性能網絡的最新進展,請關注Andreas Bechtolsheim在Standford開設的課程。)
執行單一指令
1 納秒
從L1 高速緩存取一個字
2 納秒
從內存取一個字
10 納秒
從磁盤取連續存放的一個字
200 納秒
磁盤尋址並取字
8 毫秒
以太網
2GB/s
Tim還指出Jim Gray的
名言中後半句所闡述的真理:“對於隨機訪問,硬盤慢得不可忍受;但如果你把硬盤當成磁帶來用,它吞吐連續數據的速率令人震驚;它天生適合用來給以RAM爲主的應用做日誌(logging and journaling)。”
時間閃到幾年之後的今天,我們發現硬件的發展趨勢在RAM和網絡領域勢頭不減,而在硬盤領域則止步不前。Bill McColl提到用於並行計算的海量內存系統已經出現:
內存是新的硬盤!硬盤速度提高緩慢,內存芯片容量指數上升,in-memory軟件架構有望給各類數據密集的應用帶來數量級的性能提升。小型機架服務器(1U、2U)很快就會具備T字節、甚至更大量的內存,這將會改變服務器架構中內存和硬盤之間的平衡。硬盤將成爲新的磁帶,像磁帶一樣作爲順序存儲介質使用(硬盤的順序訪問相當快速),而不再是隨機存儲介質(非常慢)。這裏面有着大量的機會,新產品的性能有望提高10倍、100倍。
Dare Obsanjo指出如果不把這句真言當回事,會帶來什麼樣的惡劣後果—— 也就是Twitter正面臨的麻煩。論及Twitter的內容管理,Obsanjo說,“如果一個設計只是簡單地反映了問題描述,你去實現它就會落入磁盤 I/O的地獄。不管你用Ruby on Rails、Cobol on Cogs、C++還是手寫彙編都一樣,讀寫負載照樣會害死你。”換言之,應該把隨機操作推給RAM,只給硬盤留下順序操作。
Tom White是Hadoop Core項目的提交者,也是Hadoop項目管理委員會的成員。他對Gray的真言中“硬盤是新的磁帶”部分作了更深入地探討。White在討論MapReduce編程模型的時候指出,爲何對於Hadloop這類工具來說,硬盤仍然是可行的應用程序數據存儲介質:
本質上,在MapReduce的工作方式中,數據流式地讀出和寫入硬盤,MapReduce是以硬盤的傳輸速率不斷地對這些數據進行排序和合並。 與之相比,訪問關係數據庫中的數據,其速率則是硬盤的尋道速率(尋道指移動磁頭到盤面上的指定位置讀取或寫入數據的過程)。爲什麼要強調這一點?請看看尋道時間和磁盤傳輸率的發展曲線。尋道時間每年大約提高5%,而數據傳輸率每年大約提高20%。尋道時間的進步比數據傳輸率慢——因此採用由數據傳輸率決定性能的模型是有利的。MapReduce正是如此。
雖然固態硬盤(SSD)能否改變尋道時間/傳輸率的對比還有待觀察,White文章的跟貼中,很多人都認爲SSD會成爲RAM/硬盤之爭中的平衡因素。
Nati Shalom對內存和硬盤在數據庫部署和使用中的角色作了一番有理有據的評述。 Shalom着重指出用數據庫集羣和分區來解決性能和可伸縮性的侷限。他說,“數據庫複製和數據庫分區都存在相同的基本問題,它們都依賴於文件系統/硬盤 的性能,建立數據庫集羣也非常複雜”。他提議的方案是轉向In-Memory Data Grid(IMDG),用Hibernate二級緩存或者GigaSpaces Spring DAO之類的技術作支撐,將持久化作爲服務(Persistence as a Service)提供給應用程序。Shalom解釋說,IMDG
提供在內存中的基於對象的數據庫能力,支持核心的數據庫功能,諸如高級索引和查詢、事務語義和鎖。IMDG還從應用程序的代碼中抽象出了數據的拓撲。通過這樣的方式,數據庫不會完全消失,只是挪到了“正確的”位置。
IMDG相比直接RDBMS訪問的優勢列舉如下:
Amdahl定律和Gustafson定律
這裏,我們都以S(n)表示n核系統對具體程序的加速比,K表示串行部分計算時間比例。
有點冷是不是?
通俗的講,Amdahl 定律將工作量看作1,有n核也只能分擔1-K的工作量;而Gustafson定律則將單核工作量看作1,有n核,就可以增加n(1-K)的工作量。
這裏沒有考慮引進分佈式帶來的開銷,比如網絡和加鎖。成本還是要仔細覈算的,不是越分佈越好。
控制算法的複雜性在常數範圍之內。
萬兆以太網
手段篇
一致性哈希

第二階段
爲了解決單點故障,使用 hash() mod (n/2), 這樣任意一個用戶都有2個服務器備選,可由client隨機選取。由於不同服務器之間的用戶需要彼此交互,所以所有的服務器需要確切的知道用戶所在的位置。因此用戶位置被保存到memcached中。
當一臺發生故障,client可以自動切換到對應backup,由於切換前另外1臺沒有用戶的session,因此需要client自行重新登錄。

這個階段的設計存在以下問題
負載不均衡,尤其是單臺發生故障後剩下一臺會壓力過大。
不能動態增刪節點
節點發生故障時需要client重新登錄
第三階段
打算去掉硬編碼的hash() mod n 算法,改用一致性哈希(consistent hashing)分佈
假如採用Dynamo中的strategy 1
我們把每臺server分成v個虛擬節點,再把所有虛擬節點(n*v)隨機分配到一致性哈希的圓環上,這樣所有的用戶從自己圓環上的位置順時針往下取到第一個vnode就是自己所屬節點。當此節點存在故障時,再順時針取下一個作爲替代節點。

優點:發生單點故障時負載會均衡分散到其他所有節點,程序實現也比較優雅。
亞馬遜的現狀
在開始的日子裏Amazon的表現非常棒。實例在幾分鐘內啓動,幾乎沒有遇到任何問題,即便是他們的小實例(SMALL INSTANCE)也很健壯,足以支持適當使用的MySQL數據庫。在20個月內,Amazon雲系統一切運轉良好,不需要任何的關心和抱怨。
算法的選擇
不同的哈希算法可以導致數據分佈的不同位置,如果十分均勻,那麼一次MapReduce就涉及節點較多,但熱點均勻,方便管理。反之,熱點不均,會大致機器效率發揮不完全。
Quorum NRW

只需W + R > N,就可以保證強一致性。
第一個關鍵參數是 N,這個 N 指的是數據對象將被複制到 N 臺主機上,N 在實例級別配置,協調器將負責把數據複製到 N-1 個節點上。N 的典型值設置爲 3.
復 制中的一致性,採用類似於 Quorum 系統的一致性協議實現。這個協議有兩個關鍵值:R 與 W。R 代表一次成功的讀取操作中最小參與節點數量,W 代表一次成功的寫操作中最小參與節點數量。R + W>N ,則會產生類似 quorum 的效果。該模型中的讀(寫)延遲由最慢的 R(W)複製決定,爲得到比較小的延遲,R 和 W 有的時候的和又設置比 N 小。
如果N中的1臺發生故障,Dynamo立即寫入到preference list中下一臺,確保永遠可寫入
如 果W+R>N,那麼分佈式系統就會提供強一致性的保證,因爲讀取數據的節點和被同步寫入的節點是有重疊的。在一個RDBMS的複製模型中 (Master/salve),假如N=2,那麼W=2,R=1此時是一種強一致性,但是這樣造成的問題就是可用性的減低,因爲要想寫操作成功,必須要等 2個節點都完成以後纔可以。
在分佈式系統中,一般都要有容錯性,因此一般N都是大於3的,此時根據CAP理論,一致性,可用性和分區容錯 性最多隻能滿足兩個,那麼我們就需要在一致性和分區容錯性之間做一平衡,如果要高的一致性,那麼就配置N=W,R=1,這個時候可用性就會大大降低。如果 想要高的可用性,那麼此時就需要放鬆一致性的要求,此時可以配置W=1,這樣使得寫操作延遲最低,同時通過異步的機制更新剩餘的N-W個節點。
當存儲系統保證最終一致性時,存儲系統的配置一般是W+R<=N,此時讀取和寫入操作是不重疊的,不一致性的窗口就依賴於存儲系統的異步實現方式,不一致性的窗口大小也就等於從更新開始到所有的節點都異步更新完成之間的時間。
(N,R,W) 的值典型設置爲 (3, 2 ,2),兼顧性能與可用性。R 和 W 直接影響性能、擴展性、一致性,如果 W 設置 爲 1,則一個實例中只要有一個節點可用,也不會影響寫操作,如果 R 設置爲 1 ,只要有一個節點可用,也不會影響讀請求,R 和 W 值過小則影響一致性,過大也不好,這兩個值要平衡。對於這套系統的典型的 SLA 要求 99.9% 的讀寫操作在 300ms 內完成。
無 論是Read-your-writes-consistency,Session consistency,Monotonic read consistency,它們都通過黏貼(stickiness)客戶端到執行分佈式請求的服務器端來實現的,這種方式簡單是簡單,但是它使得負載均衡以 及分區容錯變的更加難於管理,有時候也可以通過客戶端來實現Read-your-writes-consistency和Monotonic read consistency,此時需要對寫的操作的數據加版本號,這樣客戶端就可以遺棄版本號小於最近看到的版本號的數據。
在系統開發過程 中,根據CAP理論,可用性和一致性在一個大型分區容錯的系統中只能滿足一個,因此爲了高可用性,我們必須放低一致性的要求,但是不同的系統保證的一致性 還是有差別的,這就要求開發者要清楚自己用的系統提供什麼樣子的最終一致性的保證,一個非常流行的例子就是web應用系統,在大多數的web應用系統中都 有“用戶可感知一致性”的概念,這也就是說最終一致性中的“一致性窗口"大小要小於用戶下一次的請求,在下次讀取操作來之前,數據可以在存儲的各個節點之 間複製。還比如假如存儲系統提供了
read-your-write-consistency一致性,那麼當一個用戶寫操作完成以後可以立馬看到自己的更 新,但是其它的用戶要過一會纔可以看到更新。
幾種特殊情況:
W = 1, R = N,對寫操作要求高性能高可用。
R = 1, W = N , 對讀操作要求高性能高可用,比如類似cache之類業務。
W = Q, R = Q where Q = N / 2 + 1 一般應用適用,讀寫性能之間取得平衡。如N=3,W=2,R=2
Vector clock

vector clock算法。可以把這個vector clock想象成每個節點都記錄自己的版本信息,而一個數據,包含所有這些版本信息。來看一個例子:假設一個寫請求,第一次被節點A處理了。節點A會增加一個版本信息(A,1)。我們把這個時候的數據記做D1(A,1)。 然後另外一個對同樣key(這一段討論都是針對同樣的key的)的請求還是被A處理了於是有D2(A,2)。
這個時候,D2是可以覆蓋D1的,不會有衝突產生。現在我們假設D2傳播到了所有節點(B和C),B和C收到的數據不是從客戶產生的,而是別人複製給他們的,所以他們不產生新的版本信息,所以現在B和C都持有數據D2(A,2)。好,繼續,又一個請求,被B處理了,生成數據D3(A,2;B,1),因爲這是一個新版本的數據,被B處理,所以要增加B的版本信息。
假設D3沒有傳播到C的時候又一個請求被C處理記做D4(A,2;C,1)。假設在這些版本沒有傳播開來以前,有一個讀取操作,我們要記得,我們的W=1 那麼R=N=3,所以R會從所有三個節點上讀,在這個例子中將讀到三個版本。A上的D2(A,2);B上的D3(A,2;B,1);C上的D4(A,2;C,1)這個時候可以判斷出,D2已經是舊版本,可以捨棄,但是D3和D4都是新版本,需要應用自己去合併。
如果需要高可寫性,就要處理這種合併問題。好假設應用完成了衝入解決,這裏就是合併D3和D4版本,然後重新做了寫入,假設是B處理這個請求,於是有D5(A,2;B,2;C,1);這個版本將可以覆蓋掉D1-D4那四個版本。這個例子只舉了一個客戶的請求在被不同節點處理時候的情況, 而且每次寫更新都是可接受的,大家可以自己更深入的演算一下幾個併發客戶的情況,以及用一箇舊版本做更新的情況。
上面問題看似好像可以通過在三個節點裏選擇一個主節點來解決,所有的讀取和寫入都從主節點來進行。但是這樣就違背了W=1這個約定,實際上還是退化到W=N的情況了。所以如果系統不需要很大的彈性,W=N爲所有應用都接受,那麼系統的設計上可以得到很大的簡化。Dynamo 爲了給出充分的彈性而被設計成完全的對等集羣(peer to peer),網絡中的任何一個節點都不是特殊的。
Virtual node

虛擬節點,未完成gossip
Gossip (State Transfer Model)
在狀態轉移到模式下,每個重複節點都保持的一個Vector clock和一個state version tree。每個節點的狀態都是相同的(based on vector clock comparison),換句話說,state version tree包含有全部的衝突updates.
At query time, the client will attach its vector clock and the replica will send back a subset of the state tree which precedes the client's vector clock (this will provide monotonic read consistency). The client will then advance its vector clock by merging all the versions. This means the client is responsible to resolve the conflict of all these versions because when the client sends the update later, its vector clock will precede all these versions.


Replicas also gossip among each other in the background and try to merge their version tree together.

Gossip (Operation Transfer Model)
In an operation transfer approach, the sequence of applying the operations is very important. At the minimum causal order need to be maintained. Because of the ordering issue, each replica has to defer executing the operation until all the preceding operations has been executed. Therefore replicas save the operation request to a log file and exchange the log among each other and consolidate these operation logs to figure out the right sequence to apply the operations to their local store in an appropriate order.
"Causal order" means every replica will apply changes to the "causes" before apply changes to the "effect". "Total order" requires that every replica applies the operation in the same sequence.
In this model, each replica keeps a list of vector clock, Vi is the vector clock the replica itself and Vj is the vector clock when replica i receive replica j's gossip message. There is also a V-state that represent the vector clock of the last updated state.
When a query is submitted by the client, it will also send along its vector clock which reflect the client's view of the world. The replica will check if it has a view of the state that is later than the client's view.

When an update operation is received, the replica will buffer the update operation until it can be applied to the local state. Every submitted operation will be tag with 2 timestamp, V-client indicates the client's view when he is making the update request. V-@receive is the replica's view when it receives the submission.
This update operation request will be sitting in the queue until the replica has received all the other updates that this one depends on. This condition is reflected in the vector clock Vi when it is larger than V-client

On the background, different replicas exchange their log for the queued updates and update each other's vector clock. After the log exchange, each replica will check whether certain operation can be applied (when all the dependent operation has been received) and apply them accordingly. Notice that it is possible that multiple operations are ready for applying at the same time, the replica will sort these operation in causal order (by using the Vector clock comparison) and apply them in the right order.

The concurrent update problem at different replica can also happen. Which means there can be multiple valid sequences of operation. In order for different replica to apply concurrent update in the same order, we need a total ordering mechanism.
One approach is whoever do the update first acquire a monotonic sequence number and late comers follow the sequence. On the other hand, if the operation itself is commutative, then the order to apply the operations doesn't matter
After applying the update, the update operation cannot be immediately removed from the queue because the update may not be fully exchange to every replica yet. We continuously check the Vector clock of each replicas after log exchange and after we confirm than everyone has receive this update, then we'll remove it from the queue.
Merkle tree
有數據存儲成樹狀結構,每個節點的Hash是其所有子節點的Hash的Hash,葉子節點的Hash是其內容的Hash。這樣一旦某個節點發生變化,其Hash的變化會迅速傳播到根節點。需要同步的系統只需要不斷查詢跟節點的hash,一旦有變化,順着樹狀結構就能夠在logN級別的時間找到發生變化的內容,馬上同步。
Paxos
paxos是一種處理一致性的手段,可以理解爲事務吧。
其他的手段不要Google GFS使用的Chubby的Lock service。我不大喜歡那種重型的設計就不費筆墨了。
背景
一、Master/slave
這個是多機房數據訪問最常用的方案,一般的需求用此方案即可。因此大家也經常提到“premature optimization is the root of all evil”。
優點:利用mysql replication即可實現,成熟穩定。
缺點:寫操作存在單點故障,master壞掉之後slave不能寫。另外slave的延遲也是個困擾人的小問題。
二、Multi-master
Multi-master指一個系統存在多個master, 每個master都具有read-write能力,需根據時間戳或業務邏輯合併版本。比如分佈式版本管理系統git可以理解成multi-master模式。具備最終一致性。多版本數據修改可以借鑑Dynamo的vector clock等方法。
優點:解決了單點故障。
缺點:不易實現一致性,合併版本的邏輯複雜。
三、Two-phase commit(2PC)
Two-phase commit是一個比較簡單的一致性算法。由於一致性算法通常用神話(如Paxos的The Part-Time Parliament論文)來比喻容易理解,下面也舉個類似神話的例子。
某班要組織一個同學聚會,前提條件是所有參與者同意則活動舉行,任意一人拒絕則活動取消。用2PC算法來執行過程如下
Phase 1
Prepare: 組織者(coordinator)打電話給所有參與者(participant) ,同時告知參與者列表。
Proposal: 提出週六2pm-5pm舉辦活動。
Vote: participant需vote結果給coordinator:accept or reject。
Block: 如果accept, participant鎖住週六2pm-5pm的時間,不再接受其他請求。
Phase 2
Commit: 如果所有參與者都同意,組織者coodinator通知所有參與者commit, 否則通知abort,participant解除鎖定。
Failure 典型失敗情況分析
Participant failure:
任一參與者無響應,coordinator直接執行abort
Coordinator failure:
Takeover: 如果participant一段時間沒收到cooridnator確認(commit/abort),則認爲coordinator不在了。這時候可自動成爲Coordinator備份(watchdog)
Query: watchdog根據phase 1接收的participant列表發起query
Vote: 所有participant回覆vote結果給watchdog, accept or reject
Commit: 如果所有都同意,則commit, 否則abort。
優點:實現簡單。
缺點:所有參與者需要阻塞(block),throughput低;無容錯機制,一節點失敗則整個事務失敗。
四、Three-phase commit (3PC)
Three-phase commit是一個2PC的改進版。2PC有一些很明顯的缺點,比如在coordinator做出commit決策並開始發送commit之後,某個participant突然crash,這時候沒法abort transaction, 這時候集羣內實際上就存在不一致的情況,crash恢復後的節點跟其他節點數據是不同的。因此3PC將2PC的commit的過程1分爲2,分成preCommit及commit, 如圖。

(圖片來源:http://en.wikipedia.org/wiki/File:Three-phase_commit_diagram.png)
從圖來看,cohorts(participant)收到preCommit之後,如果沒收到commit, 默認也執行commit, 即圖上的timeout cause commit。
如果coodinator發送了一半preCommit crash, watchdog接管之後通過query, 如果有任一節點收到commit, 或者全部節點收到preCommit, 則可繼續commit, 否則abort。
優點:允許發生單點故障後繼續達成一致。
缺點:網絡分離問題,比如preCommit消息發送後突然兩個機房斷開,這時候coodinator所在機房會abort, 另外剩餘replicas機房會commit。
Google Chubby的作者Mike Burrows說過, “there is only one consensus protocol, and that’s Paxos” – all other approaches are just broken versions of Paxos. 意即“世上只有一種一致性算法,那就是Paxos”,所有其他一致性算法都是Paxos算法的不完整版。相比2PC/3PC, Paxos算法的改進
P1a. 每次Paxos實例執行都分配一個編號,編號需要遞增,每個replica不接受比當前最大編號小的提案
P2. 一旦一個 value v 被replica通過,那麼之後任何再批准的 value 必須是 v,即沒有拜占庭將軍(Byzantine)問題。拿上面請客的比喻來說,就是一個參與者一旦accept週六2pm-5pm的proposal, 就不能改變主意。以後不管誰來問都是accept這個value。
一個proposal只需要多數派同意即可通過。因此比2PC/3PC更靈活,在一個2f+1個節點的集羣中,允許有f個節點不可用。
另外Paxos還有很多約束的細節,特別是Google的chubby從工程實現的角度將Paxos的細節補充得非常完整。比如如何避免Byzantine問題,由於節點的持久存儲可能會發生故障,Byzantine問題會導致Paxos算法P2約束失效。
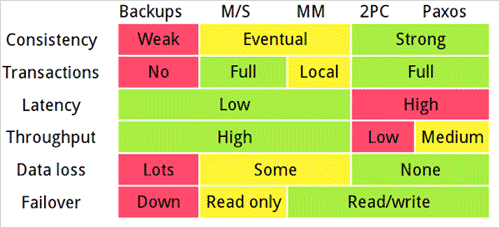
以上幾種方式原理比較如下

DHT
Distributed hash table

Map Reduce Execution
Map Reduce已經爛大街了,不過還是要提一下。
參見:http://zh.wikipedia.org/wiki/MapReduce

Handling Deletes
但我們執行刪除操作的時候必須非常謹慎,以防丟失掉相應的版本信息。
通常我們給一個Object標註上"已刪除"的標籤。在足夠的時間之後,我們在確保版本一致的情況下可以將它徹底刪除。回收他的空間。
存儲實現
One strategy is to use make the storage implementation pluggable. e.g. A local MySQL DB, Berkeley DB, Filesystem or even a in memory Hashtable can be used as a storage mechanism.
Another strategy is to implement the storage in a highly scalable way. Here are some techniques that I learn from CouchDB and Google BigTable.
CouchDB has a MVCC model that uses a copy-on-modified approach. Any update will cause a private copy being made which in turn cause the index also need to be modified and causing the a private copy of the index as well, all the way up to the root pointer.

Notice that the update happens in an append-only mode where the modified data is appended to the file and the old data becomes garbage. Periodic garbage collection is done to compact the data. Here is how the model is implemented in memory and disks

In Google BigTable model, the data is broken down into multiple generations and the memory is use to hold the newest generation. Any query will search the mem data as well as all the data sets on disks and merge all the return results. Fast detection of whether a generation contains a key can be done by checking a bloom filter.

When update happens, both the mem data and the commit log will be written so that if the
節點變化
Notice that virtual nodes can join and leave the network at any time without impacting the operation of the ring.
When a new node joins the network

Notice that other nodes may not have their membership view updated yet so they may still forward the request to the old nodes. But since these old nodes (which is the neighbor of the new joined node) has been updated (in step 2), so they will forward the request to the new joined node.
On the other hand, the new joined node may still in the process of downloading the data and not ready to serve yet. We use the vector clock (described below) to determine whether the new joined node is ready to serve the request and if not, the client can contact another replica.
When an existing node leaves the network (e.g. crash)

We haven't talked about how the virtual nodes is mapped into the physical nodes. Many schemes are possible with the main goal that Virtual Node replicas should not be sitting on the same physical node. One simple scheme is to assigned Virtual node to Physical node in a random manner but check to make sure that a physical node doesn't contain replicas of the same key ranges.
Notice that since machine crashes happen at the physical node level, which has many virtual nodes runs on it. So when a single Physical node crashes, the workload (of its multiple virtual node) is scattered across many physical machines. Therefore the increased workload due to physical node crashes is evenly balanced.
列存
描述
EmpId Lastname Firstname Salary
1
Smith
Joe
40000
2
Jones
Mary
50000
3
Johnson
Cathy
44000
這個簡單的表包括員工代碼(EmpId), 姓名字段(Lastname and Firstname)及工資(Salary).

特點
簡單分析含源碼
軟件篇
亞數據庫
我發明的新概念,就是稱不上數據庫但有一些數據庫的特徵。可以指緩存。
MemCached
Memcached是danga.com(運營LiveJournal的技術團隊)開發的一套分佈式內存對象緩存系統,用於在動態系統中減少數據庫 負載,提升性能。
特點


內存分配
因爲mc所使用的hash算法,並不會考慮到每個ms的內存大小。理論上mc會分配概率上等量的kv對給每個ms,這樣如果每個ms的內存都不太一樣,那 可能會導致內存使用率的降低。所以一種替代的解決方案是,根據每個ms的內存大小,找出他們的最大公約數,然後在每個ms上開n個容量=最大公約數的 instance,這樣就等於擁有了多個容量大小一樣的子ms,從而提供整體的內存使用率。 緩存策略
緩存數據庫查詢
數據冗餘與故障預防
Memcached客戶端(mc)
大家可以根據自己項目的需要,選擇合適的客戶端來集成。 緩存式的Web應用程序架構
性能測試
Memcached 寫速度
平均速度: 16222 次/秒
最大速度 18799 次/秒
Memcached 讀速度
平均速度: 20971 次/秒
最大速度 22497 次/秒
Memcachedb 寫速度
平均速度: 8958 次/秒
最大速度 10480 次/秒
Memcachedb 讀速度
平均速度: 6871 次/秒
最大速度 12542 次/秒
非常好的剖析文章
dbcached
● dbcached 是一款基於 Memcached 和 NMDB 的分佈式 key-value 數據庫內存緩存系統。
● dbcached = Memcached + 持久化存儲管理器 + NMDB 客戶端接口
● Memcached 是一款高性能的,分佈式的內存對象緩存系統,用於在動態應用中減少數據庫負載,提升訪問速度。
● NMDB 是一款多協議網絡數據庫(dbm類)管理器,它由內存緩存和磁盤存儲兩部分構成,使用 QDBM 或 Berkeley DB 作爲後端數據庫。
● QDBM 是一個管理數據庫的例程庫,它參照 GDBM 爲了下述三點而被開發:更高的處理速度,更小的數據庫文件大小,和更簡單的API。QDBM 讀寫速度比 Berkeley DB 要快,詳細速度比較見《Report of Benchmark Test》。

Memcached 和 dbcached 在功能上一樣嗎?
● 兼容:Memcached 能做的,dbcached 都能做。除此之外,dbcached 還將“Memcached、持久化存儲管理器、NMDB 客戶端接口”在一個程序中結合起來,對任何原有 Memcached 客戶端來講,dbcached 仍舊是個 Memcached 內存對象緩存系統,但是,它的數據可以持久存儲到本機或其它服務器上的 QDBM 或 Berkeley DB 數據庫中。
● 性能:前端 dbcached 的併發處理能力跟 Memcached 相同;後端 NMDB 跟 Memcached 一樣,採用了libevent 進行網絡IO處理,擁有自己的內存緩存機制,性能不相上下。
● 寫入:當“dbcached 的 Memcached 部分”接收到一個 set(add/replace/...) 請求並儲存 key-value 數據到內存中後,“dbcached 持久化存儲管理器”能夠將 key-value 數據通過“NMDB 客戶端接口”保存到 QDBM 或 Berkeley DB 數據庫中。
● 速度:如果加上“-z”參數,採用 UDP 協議“只發送不接收”模式將 set(add/replace/...) 命令寫入的數據傳遞給 NMDB 服務器端,對 Memcache 客戶端寫速度的影響幾乎可以忽略不計。在千兆網卡、同一交換機下服務器之間的 UDP 傳輸丟包率微乎其微。在命中的情況下,讀取數據的速度跟普通的 Memcached 無差別,速度一樣快。
● 讀取:當“dbcached 的 Memcached 部分”接收到一個 get(incr/decr/...) 請求後,如果“dbcached 的 Memcached 部分”查詢自身的內存緩存未命中,則“dbcached 持久化存儲管理器”會通過“NMDB 客戶端接口”從 QDBM 或 Berkeley DB 數據庫中取出數據,返回給用戶,然後儲存到 Memcached 內存中。如果有用戶再次請求這個 key,則會直接從 Memcached 內存中返回 Value 值。
● 持久:使用 dbcached,不用擔心 Memcached 服務器死機、重啓而導致數據丟失。
● 變更:使用 dbcached,即使因爲故障轉移,添加、減少 Memcached 服務器節點而破壞了“key 信息”與對應“Memcached 服務器”的映射關係也不怕。
● 分佈:dbcached 和 NMDB 既可以安裝在同一臺服務器上,也可以安裝在不同的服務器上,多臺 dbcached 服務器可以對應一臺 NMDB 服務器。
● 特長:dbcached 對於“讀”大於“寫”的應用尤其適用。
● 其他:《dbcached 的故障轉移支持、設計方向以及與 Memcachedb 的不同之處》
列存系列
Hadoop之Hbase
Hadoop / HBase: API: Java / any writer, Protocol: any write call, Query Method: MapReduce Java / any exec, Replication: HDFS Replication, Written in: Java, Concurrency: ?, Misc: Links: 3 Books [1, 2, 3]
耶魯大學之HadoopDB

GreenPlum

FaceBook之Cassandra
Cassandra: API: many Thrift ? languages, Protocol: ?, Query Method: MapReduce, Replicaton: , Written in: Java, Concurrency: eventually consistent , Misc: like "Big-Table on Amazon Dynamo alike", initiated by Facebook, Slides ? , Clients ?
Cassandra是facebook開源出來的一個版本,可以認爲是BigTable的一個開源版本,目前twitter和digg.com在使用。
Cassandra特點
Cassandra的主要特點就是它不是一個數據庫,而是由一堆數據庫節點共同構成的一個分佈式網絡服務,對Cassandra的一個寫操作,會 被複制到其他節點上去,對Cassandra的讀操作,也會被路由到某個節點上面去讀取。對於一個Cassandra羣集來說,擴展性能是比較簡單的事 情,只管在羣集裏面添加節點就可以了。我看到有文章說Facebook的Cassandra羣集有超過100臺服務器構成的數據庫羣集。
Cassandra也支持比較豐富的數據結構和功能強大的查詢語言,和MongoDB比較類似,查詢功能比MongoDB稍弱一些,twitter的平臺架構部門領導Evan Weaver寫了一篇文章介紹Cassandra:http://blog.evanweaver.com/articles/2009/07/06/up-and-running-with-cassandra/,有非常詳細的介紹。
Cassandra以單個節點來衡量,其節點的併發讀寫性能不是特別好,有文章說評測下來Cassandra每秒大約不到1萬次讀寫請求,我也看 到一些對這個問題進行質疑的評論,但是評價Cassandra單個節點的性能是沒有意義的,真實的分佈式數據庫訪問系統必然是n多個節點構成的系統,其並 發性能取決於整個系統的節點數量,路由效率,而不僅僅是單節點的併發負載能力。
Keyspace
Cassandra中的最大組織單元,裏面包含了一系列Column family,Keyspace一般是應用程序的名稱。你可以把它理解爲Oracle裏面的一個schema,包含了一系列的對象。
Column family(CF)
CF是某個特定Key的數據集合,每個CF物理上被存放在單獨的文件中。從概念上看,CF有點象數據庫中的Table.
Key
數據必須通過Key來訪問,Cassandra允許範圍查詢,例如:start => '10050', :finish => '10070'
Column
在Cassandra中字段是最小的數據單元,column和value構成一個對,比如:name:“jacky”,column是name,value是jacky,每個column:value後都有一個時間戳:timestamp。
和數據庫不同的是,Cassandra的一行中可以有任意多個column,而且每行的column可以是不同的。從數據庫設計的角度,你可以理解 爲表上有兩個字段,第一個是Key,第二個是長文本類型,用來存放很多的column。這也是爲什麼說Cassandra具備非常靈活schema的原 因。
Super column
Super column是一種特殊的column,裏面可以存放任意多個普通的column。而且一個CF中同樣可以有任意多個Super column,一個CF只能定義使用Column或者Super column,不能混用。下面是Super column的一個例子,homeAddress這個Super column有三個字段:分別是street,city和zip: homeAddress: {street: "binjiang road",city: "hangzhou",zip: "310052",}
Sorting
不同於數據庫可以通過Order by定義排序規則,Cassandra取出的數據順序是總是一定的,數據保存時已經按照定義的規則存放,所以取出來的順序已經確定了,這是一個巨大的性能優勢。有意思的是,Cassandra按照column name而不是column value來進行排序,它 定義了以下幾種選項:BytesType, UTF8Type, LexicalUUIDType, TimeUUIDType, AsciiType, 和LongType,用來定義如何按照column name來排序。實際上,就是把column name識別成爲不同的類型,以此來達到靈活排序的目的。UTF8Type是把column name轉換爲UTF8編碼來進行排序,LongType轉換成爲64位long型,TimeUUIDType是按照基於時間的UUID來排序。例如:
Column name按照LongType排序:
{name: 3, value: "jacky"},
{name: 123, value: "hellodba"},
{name: 976, value: "Cassandra"},
{name: 832416, value: "bigtable"}
Column name按照UTF8Type排序:
{name: 123, value: "hellodba"},
{name: 3, value: "jacky"},
{name: 832416, value: "bigtable"}
{name: 976, value: "Cassandra"}
下面我們看twitter的Schema:
<Keyspace Name="Twitter">
<ColumnFamily CompareWith="UTF8Type" Name="Statuses" />
<ColumnFamily CompareWith="UTF8Type" Name="StatusAudits" />
<ColumnFamily CompareWith="UTF8Type" Name="StatusRelationships"
CompareSubcolumnsWith="TimeUUIDType" ColumnType="Super" />
<ColumnFamily CompareWith="UTF8Type" Name="Users" />
<ColumnFamily CompareWith="UTF8Type" Name="UserRelationships"
CompareSubcolumnsWith="TimeUUIDType" ColumnType="Super" />
</Keyspace>
我們看到一個叫Twitter的keyspace,包含若干個CF,其中StatusRelationships和 UserRelationships被定義爲包含Super column的CF,CompareWith定義了column的排序規則,CompareSubcolumnsWith定義了subcolumn的排序 規則,這裏使用了兩種:TimeUUIDType和UTF8Type。我們沒有看到任何有關column的定義,這意味着column是可以靈活變更的。
爲了方便大家理解,我會嘗試着用關係型數據庫的建模方法去描述Twitter的Schema,但千萬不要誤認爲這就是Cassandra的數據模型,對於Cassandra來說,每一行的colunn都可以是任意的,而不是象數據庫一樣需要在建表時就創建好。

Users CF記錄用戶的信息,Statuses CF記錄tweets的內容,StatusRelationships CF記錄用戶看到的tweets,UserRelationships CF記錄用戶看到的followers。我們注意到排序方式是TimeUUIDType,這個類型是按照時間進行排序的UUID字段,column name是用UUID函數產生(這個函數返回了一個UUID,這個UUID反映了當前的時間,可以根據這個UUID來排序,有點類似於timestamp 一樣),所以得到結果是按照時間來排序的。使用過twitter的人都知道,你總是可以看到自己最新的tweets或者最新的friends.
存儲
Cassandra是基於列存儲的(Bigtable也是一樣),這個和基於列的數據庫是一個道理。

API
下面是數據庫,Bigtable和Cassandra API的對比: Relational SELECT `column` FROM `database`.`table` WHERE `id` = key;
BigTable table.get(key, "column_family:column")
Cassandra: standard model keyspace.get("column_family", key, "column")
Cassandra: super column model keyspace.get("column_family", key, "super_column", "column")
我對Cassandra數據模型的理解:
1.column name存放真正的值,而value是空。因爲Cassandra是按照column name排序,而且是按列存儲的,所以往往利用column name存放真正的值,而value部分則是空。例如:“jacky”:“null”,“fenng”:”null”
2.Super column可以看作是一個索引,有點象關係型數據庫中的外鍵,利用super column可以實現快速定位,因爲它可以返回一堆column,而且是排好序的。
3.排序在定義時就確定了,取出的數據肯定是按照確定的順序排列的,這是一個巨大的性能優勢。
4. 非常靈活的schema,column可以靈活定義。實際上,colume name在很多情況下,就是value(是不是有點繞)。
5.每個column後面的timestamp,我並沒有找到明確的說明,我猜測可能是數據多版本,或者是底層清理數據時需要的信息。
最後說說架構,我認爲架構的核心就是有所取捨,不管是CAP還是BASE,講的都是這個原則。架構之美在於沒有任何一種架構可以完美的解決各種問題,數據庫和NoSQL都有其應用場景,我們要做的就是爲自己找到合適的架構。
Hypertable
Hypertable: (can you help?) Open-Source Google BigTable alike.
它是搜索引擎公司Zvents根據Google的9位研究人員在2006年發表的一篇論文《Bigtable:結構化數據的分佈存儲系統》 開發的一款開源分佈式數據儲存系統。Hypertable是按照1000節點比例設計,以 C++撰寫,可架在 HDFS 和 KFS 上。儘管還在初期階段,但已有不錯的效能:寫入 28M 列的資料,各節點寫入速率可達7MB/s,讀取速率可達 1M cells/s。Hypertable目前一直沒有太多高負載和大存儲的應用實例,但是最近,Hypertable項目得到了百度的贊助支持,相信其會有更好的發展。
Google之BigTable
研究Google的產品總是感激Google給了自己那麼多方便,真心喜歡之。

AppEngine Datastore所支持的項目的數據類型要比SimpleDB豐富得多,也包括了包含在一個項目內的數據集合的列表型。
如果你打算在Google AppEngine之內建造應用的話,幾乎可以肯定要用到這個數據存儲。然而,不像SimpleDB,使用谷歌網絡服務平臺之外的應用,你並不能併發地與AppEngine Datastore進行接口 (或通過BigTable)。
Yahoo之PNUTS
特點
PNUTS實現
Record-level mastering 記錄級別主節點
每一條記錄都有一個主記錄。比如一個印度的用戶保存的記錄master在印度機房,通常修改都會調用印度。其他地方如美國用戶看這個用戶的資料調用 的是美國數據中心的資料,有可能取到的是舊版的數據。非master機房也可對記錄進行修改,但需要master來統一管理。每行數據都有自己的版本控 制,如下圖所示。
PNUTS的結構

每個數據中心的PNUTS結構由四部分構成
Storage Units (SU) 存儲單元
物理的存儲服務器,每個存儲服務器上面含有多個tablets,tablets是PNUTS上的基本存儲單元。一 個tablets是一個yahoo內部格式的hash table的文件(hash table)或是一個MySQL innodb表(ordered table)。一個Tablet通常爲幾百M。一個SU上通常會存在幾百個tablets。
Routers
每個tablets在哪個SU上是通過查詢router獲得。一個數據中心內router通常可由兩臺雙機備份的單元提供。
Tablet Controller
router的位置只是個內存快照,實際的位置由Tablet Controller單元決定。
Message Broker
與遠程數據的同步是由YMB提供,它是一個pub/sub的異步消息訂閱系統。
Tablets尋址與切分
存儲分hash和ordered data store。
以hash爲例介紹,先對所有的tablets按hash值分片,比如1-10,000屬於tablets 1, 10,000到20,000屬於tablets 2,依此類推分配完所有的hash範圍。一個大型的IDC通常會存在100萬以下的tablets, 1,000臺左右的SU。tablets屬於哪個SU由routers全部加載到內存裏面,因此router訪問速度極快,通常不會成爲瓶頸。按照官方的 說法,系統的瓶頸只存在磁盤文件hash file訪問上。
當某個SU訪問量過大,則可將SU中部分tablets移到相對空閒的SU,並修改tablet controller的偏移記錄。router定位tablet失效之後會自動通過tablet controller重新加載到內存。所以切分也相對容易實現。
Tim也曾經用MySQL實現過類似大規模存儲的系統,當時的做法是把每條記錄的key屬於哪個SU的信息保存到 一個字典裏面,好處是切分可以獲得更大的靈活性,可以動態增加新的tablets,而不需要切分舊的tablets。但缺點就是字典沒法像router這 樣,可以高效的全部加載到內存中。所以比較而言,在實際的應用中,按段分片會更簡單,且已經足夠使用。Write調用示意圖

PNUTS感悟
2006年Greg Linden就說I want a big, virtual database
What I want is a robust, high performance virtual relational database that runs transparently over a cluster, nodes dropping in an out of service at will, read-write replication and data migration all done automatically.
I want to be able to install a database on a server cloud and use it like it was all running on one machine.
詳細資料:
http://timyang.net/architecture/yahoo-pnuts/微軟之SQL數據服務
微軟看起來不同於前三個供應商,因爲雖然鍵/值存儲對於可擴性???言非常棒,相對於RDBMS,在數據管理上卻很困難。微軟的方案似乎是入木三分,在實現可擴性和分佈機制的同時,隨着時間的推移,不斷增加特性,在鍵/值存儲和關係數據庫平臺的鴻溝之間搭起一座橋樑。 非雲服務競爭者
文檔存儲
CouchDB
Links: 3 CouchDB books ?, Couch Lounge ? (partitioning / clusering), ...
它是Apache社區基於 Erlang/OTP 構建的高性能、分佈式容錯非關係型數據庫系統(NRDBMS)。它充分利用 Erlang 本身所提供的高併發、分佈式容錯基礎平臺,並且參考 Lotus Notes 數據庫實現,採用簡單的文檔數據類型(document-oriented)。在其內部,文檔數據均以 JSON 格式存儲。對外,則通過基於 HTTP 的 REST 協議實現接口,可以用十幾種語言進行自由操作。
CouchDB一種半結構化面向文檔的???布式,高容錯的數據庫系統,其提供RESTFul HTTP/JSON接口。其擁有MVCC特性,用戶可以通過自定義Map/Reduce函數生成對應的View。
在CouchDB中,數據是以JSON字符的方式存儲在文件中。特性
詳細參見:
http://www.javaeye.com/topic/319839Riak
MongoDB
MongoDB是一個介於關係數據庫和非關係數據庫之間的產品,是非關係數據庫當中功能最豐富,最像關係數據庫的。他支持的數據結構非常鬆散,是 類似json的bjson格式,因此可以存儲比較複雜的數據類型。Mongo最大的特點是他支持的查詢語言非常強大,其語法有點類似於面向對象的查詢語 言,幾乎可以實現類似關係數據庫單表查詢的絕大部分功能,而且還支持對數據建立索引。
Mongo主要解決的是海量數據的訪問效率問題,根據官方的文檔,當數據量達到50GB以上的時候,Mongo的數據庫訪問速度是MySQL的 10倍以上。Mongo的併發讀寫效率不是特別出色,根據官方提供的性能測試表明,大約每秒可以處理0.5萬-1.5次讀寫請求。對於Mongo的併發讀 寫性能,我(robbin)也打算有空的時候好好測試一下。
因爲Mongo主要是支持海量數據存儲的,所以Mongo還自帶了一個出色的分佈式文件系統GridFS,可以支持海量的數據存儲,但我也看到有些評論認爲GridFS性能不佳,這一點還是有待親自做點測試來驗證了。
最後由於Mongo可以支持複雜的數據結構,而且帶有強大的數據查詢功能,因此非常受到歡迎,很多項目都考慮用MongoDB來替代MySQL來實現不是特別複雜的Web應用,比方說why we migrated from MySQL to MongoDB就是一個真實的從MySQL遷移到MongoDB的案例,由於數據量實在太大,所以遷移到了Mongo上面,數據查詢的速度得到了非常顯著的提升。
MongoDB也有一個ruby的項目MongoMapper,是模仿Merb的DataMapper編寫的MongoDB的接口,使用起來非常簡單,幾乎和DataMapper一模一樣,功能非常強大易用。 Terrastore
Terrastore: API: Java & http, Protocol: http, Language: Java, Querying: Range queries, Predicates, Replication: Partitioned with consistent hashing, Consistency: Per-record strict consistency, Misc: Based on TerracottaThruDB
Key Value / Tuple 存儲
Amazon之SimpleDB
SimpleDB 是一個亞馬遜網絡服務平臺的一個面向屬性的鍵/值數據庫。SimpleDB仍處於公衆測試階段;當前,用戶能在線註冊其“免費”版 --免費的意思是說直到超出使用限制爲止。
SimpleDB有幾方面的限制。首先,一次查詢最多隻能執行5秒鐘。其次,除了字符串類型,別無其它數據類型。一切都以字符串形式被存儲、獲取和 比較,因此除非你把所有日期都轉爲ISO8601,否則日期比較將不起作用。第三,任何字符串長度都不能超過1024字節,這限制了你在一個屬性中能存儲 的文本的大小(比如說產品描述等)。不過,由於該模式動態靈活,你可以通過追加“產品描述1”、“產品描述2”等來繞過這類限制。一個項目最多可以有 256個屬性。由於處在測試階段,SimpleDB的域不能大於10GB,整個庫容量則不能超過1TB。
SimpleDB的一項關鍵特性是它使用一種最終一致性模型。 這個一致性模型對併發性很有好處,但意味着在你改變了項目屬性之後,那些改變有可能不能立即反映到隨後的讀操作上。儘管這種情況實際發生的機率很低,你也 得有所考慮。比如說,在你的演出訂票系統裏,你不會想把最後一張音樂會門票賣給5個人,因爲在售出時你的數據是不一致的。Chordless
Chordless: API: Java & simple RPC to vals, Protocol: internal, Query Method: M/R inside value objects, Scaling: every node is master for its slice of namespace, Written in: Java, Concurrency: serializable transaction isolation, Links:Redis
Redis是一個很新的項目,剛剛發佈了1.0版本。Redis本質上是一個Key-Value類型的內存數據庫,很像memcached,整個數據庫統 統加載在內存當中進行操作,定期通過異步操作把數據庫數據flush到硬盤上進行保存。因爲是純內存操作,Redis的性能非常出色,每秒可以處理超過 10萬次讀寫操作,是我知道的性能最快的Key-Value DB。
Redis的出色之處不僅僅是性能,Redis最大的魅力是支持保存List鏈表和Set集合的數據結構,而且還支持對List進行各種操作,例 如從List兩端push和pop數據,取List區間,排序等等,對Set支持各種集合的並集交集操作,此外單個value的最大限制是1GB,不像 memcached只能保存1MB的數據,因此Redis可以用來實現很多有用的功能,比方說用他的List來做FIFO雙向鏈表,實現一個輕量級的高性 能消息隊列服務,用他的Set可以做高性能的tag系統等等。另外Redis也可以對存入的Key-Value設置expire時間,因此也可以被當作一 個功能加強版的memcached來用。
Redis的主要缺點是數據庫容量受到物理內存的限制,不能用作海量數據的高性能讀寫,並且它沒有原生的可擴展機制,不具有scale(可擴展) 能力,要依賴客戶端來實現分佈式讀寫,因此Redis適合的場景主要侷限在較小數據量的高性能操作和運算上。目前使用Redis的網站有 github,Engine Yard。 Scalaris
Tokyo cabinet / Tyrant
Tokyo Cabinet / Tyrant: Links: nice talk ?, slides ?, Misc: Kyoto Cabinet ?
它是日本最大的SNS社交網站mixi.jp開發的 Tokyo Cabinet key-value數據庫網絡接口。它擁有Memcached兼容協議,也可以通過HTTP協議進行數據交換。對任何原有Memcached客戶端來講, 可以將Tokyo Tyrant看成是一個Memcached,但是,它的數據是可以持久存儲的。Tokyo Tyrant 具有故障轉移、日誌文件體積小、大數據量下表現出色等優勢,詳見:http://blog.s135.com/post/362.htm
Tokyo Cabinet 2009年1月18日發佈的新版本(Version 1.4.0)已經實現 Table Database,將key-value數據庫又擴展了一步,有了MySQL等關係型數據庫的表和字段的概念,相信不久的將來,Tokyo Tyrant 也將支持這一功能。值得期待。
TC除了支持Key-Value存儲之外,還支持保存Hashtable數據類型,因此很像一個簡單的數據庫表,並且還支持基於column的條 件查詢,分頁查詢和排序功能,基本上相當於支持單表的基礎查詢功能了,所以可以簡單的替代關係數據庫的很多操作,這也是TC受到大家歡迎的主要原因之一, 有一個Ruby的項目miyazakiresistance將TT的hashtable的操作封裝成和ActiveRecord一樣的操作,用起來非常爽。
TC/TT在mixi的實際應用當中,存儲了2000萬條以上的數據,同時支撐了上萬個併發連接,是一個久經考驗的項目。TC在保證了極高的併發 讀寫性能的同時,具有可靠的數據持久化機制,同時還支持類似關係數據庫表結構的hashtable以及簡單的條件,分頁和排序操作,是一個很棒的 NoSQL數據庫。
TC的主要缺點是在數據量達到上億級別以後,併發寫數據性能會大幅度下降,NoSQL: If Only It Was That Easy提到,他們發現在TC裏面插入1.6億條2-20KB數據的時候,寫入性能開始急劇下降。看來是當數據量上億條的時候,TC性能開始大幅度下降,從TC作者自己提供的mixi數據來看,至少上千萬條數據量的時候還沒有遇到這麼明顯的寫入性能瓶頸。
這個是Tim Yang做的一個Memcached,Redis和Tokyo Tyrant的簡單的性能評測,僅供參考CT.M
Scalien
Berkley DB
MemcacheDB
它是新浪互動社區事業部爲在Memcached基礎上,增加Berkeley DB存儲層而開發一款支持高併發的分佈式持久存儲系統,對任何原有Memcached客戶端來講,它仍舊是個Memcached,但是,它的數據是可以持久存儲的。
Mnesia
LightCloud
HamsterDB
Flare
flare唯一的缺點就是他只支持memcached協議,因此當你使用flare的時候,就不能使用TC的table數據結構了,只能使用TC的key-value數據結構存儲。最終一致性Key Value存儲
Amazon之Dynamo
功能特色
架構特色

BeansDB
簡介
更新
特性
性能
Num of Records : 10000
Non-Blocking IO : 0
TCP No-Delay : 0
Successful [SET] : 10000
Failed [SET] : 0
Total Time [SET] : 0.45493s
Average Time [SET] : 0.00005s
Successful [GET] : 10000
Failed [GET] : 0
Total Time [GET] : 0.28609s
Average Time [GET] : 0.00003s
􀂄 get A:7900 n=151398, avg=8.89, med=5.94, 99%=115.5, 99.9%=310.2
􀂄 get B:7900 n=100054, avg=6.84, med=0.40, 99%=138.5, 99.9%=483.0
􀂄 get C:7900 n=151250, avg=7.42, med=5.34, 99%=55.2, 99.9%=156.7
􀂄 get D:7900 n=150677, avg=7.63, med=5.09, 99%=97.7, 99.9%=284.7
􀂄 get E:7900 n=3822, avg=3.07, med=0.18, 99%=44.3, 99.9%=170.0
􀂄 get F:7900 n=249973, avg=8.29, med=6.36, 99%=46.8, 99.9%=241.5
􀂄 set A:7900 n=10177, avg=18.53, med=12.78,99%=189.3, 99.9%=513.6
􀂄 set B:7900 n=10431, avg=12.85, med=1.19, 99%=206.1, 99.9%=796.8
􀂄 set C:7900 n=10556, avg=17.29, med=12.97,99%=132.2, 99.9%=322.9
􀂄 set D:7900 n=10164, avg=7.34, med=0.64, 99%=98.8, 99.9%=344.4
􀂄 set E:7900 n=10552, avg=7.18, med=2.33, 99%=73.6, 99.9%=204.8
􀂄 set F:7900 n=10337, avg=17.79, med=15.31, 99%=109.0, 99.9%=369.5
BeansDB設計實現(非常難得的中文資料)
PPTNuclear
詳見:
http://ugc.renren.com/2010/01/21/ugc-nuclear-guide-use/
http://ugc.renren.com/2010/01/28/ugc-nuclear-guide-theory/
兩個設計上的Tips
我們在編碼的過程中走了一些彎路,同步的操作在高併發的情況下帶來的性能下降是非常恐怖的,於是乎,Nuclear系統中任何的高併發操作都消除了Block。no waiting, no delay。
2. 根據系統負載控制後臺線程的資源佔用
Nuclear系統中有不少的後臺線程默默無聞的做着各種辛苦的工作,但是它們同樣會佔用系統資源,我們的解決方案是根據系統負載動態調整線程的運行和停止,並達到平衡。 Voldemort
Voldemort是個和Cassandra類似的面向解決scale問題的分佈式數據庫系統,Cassandra來自於Facebook這個 SNS網站,而Voldemort則來自於Linkedin這個SNS網站。說起來SNS網站爲我們貢獻了n多的NoSQL數據庫,例如 Cassandar,Voldemort,Tokyo Cabinet,Flare等等。Voldemort的資料不是很多,因此我沒有特別仔細去鑽研,Voldemort官方給出Voldemort的併發讀 寫性能也很不錯,每秒超過了1.5萬次讀寫。 
其實現在很多公司可能都面臨着這個抽象架構圖中的類似問題。以 Hadoop 作爲後端的計算集羣,計算得出來的數據如果要反向推到前面去,用什麼方式存儲更爲恰當? 再放到 DB 裏面的話,構建索引是麻煩事;放到 Memcached 之類的 Key-Value 分佈式系統中,畢竟只是在內存裏,數據又容易丟。Voldemort 算是一個不錯的改良方案。
值得借鑑的幾點:
詳細:
http://www.dbanotes.net/arch/voldemort_key-value.html
http://project-voldemort.com/blog/2009/06/building-a-1-tb-data-cycle-at-linkedin-with-hadoop-and-project-voldemort/Dynomite
Dynomite: (can you help)Kai
未分類
Skynet
2004年,Google提出用於分佈式數據處理的MapReduce設計模式,同時還提供了第一個C++的實現。現在,一個名爲Skynet的Ruby實現已經由Adam Pisoni發佈。
Skynet是可適配、可容錯的、可自我更新的,而且完全
是分佈式的系統,不存在單一的失敗節點。
Skynet和Google在設計上有兩點重要的區別:
Skynet無法向工作者(Worker)發送原生代碼(Raw code),
Skynet利用結對恢復系統,不同的工作者會互相監控以防失敗:
如果有一個工作者由於某種原因離開或者放棄了,就會有另一個工作者發現並接管它的任務。Skynet 也沒有所謂的“主”管理進程,只有工作者,它們在任何時間都可以充當任何任務的主管理進程。
Skynet的使用和設置都很容易,這也正是MapReduce這個概念的真正優勢。Skynet還擴展了ActiveRecord,加入了MapReduce的特性,比如distributed_find。
你要爲Starfish編寫一些小程序,它們的代碼是你將要構建其中的。如果我沒有弄錯的話,你無法在同一臺機器上運行多種類型的MapReduce作業。Skynet是一個更全面的MR系統,可以運行多種類型的多個作業,比如,各種不同的代碼。
Skynet也允許失敗。工作者會互相關照。如果一個工作者失敗了,無法及時完成任務,另一個工作者將會接起這個任務並嘗試完成它。Skynet也支持map_data流,也就是說,即使某個數據集非常龐大,甚至無法放在一個數據結構中,Skynet也可以處理。
什 麼是map_data流?大多數時候,在你準備啓動一個map_reduce作業時,必須提供一個數據的隊列,這些數據已經被分離並將被並行處理。如果隊 列過大,以至於無法適應於內存怎麼辦?在這種情況下,你就要不能再用隊列,而應該使用枚舉(Enumerable)。Skynet知道去對象的調 用:next或者:each方法,然後開始爲“每一個(each)”分離出map_task來。通過這樣的方式,不會有人再試圖同時創建大量的數據結構。
還 有很多特性值得一提,不過最想提醒大家的是,Skynet能夠與你現有的應用非常完美地集成到一起,其中自然包括Rails應用。Skynet甚 至還提供了一個ActiveRecord的擴展,你可以在模型中以分佈式的形式執行一些任務。在Geni中,我們使用這項功能來運行特別複雜的移植,它通 常涉及到在數百萬的模型上執行Ruby代碼。
> Model.distributed_find(:all, :conditions => "id > 20").each(:somemethod)在你運行Skynet的時候,它將在每個模型上執行:somemethod,不過是以分佈式的方式(這和你 擁有多少個工作者相關)。它在向模型分發任務前不必進行初始化,甚至不必提前獲取所有的id。因此它可以操作無限大的數據集。 用戶的反饋如何?Drizzle
比較
可擴展性

數據和查詢模型

當你需要查詢或更新一個值的一部分時,Key/value模型是最簡單有效實現。
面向文本數據庫是Key/value的下一步, 允許內嵌和Key關聯的值. 支持查詢這些值數據,這比簡單的每次返回整個blob類型數據要有效得多。
Neo4J是唯一的存儲對象和關係作爲數學圖論中的節點和邊. 對於這些類型數據的查詢,他們能夠比其他競爭者快1000s
Scalaris是唯一提供跨越多個key的分佈式事務。持久化設計

內存數據庫是非常快的,(Redis在單個機器上可以完成每秒100,000以上操作)但是數據集超過內存RAM大小就不行. 而且 Durability (服務器當機恢復數據)也是一個問題
Memtables和SSTables緩衝 buffer是在內存中寫(“memtable”), 寫之前先追加一個用於durability的日誌中.
但有足夠多寫入以後,這個memtable將被排序然後一次性作爲“sstable.”寫入磁盤中,這就提供了近似內存性能,因爲沒有磁盤的查詢seeks開銷, 同時又避免了純內存操作的durability問題.(個人點評 其實Java中的Terracotta早就實現這兩者結合)
B-Trees提供健壯的索引,但是性能很差,一般和其他緩存結合起來。應用篇
eBay 架構經驗
淘寶架構經驗
Flickr架構經驗
Twitter運維經驗
運維經驗
Metrics
根據圖表可以科學的制定系統容量規劃,而不是事後救火。 
配置管理
Darkmode
進程管理
硬件
代碼協同經驗
Review制度
部署管理
團隊溝通
Cache
雲計算架構

作者認爲,金字塔概念最能說明每一層的大小,它也表達了每 個層是依賴前層的消息傳遞。在概念上,硬件是基礎和廣泛層。SaaS層是頂峯,也是最輕層。這種觀點是來自於將購買SaaS的的最終用戶角度。對於一個非 常大的企業內部,PaaS平臺層將是頂峯。使用內部開發的軟件的內部各部門將實現他們的頂峯SaaS。還要注意:大小和層位置並不一定等同於重要性。硬件 層可能是最重要的,因爲它是所有超過一定點的商品。
硬件層The Hardware Layer
必須考慮容錯和冗餘,大部分人認爲沒有容錯硬件廉價商品。冗餘和容錯處理在軟件層內,硬件預計要失敗的,當然故障多電源容錯服務器,RAID磁盤陣列也是必要的。
虛擬層The Virtualization Layer
基於操作系統OS的虛擬化層,虛擬資源能夠在線即時增加拓展,允許供應商提供基礎設施作爲服務(SaaS),VMware,Citrix公司,Sun都提供虛擬化產品。
The IaaS Layer
提 供和控制的基於虛擬層的計算方式,終端用戶能夠精確控制每個虛擬機沒分鐘每小時耗費多少錢。比如提供一個共同的接口,如門戶網站暴露的API,允許最終用 戶創建和配置虛擬機模板的需求。最終用戶還可以控制何時打開或破壞虛擬機,以及如何在虛擬機互相聯網。在這個領域的主要競爭者例子是亞馬遜網絡服務的 EC2,S3和數據庫服務。
The PaaS Layer
這一層的目的是儘量減少部署雲的複雜性和麻煩,最終用戶 利用和開發的這層的API和編程語言。兩個很好的例子是谷歌的App Engine 和Force.com平臺,在App Engine中,谷歌公開雲存儲,平臺和數據庫,以及使用Python和Java編程語言的API。開發人員能夠編寫應用程序並部署到這一層中,後端可伸縮性架構設計完全交給谷歌負責,最終用戶完全不必擔心管理基礎設施。Force.com平臺類似,但採用了自定義的編程語言名爲Apex。如果你是一個大型企業尋求內部開發應用的部署,這層是你的頂峯。
The SaaS Layer
如 果您是中小型企業(SME)和大企業不希望開發自己的應用程序時,SaaS的層是你的頂峯(是你將直接面對的)。您只是進行有興趣地採購如電子郵件或客戶 關係管理服務,這些功能服務已經被供應商開發成功,並部署到雲環境中了,您只需驗證的應用是否符合你的使用需要,帳單可以基於包月租費等各種形式,,作爲 最終用戶的您不會產生開發和維護拓展應用程序軟件的任何成本。越來越多的企業訂閱Salesforce.com和Sugar CRM的SaaS產品。反模式
單點失敗(Single Point of Failure)
大部分的人都堅持在單一的設備上部署我們的應用,因爲這樣部署的費用會比較低,但是我們要清楚任何的硬件設備都會有失敗的風險的,這種單點失敗會嚴重的影響用戶體驗甚至是拖垮你的應用,因此除非你的應用能容忍失敗帶來的損失,否則得話應該儘量的避免單點風險,比如做冗餘,熱備等。同步調用
同步調用在任何軟件系統中都是不可避免的,但是我們軟件工程師必須明白同步調用給軟件系統帶來的問題。如果我們將應用程序串接起來,那麼系統的可用性就會低於任何一個單一組件的可用性。比如組件A同步調用了組件B,組件A的可用性爲99.9%,組件B的可用性爲99.9%,那麼組件A同步調用組件B的可用性就是99.9% * 99.9%=99.8%。同步調用使得系統的可用性受到了所有串接組件可用性的影響,因此我們在系統設計的時候應該清楚哪些地方應該同步調用,在不需要同步調用的時候儘量的進行異步的調用(而我這裏所說的異步是一種基於應用的異步,是一種設計上的異步,因爲J2EE目前的底層系統出了JMS是異步API以外,其它的API都是同步調用的,所以我們也就不能依賴於底層J2EE平臺給我們提供異步性,我們必須從應用和設計的角度引入異步性)不具備回滾能力
雖然對應用的每個版本進行回滾能力測試是非常耗時和昂貴的,但是我們應該清楚任何的業務操作都有可能失敗,那麼我們必須爲這種失敗作好準備,需要對系統的用戶負責,這就要求系統一定要具有回滾的能力,當失敗的時候能進行及時的回滾。(說到回滾大家可能第一時間想到的是事務的回滾,其實這裏的回滾應該是一種更寬泛意義的回滾,比如我們記錄每一次的失敗的業務操作,這樣在出現錯誤的時候就不是依靠於事務這種技術的手段,而是通過系統本身的回滾能力來進行回滾失敗業務操作)。不記錄日誌
日誌記錄對於一個成熟穩定的系統是非常重要的,如果我們不進行日誌記錄,那麼我就很難統計系統的行爲。無切分的數據庫
隨着系統規模的慢慢變大,我們就需要打破單一數據的限制,需要對其進行切分。無切分的應用
系統在規模小的時候,也許感覺不出無切分的應用帶來的問題,但是在目前互聯網高速發展的時代,誰能保證一個小應用在一夜或者是幾夜以後還是小應用呢?說不定哪天,我們就發現應用在突如其來的訪問量打擊的支離破碎。因此我們就需要讓我們的系統和我們一樣具有生命力,要想讓系統具有應付大負載的能力,這就要求我們的應用具有很好的伸縮性,這也就要求應用需要被良好的切分,只有進行了切分,我們才能對單一的部門進行伸縮,如果應用是一塊死板的話,我們是沒有辦法進行伸縮的。就好比火車一樣,如果火車設計之初就把他們設計爲一體的,那麼我們還怎麼對火車的車廂進行裁剪?因此一個沒有切分的應用是一個沒有伸縮性和沒有可用性的應用。將伸縮性依賴於第三方廠商
如果我們的應用系統的伸縮性依賴於第三方的廠商,比如依賴於數據庫集羣,那麼我們就爲系統的伸縮性埋下了一個定時炸彈。因爲只有我們自己最清楚我們自己的應用,我們應該從應用和設計的角度出發去伸縮我們的應用,而不是依賴於第三方廠商的特性。OLAP
聯機分析處理 (OLAP) 的概念最早是由關係數據庫之父E.F.Codd於1993年提出的,他同時提出了關於OLAP的12條準則。OLAP的提出引起了很大的反響,OLAP作爲一類產品同聯機事務處理 (OLTP) 明顯區分開來。OLAP報表產品最大的難點在哪裏?
說起來有點深奧,其實並不複雜,OLAP最基本的概念只有三個:多維觀察、數據鑽取、CUBE運算。
關於CUBE運算:OLAP分析所需的原始數據量是非常龐大的。一個分析模型,往往會涉及數百萬、數千萬條數據,甚至更多;而分析模型中包含多個維數據,這些維又可以由瀏覽者作任意的提取組合。這樣的結果就是大量的實時運算導致時間的延滯。
我們可以設想,一個1000萬條記錄的分析模型,如果一次提取4個維度進行組合分析,那麼實際的運算次數將 達到4的1000次方的數量。這樣的運算量將導致數十分鐘乃至更長的等待時間。如果用戶對維組合次序進行調整,或增加、或減少某些維度的話,又將是一個重 新的計算過程。
從上面的分析中,我們可以得出結論,如果不能解決OLAP運算效率問題的話,OLAP將是一個毫無實用價值的概念。那麼,一個成熟產品是如何解決這個問題的呢?這涉及到OLAP中一個非常重要的技術——數據CUBE預運算。
一個OLAP模型中,度量數據和維數據我們應該事先確定,一旦兩者確定下來,我們可以對數據進行預先的處理。在正式發佈之前,將數據根據維進行最大
限度的聚類運算,運算中會考慮到各種維組合情況,運算結果將生成一個數據CUBE,並保存在服務器上。
這樣,當最終用戶在調閱這個分析模型的時候,就可以直接使用這個CUBE,在此基礎上根據用戶的維選擇和維組合進行復運算,從而達到實時響應的效果。NOSQL們背後的共有原則
假設失效是必然發生的
對數據進行分區
保存同一數據的多個副本
動態伸縮
查詢支持
使用 Map/Reduce 處理匯聚
基於磁盤的和內存中的實現
然而,對於高吞吐量需求的應用,內存雲將更有競爭力。當 使用每次操作的成本和能量作爲衡量因素的時候,內存雲的效率是傳統硬盤系統的 100 到 1000 倍,是閃存系統的 5-10 倍。因此,對於高吞吐量需求的系統來說,內存雲不僅提供了高性能,也提供了高能源效率。同時,如果使用 DRAM 芯片提供的低功耗模式,也可以降低內存雲的功耗,特別是在系統空閒的時候。此外,內存雲還有一些缺點,一些內存雲無法支持需要將數據在 多個數據中心之間進行數據複製。對於這些環境,更新的時延將主要取決於數據中心間數據傳輸的時間消耗,這就喪失了內存雲的時延方面的優勢。此外,跨數據中 心的數據複製會讓內存雲數據一致性更能難保證。不過,內存雲仍然可以在誇數據中心的情況下提供低時延的讀訪問。 僅僅是炒作?
附
感謝
版本志
v0.2版本在2010.2.24發佈,因爲一些外界原因,提前發佈。完善各個示例,勘誤,翻譯部分內容。
v0.3版本將在3月份或之後發佈引用
http://queue.acm.org/detail.cfm?id=1413264
http://www.dbanotes.net/arch/five-minute_rule.html
http://www.infoq.com/cn/news/2009/09/Do-Not-Delete-Data
http://www.infoq.com/cn/news/2010/02/ec2-oversubscribed
http://timyang.net/architecture/consistent-hashing-practice
http://en.wikipedia.org/wiki/Gossip_protocol
http://horicky.blogspot.com/2009/11/nosql-patterns.html
http://snarfed.org/space/transactions_across_datacenters_io.html
http://research.microsoft.com/en-us/um/people/lamport/pubs/lamport-paxos.pdf
http://en.wikipedia.org/wiki/Distributed_hash_table
http://hi.baidu.com/knuthocean/blog/item/cca1e711221dcfcca6ef3f1d.html
http://zh.wikipedia.org/wiki/MapReduce
http://labs.google.com/papers/mapreduce.html
http://nosql-database.org/
http://www.rackspacecloud.com/blog/2009/11/09/nosql-ecosystem/
http://www.infoq.com/cn/news/2008/02/ruby-mapreduce-skynet
http://s3.amazonaws.com/AllThingsDistributed/sosp/amazon-dynamo-sosp2007.pdf
http://labs.google.com/papers/bigtable.html
http://www.allthingsdistributed.com/2008/12/eventually_consistent.html
http://www.rackspacecloud.com/blog/2009/11/09/nosql-ecosystem/
http://timyang.net/tech/twitter-operations/
http://blog.s135.com/read.php?394
http://www.programmer.com.cn/1760/
{kind=link}