




繼續接上轉載
爲了解決Kubernetes當中網絡通信的問題,Kubernetes作爲一個容器編排平臺提出了Kubernetes網絡模型,但是並沒有自己去實現,具體網絡通信方案通過網絡插件來實現。
其實Kubernetes網絡模型當中總共只作了三點要求:
1) 運行在一個節點當中的Pod能在不經過NAT的情況下跟集羣中所有的Pod進行通信
2) 節點當中的客戶端(system daemon、kubelet)能跟該節點當中的所有Pod進行通信
3) 以host network模式運行在一個節點上的Pod能跟集羣中所有的Pod進行通信
從Kubernetes的網絡模型可以看出來,在Kubernetes當中希望做到的是每一個Pod都有一個在集羣當中獨一無二的IP,並且可以通過這個IP直接跟集羣當中的其他Pod以及節點自身的網絡進行通信,一句話概括就是Kubernetes當中希望網絡是扁平化的。
針對Kubernetes網絡模型也涌現出了許多的實現方案,例如Calico、Flannel、Weave等等,雖然實現原理各有千秋,但都圍繞着同一個問題即如何實現Kubernetes當中的扁平網絡進行展開。Kubernetes只需要負責編排調度相關的事情,修橋鋪路的事情交給相應的網絡插件即可。Flannel簡介
Flannel項目爲CoreOS團隊對Kubernetes網絡設計實現的一種三層網絡通信方案,安裝部署方式可以參考官方示例文檔:https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml, 故關於Flannel的安裝部署部分這裏暫時不進行贅述,有興趣的朋友可以參考官方文檔進行部署測試。
爲了便於理解和說明,以下內容將用一個1(master)+2(work node)的Kubernetes集羣進行舉例說明。 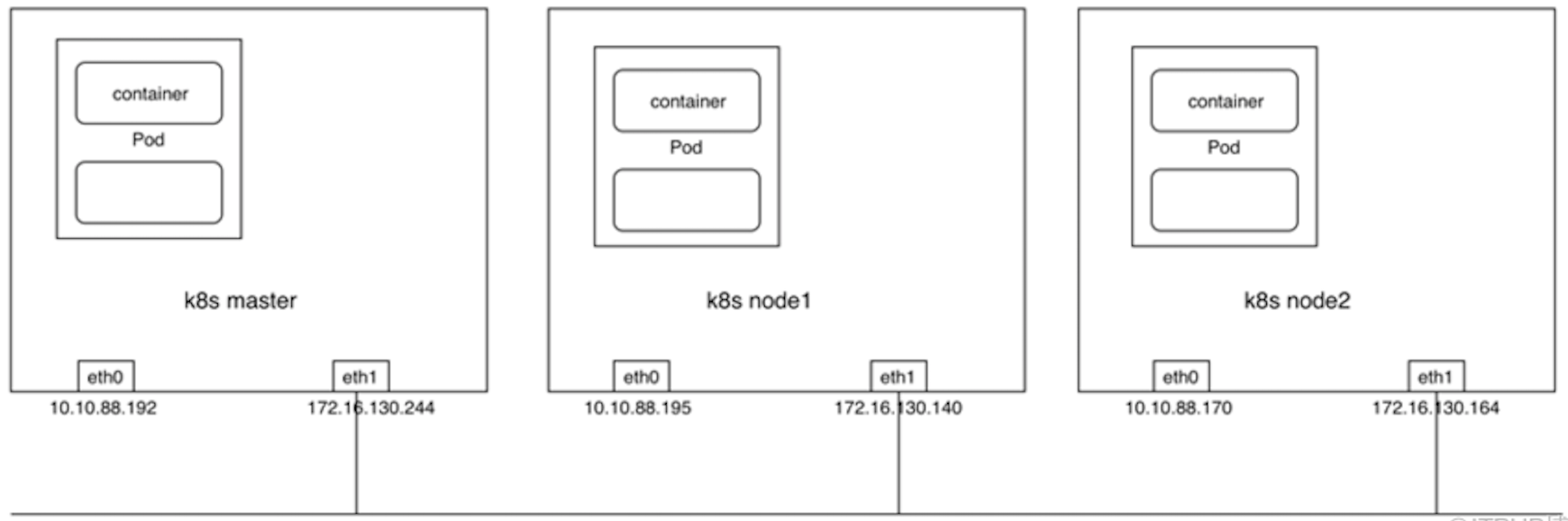
在安裝部署完成之後應該能看到在各個節點上通過DaemonSet的方式運行了一個Flannel的Pod。
[root@10-10-88-192 ~]# kubectl get daemonset -n kube-system -l app=flannel
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
kube-flannel-ds 3 3 3 3 3 beta.kubernetes.io/arch=amd64 135d
[root@10-10-88-192 ~]#
[root@10-10-88-192 ~]#
[root@10-10-88-192 ~]# kubectl get pod -n kube-system -o wide -l app=flannel
NAME READY STATUS RESTARTS AGE IP NODE
kube-flannel-ds-npcxv 1/1 Running 0 2h 172.16.130.164 10-10-88-170
kube-flannel-ds-rv8wv 1/1 Running 0 2h 172.16.130.244 10-10-88-192
kube-flannel-ds-t5zlv 1/1 Running 0 2h 172.16.130.140 10-10-88-195
[root@10-10-88-192 ~]#每一個Flannel的Pod當中都運行了一個flanneld進程,且flanneld的配置文件以ConfigMap的形式掛載到容器內的/etc/kube-flannel/目錄供flanneld使用。
[root@10-10-88-192 ~]# kubectl get cm -n kube-system -l app=flannel
NAME DATA AGE
kube-flannel-cfg 2 137d
[root@10-10-88-192 ~]#Flannel Backend
Flannel 通過在每一個節點上啓動一個叫flanneld的進程,負責每一個節點上的子網劃分,並將相關的配置信息如各個節點的子網網段、外部IP等保存到etcd當中,而具體的網絡包轉發交給具體的Backend來實現。
flanneld 可以在啓動的時候通過配置文件來指定不同的Backend來進行網絡通信,目前比較成熟的Backend有VXLAN、host-gw以及UDP三種方式,也有諸如AWS,GCE and AliVPC這些還在實驗階段的Backend。VXLAN 是目前官方最推崇的一種Backend實現方式,host-gw一般用於對網絡性能要求比較高的場景,但需要基礎架構本身的支持,UDP則一般用於Debug和一些比較老的不支持VXLAN的Linux內核。
這裏只展開講講最成熟也是最通用的三種Backend網絡通信實現流程:
1) UDP
2) VXLAN
3) host-gw
1、UDP
由於UDP模式相對容易理解,故這裏先採用UDP這種Backend模式進行舉例說明然後再對其他Backend模式進行展開講解。
採用UDP模式時需要在flanneld的配置文件當中指定Backend type爲UDP,可以通過直接修改flanneld的ConfigMap的方式實現,配置修改完成之後如下:
[root@10-10-88-192 ~]# kubectl get cm -n kube-system -o yaml kube-flannel-cfg
apiVersion: v1
data:
cni-conf.json: |
{
"name": "cbr0",
"type": "flannel",
"delegate": {
"isDefaultGateway": true
}
}
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "udp"
}
}
kind: ConfigMap
metadata:
creationTimestamp: 2018-10-30T08:34:01Z
labels:
app: flannel
tier: node
name: kube-flannel-cfg
namespace: kube-system
resourceVersion: "33718154"
selfLink: /api/v1/namespaces/kube-system/configmaps/kube-flannel-cfg
uid: 8d981eff-dc1e-11e8-8103-fa900126bc00
[root@10-10-88-192 ~]#關鍵字段爲Backend當中的Type字段,採用UDP模式時Backend Port默認爲8285,即flanneld的監聽端口。
flanneld的ConfigMap更新完成之後delete flannel pod進行配置更新:
[root@10-10-88-192 ~]# kubectl delete pod -n kube-system -l app=flannel
pod "kube-flannel-ds-npcxv" deleted
pod "kube-flannel-ds-rv8wv" deleted
pod "kube-flannel-ds-t5zlv" deleted
[root@10-10-88-192 ~]#當採用UDP模式時,flanneld進程在啓動時會通過打開/dev/net/tun的方式生成一個TUN設備,TUN設備可以簡單理解爲Linux當中提供的一種內核網絡與用戶空間(應用程序)通信的一種機制,即應用可以通過直接讀寫tun設備的方式收發RAW IP包。
flanneld進程啓動後通過ip a命令可以發現節點當中已經多了一個叫flannel0的網絡接口:
[root@10-10-88-192 ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether fa:90:01:26:bc:00 brd ff:ff:ff:ff:ff:ff
inet 10.10.88.192/24 brd 10.10.88.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::f890:1ff:fe26:bc00/64 scope link
valid_lft forever preferred_lft forever
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether fa:86:b8:79:70:01 brd ff:ff:ff:ff:ff:ff
inet 172.16.130.244/24 brd 172.16.130.255 scope global eth1
valid_lft forever preferred_lft forever
inet6 fe80::f886:b8ff:fe79:7001/64 scope link
valid_lft forever preferred_lft forever
4: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN
link/ether 02:42:ae:dd:19:83 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 scope global docker0
valid_lft forever preferred_lft forever
5: flannel0: <POINTOPOINT,MULTICAST,NOARP,UP,LOWER_UP> mtu 1472 qdisc pfifo_fast state UNKNOWN qlen 500
link/none
inet 10.244.0.0/16 scope global flannel0
valid_lft forever preferred_lft forever
inet6 fe80::969a:a8eb:e4da:308b/64 scope link flags 800
valid_lft forever preferred_lft forever
6: cni0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1472 qdisc noqueue state UP qlen 1000
link/ether 0a:58:0a:f4:00:01 brd ff:ff:ff:ff:ff:ff
inet 10.244.0.1/24 scope global cni0
valid_lft forever preferred_lft forever
inet6 fe80::3428:a4ff:fe6c:bb77/64 scope link
valid_lft forever preferred_lft forever細心的同學就會發現此時flannel0這個網絡接口上的MTU爲1472,相比Kubernetes集羣網絡接口eth1小了28個字節,爲什麼呢?
通過可以ip -d link show flannel0可以看到這是一個tun設備:
[root@10-10-88-192 ~]# ip -d link show flannel0
5: flannel0: <POINTOPOINT,MULTICAST,NOARP,UP,LOWER_UP> mtu 1472 qdisc pfifo_fast state UNKNOWN mode DEFAULT qlen 500
link/none promiscuity 0
tun
[root@10-10-88-192 ~]#通過netstat -ulnp命令可以看到此時flanneld進程監聽在8285端口:
[root@10-10-88-192 ~]# netstat -ulnp | grep flanneld
udp 0 0 172.16.130.140:8285 0.0.0.0:* 2373/flanneld
[root@10-10-88-192 ~]#容器跨節點通信實現流程:
假設在節點A上有容器A(10.244.1.96),在節點B上有容器B(10.244.2.194),此時容器A向容器發送一個ICMP請求報文(ping),我們來逐步分析一下ICMP報文是如何從容器A到達容器B的。
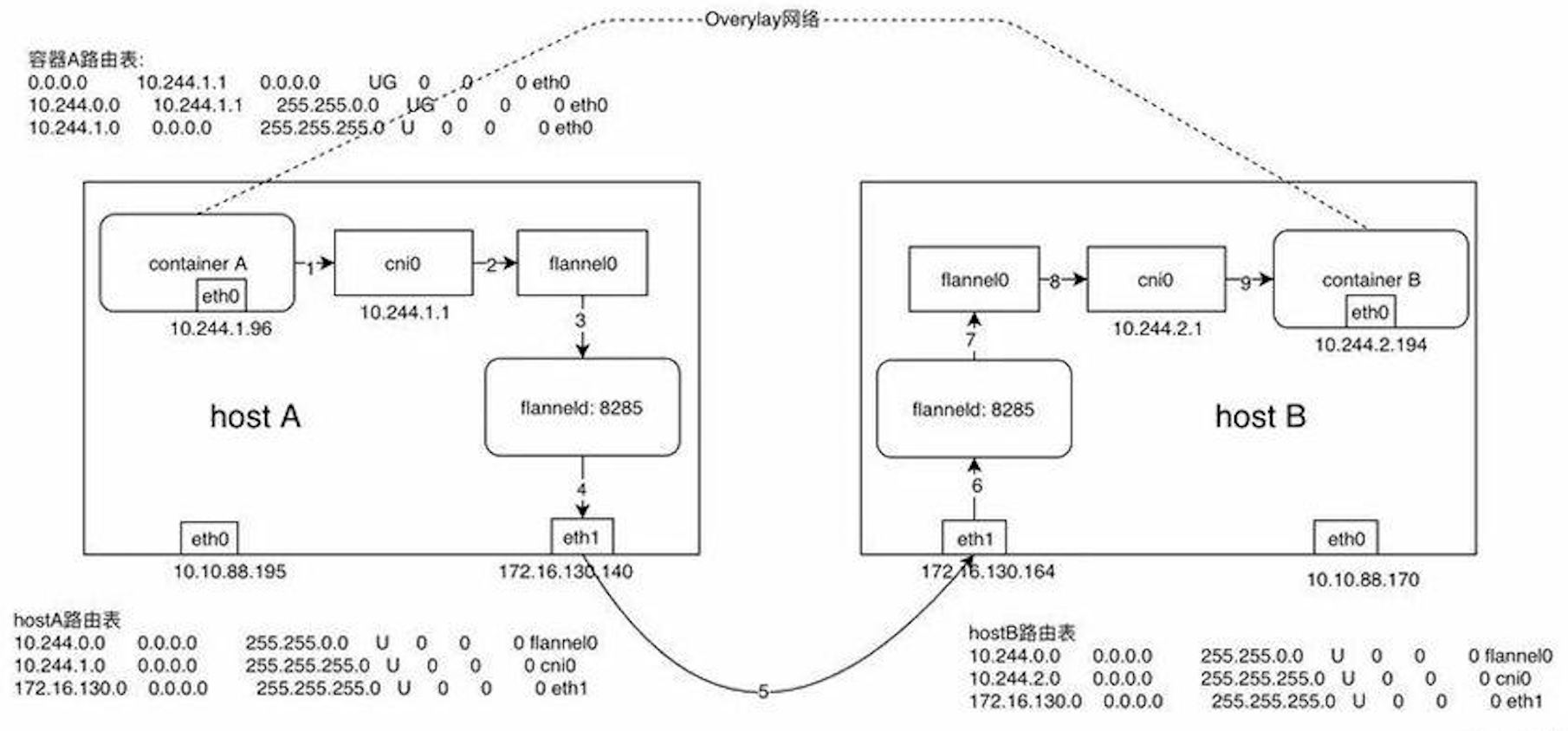
1)、容器A當中發出ICMP請求報文,通過IP封裝後形式爲:10.244.1.96 -> 10.244.2.194,此時通過容器A內的路由表匹配到應該將IP包發送到網關10.244.1.1(cni0網橋)。
完整的幀格式爲: 
2)、此時到達cni0的IP包目的地IP 10.244.2.194匹配到節點A上第一條路由規則(10.244.0.0),內核將RAW IP包發送給flannel0接口。
3)、flannel0爲tun設備,發送給flannel0接口的RAW IP包(無MAC信息)將被flanneld進程接收到,flanneld進程接收到RAW IP包後在原有的基礎上進行UDP封包,UDP封包的形式爲:172.16.130.140:src port -> 172.16.130.164:8285。
這裏有一個問題就是flanneld怎麼知道10.244.2.194這個容器到底是在哪個節點上呢?
flanneld在啓動時會將該節點的網絡信息通過api-server保存到etcd當中,故在發送報文時可以通過查詢etcd得到10.244.2.194這個容器的IP屬於host B,且host B的IP爲172.16.130.164。
RAW IP包示例:
4)、flanneld將封裝好的UDP報文經eth1發出,從這裏可以看出網絡包在通過eth1發出前先是加上了UDP頭(8個字節),再然後加上了IP頭(20個字節)進行封裝,這也是爲什麼flannel0的MTU要比eth1的MTU小28個字節的原因(防止封裝後的以太網幀超過eth1的MTU而在經過eth1時被丟棄)。
此時完整的以太網幀格式爲:
5)、網絡包經節點A和節點B之間的網絡連接到達host B。
6)、host B收到UDP報文後經Linux內核通過UDP端口號8285將包交給正在監聽的應用flanneld。
7)、運行在host B當中的flanneld將UDP包解包後得到RAW IP包:10.244.1.96 -> 10.244.2.194。
8)、解封后的RAW IP包匹配到host B上的路由規則(10.244.2.0),內核將RAW IP包發送到cni0。
此時的完整的以太網幀格式爲:
9)、cni0將IP包轉發給連接在cni0網橋上的container B,而flanneld在整個過程中主要主要負責兩個工作:UDP封包解包 和 節點上的路由表的動態更新
從上面虛線部分就可以看到container A和container B雖然在物理網絡上並沒有直接相連,但在邏輯上就好像是處於同一個三層網絡當中,這種基於底下的物理網絡設備通過Flannel等軟件定義網絡技術實現的網絡我們稱之爲Overlay網絡。
那麼上面通過UDP這種Backend實現的網絡傳輸過程有沒有問題呢?最明顯的問題就是,網絡數據包先是通過tun設備從內核當中複製到用戶態的應用,然後再由用戶態的應用複製到內核,僅一次網絡傳輸就進行了兩次用戶態和內核態的切換,顯然這種效率是不會很高的。那麼有沒有高效一點的辦法呢?當然,最簡單的方式就是把封包解包這些事情都交給內核去幹好了,事實上Linux內核本身也提供了比較成熟的網絡封包解包(隧道傳輸)實現方案VXLAN,下面我們就來看看通過內核的VXLAN跟flanneld自己通過UDP封裝網絡包在實現上有什麼差別。
2、VXLAN
VXLAN全稱Virtual Extensible LAN,是一種虛擬化隧道通信技術,主要是爲了突破VLAN的最多4096個子網的數量限制,以滿足大規模雲計算數據中心的需求。VLAN技術的缺陷是VLAN Header預留的長度只有12 bit,故最多隻能支持2的12次方即4096個子網的劃分,無法滿足雲計算場景下主機數量日益增長的需求。當前VXLAN的報文Header內有24 bit,可以支持2的24次方個子網,並通過VNI(Virtual Network Identifier)來區分不同的子網,相當於VLAN當中的VLAN ID。
不同於其他隧道協議,VXLAN是一個一對多的網絡,並不僅僅是一對一的隧道協議。一個VXLAN設備能通過像網橋一樣的學習方式學習到其他對端的IP地址,也可以直接配置靜態轉發表。
VXLAN包格式:
詳細如下: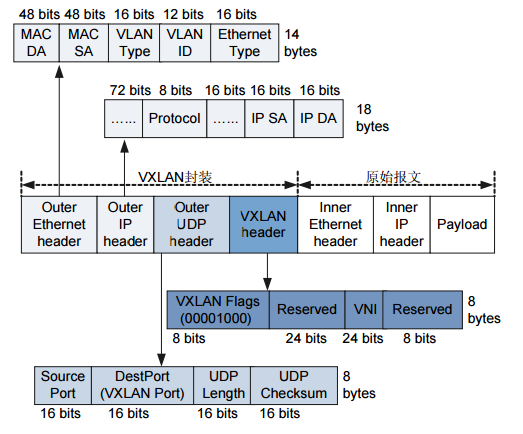
從VXLAN的包格式就可以看到原本的二層以太網幀被放在VXLAN包頭裏進行封裝,VXLAN實際實現的是一個二層網絡的隧道,通過VXLAN讓處於同一個VXLAN網絡(VNI相同則爲同一個VXLAN網絡)當中的機器看似處在同一個二層網絡當中(邏輯上處於同一個二層網絡),而網絡包轉發的方式也類似二層網絡當中的交換機(這樣雖然不是很準確,但更便於理解)。
當採用VXLAN模式時,flanneld在啓動時會通過Netlink機制與Linux內核通信,建立一個VTEP(Virtual Tunnel Access End Point)設備flannel.1 (命名規則爲flannel.[VNI],VNI默認爲1),類似於交換機當中的一個網口。
可以通過ip -d link查看VTEP設備flannel.1的配置信息,從以下輸出可以看到,VTEP的local IP爲172.16.130.244,destination port爲8472。
[root@10-10-88-192 ~]# ip -d link show flannel.1
5: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN mode DEFAULT
link/ether a2:5e:b0:43:09:a7 brd ff:ff:ff:ff:ff:ff promiscuity 0
vxlan id 1 local 172.16.130.244 dev eth1 srcport 0 0 dstport 8472 nolearning ageing 300 addrgenmode eui64
[root@10-10-88-192 ~]#在UDP模式下由flanneld進程進行網絡包的封包和解包的工作,而在VXLAN模式下解封包的事情交由內核處理,那麼此時FlannnelD的作用是什麼呢?帶着這個疑問我們先來簡單看一下VXLAN Backend是如何工作的。
VXLAN Backend工作原理
Flannel當中對VXLAN Backend的實現經過了幾個版本的改進之後目前最新版本的flanneld當中的處理流程爲:
當flanneld啓動時將創建VTEP設備(默認爲flannel.1,若已經創建則跳過),並將VTEP設備的相關信息上報到etcd當中,而當在Flannel網絡中有新的節點發現時,各個節點上的flanneld將依次執行以下流程:
在節點當中創建一條該節點所屬網段的路由表,主要是能讓Pod當中的流量路由到flannel.1接口。
通過route -n可以查看到節點當中已經有兩條flannel.1接口的路由:
[root@10-10-88-192 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.10.88.254 0.0.0.0 UG 0 0 0 eth0
10.10.88.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
10.244.0.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0
10.244.1.0 10.244.1.0 255.255.255.0 UG 0 0 0 flannel.1
10.244.2.0 10.244.2.0 255.255.255.0 UG 0 0 0 flannel.1
169.254.0.0 0.0.0.0 255.255.0.0 U 1002 0 0 eth0
169.254.0.0 0.0.0.0 255.255.0.0 U 1003 0 0 eth1
172.16.130.0 0.0.0.0 255.255.255.0 U 0 0 0 eth1
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
[root@10-10-88-192 ~]#在節點當中添加一條該節點的IP以及VTEP設備的靜態ARP緩存。
可通過arp -n命令查看到master節點當中已經緩存了另外兩個節點以及VTEP的ARP信息(已刪除無關ARP緩存信息)。
[root@10-10-88-192 ~]# arp -n
Address HWtype HWaddress Flags Mask Iface
10.244.2.0 ether 42:7f:69:c7:cd:37 CM flannel.1
10.244.1.0 ether 7a:2c:d0:7f:48:3f CM flannel.1
172.16.130.140 ether fa:89:cf:03:e3:01 C eth1
172.16.130.164 ether fa:88:2a:44:2b:01 C eth1在節點當中添加一條該節點的轉發表。
通過bridge命令查看節點上的VXLAN轉發表(FDB entry),MAC爲對端VTEP設備即flannel.1的MAC,IP爲VTEP對應的對外IP(可通過flanneld的啓動參數--iface=eth1指定,若不指定則按默認網關查找網絡接口對應的IP),可以看到已經有兩條轉發表。
[root@10-10-88-192 ~]# bridge fdb show dev flannel.1
42:7f:69:c7:cd:37 dst 172.16.130.164 self permanent
7a:2c:d0:7f:48:3f dst 172.16.130.140 self permanent
[root@10-10-88-192 ~]#VXLAN Backend配置
跟UDP Backend一樣,將Flannel Backend修改爲VXLAN只需要將Flannel ConfigMap當中的Backend type字段修改爲VXLAN即可。由於VXLAN類型相對UDP複雜並且有較好的靈活性,這裏簡單說一下VXLAN當中的幾個配置選項:
VNI(Number):VXLAN Identifier,默認爲1
Port(Number):用於發送VXLAN UDP報文的端口,默認爲8472
DirectRouting(Boolean):當兩臺主機處於同一個網段當中時,啓用後將採用直接路由的方式進行跨節點網絡通信(此時工作模式跟後面要講的host-gw Backend一樣),只有當兩臺主機處於不同的網段當中時纔會採用VXLAN進行封包,默認爲關閉狀態。
修改完成後的ConfigMap如下:
[root@10-10-88-192 ~]# kubectl get cm -o yaml -n kube-system kube-flannel-cfg
apiVersion: v1
data:
cni-conf.json: |
{
"name": "cbr0",
"type": "flannel",
"delegate": {
"isDefaultGateway": true
}
}
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan"
}
}
kind: ConfigMap
metadata:
creationTimestamp: 2018-10-30T08:34:01Z
labels:
app: flannel
tier: node
name: kube-flannel-cfg
namespace: kube-system
resourceVersion: "33872104"
selfLink: /api/v1/namespaces/kube-system/configmaps/kube-flannel-cfg
uid: 8d981eff-dc1e-11e8-8103-fa900126bc00
[root@10-10-88-192 ~]#同樣在更新配置後delete pod使配置生效,並可以通過Flannel的日誌查看到Backend已經更新爲VXLAN模式:
[root@10-10-88-192 ~]# kubectl logs -f -n kube-system kube-flannel-ds-7bjfm
I0318 03:24:02.148654 1 main.go:487] Using interface with name eth1 and address 172.16.130.244
I0318 03:24:02.148754 1 main.go:504] Defaulting external address to interface address (172.16.130.244)
I0318 03:24:02.207525 1 kube.go:130] Waiting 10m0s for node controller to sync
I0318 03:24:02.207596 1 kube.go:283] Starting kube subnet manager
I0318 03:24:03.207695 1 kube.go:137] Node controller sync successful
I0318 03:24:03.207729 1 main.go:234] Created subnet manager: Kubernetes Subnet Manager - 10-10-88-192
I0318 03:24:03.207735 1 main.go:237] Installing signal handlers
I0318 03:24:03.207812 1 main.go:352] Found network config - Backend type: vxlan
I0318 03:24:03.227332 1 vxlan.go:119] VXLAN config: VNI=1 Port=0 GBP=false DirectRouting=false
I0318 03:24:03.587362 1 main.go:299] Wrote subnet file to /run/flannel/subnet.env
I0318 03:24:03.587379 1 main.go:303] Running backend.
I0318 03:24:03.587390 1 main.go:321] Waiting for all goroutines to exit
I0318 03:24:03.587418 1 vxlan_network.go:56] watching for new subnet leases同樣可以通過netstat -ulnp命令查看VXLAN監聽的端口:
[root@10-10-88-192 ~]# netstat -ulnp | grep 8472
udp 0 0 0.0.0.0:8472 0.0.0.0:* -
[root@10-10-88-192 ~]#但跟UDP模式下查看flanneld監聽的端口的區別爲,最後一欄顯示的不是進程的ID和名稱,而是一個破折號“-”,這說明UDP的8472端口不是由用戶態的進程在監聽的,也證實了VXLAN模塊工作在內核態模式下。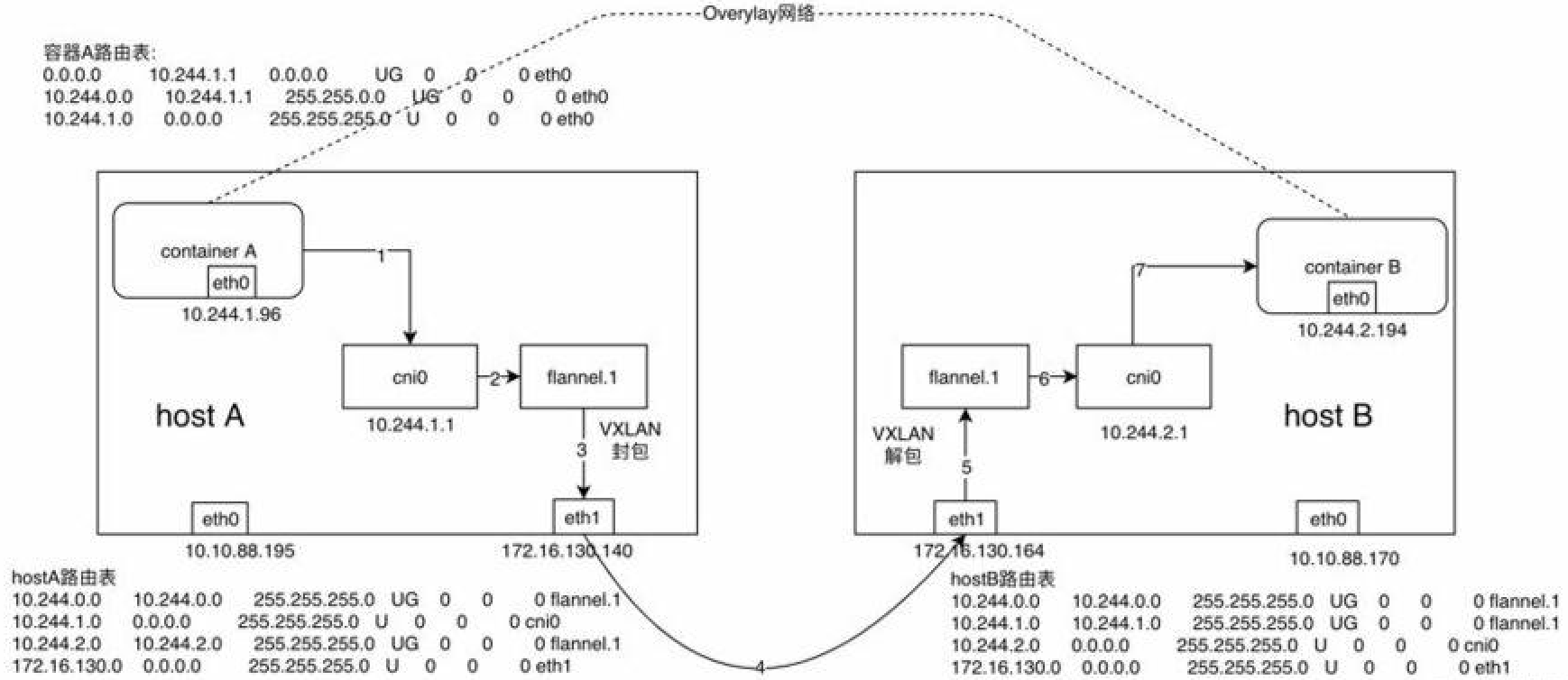
此時容器跨節點網絡通信實現流程爲:
1) 同UDP Backend模式,容器A當中的IP包通過容器A內的路由表被髮送到cni0
2) 到達cni0當中的IP包通過匹配host A當中的路由表發現通往10.244.2.194的IP包應該交給flannel.1接口
3) flannel.1作爲一個VTEP設備,收到報文後將按照VTEP的配置進行封包,首先通過etcd得知10.244.2.194屬於節點B,並得到節點B的IP,通過節點A當中的轉發表得到節點B對應的VTEP的MAC,根據flannel.1設備創建時的設置的參數(VNI、local IP、Port)進行VXLAN封包
4) 通過host A跟host B之間的網絡連接,VXLAN包到達host B的eth1接口
5) 通過端口8472,VXLAN包被轉發給VTEP設備flannel.1進行解包
6) 解封裝後的IP包匹配host B當中的路由表(10.244.2.0),內核將IP包轉發給cni0
7) cni0將IP包轉發給連接在cni0上的容器B
這麼一看是不是覺得相比UDP模式單單從步驟上就少了很多步?VXLAN模式相比UDP模式高效也就不足爲奇了。
host-gw
host-gw即Host Gateway,從名字中就可以想到這種方式是通過把主機當作網關來實現跨節點網絡通信的。那麼具體如何實現跨節點通信呢?
同理UDP模式和VXLAN模式,首先將Backend中的type改爲host-gw,這裏就不再贅述,只講一下網絡通信的實現流程。
採用host-gw模式後flanneld的唯一作用就是負責主機上路由表的動態更新, 想一下這樣會不會有什麼問題?
使用host-gw Backend的Flannel網絡的網絡包傳輸過程如下圖所示: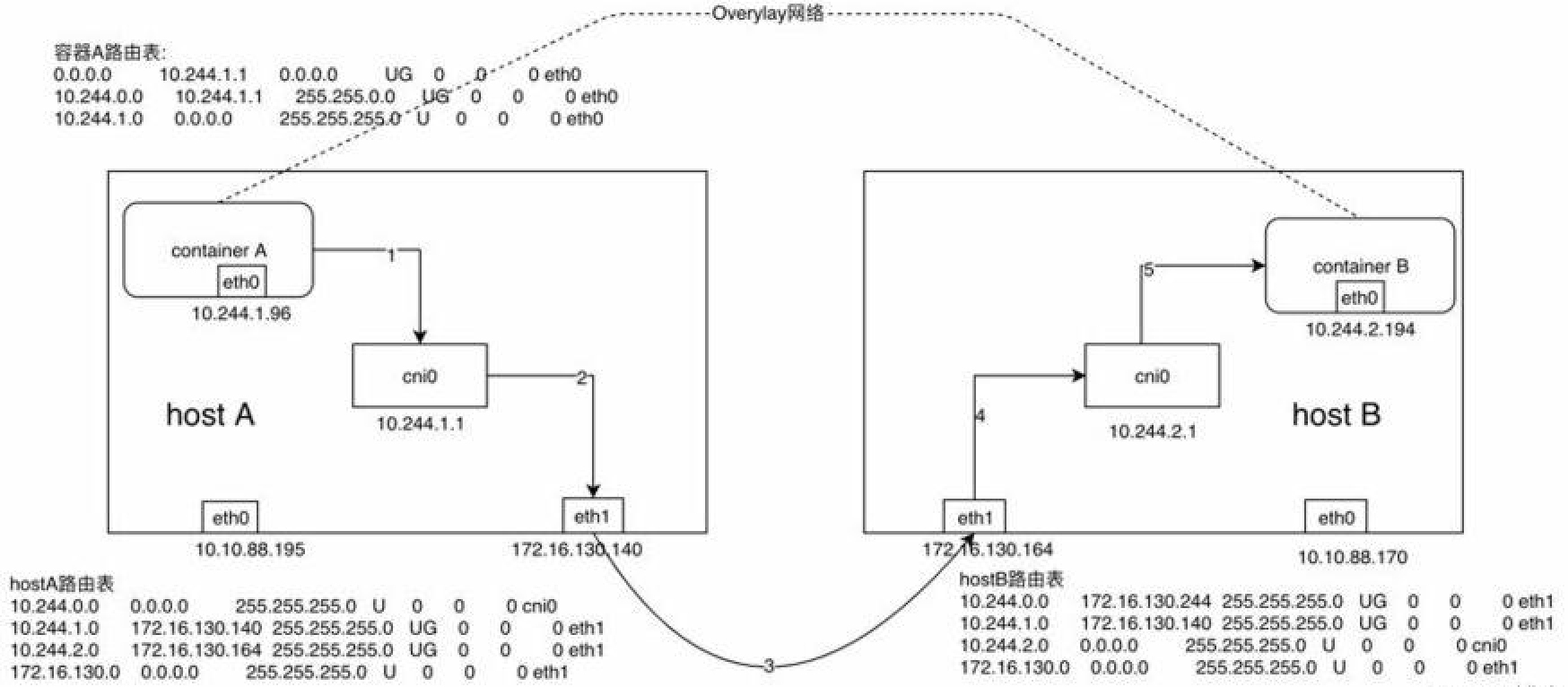
1) 同UDP、VXLAN模式一致,通過容器A的路由表IP包到達cni0
2) 到達cni0的IP包匹配到host A當中的路由規則(10.244.2.0),並且網關爲172.16.130.164,即host B,所以內核將IP包發送給host B(172.16.130.164)
3) IP包通過物理網絡到達host B的eth1
4) 到達host B eth1的IP包匹配到host B當中的路由表(10.244.2.0),IP包被轉發給cni0
5) cni0將IP包轉發給連接在cni0上的容器B
host-gw模式其中一個侷限性就是,由於是通過節點上的路由表來實現各個節點之間的跨節點網絡通信,那麼就得保證兩個節點是可以直接路由過去的。按照內核當中的路由規則,網關必須在跟主機當中至少一個IP處於同一網段,故造成的結果就是採用host-gw這種Backend方式時則集羣中所有的節點必須處於同一個網絡當中,這對於集羣規模比較大時需要對節點進行網段劃分的話會存在一定的侷限性。另外一個則是隨着集羣當中節點規模的增大,flanneld需要維護主機上成千上萬條路由表的動態更新也是一個不小的壓力。