




背景
最近準備上線cassandra這個產品,同事在做一些小規格ECS(8G)的壓測。壓測時候比較容易觸發OOM Killer,把cassandra進程幹掉。問題是8G這個規格我配置的heap(Xmx)並不高(約6.5g)已經留出了足夠的空間給系統。只有可能是Java堆外內存使用超出預期,導致RES增加,纔可能觸發OOM。焦作國醫醫院口碑好嗎___看胃腸到國醫:http://jz.lieju.com/zhuankeyiyuan/37572844.htm
調查過程
0.初步懷疑是哪裏有DirectBuffer泄漏,或者JNI庫的問題。
1.按慣例通過google perftools追蹤堆外內存開銷,但是並未發現明顯的異常。
2.然後用Java NMT 看了一下,也沒有發現什麼異常。

3.查到這裏思路似乎斷了,因爲跟DirectBuffer似乎沒啥關係。這時候我注意到進程虛擬內存非常高,已經超過ECS內存了。懷疑這裏有些問題。

4.進一步通過/proc/pid/smaps 查看進程內存地址空間分佈,發現有大量mmap的文件。這些文件是cassandra的數據文件。
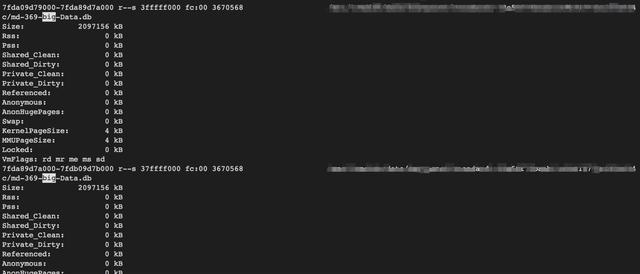
此時這些mmap file 虛擬內存是2G,但是物理內存是0(因爲我之前重啓過,調低過內存防止進程掛掉影響問題排查)。
顯然mmap的內存開銷是不受JVM heap控制的,也就是堆外內存。如果mmap的文件數據被從磁盤load進物理內存(RES增加),Java NMT和google perftool是無法感知的,這是kernel的調度過程。
5.考慮到是在壓測時候出現問題的,所以我只要讀一下這些文件,觀察下RES是否會增加,增加多少,爲啥增加,就能推斷問題是不是在這裏。通過下面的命令簡單讀一下之前導入的數據。
cassandra-stress read duration=10m cl=ONE -rate threads=20 -mode native cql3 user=cassandra password=123 -schema keysp ace=keyspace5 -node core-3
6.可以觀察到壓測期間(sar -B),major page fault是明顯上升的,因爲數據被實際從磁盤被load進內存。焦作國醫胃腸醫院胃鏡檢查多少錢__良心醫院:http://jz.lieju.com/zhuankeyiyuan/37572711.htm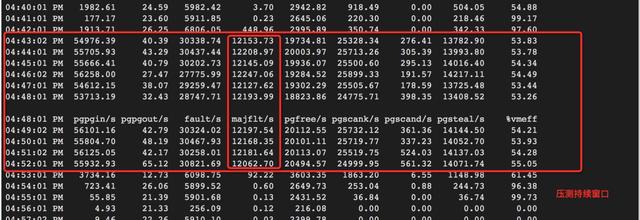
同時觀察到mmap file物理內存增加到20MB: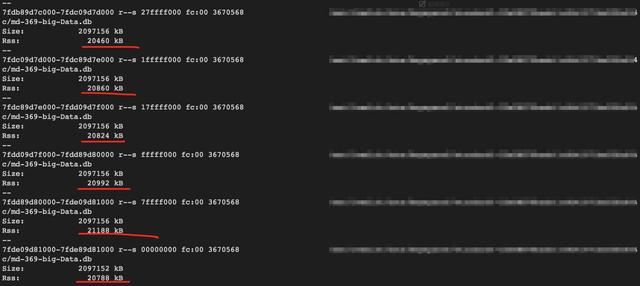
最終進程RES漲到7.1g左右,增加了大約600M:

如果加大壓力(50線程),還會漲,每個mmap file物理內存會從20MB,漲到40MB
7.Root cause是cassandra識別系統是64還是32來確定要不要用mmap,ECS都是64,但是實際上小規格ECS內存並不多。

結論
1.問題誘因是mmap到內存開銷沒有考慮進去,具體調整方法有很多。可以針對小規格ECS降低heap配置或者關閉mmap特性(disk_access_mode=standard)
2.排查Java堆外內存還是比較麻煩的,推薦先用NMT查查,用起來比較簡單,配置JVM參數即可,可以看到內存申請情況。