




前幾天看到一篇關於Kubernetes 網絡模型的博文,共兩篇,感覺分析很到位。自己對內容稍做整理,與各位朋友分享。
隨着雲計算的興起,各大平臺之爭也落下了帷幕,Kubernetes作爲後起之秀已經成爲了事實上的PaaS平臺標準,而網絡又是雲計算環境當中最複雜的部分,總是讓人琢磨不透。本篇 圍繞在Kubernetes環境當中同一個節點(work node)上的Pod之間是如何進行網絡通信的這個問題進行展開,暫且不考慮跨節點網絡通信的情況。
一、Network Namespace
Namespace
提到容器就不得不提起容器的核心底層技術Namespace,Namespace爲Linux內核當中提供的一種隔離機制,最初在2002年引入到Linux 2.4.19當中,且只有Mount Namespace用於文件系統隔離。截止目前,Linux總共提供了7種Namespace(since Linux 4.6),系統當中運行的每一個進程都與一個Namespace相關聯,且該進程只能看到和使用該Namespace下的資源。可以簡單將Namespace理解爲操作系統對進程實現的一種“障眼法”,比如通過UTS Namespace可以實現讓運行在同一臺機器上的進程看到不同的Hostname。正是由於Namespace開創性地隔離方式才讓容器的實現得以變爲可能,才能讓我們的軟件真正地實現“build once, running everywhere”。
Mount Namespace 文件系統隔離
UTS Namespace 主機名隔離
IPC Namespace 進程間通信隔離
PID Namespace 進程號隔離
Network Namespace 網絡隔離
User Namespace 用戶認證隔離
Control group (Cgroup) Namespace Cgroup 認證(since Linux 4.6)Network Namespace
Network Namespace是Linux 2.6.24纔開始引入的,直到Linux 2.6.29才完成的特性。Network Namespace實際上實現的是對網絡棧的虛擬化,且在創建出來時默認只有一個迴環網絡接口lo,每一個網絡接口(不管是物理接口還是虛擬化接口)都只能存在於一個Network Namespace當中,但可以在不同的Network Namespace之間切換,每一個Network Namespace都有自己獨立的IP地址、路由表、防火牆以及套接字列表等網絡相關資源。當刪除一個Network Namespace時,其內部的網絡資源(網路接口等)也會同時被刪掉,而物理接口則會被切換回之前的Network Namespace當中。
由此可以知道不同的兩個Network Namespace在網絡上是相互隔離的,即不能夠直接進行通信,就好比兩個相互隔離的局域網之間不能直接通信,那麼通過Network Namespace隔離後的容器是如何實現與外部進行通信的呢?
容器與Pod
在Kubernetes的定義當中,Pod爲一組不可分離的容器,且共享同一個Network Namespace,故不存在同一個Pod當中容器間網絡通信的問題,對於同一個Pod當中的容器來講,通過Localhost即可與其他的容器進行網絡通信。
所以同一個節點上的兩個Pod如何進行網絡通信的問題可以轉變爲,同一個節點上的兩個容器如何進行網絡通信。
Namespace實操
在回答上面提出的Network Namespace網絡通信的問題前,先來做一些簡單的命令行操作,先對Namespace有一個感性地認識,實驗環境如下:
[root@andy ~]# cat /etc/redhat-release
CentOS Linux release 7.6.1810 (Core)
[root@andy ~]# uname -a
Linux andy 3.10.0-957.10.1.el7.x86_64 #1 SMP Mon Mar 18 15:06:45 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux
[root@andy ~]#通過命令lsns可以查看到宿主機上所有的Namespace(注意需要使用root用戶執行,否則可能會出現有些Namespace看不到的情況):
[root@andy ~]# lsns
NS TYPE NPROCS PID USER COMMAND
4026531836 pid 152 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 2
4026531837 user 152 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 2
4026531838 uts 152 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 2
4026531839 ipc 152 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 2
4026531840 mnt 148 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 2
4026531856 mnt 1 28 root kdevtmpfs
4026531956 net 152 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 2
4026532438 mnt 1 5046 chrony /usr/sbin/chronyd
4026532503 mnt 1 5127 root /usr/sbin/NetworkManager --no-daemon
4026532593 mnt 1 5622 root /usr/sbin/cupsd -f
[root@andy ~]#lsns默認會輸出所有可以看到的Namespace,簡單解釋一下lsns命令各個輸出列的含義:
NS Namespace identifier (inode number)
Type kind of namespace
NPROCS number of processes in the namespace
PID lowers PID in the namespace
USER username of the PID
COMMAND command line of the PID與Network Namespace相關性較強的還有另外一個命令 ip netns,主要用於持久化命名空間的管理,包括Network Namespace的創建、刪除以和配置等。 ip netns命令在創建Network Namespace時默認會在/var/run/netns目錄下創建一個bind mount的掛載點,從而達到持久化Network Namespace的目的,即允許在該命名空間當中沒有進程的情況下依然保留該命名空間。Docker當中由於缺少了這一步,玩過Docker的同學就會發現通過Docker創建容器後並不能在宿主機上通過 ip netns查看到相關的Network Namespace(這個後面會講怎麼才能夠看到,稍微小操作一下就行)。
與Network Namespace相關操作命令:
ip netns add < namespace name > # 添加network namespace
ip netns list # 查看Network Namespace
ip netns delete < namespace name > # 刪除Network Namespace
ip netns exec < namespace name > <command> # 進入到Network Namespace當中執行命令
創建名爲netA的Network Namespace:
[root@andy ~]#
[root@andy ~]# ip netns list
[root@andy ~]# ip netns add netA
[root@andy ~]# ip netns list
netA
[root@andy ~]#查看創建的Network Namespace:
[root@andy ~]# ip netns exec netA ip link set lo up
[root@andy ~]# ip netns exec netA ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
[root@andy ~]#
[root@andy ~]# ip netns exec netA ip route show
[root@andy ~]#可以看到Network Namespace netA當中僅有一個環回網絡接口lo,且有獨立的路由表(爲空)。
宿主機(root network namespace)上有網絡接口ens160(192.168.20.136),此時可以直接ping通IP 192.168.20.136。
[root@andy ~]# ip add show ens160
3: ens160: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:f1:84:81 brd ff:ff:ff:ff:ff:ff
inet 192.168.20.136/24 brd 192.168.20.255 scope global noprefixroute dynamic ens160
valid_lft 85091sec preferred_lft 85091sec
inet6 fe80::4845:682:9d35:c511/64 scope link noprefixroute
valid_lft forever preferred_lft forever
[root@andy ~]# ping -c2 192.168.20.136
PING 192.168.20.136 (192.168.20.136) 56(84) bytes of data.
64 bytes from 192.168.20.136: icmp_seq=1 ttl=64 time=0.058 ms
64 bytes from 192.168.20.136: icmp_seq=2 ttl=64 time=0.066 ms
--- 192.168.20.136 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 999ms
rtt min/avg/max/mdev = 0.058/0.062/0.066/0.004 ms
[root@andy ~]#嘗試將root network namespace當中的ens160接口添加到network namespce netA當中:
ip link set dev ens160 netns netA
[root@andy ~]# ip link set dev ens160 netns netA
[root@andy ~]# ip netns exec netA ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
3: ens160: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 00:0c:29:f1:84:81 brd ff:ff:ff:ff:ff:ff
[root@andy ~]# ifconfig ens160
ens160: error fetching interface information: Device not found
[root@andy ~]# ip netns exec netA ip link set ens160 up
[root@andy ~]# ip netns exec netA ip addr add 10.10.88.170/24 dev ens160
[root@andy ~]# ip netns exec netA ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
3: ens160: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:f1:84:81 brd ff:ff:ff:ff:ff:ff
inet 10.10.88.170/24 scope global ens160
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fef1:8481/64 scope link
valid_lft forever preferred_lft forever
[root@andy ~]#將宿主機上的網絡接口ens160(10.10.88.170)加入到網絡命名空間netA後:
- 宿主機上看不到ens160網絡接口了(同一時刻網絡接口只能在一個Network Namespace)
- netA network namespace裏面無法ping通root namespace當中的ens32(網絡隔離)
從上面的這些操作我們只是知道了Network Namespace的隔離性,但仍然無法達到想要的結果,即讓兩個容器或者說兩個不同的Network Namespace進行網絡通信。在真實的生活場景中,當要連接同一個集團兩個相距千里的分公司的局域網時,有3種解決方案:第一種是對數據比較隨意的,直接走公網連接,但存在網絡安全的問題。第二種是不差錢的,直接拉一根專線將兩個分公司的網絡連接起來,這樣雖然遠隔千里,但仍然可以處於一個網絡當中。另外一種是兼顧網絡安全集和性價比的×××連接,但存在性能問題。很顯然,不管是哪一種方案都需要有一根“線”將兩端連接起來,不管是虛擬的×××還是物理的專線。
二、vEth(Virtual Ethernet Device)
前面提到了容器通過Network Namespace進行網絡隔離,但是又由於Network Namespace的隔離導致兩個不同的Network Namespace無法進行通信,這個時候我們聯想到了實際生活場景中連接一個集團的兩個分公司局域網的處理方式。實際上Linux當中也存在類似像網線一樣的虛擬設備vEth(此時是不是覺得Linux簡直無所不能?),全稱爲Virtual Ethernet Device,是一種虛擬的類似於以太網絡的設備。
vEth有以下幾個特點:
1) vEth作爲一種虛擬以太網絡設備,可以連接兩個不同的Network Namespace。
2) vEth總是成對創建,所以一般叫veth pair。(因爲沒有隻有一頭的網線)。
3) vEth當中一端收到數據包後另一端也會立馬收到。
4) 可以通過ethtool找到vEth的對端接口。(注意後面會用到)
理解了以上幾點對於我們後面理解容器間的網絡通信就容易多了。
vEth實操
創建vEth:
ip link add < veth name > type veth peer name < veth peer name >
創建名爲veth0A,且對端爲veth0B的vEth設備。如下所示:
[root@andy ~]# ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: ens32: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 00:0c:29:f1:84:77 brd ff:ff:ff:ff:ff:ff
[root@andy ~]#
[root@andy ~]# ip link add veth0A type veth peer name veth0B
[root@andy ~]# ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: ens32: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 00:0c:29:f1:84:77 brd ff:ff:ff:ff:ff:ff
4: veth0B@veth0A: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 6e:4f:15:ab:f5:36 brd ff:ff:ff:ff:ff:ff
5: veth0A@veth0B: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 22:17:ec:4e:0f:eb brd ff:ff:ff:ff:ff:ff
[root@andy ~]#可以看到root network namespace當中多出來了兩個網絡接口veth0A和veth0B,網絡接口名稱@後面的接的正是對端的接口名稱。
創建Network Namespace netA和netB:
ip netns add netA
ip netns add netB
[root@andy ~]# ip netns add netB
[root@andy ~]# ip netns list
netB
netA (id: 0)
[root@andy ~]#分別將接口veth0A加入到netA,將接口veth0B加入到netB:
ip link set veth0A netns netA
ip link set veth0B netns netB
[root@andy ~]# ip link set veth0A netns netA
[root@andy ~]# ip link set veth0B netns netB這個時候通過ip a查看宿主機(root network namespace)網絡接口時可以發現,已經看不到接口veth0A和veth0B了(同一時刻一個接口只能處於一個Network Namespace下面)。
再分別到netA和netB兩個Network Namespace當中去查看,可以看到兩個Network Namespace當中都多了一個網絡接口。如下所示:
[root@andy ~]# ip netns exec netA ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
3: ens160: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:f1:84:81 brd ff:ff:ff:ff:ff:ff
inet 10.10.88.170/24 scope global ens160
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fef1:8481/64 scope link
valid_lft forever preferred_lft forever
5: veth0A@if4: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 22:17:ec:4e:0f:eb brd ff:ff:ff:ff:ff:ff link-netnsid 1
[root@andy ~]#
[root@andy ~]# ip netns exec netB ip addr
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
4: veth0B@if5: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 6e:4f:15:ab:f5:36 brd ff:ff:ff:ff:ff:ff link-netnsid 0
[root@andy ~]#
[root@andy ~]# ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: ens32: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 00:0c:29:f1:84:77 brd ff:ff:ff:ff:ff:ff
[root@andy ~]#分別拉起兩個網絡接口並配上IP,這裏將爲veth0A配置IP 192.168.100.1,veth0B配置IP 192.168.100.2:
ip netns exec netA ip link set veth0A up
ip netns exec netA ip addr add 192.168.100.1/24 dev veth0A
[root@andy ~]# ip netns exec netA ip link set veth0A up
[root@andy ~]# ip netns exec netB ip link set veth0B up
[root@andy ~]# ip netns exec netA ip address add 192.168.100.1/24 dev veth0A
[root@andy ~]# ip netns exec netB ip address add 192.168.100.2/24 dev veth0B
[root@andy ~]#
[root@andy ~]# ip netns exec netA ip add
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
3: ens160: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:f1:84:81 brd ff:ff:ff:ff:ff:ff
inet 10.10.88.170/24 scope global ens160
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fef1:8481/64 scope link
valid_lft forever preferred_lft forever
5: veth0A@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 22:17:ec:4e:0f:eb brd ff:ff:ff:ff:ff:ff link-netnsid 1
inet 192.168.100.1/24 scope global veth0A
valid_lft forever preferred_lft forever
inet6 fe80::2017:ecff:fe4e:feb/64 scope link
valid_lft forever preferred_lft forever
[root@andy ~]# ip netns exec netB ip add
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
4: veth0B@if5: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 6e:4f:15:ab:f5:36 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 192.168.100.2/24 scope global veth0B
valid_lft forever preferred_lft forever
inet6 fe80::6c4f:15ff:feab:f536/64 scope link
valid_lft forever preferred_lft forever
[root@andy ~]#測試通過veth pair連接的兩個Network Namespace netA和netB之間的網絡連接。
在netA(192.168.100.1)當中ping netB(192.168.100.2):
[root@andy ~]# ip netns exec netA ping -c 2 192.168.100.2
PING 192.168.100.2 (192.168.100.2) 56(84) bytes of data.
64 bytes from 192.168.100.2: icmp_seq=1 ttl=64 time=0.104 ms
64 bytes from 192.168.100.2: icmp_seq=2 ttl=64 time=0.059 ms
--- 192.168.100.2 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 999ms
rtt min/avg/max/mdev = 0.059/0.081/0.104/0.024 ms
[root@andy ~]#
[root@andy ~]# ip netns exec netB ping -c 2 192.168.100.1
PING 192.168.100.1 (192.168.100.1) 56(84) bytes of data.
64 bytes from 192.168.100.1: icmp_seq=1 ttl=64 time=0.066 ms
64 bytes from 192.168.100.1: icmp_seq=2 ttl=64 time=0.066 ms
--- 192.168.100.1 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 999ms
rtt min/avg/max/mdev = 0.066/0.066/0.066/0.000 ms
[root@andy ~]#可以發現netA跟netB這兩個Network Namespace在通過veth pair連接後已經可以進行正常的網絡通信了。
解決了容器Network Namespace隔離的問題,這個時候有云計算經驗或者熟悉OpenStack和ZStack的同學就會發現,現在的場景跟虛擬機之間的網絡互聯是不是簡直一模一樣了?
vEth作爲一個二層網絡設備,當需要跟別的網絡設備相連時該怎麼處理呢?在現實生活場景當中會拿一個交換機將不同的網線連接起來。實際上在虛擬化場景下也是如此,Linux Bridge和Open vSwith(OVS)是當下比較常用的兩種連接二層網絡的解決方案,而Docker當中採用的是Linux Bridge。
三、Docker與Kubernetes
Kubernetes作爲一個容器編排平臺,在容器引擎方面既可以選擇Docker也可以選擇rkt,這裏直接分別通過Docker和Kubernetes創建容器來進行簡單比對。 Kubernetes在創建Pod時首先會創建一個pause容器,它的唯一作用就是保留和佔據一個被Pod當中所有容器所共享的網絡命名空間(Network Namespace),就這樣,一個Pod IP並不會隨着Pod當中的一個容器的起停而改變。
Docker下的容器網絡
先來看一下在沒有Kubernetes的情況下是什麼樣子的。在Docker啓動的時候默認會創建一個名爲docker0的網橋,且默認配置下采用的網絡段爲172.17.0.0/16,每一個在該節點上創建的容器都會被分配一個在該網段下的IP。容器通過連接到docker0上進行相互通信。
手動創建兩個容器:
docker run -it --name testA busybox sh
docker run -it --name testB busybox sh
查看網絡接口狀況,並查看宿主機網橋,如下所示:
brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.0242f826c7a7 no veth4545ac7
vethfcfc926可以發現docker0上面已經連接了兩個虛擬網絡接口(vEth)。
在docker0上通過tcpdump抓包查看整個過程,命令如下:
tcpdump -n -i docker0
可以發現容器testA和容器testB正是通過docker0網橋進行網絡包轉發的。
加入Kubernetes後的容器網絡
其實加入Kubernetes後本質上容器網絡通信模式並沒有發生變更,但Kubernetes出於網絡地址規劃的考慮,重新創建了一個網橋cni0用於取代docker0,來負責本節點上網絡地址的分配,而實際的網絡段管理由Flannel處理。
如果想辦法 創建2個Pods 並運行同一臺宿主機上。通過ip a命令可以看到在Pod的宿主機上多出來了2個vethXXX樣式的網絡接口:
ip a
.....
6: cni0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP qlen 1000
link/ether 0a:58:0a:f4:02:01 brd ff:ff:ff:ff:ff:ff
inet 10.244.2.1/24 scope global cni0
valid_lft forever preferred_lft forever
inet6 fe80::f0a0:7dff:feec:3ffd/64 scope link
valid_lft forever preferred_lft forever
9: veth2a69de99@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master cni0 state UP
link/ether 86:70:76:4f:de:2b brd ff:ff:ff:ff:ff:ff link-netnsid 2
inet6 fe80::8470:76ff:fe4f:de2b/64 scope link
valid_lft forever preferred_lft forever
10: vethc8ca82e9@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master cni0 state UP
link/ether 76:ad:89:ae:21:68 brd ff:ff:ff:ff:ff:ff link-netnsid 3
inet6 fe80::74ad:89ff:feae:2168/64 scope link
valid_lft forever preferred_lft forever
39: veth686e1634@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master cni0 state UP
link/ether 66:99:fe:30:d2:e1 brd ff:ff:ff:ff:ff:ff link-netnsid 4
inet6 fe80::6499:feff:fe30:d2e1/64 scope link
valid_lft forever preferred_lft forever
40: vethef16d6b0@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master cni0 state UP
link/ether c2:7f:73:93:85:fc brd ff:ff:ff:ff:ff:ff link-netnsid 5
inet6 fe80::c07f:73ff:fe93:85fc/64 scope link
valid_lft forever preferred_lft forever查看網橋的狀態如下:
brctl show
bridge name bridge id STP enabled interfaces
cni0 8000.0a580af40201 no veth2a69de99
veth686e1634
vethc8ca82e9
vethef16d6b0
docker0 8000.024243a1fcad no此時兩個Pod的網絡連接如圖所示: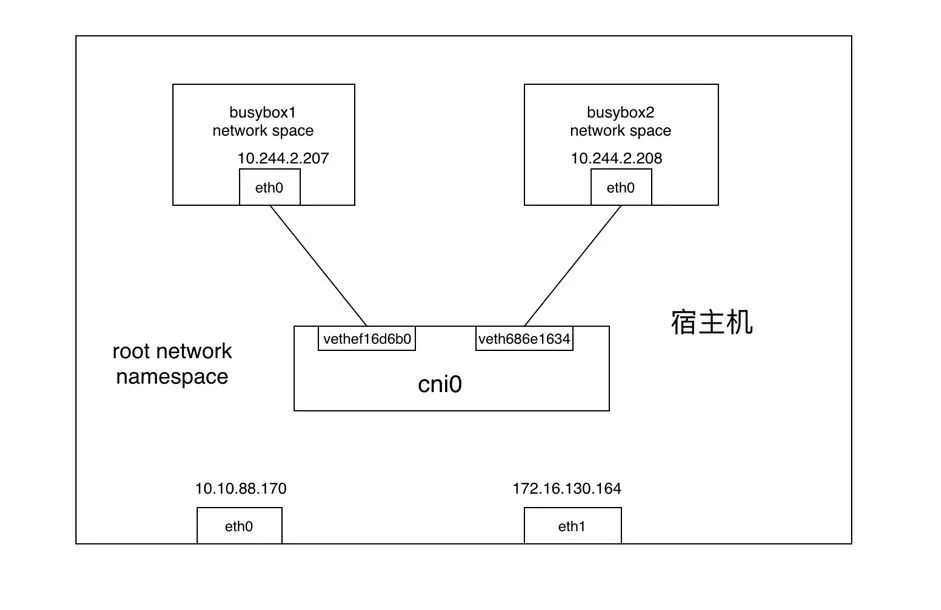
網絡包從Container A發送到Container B的過程如下:
- 網絡包從busybox1的eth0發出,並通過vethef16d6b0進入到root netns(網絡包從vEth的一端發送後另一端會立馬收到)。
- 網絡包被傳到網橋cni0,網橋通過發送“who has this IP?”的ARP請求來發現網絡包需要轉發到的目的地(10.244.2.208)。
- busybox2回答到它有這個IP,所以網橋知道應該把網絡包轉發到veth686e1634(busybox2)。
- 網絡包到達veth686e1634接口,並通過vEth進入到busybox2的netns,從而完成網絡包從一個容器busybox1到另一個容器busybox2的過程。
對於以上流程有疑問的同學也可以自己動手驗證一下結論,最好的方式就是通過tcpdump命令在各個網絡接口上進行抓包驗證,看網絡包是如何經過網橋再由veth pair流轉到另一個容器網絡當中的。