




1.簡單介紹Transformer
Transformer是一種使用Attention機制類提升模型訓練的速度的模型,該模型的最大優勢在於其並行性良好,是一個非時序深度的encoder block加decoder block模型,可以用來代替seq2seq進行長距離的依賴建模。
Transformer詳解推薦這篇文章:https://jalammar.github.io/illustrated-transformer/
2.Encoder-Decoder框架
我們先來看看Encoder-Decoder框架。現階段的深度學習模型,我們通常都將其看作黑箱,而Encoder-Decoder框架則是將這個黑箱分爲兩個部分,一部分做編碼,另一部分做解碼。

在不同的NLP任務中,Encoder框架及Decoder框架均是由多個單獨的特徵提取器堆疊而成,比如說我們之前提到的LSTM結構或CNN結構。由最初的one-hot向量通過Encoder框架,我們將得到一個矩陣(或是一個向量),這就可以看作其對輸入序列的一個編碼。而對於Decoder結構就比較靈活餓了,我們可以根據任務的不同,對我們得到的“特徵”矩陣或“特徵”向量進行解碼,輸出爲我們任務需要的輸出結果。因此,對於不同的任務,如果我們堆疊的特徵抽取器能夠提取到更好的特徵,那麼理論上來說,在所有的NLP任務中我們都能夠得到更好的表現。
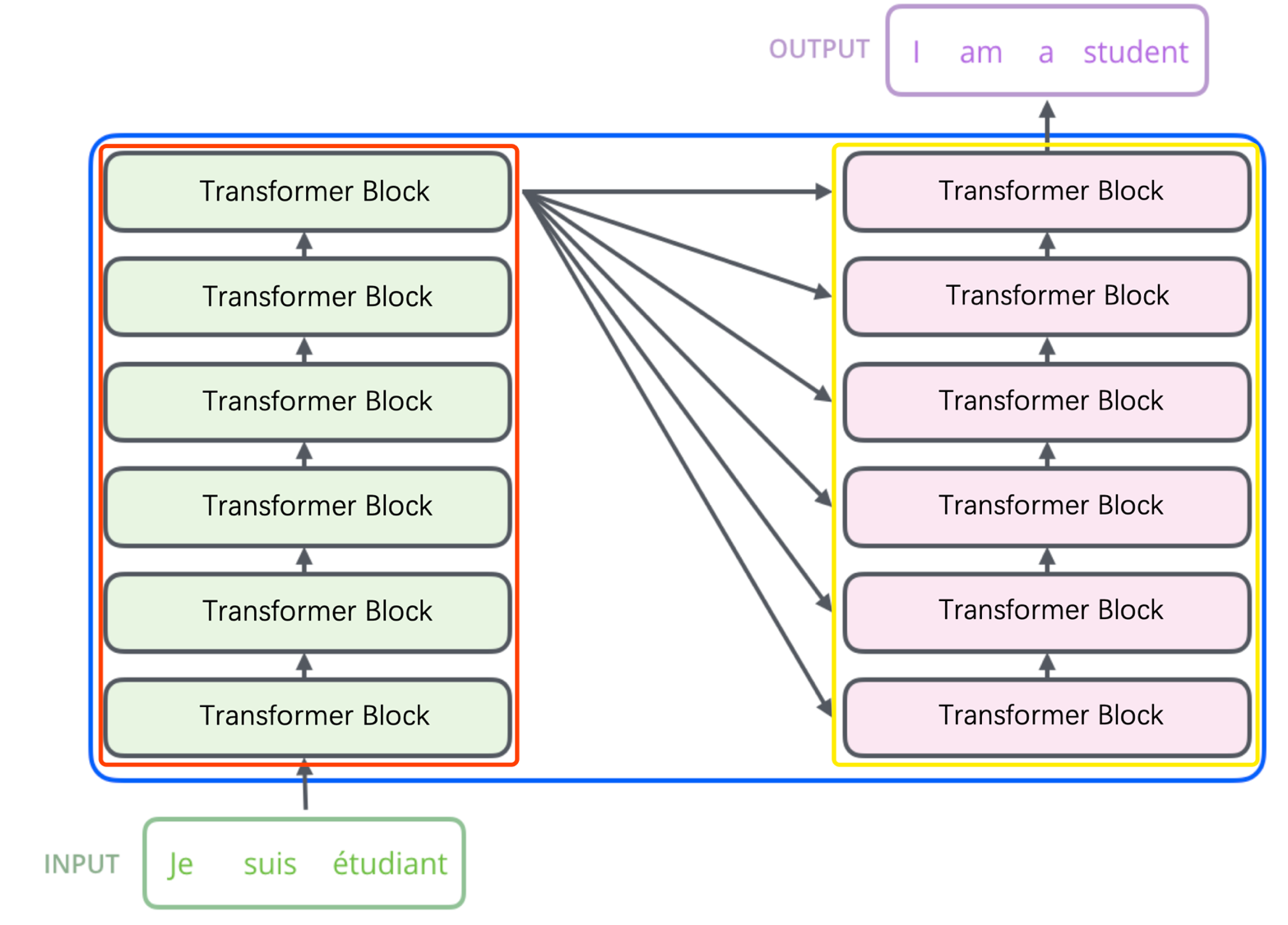
Transformer結構是在論文《Attention is All You Need》中提出的的模型,如上圖所示。圖中紅框內爲Encoder框架,黃框內爲Decoder框架,其均是由多個Transformer Block堆疊而成的。這裏的Transformer Block就代替了我們之前提到的LSTM和CNN結構作爲了我們的特徵提取器,也是其最關鍵的部分。更詳細的示意圖如下圖所示。我們可以發現,編碼器中的Transformer與解碼器中的Transformer是有略微區別的,但我們通常使用的特徵提取結構(包括Bert)主要是Encoder中的Transformer,那麼我們這裏主要理解一下Transformer在Encoder中是怎麼工作的。
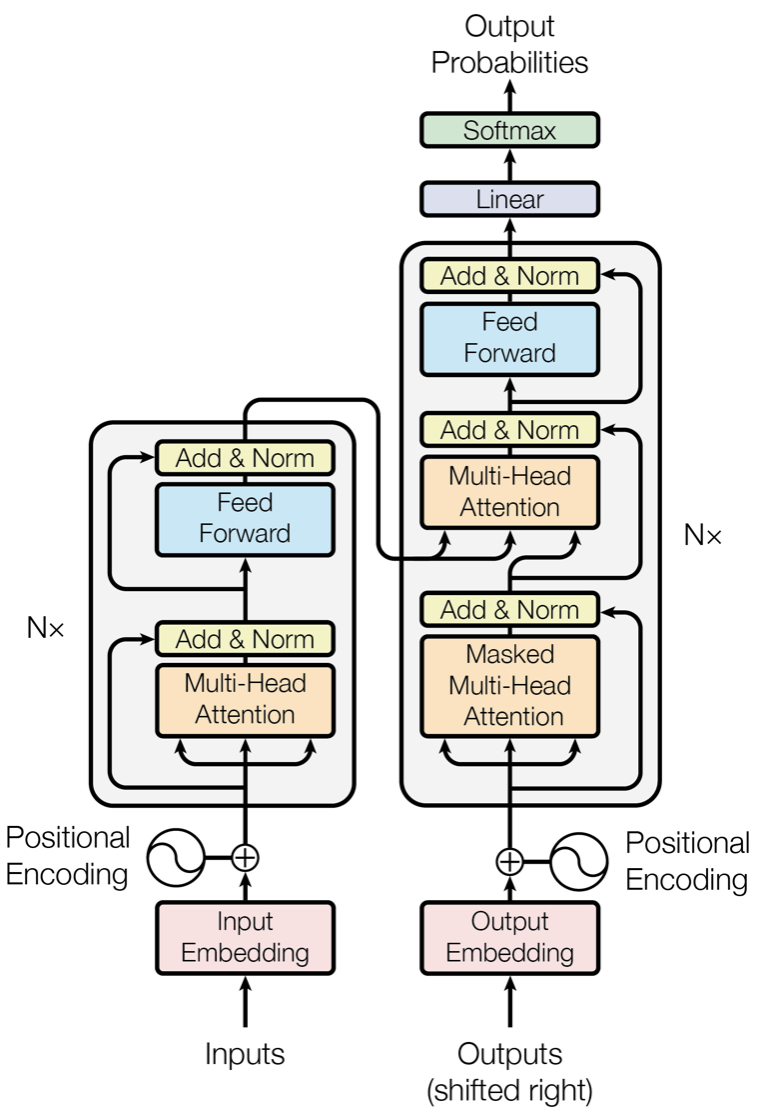
由上圖可知,單個的Transformer Block主要由兩部分組成:多頭注意力機制(Multi-Head Attention)和前饋神經網絡(Feed Forward)。
3.多頭注意力機制(Multi-Head Attention)
Multi-Head Attention模塊結構如下圖所示:
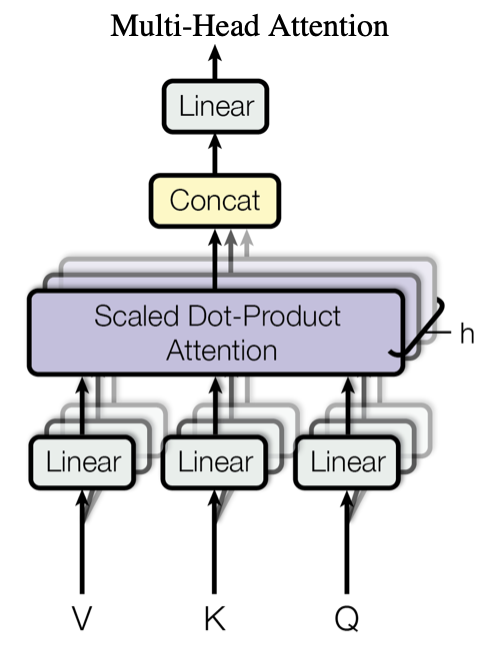
這裏,我們就可以明白爲什麼這一部分被稱爲Multi-Head了,因爲其本身就是由hh個子模塊Scaled Dot-Product Attention堆疊而成的,該模塊也被稱爲Self-Attention模塊。
在Multi-Head Attention中,最關鍵的部分就是Self-Attention部分了,這也是整個模型的核心配方,我們將其展開,如下圖所示。
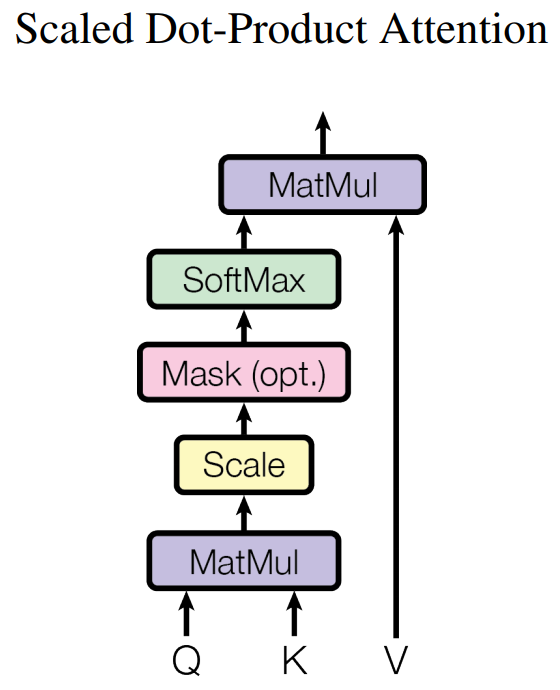
我們之前已經提到過,Self-Attention的輸入僅僅是矩陣X的三個線性映射。那麼Self-Attention內部的運算具有什麼樣的含義呢?我們從單個詞編碼的過程慢慢理解:
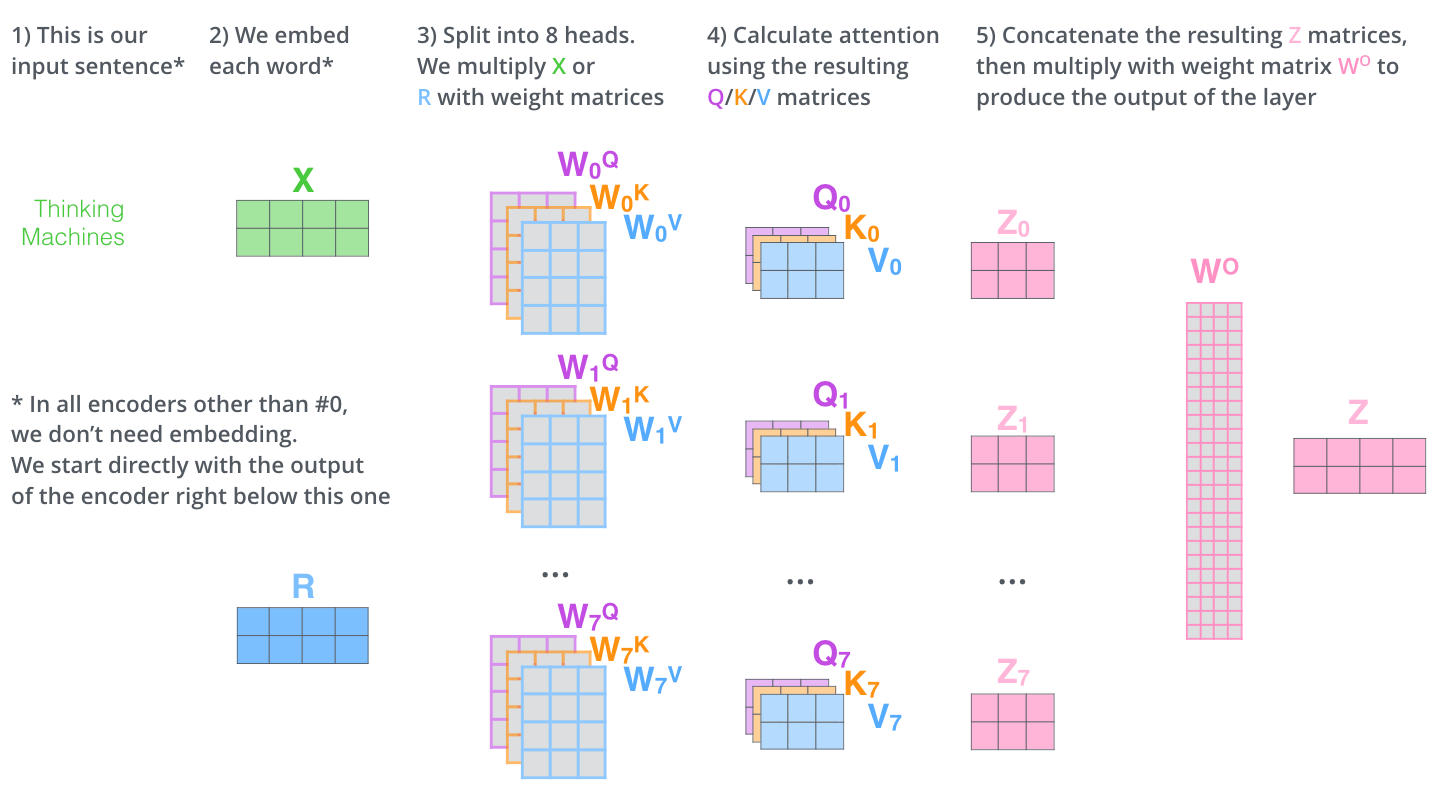
- 首先,我們對於輸入單詞向量X生成三個對應的向量: Query, Key 和 Value。注意這三個向量相比於向量X要小的多(論文中X的長度是512,三個向量的長度爲64,這只是一種基於架構上的選擇,因爲論文中的Multi-Head Attention有8個Self-Attention模塊,8個Self-Attention的輸出要拼接,將其恢復成長度爲512的向量),這一個部分是對每個單詞獨立操作的
- 用Queries和Keys的點積計算所有單詞相對於當前詞(圖中爲Thinking)的得分Score,該分數決定在編碼單詞“Thinking”時其他單詞給予了多少貢獻
- 將Score除以向量維度(64)的平方根(保證Score在一個較小的範圍,否則softmax的結果非零即1了),再對其進行Softmax(將所有單詞的分數進行歸一化,使得所有單詞爲正值且和爲1)。這樣對於每個單詞都會獲得所有單詞對該單詞編碼的貢獻分數,當然當前單詞將獲得最大分數,但也將會關注其他單詞的貢獻大小
- 對於得到的Softmax分數,我們將其乘以每一個對應的Value向量
- 對所得的所有加權向量求和,即得到Self-Attention對於當前詞”Thinking“的輸出
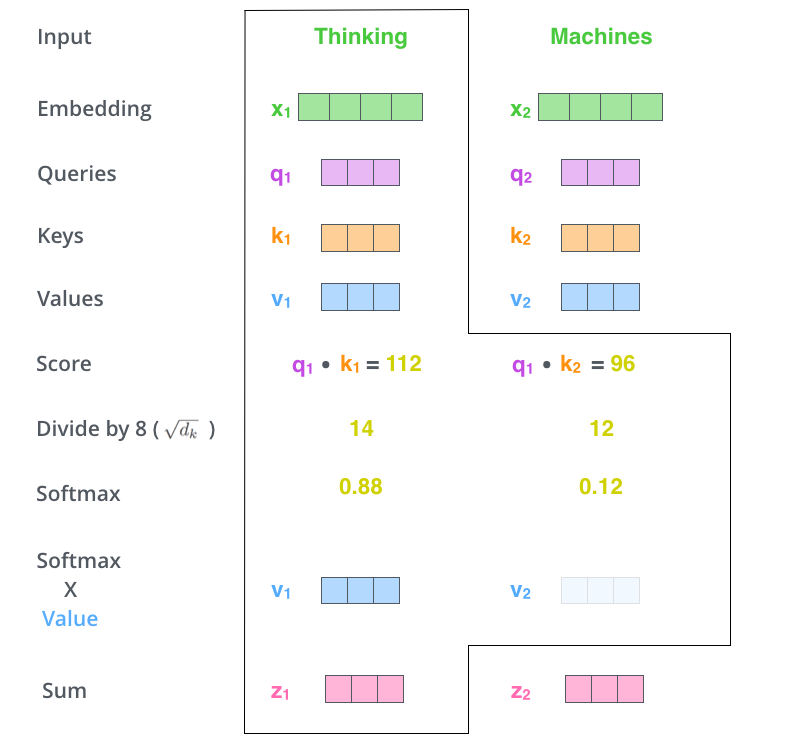
顯然,上述過程可以用以下的矩陣形式進行並行計算:

其中,Q, V, K分別表示輸入句子的Queries, Keys, Values矩陣,矩陣的每一行爲每一個詞對應的向量Query, Key, Value向量,dkdk表示向量長度。因此,Transformer同樣也具有十分高效的並行計算能力。
我們再回到Multi-Head Attention,我們將獨立維護的8個Self-Attention的輸出進行簡單的拼接,通過一個線性映射層,就得到了單個多頭注意力的輸出。其整個過程可以總結爲下面這個示意圖:
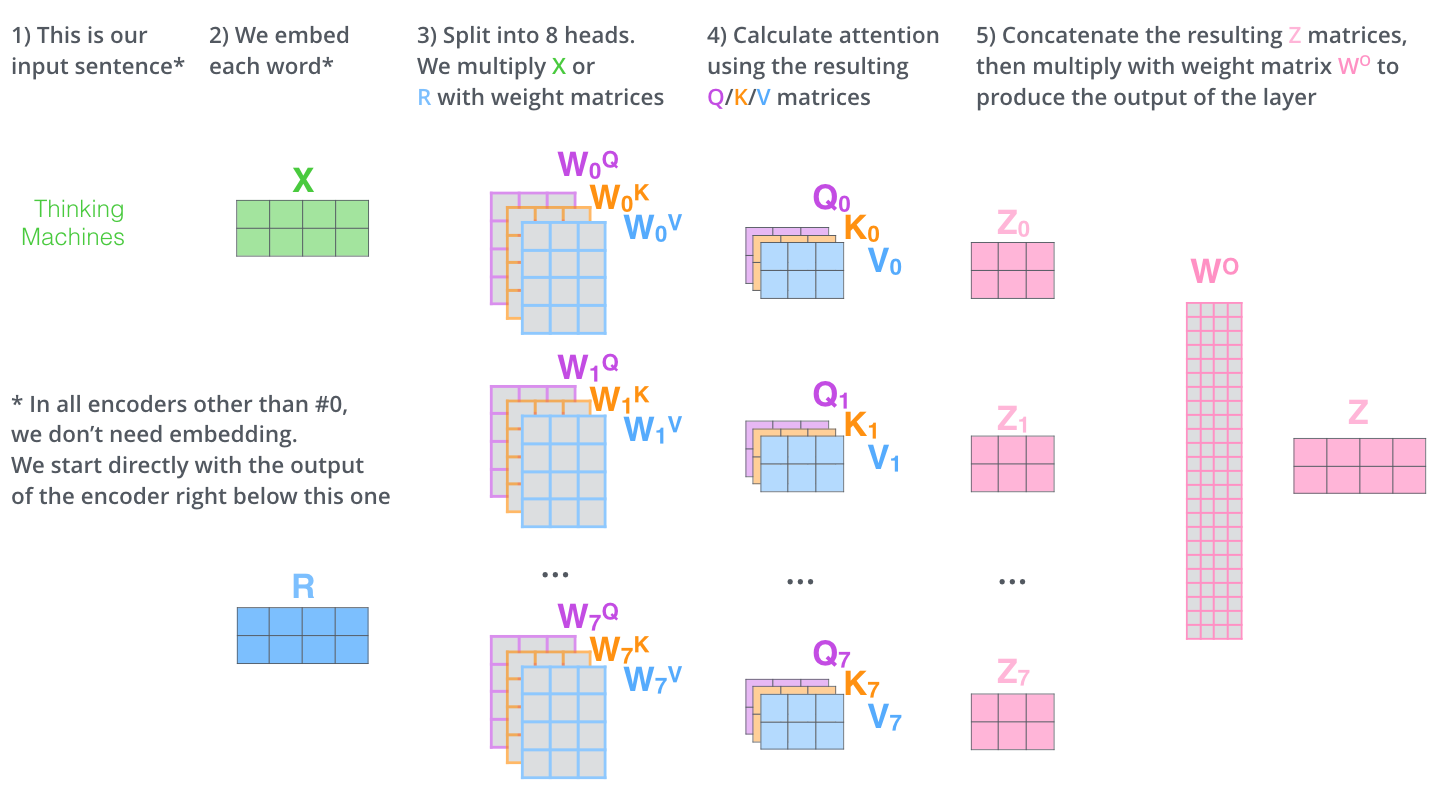
4.位置編碼(Positional Encoding)
我們之前提到過,由於RNN的時序性結構,所以天然就具備位置編碼信息。CNN本身其實也能提取一定位置信息,但多層疊加之後,位置信息將減弱,位置編碼可以看作是一種輔助手段。Transformer的每一個詞的編碼過程使得其基本不具備任何的位置信息(將詞序打亂之後並不會改變Self-Attention的計算結果),因此位置向量在這裏是必須的,使其能夠更好的表達詞與詞之間的距離。構造位置編碼的公式如下所示:

5.Transformer小結
- 從語義特徵提取能力:Transformer顯著超過RNN和CNN,RNN和CNN兩者能力差不太多。
- 長距離特徵捕獲能力:CNN極爲顯著地弱於RNN和Transformer,Transformer微弱優於RNN模型,但在比較遠的距離上(主語謂語距離大於13),RNN微弱優於Transformer,所以綜合看,可以認爲Transformer和RNN在這方面能力差不太多,而CNN則顯著弱於前兩者。這部分我們之前也提到過,CNN提取長距離特徵的能力收到其卷積核感受野的限制,實驗證明,增大卷積核的尺寸,增加網絡深度,可以增加CNN的長距離特徵捕獲能力。而對於Transformer來說,其長距離特徵捕獲能力主要受到Multi-Head數量的影響,Multi-Head的數量越多,Transformer的長距離特徵捕獲能力越強
- 任務綜合特徵抽取能力:通常,機器翻譯任務是對NLP各項處理能力綜合要求最高的任務之一,要想獲得高質量的翻譯結果,對於兩種語言的詞法,句法,語義,上下文處理能力,長距離特徵捕獲等方面的性能要求都是很高的。從綜合特徵抽取能力角度衡量,Transformer顯著強於RNN和CNN,而RNN和CNN的表現差不太多。
- 並行計算能力:對於並行計算能力,上文很多地方都提到過,並行計算是RNN的嚴重缺陷,而Transformer和CNN差不多。