




事件驅動是一種靈活的系統設計方法,在事件驅動的系統中,當數據發生變化時系統會產生、發佈一個對應的事件,其它對這個事件感興趣的部分會接收到通知,並進行相應的處理。事件驅動設計最大的好處在我看來有兩點:一是它爲系統提供了很好的擴展能力,比如我們可以對某類事件增加一個訂閱者來對系統進行擴展,最主要的是我們並不需要修改任何已有的代碼,它完全符合開閉原則;二是它實現了模塊間的低偶合,系統間各個部分不是強依賴關係,而是通過事件把整個系統串聯起來。
當然,任何事務都有兩面性,事件驅動也有其不好的方面。首先,實現一套這樣的系統複雜度就很高,對開發人員的要求也很高;再次,對系統的整體把控會很困難,想象一下面對幾百個類別的事件,並且沒有一個統一的地方可以讓我們看到整個業務處理流程,會是什麼心情?所以當我們決定採用事件驅動實現系統中,一定要維護好相關的文檔,並保持它們的有效性。
我們再來看看事件驅動架構的一些其它的優點:
更好的響應性
事件驅動中,事件的響應是異步處理的,所以它具有更好的響應性。
更好的容錯性
業務主流程在發佈事件之後便結束了,擴展流程的延後處理可以異步不斷的失敗重試,直到成功爲止,系統整體容錯性更強。
設計篇
首先,我們需要定義什麼是事件?從業務角度看,事件包括以下屬性:
事件的定義屬性字段類型說明標識IDstring系統內部每個事件都需要一個唯一的標識。類型eventTypestring數據發生變化產生事件,不同類型的數據變化產生不同類型的事件。比如會員下單、會員註冊、用戶修改手機號等等。時間eventTimedatetime即數據發生變化的時間。上下文contextstring事件發生時的上下文信息。比如會員修改手機號事件,需要原號碼和新號碼,會員 ID 等信息。
接下來,我們看看如何設計一套基於事件驅動的系統,你知道設計模式中的觀察者模式嗎?
觀察者模式 :定義了一種一對多的依賴關係,讓多個觀察者對象同時監聽某一個主題對象。這個主題對象在狀態發生變化時,會通知所有觀察者對象,使它們能夠自動更新自己。觀察者模式 :定義了一種一對多的依賴關係,讓多個觀察者對象同時監聽某一個主題對象。這個主題對象在狀態發生變化時,會通知所有觀察者對象,使它們能夠自動更新自己。
觀察者模式天生就是事件驅動的一個實現,但是直接使用它有很多的弊端。首先,它是基於主題的,有多少類事件就需要多少個主題類,這可能會導致類爆炸;其次,觀察者模式是同步實現的,這樣我們可能會犧牲掉響應性和容錯性等優勢。
所以我們需要對觀察者模式稍作改進,我們分別從事件發發布和消費兩個方面來分析。
事件的發佈
本文的標題是《基於 Kafka 實現事件驅動架構》,很明顯,我們使用 kafka 作爲消息中間件來傳遞事件消息。所以,像修改會員手機號碼的代碼可能實現如下:
@Transactional(readOnly =false, isolation = Isolation.READ_COMMITTED, rollbackFor = Exception.class)br/>@Override
publicvoidchangePhoneNumber(String newNumber){
userDao.updatePhone(this.getUserId(), newNumber);// 本地數據庫修改
// 發佈 用戶手機號碼變更 事件
Event event =newEvent(...);// 創建一個事件對象,表示用戶修改手機號碼
ProducerRecord record =newProducerRecord(...event);// 根據 event 生成 kakfa record
Future<RecordMetadata> f = kafkaProducer.send(record);
try{
f.get();
}catch(InterruptedException | ExecutionException e) {
thrownewRuntimeException(e);
}
}
這段代碼正確嗎?從邏輯上看,它完全正確。但從可靠性角度看它是有問題的。Kafka 和數據庫是兩個異構系統,我們不能僅僅通過一個本地事務保證他們之間的數據一致性。例如,推送 Kafka 成功了,但是在提交 DB 事務的時候失敗了呢(比如說事務超時滾)?這樣 kafka 中就會存在一個髒數據,因爲本地數據庫事務已經回滾了。
分佈式系統數據一致性一直就是複雜的問題,常用的方案有兩階段提交、三階段提交、zookeeper 的 zab 協議、proxs、raft 等算法,這不是本文的重點。我們採用一個簡單易懂的方式來解決上面的問題。我們引入一張 DB 事件表,在發佈事件時將事件信息存入這個事件表,將事件的發佈和業務處理包裝在同一個本地事務中。
createtableifnotexistsevent_queue(idbigintnotnullauto_incrementcomment'主鍵',event_idchar(32)notnullcomment'事件 ID',event_typechar(12)notnullcomment'事件類型',event_timedatetimenotnullcomment'事件發生時間',contextmediumtextnotnullcomment'事件內容',
primarykey(id),
uniquekey(event_id)
)engine=innodbdefaultcharset=utf8comment='事件隊列表';
發佈事件,就是向這個事件表中增加一條記錄,修改會員手機號碼的代碼現在變成了:
@Transactional(readOnly =false, isolation = Isolation.READ_COMMITTED, rollbackFor = Exception.class)br/>@Override
publicvoidchangePhoneNumber(String newNumber){
userDao.updatePhone(this.getUserId(), newNumber);// 本地數據庫修改
// 發佈 用戶手機號碼變更 事件
Event event =newEvent(...);// 創建一個事件對象,表示用戶修改手機號碼
eventDao.insert(event);// 向事件表創建一條新記錄。
}
由於事件消息現在被暫存進了 DB,我們還需要將它取出來推到 Kafka,爲此我們需要起一個線程,不斷的讀取事件表中的記錄發送給 Kafka,並在成功發送之後將記錄從 DB 中刪除。如果刪除 DB 的時候失敗了,那麼消息會被重新推送到 kafka,意爲着我們實現的是 At least once 的遞交語義,對於業務上不接受重複的場景,在消費端需要做好冪等處理。
講到這裏,關於事件的分佈已經接近尾聲,但還有一個問題: 性能 。如果一個系統的負載很高,一秒內產生成千上萬個事件,那我們的事件表就會成爲瓶頸,因爲只用了一個線程來處理事件表向 Kafka 的推送,集羣中只有一個實例能發輝作用,無法實現彈性。爲了解決這個問題,我們可以對事件表進行分表,並使用多線程併發處理,而且這些線程可以分佈在不同的集羣實例中。但這樣使設計變得更復雜了,現在我們需要解決一個新的問題: 如何保證一個事件表,最多隻被一個線程處理? 我們需要保證一個事件表同一時刻只能被一個線程處理,同時在實例宕機後,其它實例可以起線程接替它的工作。這句話我們換一種方式來描述更容易理解:
集羣有 M 個實例,需要進行 N 個任務(任務是把事件分表中的事件信息推送到 kafka)
一個任務最多可以分配給 1 個實例,1 個實例可以同時執行多個任務。
如果一個實例宕機了,分配給它的任務需要重新在其它實例上分配。
N 個任務固定不變,實例可以動態增加或減少,需要實現實例之間的均衡負載。
如果你熟悉像 HBase、ES 這類分佈式系統的話,不難理解我們需要在集羣中選出一個實例作爲 Master,由它來負責任務在集羣中的分配工作。我們藉助 Kookeeper,所有實例在啓動時創建一個 EPHEMERAL 類型的 master 節點,創建成功的實例成爲 Master,其它實例則監聽 master 節點,當 Master 實例宕機後重新競選。
每個實例啓動後,會在 workers 節點下創建一個臨時節點,表示自己作爲一個 Worker 加入集羣;Worker 同時會監聽自己創建的子節點,接收由 Master 分配給自己的任務。Master 會監聽 workers 下子節點的變化,當實例下線或有新的實例加入集羣中時,Master 會收到通知並重新進行任務的分配。分配的具體信息保存在 Worker 實例創建的子節點中,Master 通過直接修改這些子節點的內容實現分配。
從事件的發佈來看,系統的架構是這樣的:
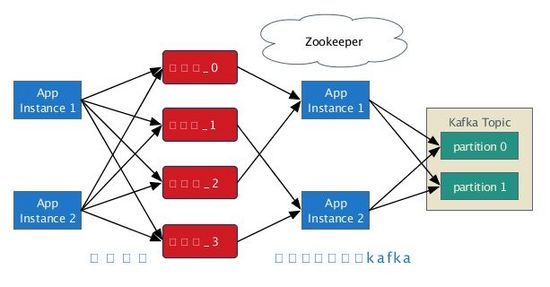
這裏有個細節需要說明: 因爲 Kafka 只保證 partition 級別的有序性,我們的事件分表數必須大於或等於 partition 的數量,否則事件的順序得不到保證 。
事件的消費
因爲我們使用了 Kafka 作爲事件消息中間件,事件的消費簡單很多。每個實例在啓動時啓一個 Kafka Consumer 即可,像實例間的負載、可用性、故障轉移等等問題,Kafka 已經幫我們解決了,我們只需要從 Kafka 中獲取事件消息,並通知相應的訂閱者即可。
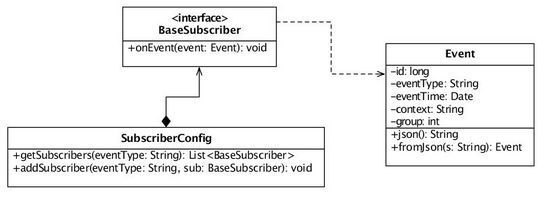
訂閱者需要實現 BaseSubscriber 接口,另外在啓動時,需要把事件與訂閱者的關係維護在 SubscriberConfig 類中:
BaseSubscriber sub = ...// your implementation
SubscriberConfig.instance().addSubscriber("event_type", sub);
系統整體的設計是面向擴展的,我們可以通過調整集羣應用實例數、事件表分表數量和 kafka partitions 數量來提高系統整體的吞吐量。事件表分表越多,事件消息從 DB 到 kafka 的延遲就更低;應用實例越多,系統單位時間內能承受的事件上限也越多,另外也能更好的負載 kafka 消息的消費。
每一個應用,作爲事件發佈者,其產生的事件最終都被推送到一個 Kafka Topic;但作爲消費者,可以訂閱不同的 Topic,這些 Topic 可以是自己的推送的,也可以是其它應用推送的事件。
實現篇
這裏我們只對部分核心代碼作一個簡單的介紹:
SimpleLock 是一個基於 Zookeeper 的簡單分佈式鎖實現,我們使用 SimpleLock 來實現 Master 的競選。
EventSubmitter 是一個線程,負責把事件表中的事件信息推送到 Kafka broker。初始化時需要傳入一個 int 參數,表示處理哪一個事件分表。它被實現成一個響應中斷的線程,因爲當 Master 重新分配任務後,Worker 需要先停掉當前進行中的任務。
Master 類是 Master 實例的主要實現。實例在啓動時會調 Master 類的 start 方法,Master 實例監聽 workers 節點,當有新實例加入或實例下線時,Master 實例會調用 onWorkerChange 方法進行重新分配, onWorkerChange 方法實現了一個簡單的分配算法,只有任務變更的 Worker 實例會收到分配通知。
Worker 類是 Worker 實例的主要實現,實例在啓動時會調 Worker 類的 start 方法。集羣中的每一個實例都是 Worker,會在 workers 節點下創建一個臨時的節點表示自己,同時監聽該節點,接受 Master 分配給自己的任務。當 Worker 接收到分配通知時,會先停止當前在運行的所有任務,再根據 worker 節點的內容開始執行新分配的任務。
示例
來看一個具體的事例,假設我們要以天爲維度,統計每天的下單量和下單金額。現在,我們已經有了訂單表:
createtableifnotexistsorder(order_idbigintnotnullauto_incrementcomment'主鍵',user_idbigintnotnullcomment'客戶 id',order_timedatetimenotnullcomment'訂單時間',order_amountintnotnullcomment'訂單金額,單位:分',
primarykey(order_id)
)engine=innodbdefaultcharset=utf8comment='訂單表';
這個需求我們可以簡單的使用 sql 來做,比如:
selectdate(order_time)as day,count(*)as total_num,sum(order_amount)as total_amount from order
group bydate(order_time)
{1}
但是在生產環境中這麼做往往不現實,比如性能問題、或者我們對訂單表做了分表、或者幾個月前的數據庫了備份,而你正好需要查詢這些數據,等等。實現這個需求更好的方式是採用事件驅動,在下單的時候發佈一個事件,然後異步的維護一個查詢表,這樣之間的種種問題都將不復存在。先創建一個查詢表,如下:
createtableifnotexistsdaily_order_report(idbigintnotnullauto_incrementcomment'主鍵',daydatenotnullcomment'統計日',order_numbigintnotnullcomment'訂單數量',order_totalbigintnotnullcomment'訂單總金額,單位:分',
primarykey(id),
uniquekey(day)
)engine=innodbdefaultcharset=utf8comment='訂單日報表';
在下單的時候,我們需要發佈一個 下單事件 :
@Transactional(readOnly =false, propagation = Propagation.REQUIRED, isolation = Isolation.READ_COMMITTED, rollbackFor = Exception.class)br/>@Override
publicvoidcreateOrder(Order order){
orderDao.insert(order);
// 發佈下單事件
publisher.publish("order_created",newDate(), order.json(), order.getUserId().intValue() % Configuration.instance().getNumOfEventTables());
}
之後,我們需要實現一個訂閱者,在接收到 下單事件 後,根據訂單的日期做相應的統計:br/>@Component
publicclassDailyOrderReportSubscriberimplementsBaseSubscriber{
@Autowired
privateOrderRepos repos;
@Override
publicvoidonEvent(Event e){
Order order = Order.fromJson(e.getContext());
DailyOrderReport report = repos.selectDailyOrderReportByKey(newjava.sql.Date(order.getOrderTime().getTime()));
if(null== report) {
report =newDailyOrderReport();
report.setDay(newjava.sql.Date(order.getOrderTime().getTime()));
report.setOrderNum(1l);
report.setOrderTotal(newLong(order.getOrderAmount()));
repos.createDailyOrderReport(report);
}else{
report.setOrderNum(report.getOrderNum() +1);
report.setOrderTotal(report.getOrderTotal() + order.getOrderAmount());
repos.updateDailyOrderReport(report);
}
}
}
隨機創建 10 個訂單後,我們的報表情況如下:
mysql>select*fromorder;
+----------+---------+---------------------+--------------+
| order_id | user_id | order_time | order_amount |
+----------+---------+---------------------+--------------+
| 21 | 3 | 2018-09-24 01:06:43 | 251 |
| 22 | 2 | 2018-09-24 01:06:43 | 371 |
| 23 | 5 | 2018-09-24 01:06:43 | 171 |
| 24 | 0 | 2018-09-24 01:06:43 | 904 |
| 25 | 3 | 2018-09-24 01:06:43 | 55 |
| 26 | 5 | 2018-09-24 01:06:44 | 315 |
| 27 | 8 | 2018-09-24 01:06:44 | 543 |
| 28 | 8 | 2018-09-24 01:06:44 | 537 |
| 29 | 2 | 2018-09-24 01:06:44 | 123 |
| 30 | 3 | 2018-09-24 01:06:45 | 938 |
+----------+---------+---------------------+--------------+
10 rows inset(0.00sec)
mysql>select*fromdaily_order_report;
+----+------------+-----------+-------------+
| id | day | order_num | order_total |
+----+------------+-----------+-------------+
| 2 | 2018-09-24 | 10 | 4208 |
+----+------------+-----------+-------------+
1 row inset(0.00sec)
mysql>