




前言
我在哪?是LBS領域首先要解決的問題。因爲技術限制,傳統的GPS衛星定位只有室外的空曠地區才能夠準確定位,對於室內環境來說,GPS定位往往會因“搜星”失敗而無法定位。正因爲GPS定位的天然缺陷,基於手機基站的定位技術正在蓬勃發展。然而因爲基站的覆蓋範圍大,很難以取得高精度的效果,本文利用基站軌跡,提出了一個提高基站定位精度的方法。
關鍵字:基站定位,軌跡定位,Viterbi算法
緒論
對於單基站定位,如果僅根據用戶當前的基站ID進行定位,精度必定有限。用戶可能出現在基站覆蓋範圍內的任意一個地方,基站的覆蓋範圍越大,推測出來的用戶位置就越不準。
如果我們還知道用戶之前一段時間內經過的基站ID序列(稱爲基站軌跡),此時即可大致判定用戶行動軌跡,可藉此提高精度。
例舉一個簡單例子:
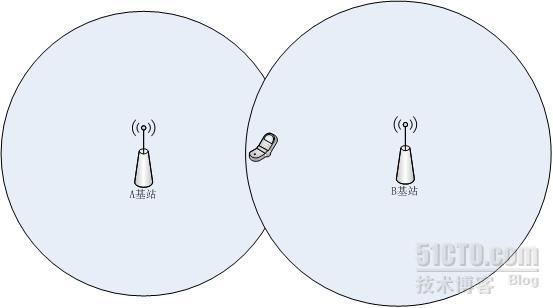
如上圖所示,假設用戶在一瞬間,基站ID從A切換到了B,此時用戶屬於B基站,單單從B這一個基站考慮的話,很難從其巨大的覆蓋圓內取出精準位置。
但是從假設條件我們知道,用戶之前一直是在A基站範圍內,切換到B基站只是剛剛發生的事情,通過這個條件,人很容易就想到用戶很大可能在兩圓相交的位置(圖中手機的位置)。當然,對於這種特殊情況來說,不光是人,程序也很容易去模擬,但是如果用戶繼續行走呢?比如一直走到B基站的右側,還有算法可以繼續推算嗎?
本算法便是提出一種模型,用以解決此問題。
隱馬爾可夫鏈模型(HMM)與Viterbi算法介紹
隱馬爾可夫鏈作爲一個常見的序列預測模型,其具體定義在這裏就不細細展開了,有興趣的用戶可以到wiki上搜索相關資料。此模型已經在多個計算機場景中得到了成功的應用,比如拼音輸入法中,我們輸入”wo zai bai du da sha”,實際想輸入的是“我在百度大廈”,也就是說其中有兩個序列、一個是拼音字母序列(明序列),一個是漢字序列(隱序列)。兩個序列之間有一定的相互關係,如何通過一個已知的“明序列”來推測另一個未知的“隱序列”便是隱馬爾可夫鏈模型要解決的問題。本文的重點也是如何用隱馬爾可夫鏈模型解決軌跡基站定位。
解決隱馬爾可夫鏈問題中的一個著名算法是Viterbi算法。建議讀者先去閱讀wiki中的Viterbi算法介紹,裏面有一個簡單的天氣的例子詳細說明了該算法的大體過程。:
http://en.wikipedia.org/wiki/Viterbi_algorithm
算法細節
隱馬爾可夫鏈模型
我們知道隱馬爾可夫鏈中有兩個序列,一個是明序列(A1、A2、A3……),一個是隱序列(B1、B2、B3……)。在本模型之中,明序列(A1、A2、A3……)代表了用戶經過的基站序列,隱序列是用戶的實際位置序列。我們要做的是通過基站序列,來推測用戶的實際位置序列。
首先,我們做如下假設:
● 用戶行使在道路上。
●用戶在勻速的行駛。
有了這兩個假設,再把道路分解成一個一個的路段,我們便可以用路段序列來代替用戶的位置序列。也就是說,我們需要通過觀察到的用戶基站序列,來推測用戶的路段序列。如下圖所示,我們觀察到的是用戶所經過的基站覆蓋圓情況,需要求得的是用戶的路段行駛軌跡。假設觀察到基站軌跡是圖中的綠色基站,那很明顯用戶最大可能是沿着紅色箭頭在行走。

Viterbi算法
如果要用Viterbi算法來解決本應用,只要知道如下幾個問題即可。
路段的定義:將路網數據每隔10m抽象成一個有向線段,並且假設用戶在這些路段之間離散的跳躍,每一個有向線段,即爲一個路段。並且在這裏假設用戶將要跳躍到的路段只和當前路段相關,與過去的路段無關。
基站序列的定義:每秒鐘檢測其所處的基站,並且做記錄。比如記錄信息爲(基站A、基站B、基站B、基站C),則表示用戶在四秒鐘的時間內分別屬於基站ABBC三個基站,並且在B基站待了2秒。
路段序列定義:如果用戶能夠每秒鐘記錄其所屬的路段,這個序列便是路段序列,這是用戶的真實位置序列。
路段從屬於基站的概率:Viterbi算法中需要知道隱狀態從屬於明狀態的概率,拿到本應用中來看,便是要知道路段從屬於基站的概率。解決此問題有如下兩個方法:
1.根據路段在基站覆蓋圓的具體位置來調整概率,比如,距離基站覆蓋圓中心越近,則從屬於此基站的概率越大。
2.根據真實的用戶數據來推算概率。此方法最準確,其原理也簡單,根據用戶的真實位置(GPS點)變可以知道用戶處於的哪個路段,也就知道了這個路段曾經屬於過哪些基站,以及其概率。
如果有用戶的真實數據,那麼採用方案2無疑是最好的,但是沒有數據的情況下,用方案1也可以最大可能的模擬。
路段之間的轉移概率:路段之間的轉移概率是本算法的重點,在這裏做如下定義:假設路段A指向了路段B和C,那麼從路段A轉移到B和C的概率分別是33%,也就是概率等分,請注意路段A能轉移到自身,其到自身的概率也是33%。
Viterbi算法大體過程
Viterbi算法過程是在各個路段之間進行概率轉移。如下圖所示,用戶的基站序列爲ABBC,則需要進行三(n-1)次概率轉移過程。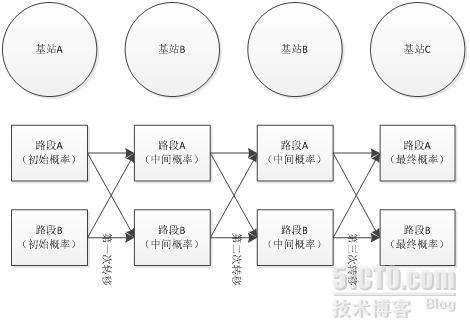
對於基站序列ABBC來說,需要分成以下幾步:
1.求得每一個路段的初始概率,即各個路段屬於基站A的概率。
2.進行第一次轉移,從基站A到基站B。比如路段A轉移到路段B的概率爲:路段A的概率×兩個路段的轉移概率×路段B屬於基站的概率。
3.重複過程2,再轉移兩次,分別爲 基站Bà基站B
4.最後取出概率最大的路段即爲用戶位置。
有心的讀者可能已經看到,路段之間轉移概率的定義是一個路段只能轉移與其相連接的路段,這樣有一個問題便是,按照上述算法可能所有路段的最終概率均爲0。這是因爲我們假設在時間間隔內,用戶只能從一個路段行駛到相鄰的路段,然而實際情況下,用戶的速度可能較快,在我們掃描基站的間隔內,用戶能跨越多個路段。對於這個問題,我們需要根據用戶的速度來對用戶掃描到的基站序列進行修復,比如速度是我們假定速度兩倍的用戶可以將基站序列ABBC變換成AABBBBCC。用戶的速度可以通過速度傳感器或者基站軌跡進行大概的推算,比如用戶經過了10個基站,將這10個基站的覆蓋圓中心連接起來,用總長除以時間,即爲大概的速度。
算法效果
作者在實現本算法之後,對於勻速運動的定位用戶的定位精度提升了一倍之多。對於一些特定用戶,更是能明顯的起到優化作用,比如高速公路上的用戶,基站覆蓋半徑大,沒有用本算法的話,只能返回巨大基站覆蓋圓的中心給用戶,定位精度極差。採用本算法之後定位精度會得到極大的提高,甚至用戶的定位點絲毫不差的跟隨用戶的真實走動而走動,這也是因爲在高速公路上路網比較簡單,此算法效果會更突出。